機器學習的專業術語非常多,不需要一開始理解所有的專業術語,這些術語會隨著對機器學習的深入,會慢慢理解,水到渠成,
不過在學習的程序中,有一些概念必須要了解,有助于后續的學習與理解,需要了解的核心概念有:監督學習、無監督學習、模型、策略、演算法等,
監督學習
監督學習,指的是學習的資料與后續測驗的資料,都有答案(標簽),
比如說,我們自己的相片集,里面每個人我們都知道是誰并可以標識出來,給機器學習時,我們將每個單人照和對應的名字提交給機器學習模型,機器學習模型完成學習以后,我們繼續提交新的相片(單人或多人的),模型直接輸出照片中每個人的名字,而對這類有標準答案的資料集的學習,就是有監督學習,
監督學習主要用來處理分類與回歸兩類問題,
- 分類:比如前面對相片的學習,輸出的是相片中人物對應的名字標簽,這個名字標簽可以理解為分類的類別名稱,百香果的酸與甜、人的性別男與女等這些離散的類別,都是機器學習中分類演算法處理的目標,
- 回歸:回歸類演算法主要是用來預測連續值的變化,比如預測一個人作業年限與收入的變化;網站每日訪問量(PV值)變化;廣告投放與新增用戶、消費(充值)的關系變化等等,這類資料型別的增減變化,就是回歸演算法預測的目標,
監督學習常用演算法包括:K最近鄰演算法、樸素貝葉斯演算法、線性回歸演算法、邏輯回歸演算法、決策樹演算法、神經網路演算法、支持向量機演算法、因子分解機演算法等
無監督學習
無監督學習,指的是通過對資料的統計、分析、分類等方法處理后,從中發現資料本身的自有規律,從而提取出對應的類別、知識或模型的學習方法,可以簡單理解為,資料沒有標準答案,甚至我們都不知道里面的答案,只知道有一堆資料,需要運行演算法自動對這些資料進行各種分類處理,幫助我們找出規律(分類類別)的程序,
無監督學習主要概念:
- 聚類:在無監督學習中,將資料集分成由類似的物件組成多個類的程序稱為聚類,
比如DNA,每個個體都有相似與獨特的地方,想要了解DNA中每個基因的作用,就可以使用無監督學習進行學習與分析,將具有不同型別或特特征的人聚集到一塊,然后根據通過對這些人的共同點進行分析,從而得出特定基因的作用,同樣,無監督學習可以應用到廣告系統、推薦系統、新聞分類等各類系統中,面對海量的資料,從中找出不同的型別特征,幫助我們更快速的找到資料的特征與共性,從而讓資料發揮更多更重要的作用,
無監督學習常用演算法包括:K均值演算法、最大期望演算法、感知機演算法、主成分分析演算法、奇異值分解演算法等,
半監督學習
半監督學習是監督學習與監督學習結合的一種方法,指的是將有標簽資料和無標簽資料一起提供模型學習的方法,
我們都知道人力成本是最貴的,如果需要對資料都打上標簽,所花費的人工成本與時間成本是很可觀的,況且有些資料我們也不清楚它們的規律無法添加標簽,而半監督學習,可以將已知的有價值的資料先打上標簽,跟無標簽資料一起給機器進行學習,機器訓練并輸出結果,我們可對結果打上新的簽標后繼續提供給機器訓練,從而提升預測結果,當然,如果標簽標記不準確,也可能會誤導訓練模型,得出錯誤的結論,
無監督學習常用演算法包括:協同訓練演算法(Co-Training)和轉導支持向量機演算法,
機器學習的三要素:模型、策略和演算法
機器學習由模型、策略和演算法組成,模型用于作出決策,策略用于評價決策,演算法用于修正模型,
模型
簡單的理解,指的是模子,
百度百科有兩個解釋我覺得很貼切:
- 人們依據研究的特定目的,在一定的假設條件下,再現原型(antetype)客體的結構、功能、屬性、關系、程序等本質特征的物質形式或思維形式,
- 對研究的物體進行必要的簡化,并用適當的變現形式或規則把它的主要特征描述出來,所得到的系統模仿品稱之為模型,
機器學習中的模型,就是為了預測和分析指定的目標,運行已知的策略和演算法,所構建的學習統計模型,通過對資料的學習(統計分析和找出其概率分布規律),最終能對目標進行準確預測,
策略
在百度百科中解釋為:
策略,指計策;謀略,一般是指可以實作目標的方案集合;根據形勢發展而制定的行動方針和斗爭方法.
在機器學習中的策略,指的是實作模型方案集合的最優解,要實作同一個目標(模型),有無數種解決方案,而不同的解決方案各有優劣,在監督學習中引入了損失函式,來找出最優化的模型,
演算法
在百度百科中解釋為:
演算法(Algorithm)是指解題方案的準確而完整的描述,是一系列解決問題的清晰指令,演算法代表著用系統的方法描述解決問題的策略機制,
演算法簡單理解,就是計算方法,在機器學習中,用什么樣的計算方法,來幫助機器學習模型和策略,快速、高效、準確的計算出結果,在海量的資料與幾何級復雜度的資料中,找出資料分布規律和概率,也是相當困難的,而機器學習演算法模型中,提供了梯度下降、降維等演算法,來求解出最優解,減少過擬合等各種問題,
演算法專案的兩個脈絡
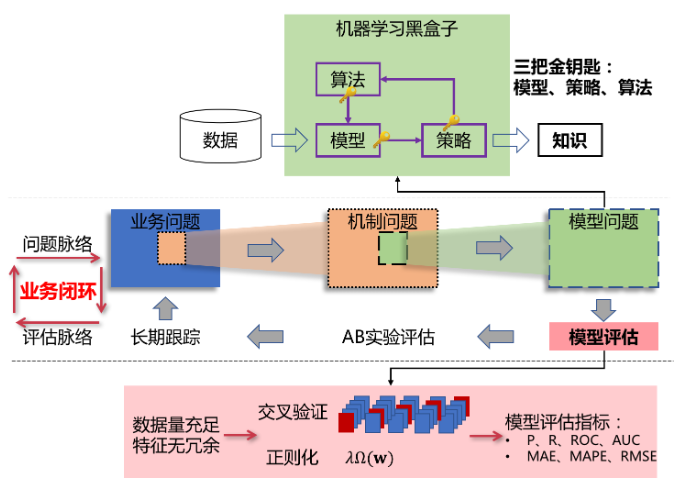
(圖片來自:https://www.imooc.com/read/50/article/974)
問題線:業務問題 -> 機制問題 -> 模型問題
評估線:長期跟蹤 <- AB實驗 <- 模型評估
演算法工程師對模型直接負責,對整個專案要有大局觀
專案 -> 解決業務問題
例如:業務運營部門希望提升業務收入業務問題 -> 分析拆解,找出關鍵指標 -> 得到解決方案(公式)-> 確定可控與不可控因素
指標1:提升新增用戶量 = 渠道數 * 廣告曝光量 * 用戶轉化比率 = 加大渠道投入 可控因素:渠道數量與廣告曝光量(廣告費) 不可控因素:用戶轉化比率 待分析問題:各渠道用戶轉化率差別?渠道推廣投入的產出比盈虧狀況?廣告投放精準度與效果如何確認?相同渠道不同時間段投放廣告,用戶轉化率變化?不同渠道同一時間段投放廣告用戶轉化率有什么不同?視頻廣告與圖文廣告對用戶轉化率的影響?不同版本以及這些版本例外報告數量對用戶轉化率的影響?不同品牌用戶轉化率?不同機型用戶轉化率?是否存在刷量問題(新增用戶的IP、機型、活躍變化、留存變化、在線時長、用戶行為漏斗分析、充值轉化比率……等問題的監控)?……指標2:提升用戶留存指標3:提升用戶充值比例……不可控因素 -> 如何變為可控?-> 建立機器學習預測分析模型 -> 什么演算法模型適合當前問題?怎么設計和得出演算法公式?為什么這個模型能對資料進行預測?
建立機器學習模型 -> 模型預測準確性?-> 演算法層是否正確,對模型進行綜合評估,確定預測模型正確率指標 -> 開展AB實驗進行驗證 -> 通過同比、環比等多項指標,評估推薦結果正確性 -> 全量推廣,長期跟蹤效果
參考資料
https://github.com/apachecn/AiLearning/blob/master/docs/ml/1.機器學習基礎.md
http://ai-start.com/ml2014/html/week1.html
https://feisky.xyz/machine-learning/basic.html
https://github.com/apachecn/scipycon-2018-sklearn-tut-zh/blob/master/1.md
https://github.com/apachecn/ml-for-humans-zh/blob/master/3.md
https://www.imooc.com/read/50/article/974
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53510.html
標籤:其他