摘要:在開發初期開發者往往聚焦在模型的精度上,性能關注較少,但隨著業務量不斷增加,AI應用的性能往往成為瓶頸,此時對于沒有性能優化經驗的開發者來說往往需要耗費大量精力做優化性能,本文為開發者介紹一些常用的優化方法和經驗,
本文分享自華為云社區《如何使用ModelBox快速提升AI應用性能》,作者: panda,
隨著AI技術和計算能力的發展,越來越多的開發者學會用tensorflow、pytorch等引擎訓練模型并開發成AI應用以解決各種生產問題,在開發初期開發者往往聚焦在模型的精度上,性能關注較少,但隨著業務量不斷增加,AI應用的性能往往成為瓶頸,此時對于沒有性能優化經驗的開發者來說往往需要耗費大量精力做優化性能,本文為開發者介紹一些常用的優化方法和經驗,本文首先介紹什么是AI應用性能優化,以及常用的性能優化手段,然后介紹華為云ModelBox開源框架,最后結合實際業務為例,詳細講解如何利用ModelBox框架進行快速的性能優化以及背后的原理,
一、AI應用常用性能優化方法
1、什么是AI應用性能優化
什么是AI應用性能優化? AI應用性能優化是保證結果正確的情況下,提升AI推理應用執行效率,AI應用性能優化的目的一般分為兩方面:一方面可以提升用戶體驗,如門禁系統刷臉場景,對推理時延比較敏感,識別速度直接影響用戶感官,再比如自動駕駛場景,對時延要求非常高;另一方面可以降低硬體成本,相同的硬體設備可以支撐更多的業務,當部署節點數具備一定規模時,節省的硬體成本就相當可觀了,
如何去衡量性能的好壞?我們通常使用吞吐量和時延來衡量, 吞吐量在不同場景也有不同衡量指標,比如圖片請求場景,一般使用qps作為吞吐量的指標,即每秒種處理的請求個數,在視頻流場景,則一般使用視頻并發路數來衡量, 時延是指資料輸入到結果輸出中間的處理時間差,正常來講吞吐量越大越好,時延越小越好,在不同場景對吞吐量和時延的要求不一樣, 對于某些時延不敏感的場景,我們可以犧牲時延來提升吞吐量,所以我們在做性能優化前需要先明確優化指標是吞吐量還是時延,
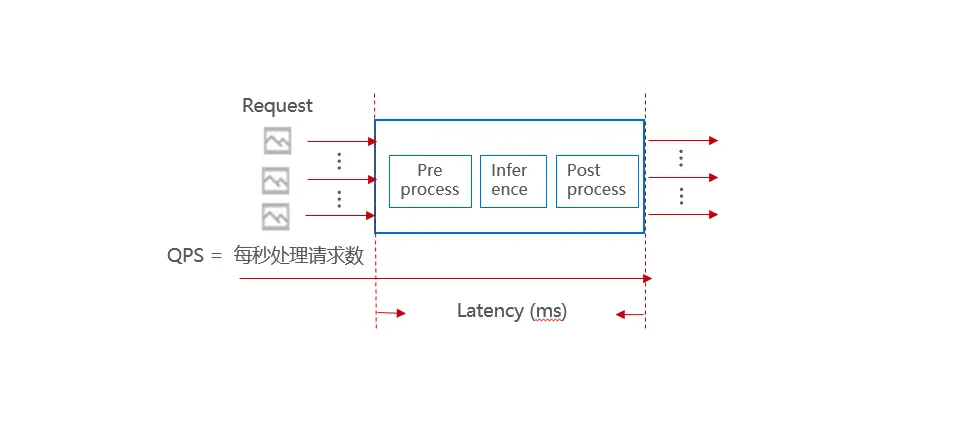
另外除此之外,在性能優化程序中,還需要重點關注一些系統資源指標,如記憶體、顯存、CPU占用率、GPU占用率等,這些指標可以幫忙我們輔助判斷當前資源使用情況,為我們做性能優化提供思路,如GPU利用率較低時,就需要針對性想辦法充分利用GPU資源,
2、AI應用性能優化方法
一個AI應用可以分為模型和工程邏輯,AI應用的優化我們也可以從上到下進行劃分,其中應用流程優化和應用工程優化為工程方面的優化,模型編譯優化和模型演算法優化則為模型優化,
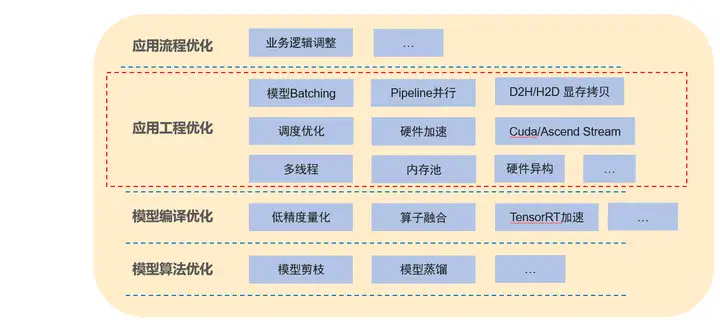
應用流程優化:主要是對業務邏輯進行調整,減少一些不必要的操作以到達性能提升的效果,業務邏輯的優化有時是最快捷最有效的,往往會有事半功倍的效果,但需要具體場景具體分析,
應用工程優化:主要是軟體工程方面的優化,如多執行緒、記憶體池、硬體加速等等, 對上層 ,此外模型batching也是最常見的優化手段,通過共享佇列組batch以充分利用模型的batching性能,方法較通用,ModelBox框架提供的主要為應用工程優化能力,
模型編譯優化:常用手段有低精度量化、混合精度等、算子融合等,此類優化會影響模型精度,
模型演算法優化:對模型結構進行優化,減少模型計算量,如模型剪枝、模型蒸餾等,需要重新訓練,
本文重點介紹AI應用工程優化的常用手段,常用優化手段如下:
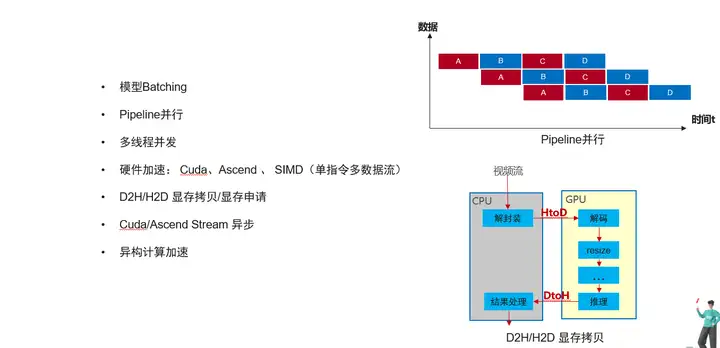
模型Batching: 原理主要是將多次推理資料合并成一批資料進行GPU推理,相比單資料推理,batching推理可以降低Gpu Kernel Launch次數,充分利用多個GPU計算單元并發計算,從而提高整體吞吐量, 一次推理的資料個數叫Batchsize,Batchsize不一定是越大越好,往往和模型結構的稀疏程度有關系 ,所以需要具體模型具體分析,
Pipeline并行:將業務的處理劃分為幾個階段,通過流水線的方式讓不同資料并行起來,如下圖所示,同一時間資料1在執行操作C的同時,資料2在執行操作B,資料3在執行操作A,
多執行緒并發:某個操作單執行緒處理成為瓶頸時,可以采用多執行緒并發執行,但一般還需要對多執行緒執行的結果做保序操作,
硬體加速:使用硬體的加速能力如Cuda、Ascend 、 SIMD等,與此同時硬體的加速會帶來額外的主機到硬體設備的記憶體拷貝開銷,
顯存拷貝/顯存申請: 不同與記憶體,硬體上顯存的拷貝和申請耗時較長,頻繁的申請和拷貝會影響整體性能,可以通過顯存池的管理減少記憶體申請的時間,還可以調整業務邏輯,盡量減少HtoD,DtoH的拷貝次數,
Cuda/Ascend Stream 異步: 基于cuda或者ascend硬體時,可以使用帶Stream的異步介面進行加速,
異構計算加速:可以使用多個或者多種硬體進行加速,如使用多GPU進行推理,再比如使用cpu+gpu多硬體同時推理,并且能做到負載均衡,
以上這些常用的應用工程優化需要根據當前業務瓶頸合理選擇,同時上述方法的實作實作往往需要耗費大量作業,同時對軟體能力要求較高,為此華為云開源了ModelBox框架,集成了上述優化手段,能夠幫忙開發者快速提升性能,
二、ModelBox開源框架介紹
1、什么ModelBox開源框架
一個典型場景AI演算法的商用落地除了模型訓練外,還需要進行視頻圖片解碼、HTTP服務、預處理、后處理、多模型復雜業務串聯、運維、打包等工程開發,往往需要耗費比模型訓練多得多的時間,同時演算法的性能和可靠性通常隨開發人員的工程能力水平高低而參差不齊,嚴重影響AI演算法的上線效率,
ModelBox是一套專門為AI開發者提供的易于使用,高效,高擴展的AI推理開發框架,它可以幫助AI開發者快速完成從模型檔案到AI推理應用的開發和上線作業,降低AI演算法落地門檻,同時帶來AI應用的高穩定性和極致性能,ModelBox是一套易用、高效、高擴展的AI推理開發框架,幫助開發者快速完成演算法工程化,并帶來高性能,一次開發端邊云部署等好處,ModelBox框架當前已經開源,可詳見https://modelbox-ai.com,
ModelBox框架主要特點有:
- 高效推理運行性能:集成常用應用工程優化手段,高效的智能調度引擎,相比原生推理框架性能成倍提升,
- 全場景靈活開發模式:支持圖編排模式、SDK模式、Serving模式等多種適用方式,適用于新業務快速開發、業務遷移、單模型推理等不同開發場景,
- 一次開發端邊云部署:屏蔽底層作業系統、加速硬體、推理框架差異,一份代碼端邊云部署,
- 支撐多語言開發:支持C++、Python兩種語言開發,
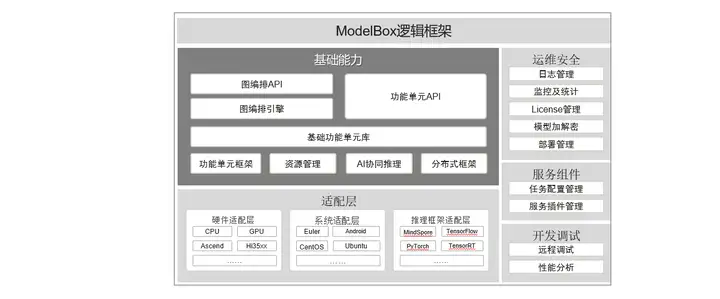
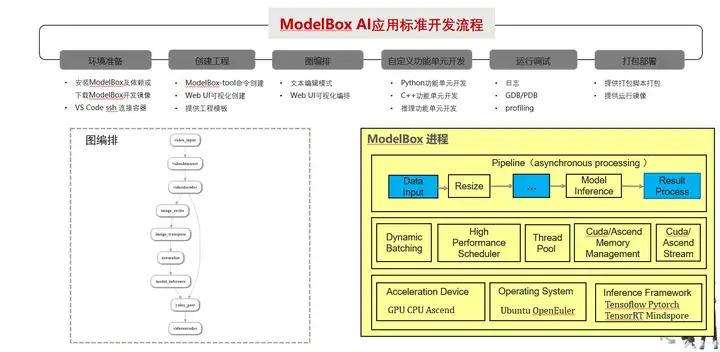
ModolBox框架采用圖編排的方式開發業務,將應用執行邏輯通過有向圖的方式表達出來,而圖上的每個節點叫做ModelBox功能單元,是應用的基本組成部分,也是ModelBox的執行單元,在ModelBox中,內置了大量的高性能基礎功能單元庫,開發者可以直接復用這些功能單元減少開發作業,除內置功能單元外,ModelBox支持功能單元的自定義開發,支持的功能單元形式多樣,如C/C++動態庫、Python腳本、模型+模型組態檔等,除此之外,ModolBox提供了運維安全、開發除錯等配套的組件用于快速服務化,
ModolBox邏輯架構如下圖:
ModelBox提供了兩個開發模式:標準模式和SDK模式,
標準模式:這種模式下AI應用的主入口由ModelBox行程管理,應用的全部邏輯承載編排在流程圖中,開發者首先通過流程圖組態檔描述整個應用的資料處理程序,然后實作流程圖中缺少的功能單元,完成整個應用,此模式優點是并發度高,性能好,配套組件豐富,缺點是需要把全部業務邏輯拆分為圖,在存量復雜業務場景切換作業量大,
SDK模式:這種模式下,開發者業務行程通過ModelBox SDK提供的API管理流程圖的初始化、啟動及資料互動, 此模式可以選擇性的將部分邏輯切換為ModelBox圖編排,優點是改動少,優化作業量少,可以逐步優化,缺點相對于標準模式只能獲得部分性能收益,
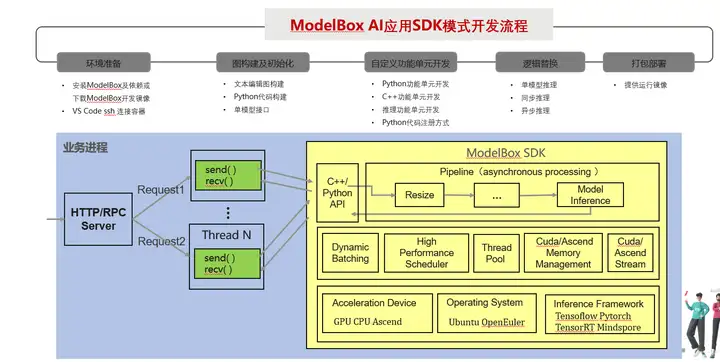
兩種模式適用于不同場景,標準模式適用于整體業務邏輯清晰,比較容易通過流程圖方式表達的場景,和新開發業務場景,SDK模式適用場景于應用邏輯不能全部進入流程圖中,控制邏輯較為復雜的場景;已有業務遷移場景等,本文后續講解的AI應用性能優化實踐主要通過SDK模式進行優化,
三、AI應用性能優化實踐
1、影像分類業務介紹
下面以一個影像分類的AI應用為樣例,介紹如何使用ModelBox框架進行性能優化,
該業務原始代碼使用Python語言開發,采用flask框架作為Http Server提供Restful API 對輸入影像進行識別分類,模型為ResNet101網路,訓練引擎為tensorflow ,具體業務邏輯和性能情況如下圖所示:
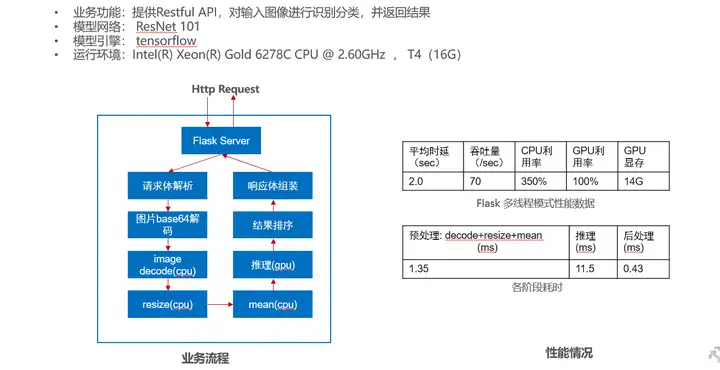
從當前業務場景和性能測驗情況看,推理階段耗時占比大,導致整體性能較差,對照前面講解的AI應用軟體工程優化方法,我們可以從以下幾個方面嘗試做優化:
1)一次請求攜帶一張圖片,只能單batch推理,多個請求多次單bacth推理,算然gpu利用率100%,但效率低,可通過模型batching優化推理性能,
2)如果模型推理時間優化后,預處理、推理、后處理可以通過pipeline并發優化,
3)圖片decode、resize、mean等cpu的預處理操作可以通過cuda、多執行緒加速
我們使用ModelBox框架可以快速嘗試上述模型和預處理優化,測驗效果,
2、模型推理優化
我們首先嘗試使用ModelBox 框架SDK API優化模型推理部分性能,針對純模型優化,ModelBox 提供了Model介面,只需幾行代碼即可完成優化,
1) 環境準備
下載tensorflow引擎的ModelBox開發鏡像,下載方法可見ModelBox檔案,在代碼中引入modelbox包,設定日志級別,
# modelbox
import modelbox
modelbox.set_log_level(modelbox.Log.Level.DEBUG)
2) 配置推理功能單元
新建classify_infer.toml組態檔,根據模型實際情況填寫模型配置,如模型檔案路徑、推理引擎型別、輸入Tensor名稱、輸出Tensor名稱等,配置如下:
# 基礎配置 [base] name = "classify_infer" # 功能單元名稱 device = "cuda" # 功能單元運行的設備型別,cpu,cuda,ascend等, version = "0.0.1" # 功能單元組件版本號 description = "description" # 功能單元功能描述資訊 entry = "../model/resnet_v1_101.pb" # 模型檔案路徑 type = "inference" #推理功能單元時,此處為固定值 virtual_type = "tensorflow" # 指定推理引擎, 可以時tensorflow, tensorrt, atc [config] plugin = "" # 推理引擎插件 # 輸入埠描述 [input] [input.input1] # 輸入埠編號,格式為input.input[N] name = "input" # 輸入埠名稱 # 輸出埠描述 [output] [output.output1] # 輸出埠編號,格式為output.output[N] name = "resnet_v1_101/predictions/Softmax" # 輸出埠名稱
3) 模型初始化
在業務初始化階段使用Model介面進行模型推理實體初始化,介面如下:
modelbox.Model(path, node_name, batch_size, device_type, device_id)
輸入引數說明:
path: 推理功能單元組態檔路徑,即classify_infer.toml路徑
node_name:實體名稱
batch_size:一次batching推理的batchsize最大值,當不足時,采用動態batch,
device_type:加速硬體型別,可取值cuda、cpu、ascend等,也可設定多硬體,如” cuda:0,1,2;cpu:0” 等
device_id:單加速型別時,加速設備號
Model實體初始化成功后啟動,同時注釋掉原有tensorflow不再使用的代碼,初始化代碼如下:
def __init__(self) ... # modelbox self.model = modelbox.Model("/home/code/image_classify/classify_infer/", "classify_infer", ["input"], ["resnet_v1_101/predictions/Softmax"], 8, "cuda", "0") self.model.start()
4) 模型推理替換
使用Model.infer 介面替換掉原始tensorflow的session.run介面,介面說明如下:
output = model.infer([input_port1_data, input_port2_data, … ])
輸入引數說明:
input_port1_data、 input_port2_data : 模型每個輸入Tensor資料
輸出引數說明:
output: 模型的推理結果串列,,可以通過下標獲取每個Tensor輸出結果,結果型別為modelbox::Buffer,通常需要通過numpy介面轉換numpy型別進行后處理,
具體代碼修改如下:
def process(self, img_file): image = self.preprocess(img_file) ... # 對image進行推理,batch為1 # infer_output = self.sess.run(self.output,feed_dict={self.input: np.expand_dims( image,0 )}) # probabilities = infer_output[0, 0:] #modelbox output_list = self.model.infer([image.astype(np.float32)]) output_buffer = output_list[0] probabilities = np.array(output_buffer) ... self.postprocess(probabilities, resp)
至此,推理的優化代碼已修改完畢,進行功能除錯后,即可對性能進行測驗,通過還可以通過ModelBox 性能Profiling工具進行性能資料打點分析推理執行性能詳細情況,具體使用方法可見官方檔案,前面我們講到bacth_size并不是越大越好,我們可以通過調整bacth_size引數測驗性能情況,該業務實測資料如下:
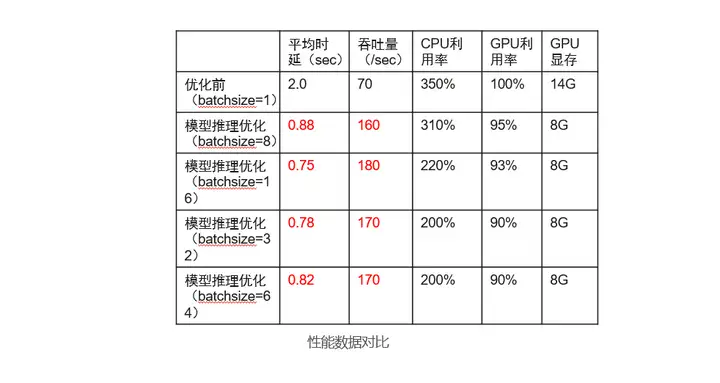
我們可以看到性能優化效果十分明顯,吞吐量整體提升257%,同時在batch_size 為8時性能最佳,至此,模型推理優化完成, 為啥經過簡單幾行代碼即可完成性能的顯著提升呢? 我們可以看看下圖:
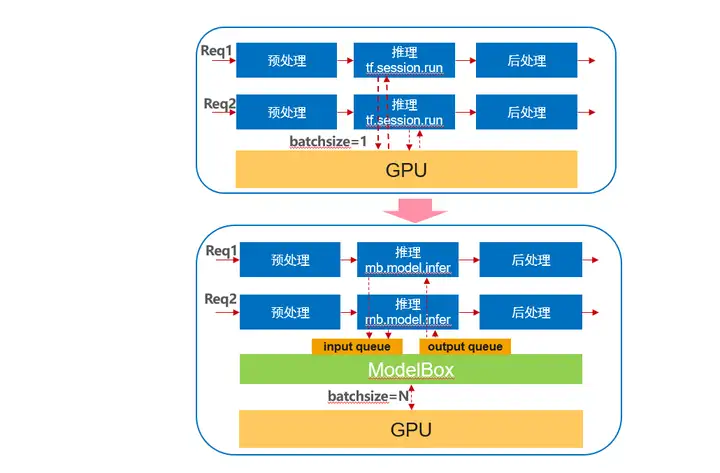
優化前每個請求單獨處理, 每次推理一份資料,使用ModelBox后,會有單獨ModelBox執行緒和佇列將多個執行緒的推理請求合并,通過bacthing推理一組資料,
推理模型切換到ModelBox后,除了識訓性能收益外,還可以獲得如下收益: 軟硬體引擎適配能力, 修改到其他引擎或者硬體無需修改代碼,只需要修改模型組態檔即可; 多卡、多硬體能力:可以通過配置至此單行程多卡,或者多型別硬體異構能力,
3、預處理優化
模型優化完成后,如果瓶頸轉移到模型預處理,我們還可以通過ModelBox對AI應用的預處理進行優化,下面介紹下如果通過ModelBox SDK API進行推理加預處理優化,
1) 構造流程圖
基于上一章節推理優化步驟的環境準備、配置推理功能單元后,我們需要將預處理和推理流程構造為ModelBox流程圖, 原始業務邏輯中:圖片解碼、resize、mean、推理 以上這些操作都是相對耗時,并且通過GPU加速的,本次我們對上述操作進行流程圖構建如下:
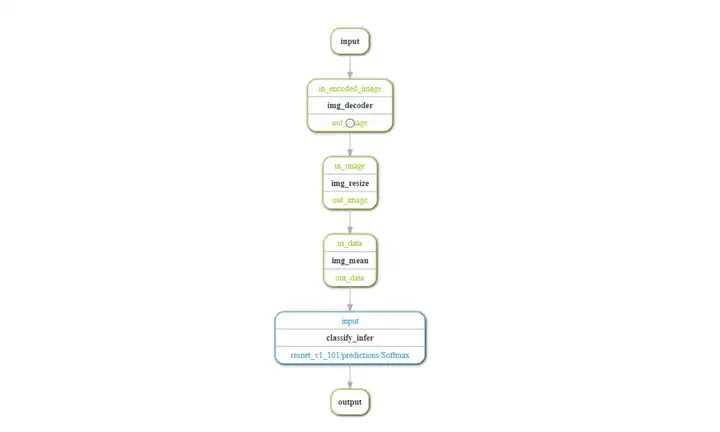
代碼層面,ModelBox可以通過兩種方式構建流程圖:
a)通過圖組態檔構建
創建graph.toml, 并撰寫組態檔如下:
[driver] skip-default = false dir=["/home/code/image_classify/classify_infer/"] # path for user c++ flowuint, python flowuint, infer flowunit [profile] profile=false trace=false dir="/home/code/image_classify/test/" [log] level="INFO" [graph] format = "graphviz" graphconf = '''digraph weibo_sample { queue_size=64 batch_size=8 input[type=input, device=cpu] img_decoder[type=flowunit, flowunit=image_decoder, device=cpu, deviceid=0,batch_size=8] img_resize[type=flowunit, flowunit=resize, device=cpu, deviceid=0, image_height=224, image_width=224,batch_size=18] img_mean[type=flowunit, flowunit=mean, device=cpu, deviceid=0, mean="123.68,116.78,103.94",batch_size=8] classify_infer[type=flowunit, flowunit=classify_infer, device=cuda, deviceid="1",batch_size=16] output[type=output, device=cpu] input -> img_decoder:in_encoded_image img_decoder:out_image -> img_resize:in_image #input -> img_resize:in_image img_resize:out_image -> img_mean:in_data img_mean:out_data -> classify_infer:input classify_infer:"resnet_v1_101/predictions/Softmax" -> output } '''
組態檔撰寫后通過ModelBox Flow介面加載并運行:
def __init__(self) ... # modelbox self.flow = modelbox.Flow() self.flow.init("/home/code/image_classify/graph/image_classify.toml") self.flow.start_run()
b)通過代碼構建
通過FlowGraphDesc物件構建流程圖,并加載運行,
def __init__(self) ... # modelbox self.graph_desc = modelbox.FlowGraphDesc() self.graph_desc.set_drivers_dir(["/home/code/image_classify/classify_infer/"]) self.graph_desc.set_queue_size(64) self.graph_desc.set_batch_size(8) input = self.graph_desc.add_input("input") img_decoder = self.graph_desc.add_node("image_decoder", "cpu",input) img_resize = self.graph_desc.add_node("resize", "cpu", ["image_height=224", "image_width=224"],img_decoder) img_mean = self.graph_desc.add_node("mean", "cpu",["mean=123.68,116.78,103.94" ], img_resize) classify_infer = self.graph_desc.add_node("classify_infer", "cuda", ["batch_size=32"], img_mean) self.graph_desc.add_output("output", classify_infer) self.flow = modelbox.Flow() self.flow.init(self.graph_desc) self.flow.start_run()
需要說明的是,本業務需要優化的功能單元圖片解碼、resize、mean都是ModelBox預置功能單元,并且支持硬體加速,如果不在預置庫中時,可以通過功能單元注冊介面注冊為功能單元,
不管哪種方式,我們都可以通過配置調整每個功能單元的batch_size、queue_size、設備型別,設備ID等功能引數來調整執行策略,如通過設定device=cuda則指定改功能單元通過GPU加速,batch_size=8, 則表示一次處理8個資料,queue_size =32 ,則代表非功能單元會使用queue_size/batch_size = 4個執行緒同時并行計算,
2) 業務邏輯替換
將原有預處理和推理的代碼替換為ModelBox Flow的運行介面,
def process(self, img_file): # image = self.preprocess(img_file) # 對image進行推理,batch為1 # infer_output = self.sess.run(self.output,feed_dict={self.input: np.expand_dims( image,0 )}) # probabilities = infer_output[0, 0:] #modelbox stream_io = self.flow.create_stream_io() buffer = stream_io.create_buffer(img_file) stream_io.send("input", buffer) output_buffer = stream_io.recv("output") probabilities = np.array(output_buffer) ... self.postprocess(probabilities, resp)
send()輸入引數說明: 圖的輸入埠名稱,輸入buffer
recv()輸出引數說明: output: 圖的輸出buffer
至此,預處理加推理的優化代碼已修改完畢,進行功能除錯后,即可對性能進行測驗,同樣可以通過ModelBox 性能Profiling工具進行性能分析,我們分別設定預處理全為cpu、 預處理全為gpu進行性能測驗,測驗結果如下:
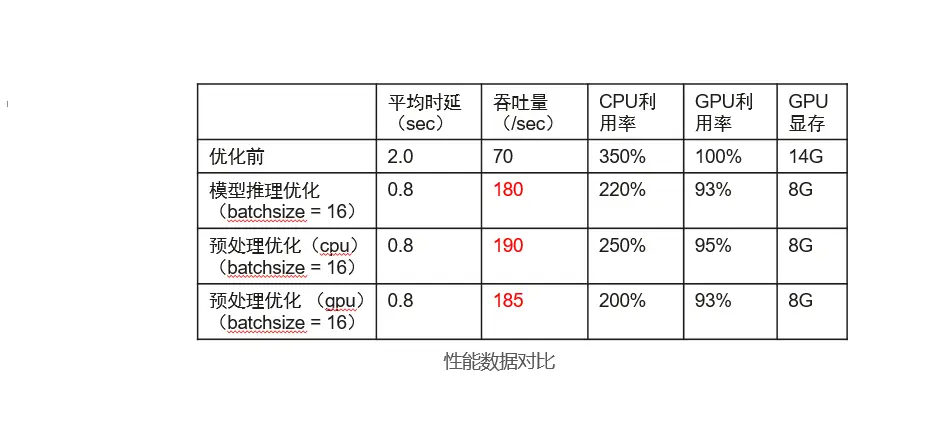
可以看到同為batchsize為16時,通過預處理性能較純模型推理優化性能有提升,同時全為cpu預處理時反而比gpu預處理性能好,這是因為一方面cpu預處理采用了多執行緒并發處理,另一方面GPU預處理搶占了GPU資源,影響了推理速度,從而影響整體性能,所以并不推薦所有操作都使用硬體加速,需要具體場景具體分析,保證資源計算的合理分配,
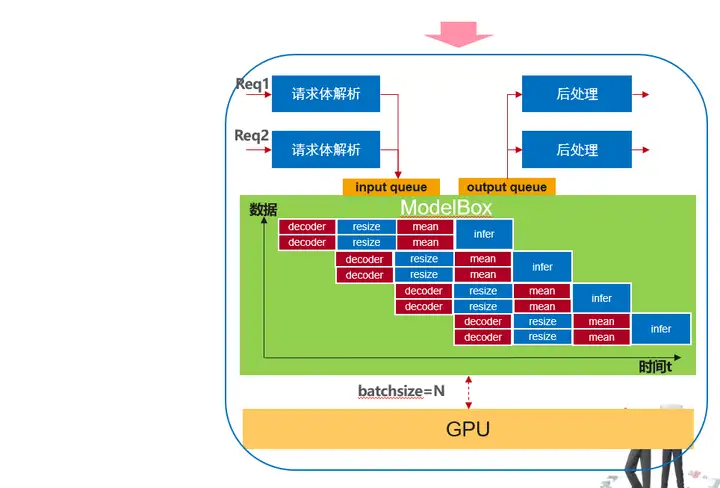
通過ModelBox優化后的資料執行情況如上,優化收益主要如下:
1、流程圖每個節點都是獨立執行緒執行,多個資料通過pipeline并行
2、除推理功能單元外,其他cpu預處理采用多執行緒執行,每個功能單元執行緒數可以靈活配置
3、不僅推理,其他功能單元的執行也可以是采用多硬體異構加速
AI應用的性能優化是一個循序漸進的程序,并不是所有方法都有效,開發者需要結果自身業務具體問題具體分析,才能到達事半功倍的效果,經過實際業務的優化實踐,希望大家對如果使用ModeBox框架優化AI應用性能有一些初步了解,同時也能理解優化原理,如果對ModelBox感興趣可以進入ModelBox官網詳細了解,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/534165.html
標籤:其他
上一篇:沒事練練題二