本文為學習筆記
參與:王博kings,Sophia
最近結束的CVPR 2020在推動物體檢測方面做出了巨大貢獻,在本文中,我們將介紹一些特別令人印象深刻的論文,
1、A Hierarchical Graph Network for 3D Object Detection on Point Clouds(用于點云3D目標檢測的分層圖網路)
HGNet包含三個主要組件:
- 基于GConv的U形網路(GU-net)
- 提案生成者
- 提案推理模塊(ProRe Module)-使用完全連接的圖對提案進行推理
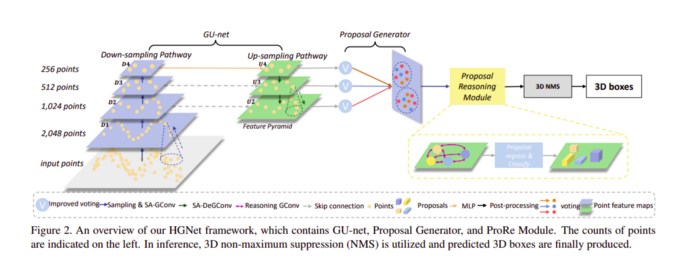
作者提出了一種注重形狀的GConv(SA-GConv),以捕獲區域形狀特征,這是通過對相對幾何位置進行建模以描述物件形狀來完成的,
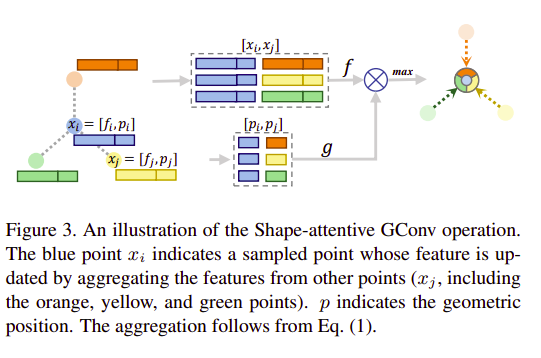
基于SA-GConv的U型網路可捕獲多級功能,然后將它們通過投票模塊映射到相同的特征空間,并用于生成建議,下一步,基于GConv的提案推理模塊使用提案來預測邊界框,
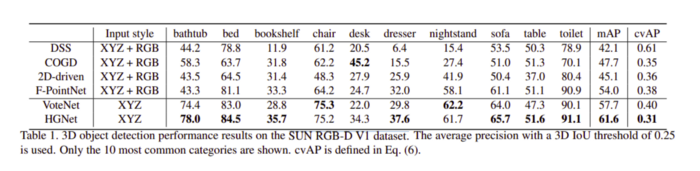
以下是在SUN RGB-D V1資料集上獲得的一些性能結果,
2、HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection(HVNet:基于激光雷達的三維物體檢測的混合體素網路)
在本文中,作者提出了混合體素網路(HVNet),這是一個用于基于點云的3D物件檢測自動駕駛的一級網路,

本文中使用的體素特征編碼(VFE)方法包含三個步驟:
- 體素化—將點云分配給2D體素網格
- 體素特征提取-計算與網格相關的逐點特征,該點特征被饋送到PointNet樣式特征編碼器
- 投影-將逐點特征聚合到體素級特征并將其投影到其原始網格,這形成偽影像特征圖
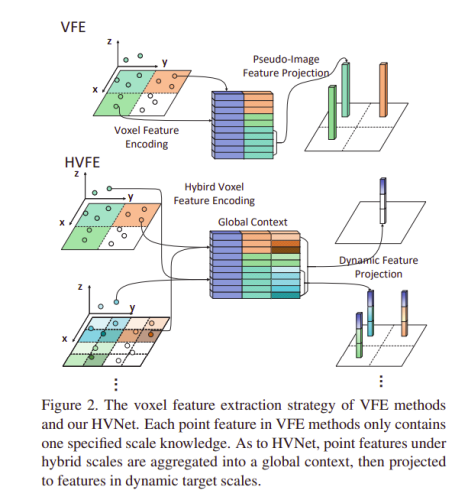
體素的大小在VFE方法中非常重要,較小的體素尺寸可以捕獲更精細的幾何特征,它們也更擅長物件本地化,但推理時間更長,使用較粗的體素可以獲得更快的推理速度,因為這會導致較小的特征圖,但是,它的性能較差,
作者提出了混合體素網路(HVNet),以實作細粒度體素功能的利用,它由三個步驟組成:
- 多尺度體素化-創建一組特征體素尺度并將它們分配給多個體素,
- 混合體素特征提取-計算每個比例的體素相關特征,并將其輸入到關注特征編碼器(AVFE)中,每個體素比例尺上的要素都是逐點連接的,
- 動態要素投影-通過創建一組多比例專案體素將要素投影回偽影像,
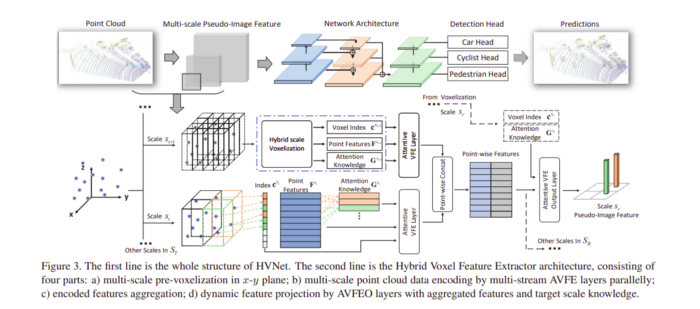
這是在KITTI資料集上獲得的結果,
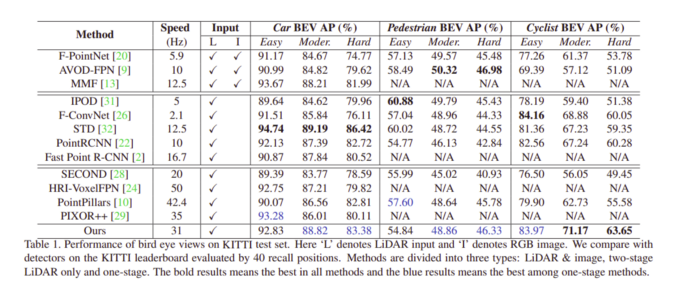
3、Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud(Point-GNN:用于點云中3D物件檢測的圖神經網路)
本文的作者提出了一種圖神經網路-Point-GNN-從LiDAR點云中檢測物體,網路預測圖形中每個頂點所屬的物件的類別和形狀,Point-GNN具有自動回歸機制,可以一次檢測多個物體,
所提出的方法包括三個部分:
- 圖形構建:體素降采樣點云用于圖形構建
- T迭代的圖神經網路
- 邊界框合并和評分
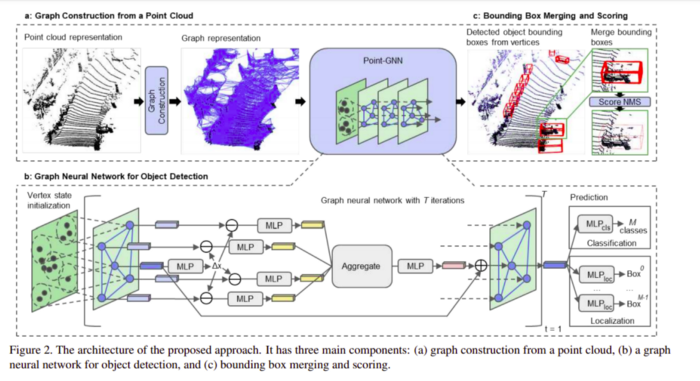
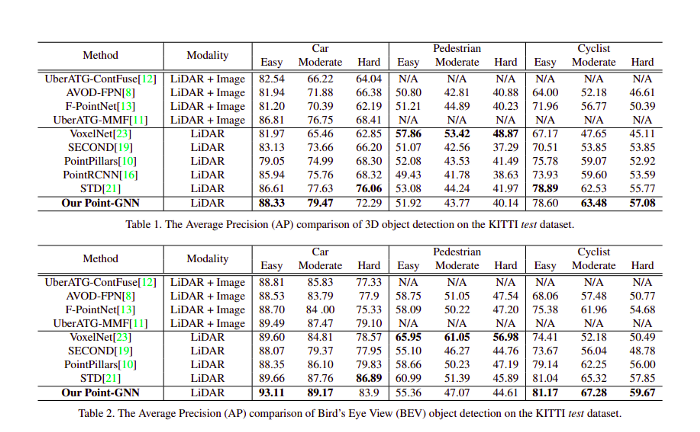
以下是在KITTI資料集上獲得的結果:
代碼:https://github.com/WeijingShi/Point-GNN
4、Camouflaged Object Detection
本文解決了檢測嵌入在其周圍環境中的物體的挑戰-偽裝物體檢測(COD),作者還介紹了一個名為COD10K的新資料集,它包含10,000張影像,覆寫許多自然場景中的偽裝物體,它具有78個物件類別,影像帶有類別標簽,邊界框,實體級別和消光級別的標簽注釋,


作者開發了一種稱為搜索標識網路(SINet)的COD框架,該代碼在這里可用:
https://github.com/DengPingFan/SINet/
網路有兩個主要模塊:
- 搜索模塊(SM),用于搜索偽裝的物體
- 用于檢測物體的識別模塊(IM)

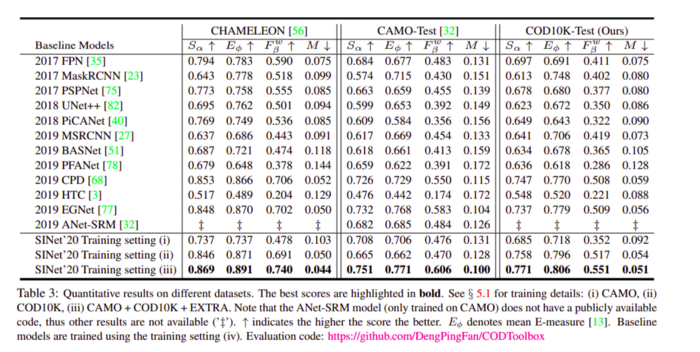
以下是在各種資料集上獲得的結果:
5、Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
本文提出了一個短時目標檢測網路,該網路的目標是檢測不可見類別的目標,并帶有一些注釋示例,
他們的方法包括注意RPN,多重關系檢測器和對比訓練策略,該方法利用少拍支持集和查詢集之間的相似性來標識新物件,同時還減少了錯誤標識,作者還貢獻了一個新的資料集,其中包含1000個類別,這些類別的物件具有高質量的注釋,https://github.com/fanq15/Few-Shot-Object-Detection-Dataset
該網路體系結構由一個權重共享框架組成,該框架具有多個分支-一個分支是查詢集,其余分支用于支持集,權重共享框架的查詢分支是Faster R-CNN網路,
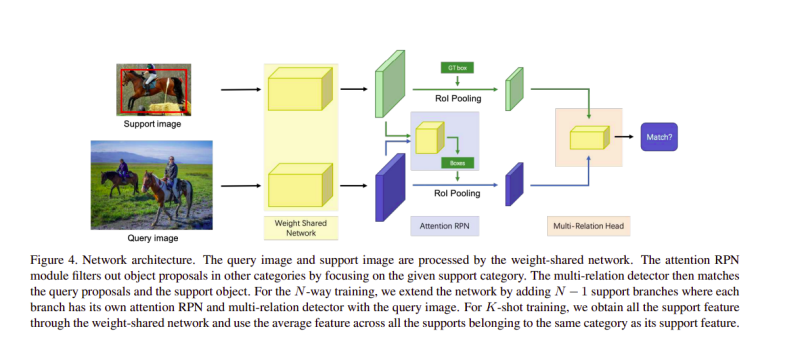
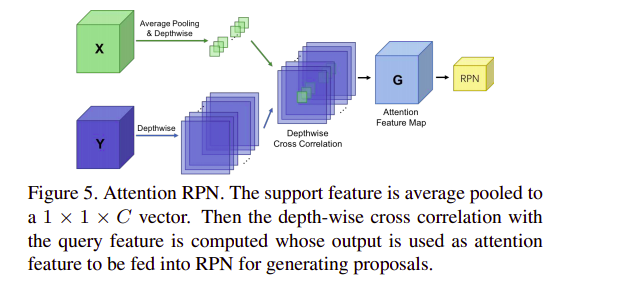
作者介紹了帶有多關系模塊的注意力RPN和檢測器,以在支持和查詢中的潛在框之間產生準確的決議,
以下是在ImageNet資料集上獲得的一些結果,

以下是在許多資料集上獲得的一些觀察結果,

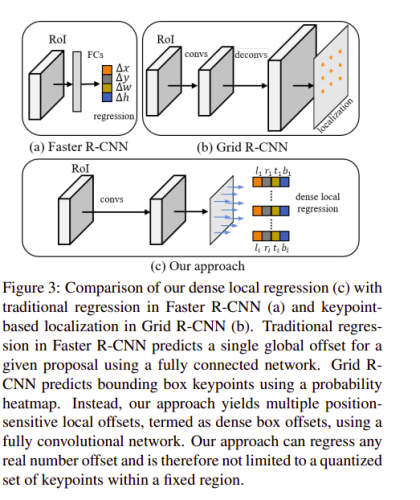
6、D2Det: Towards High-Quality Object Detection and Instance Segmentation
本文的作者提出了D2Det,一種解決精確定位和精確分類的方法,他們引入了密集區域回歸,可以預測物件提案的多個密集框偏移,這使他們能夠實作精確的定位,
作者還介紹了區分RoI池方案,以實作準確的分類,合并方案從提案的幾個子區域進行采樣,并執行自適應加權以獲得區別特征,
該代碼位于:https://github.com/JialeCao001/D2Det
該方法基于標準的Faster R-CNN框架,在這種方法中,Faster R-CNN的傳統盒偏移回歸被提議的密集區域回歸所替代,在該方法中,通過判別式RoI池增強了分類,
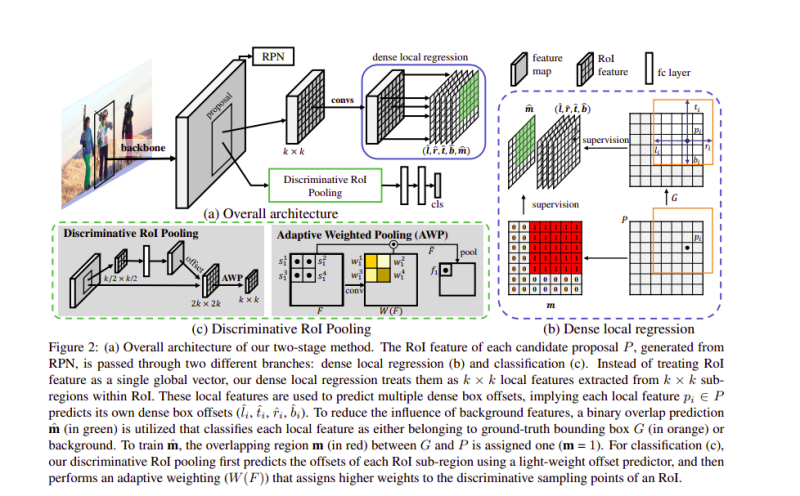
在兩階段方法中,第一階段使用區域提議網路(RPN),第二階段使用單獨的分類和回歸分支,分類分支基于判別池,區域回歸分支的目標是物件的精確定位,
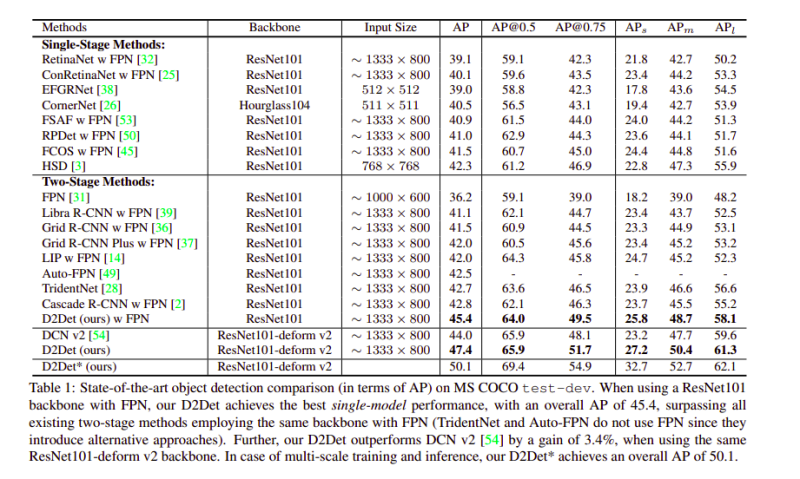
以下是在MS COCO資料集上獲得的結果:
鏈接:https://heartbeat.fritz.ai/cvpr-2020-the-top-object-detection-papers-f920a6e41233
編輯:Sophia | 王博(Kings)筆記
計算機視覺聯盟 報道 | 公眾號 CVLianMeng
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5347.html
標籤:其他
下一篇:yolov5 簡單教程