
?? 作者:韓信子@ShowMeAI
?? 機器學習實戰系列:https://www.showmeai.tech/tutorials/41
?? 本文地址:https://www.showmeai.tech/article-detail/330
?? 宣告:著作權所有,轉載請聯系平臺與作者并注明出處
?? 收藏ShowMeAI查看更多精彩內容

現在的互聯網平臺都有著海量的客戶,但客戶和客戶之間有很大的差異,了解客戶的行為方式對于充分理解用戶與優化服務增強業務至關重要,而借助機器學習,我們可以實作更精細化地運營,具體來說,我們可以預測客戶價值,即在特定時間段內將為公司帶來多少價值,
本篇內容中使用的 ??scanner在線交易資料集,可以直接在 ShowMeAI的百度網盤中下載獲取,
?? 實戰資料集下載(百度網盤):公?眾?號『ShowMeAI研究中心』回復『實戰』,或者點擊 這里 獲取本文 [26] 基于機器學習的客戶價值預估 『scanner在線交易資料集』
? ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub

本篇內容中我們的實作步驟包括:
- 整合&處理資料
- 基于遞回 RFM 技術從資料構建有效特征
- 基于資料建模與預估
?? 整合&處理資料
?? 資料說明
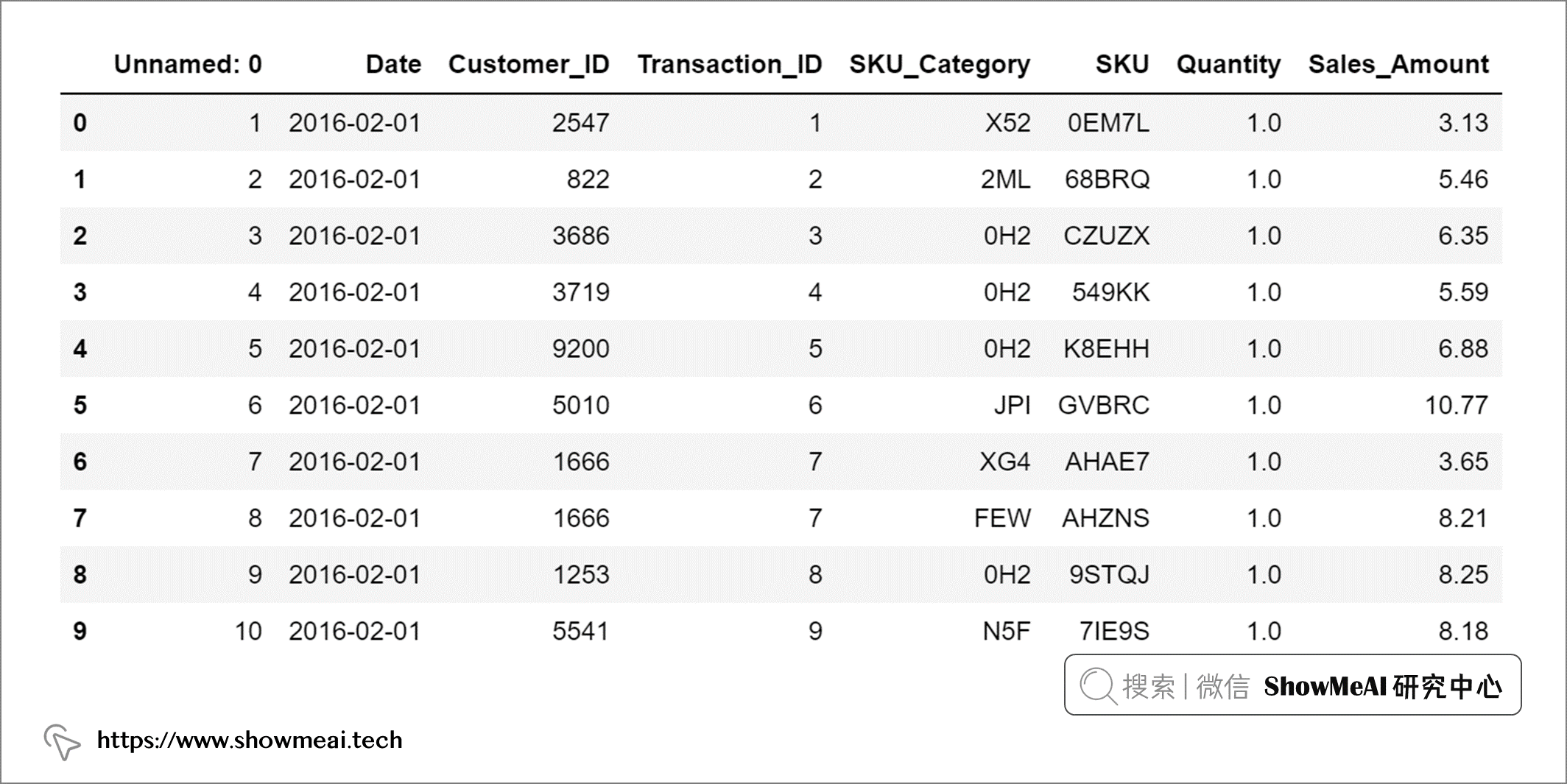
ShowMeAI本篇使用到的資料集,是通過零售店『掃描』商品條形碼而獲得的流水銷售的詳細資料,資料集覆寫一年時間,涵蓋 22625 個顧客、5242 個商品、64682 次交易,資料欄位說明如下:
| 欄位 | 含義 |
|---|---|
| Date | 銷售交易的日期 |
| Customer_ID | 客戶ID |
| Transaction_ID | 交易ID |
| SKU_Category_ID | 商品類別ID |
| SKU_ID | 商品ID |
| Quantity | 銷售數量 |
| Sales_Amount | 銷售金額(單價乘以數量) |
?? 資料讀取 & 處理
本文資料處理部分涉及的工具庫,大家可以參考ShowMeAI制作的工具庫速查表和教程進行學習和快速使用,
??資料科學工具庫速查表 | Pandas 速查表
??圖解資料分析:從入門到精通系列教程
上述資訊中最重要的3列是:客戶ID、銷售交易的日期、銷售金額,當然大家也可以在后續建模中囊括更多的豐富資訊(如商品類別等),這里我們先讀取資料并針對時間欄位做一點格式轉換,
import pandas as pd
# 讀取CSV格式交易資料
df = pd.read_csv(data_path) # 資料路徑
# 日期型資料轉換
df.Date = pd.to_datetime(df.Date)
df.head(10)
?? RFM & 特征工程
關于機器學習特征工程,大家可以參考 ShowMeAI 整理的特征工程最全解讀教程,
??機器學習實戰 | 機器學習特征工程最全解讀
?? RFM介紹
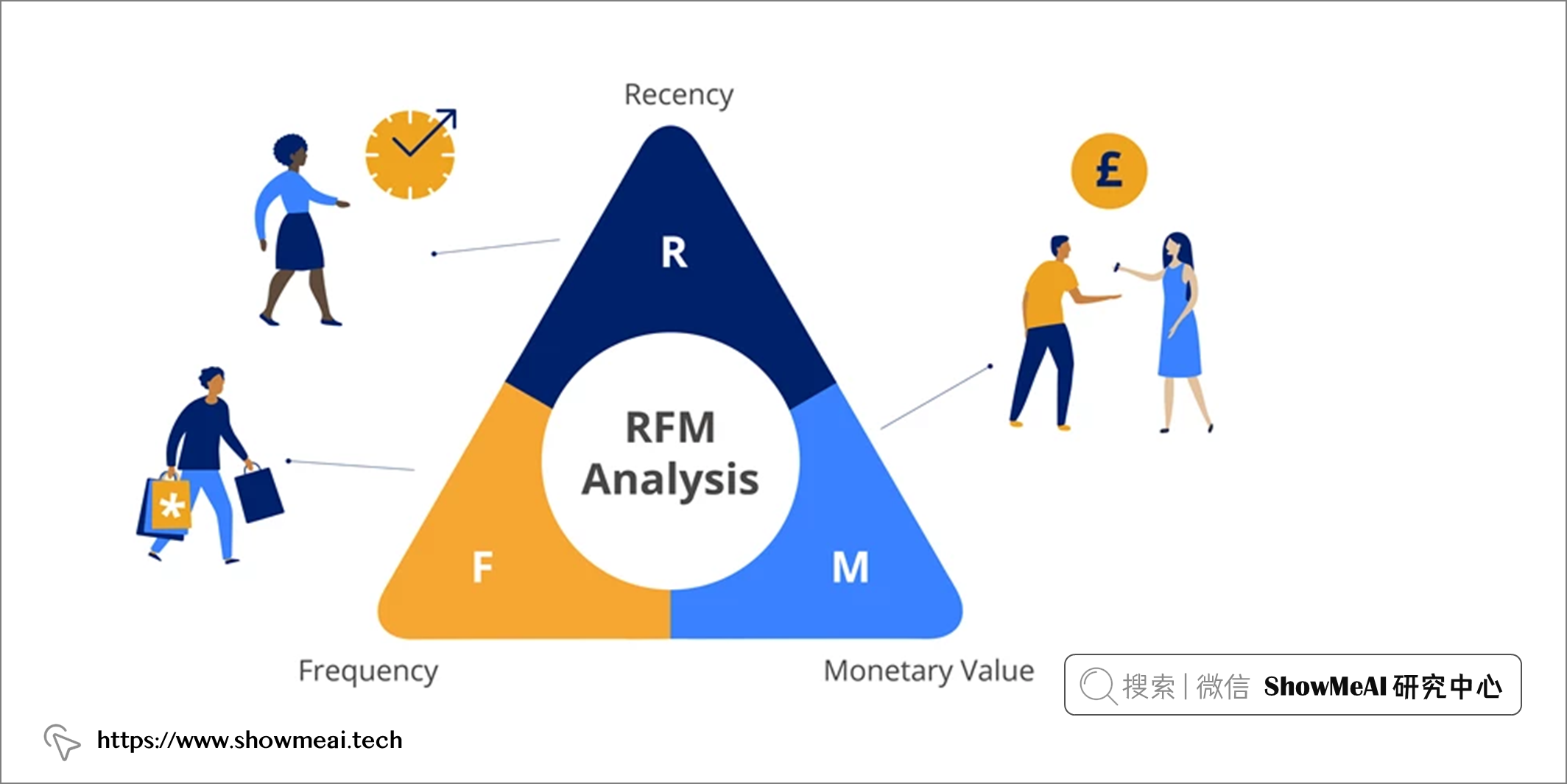
??RFM 是一種量化客戶價值的方法,英文全稱為『Recency, Frequency and Monetary value』,RFM 模型的三個引數分別是 R(最近一次消費的時間間隔)、F(消費的頻率)和 M(消費金額),
RFM的使用方法是,將訓練資料分成觀察期 Observed 和未來期 Future, 如果我們要預測客戶一年內會花費多少,就將未來期 Future的長度設定為一年,如下圖所示:
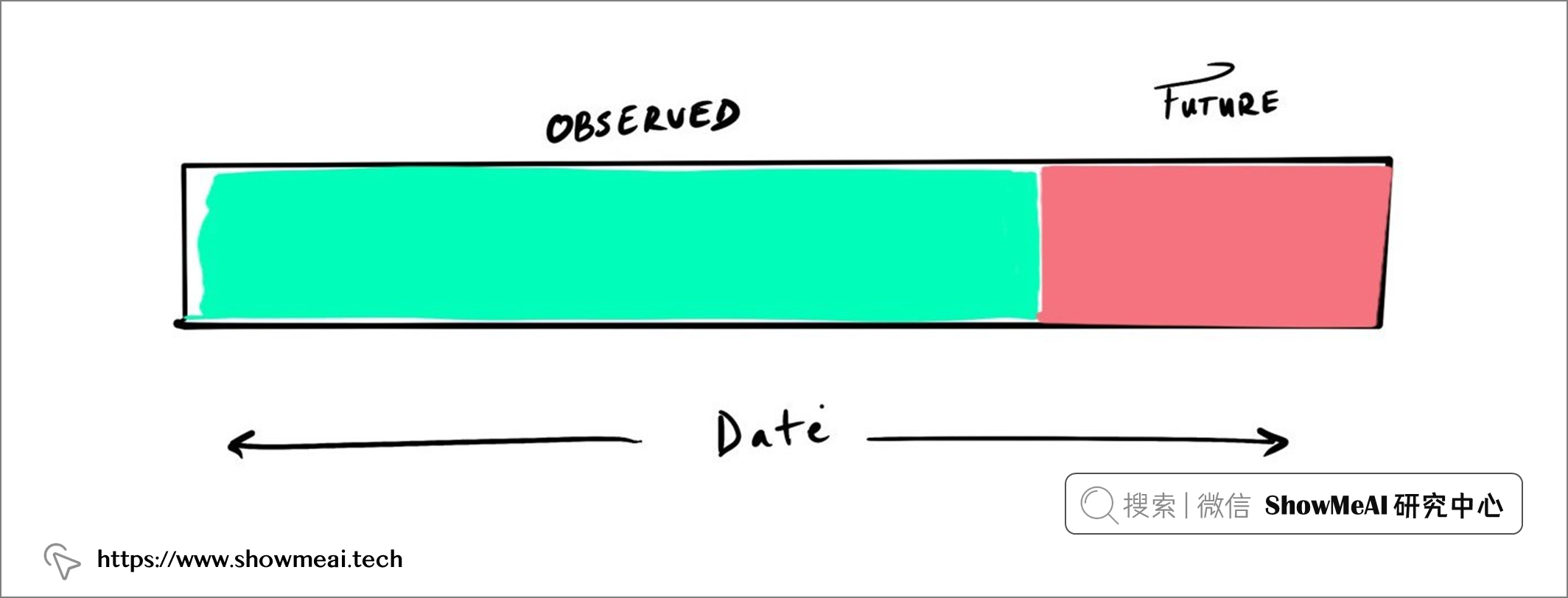
基于觀察期的資料特征建模,并預測未來期的情況,下述代碼我們基于日期進行截斷:
# 截斷日期前的資料
observed = df[df[date_col] < cut_off
# 截斷日期后的資料
future = df [(df[date_col] > cut_off) & (df[date_col] < cut_off + pd.Timedelta(label_period_days, unit='D'))]
下面我們來看看 RFM 的3要素,并通過代碼進行實作:
?? Recency / 時間間隔
它代表自最近一次交易以來的時間(小時/天/周), 我們需要設定一個基準時間點來計算 Recency, 我們會計算客戶在基準時間點后多少天進行了交易,
def customer_recency(data, cut_off, date_column, customer_id_column):
# 截斷前的資料
recency = data[data[date_column] < cut_off].copy()
recency[date_column] = pd.to_datetime(recency[date_column])
# 按最新交易對客戶進行分組
recency = recency.groupby(customer_id_column)[date_column].max()
return ((pd.to_datetime(cut_off) - recency).dt.days).reset_index().rename(
columns={date_column : 'recency'}
)
?? Frequency / 頻率
它代表客戶進行交易的不同時間段的數量, 這將使我們能夠跟蹤客戶進行了多少交易以及交易發生的時間, 我們還可以保留從截止日期開始計算這些指標的做法,因為以后會很方便,
def customer_frequency(data, cut_off, date_column, customer_id_column, value_column, freq='M'):
# 截斷前的資料
frequency = data[data[date_column] < cut_off].copy()
# 設定日期列為索引
frequency.set_index(date_column, inplace=True)
frequency.index = pd.DatetimeIndex(frequency.index)
# 按客戶鍵和不同時期對交易進行分組
# 并統計每個時期的交易
frequency = frequency.groupby([
customer_id_column,
pd.Grouper(freq=freq, level=date_column)
]).count()
frequency[value_column] = 1 # 存盤所有不同的交易
# 統計匯總所有交易
return frequency.groupby(customer_id_column).sum().reset_index().rename(
columns={value_column : 'frequency'}
)
?? Monetary value / 消費金額
它代表平均銷售額, 在這里我們可以簡單計算每個客戶所有交易的平均銷售額, (當然,我們后續也會用到)
def customer_value(data, cut_off, date_column, customer_id_column, value_column):
value = https://www.cnblogs.com/showmeai/archive/2022/11/16/data[data[date_column] < cut_off]
# 設定日期列為索引
value.set_index(date_column, inplace=True)
value.index = pd.DatetimeIndex(value.index)
# 獲取每個客戶的平均或總銷售額
return value.groupby(customer_id_column)[value_column].mean().reset_index().rename(
columns={value_column :'value'}
)
?? 附加資訊
用戶齡: 自第一次交易以來的時間,我們把每個客戶首次交易以來的天數也加到資訊中,
def customer_age(data, cut_off, date_column, customer_id_column):
age = data[data[date_column] < cut_off]
# 獲取第一筆交易的日期
first_purchase = age.groupby(customer_id_column)[date_column].min().reset_index()
# 獲取截止到第一次交易之間的天數
first_purchase['age'] = (cut_off - first_purchase[date_column]).dt.days
return first_purchase[[customer_id_column, 'age']]
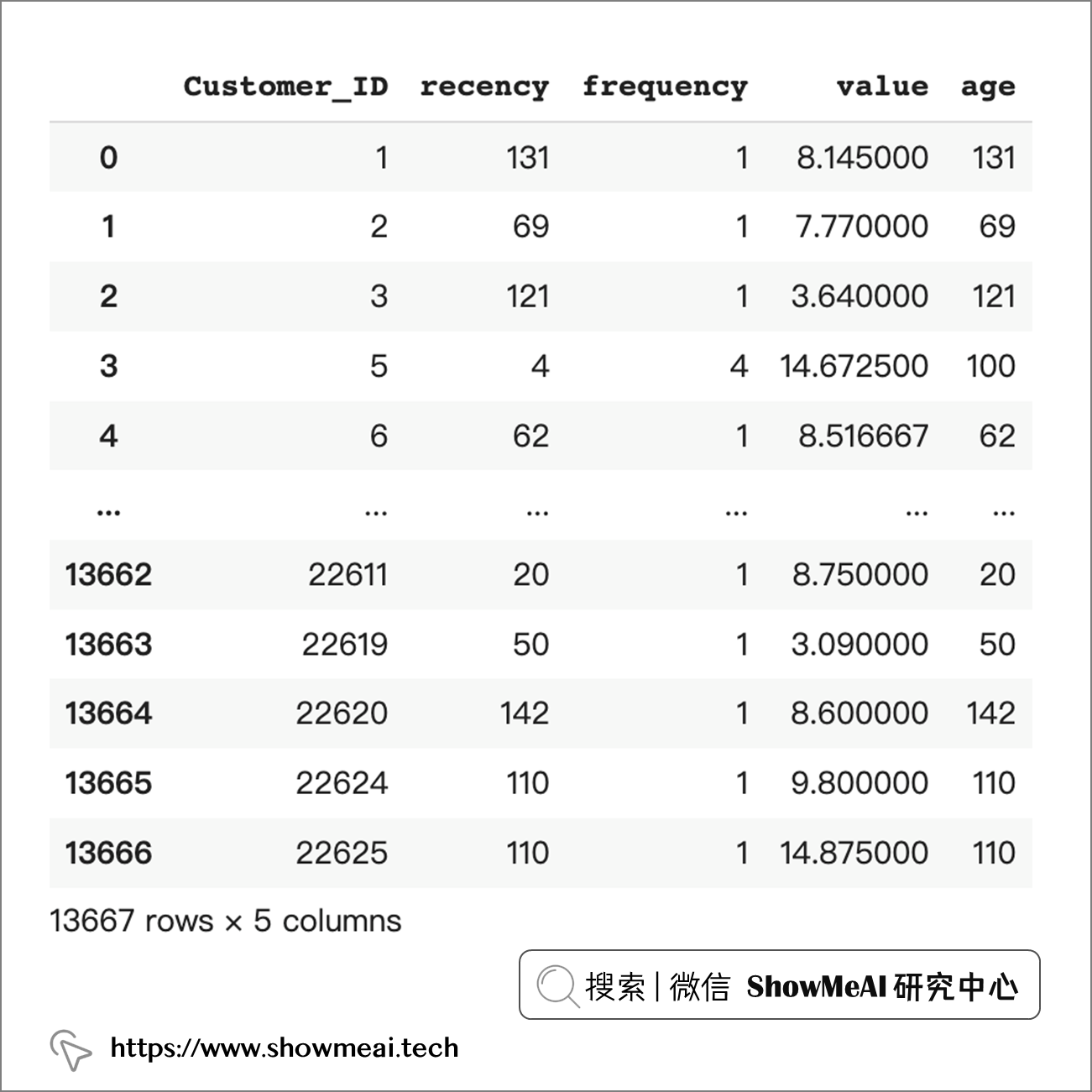
最后我們定義一個函式把 RFM 涉及到的資訊囊括進去:
def customer_rfm(data, cut_off, date_column, customer_id_column, value_column, freq='M'):
cut_off = pd.to_datetime(cut_off)
# 計算
recency = customer_recency(data, cut_off, date_column, customer_id_column)
# 計算頻率
frequency = customer_frequency(data, cut_off, date_column, customer_id_column, value_column, freq=freq)
# 計算平均值
value = https://www.cnblogs.com/showmeai/archive/2022/11/16/customer_value(data, cut_off, date_column, customer_id_column, value_column) # 計算年齡
age = customer_age(data, cut_off, date_column, customer_id_column)
# 合并所有列
return recency.merge(frequency, on=customer_id_column).merge(on=customer_id_column).merge(age,on=customer_id_column)
理想情況下,這可以捕獲特定時間段內的資訊,看起來像下面這樣:
我們把每個客戶未來期間花費的金額作為標簽(即我們截斷資料的后面一部分,即future),
labels = future.groupby(id_col)[value_col].sum()
?? 建模思路 & 實作
通過上面的方式我們就構建出了資料樣本,但每個用戶只有1個樣本,如果我們希望有更多的資料樣本,以及在樣本中囊括不同的情況(例如時間段覆寫節假日和 618 和 11.11 等特殊促銷活動),我們需要使用到『遞回RFM』方法,
?? 遞回 RFM
所謂的遞回 RFM 相當于以滑動視窗的方式來把未來不同的時間段構建為 future 標簽,如下圖所示,假設資料從年初(最左側)開始,我們選擇一個頻率(例如,一個月)遍歷資料集構建未來 (f) 標簽,也即下圖的紅色 f 塊,
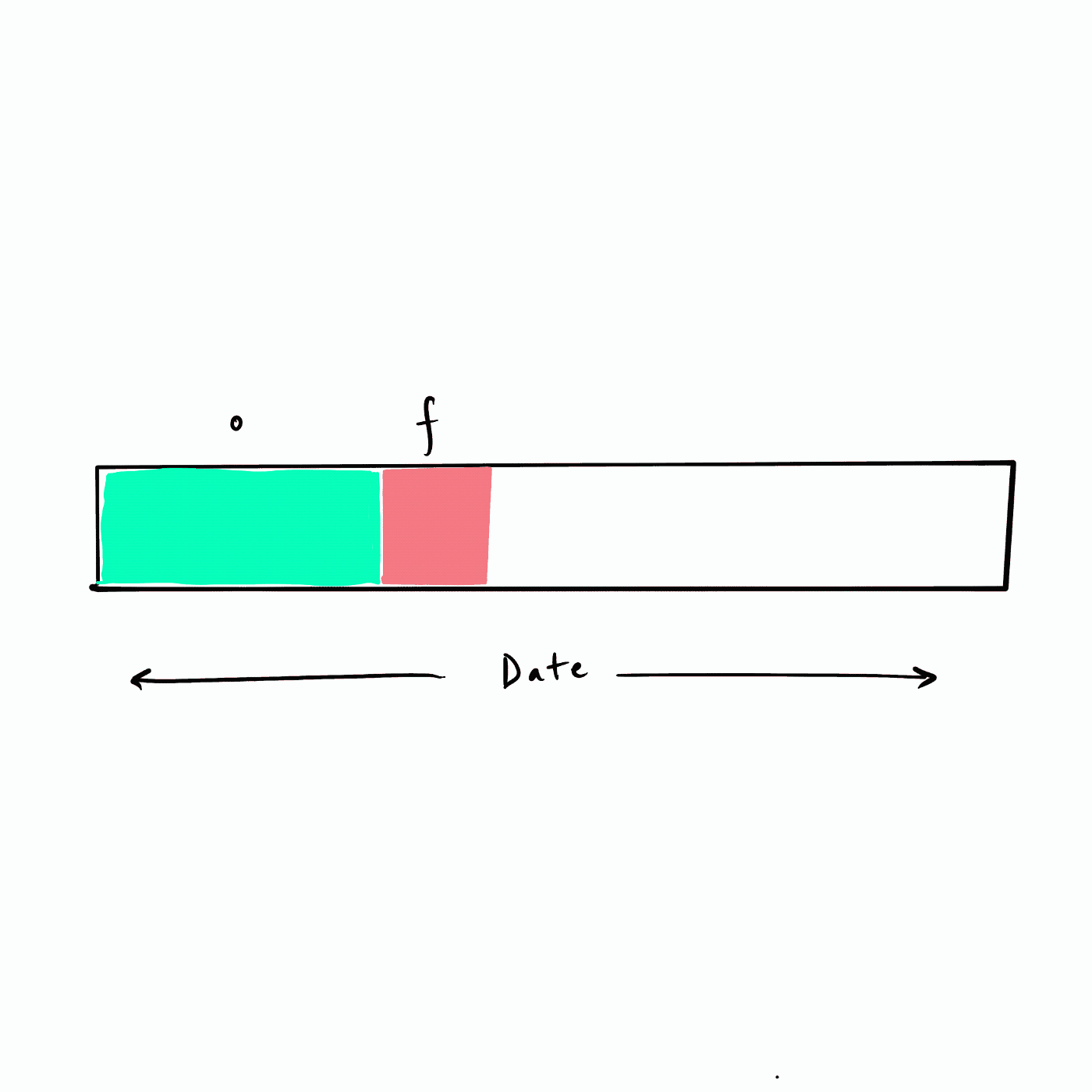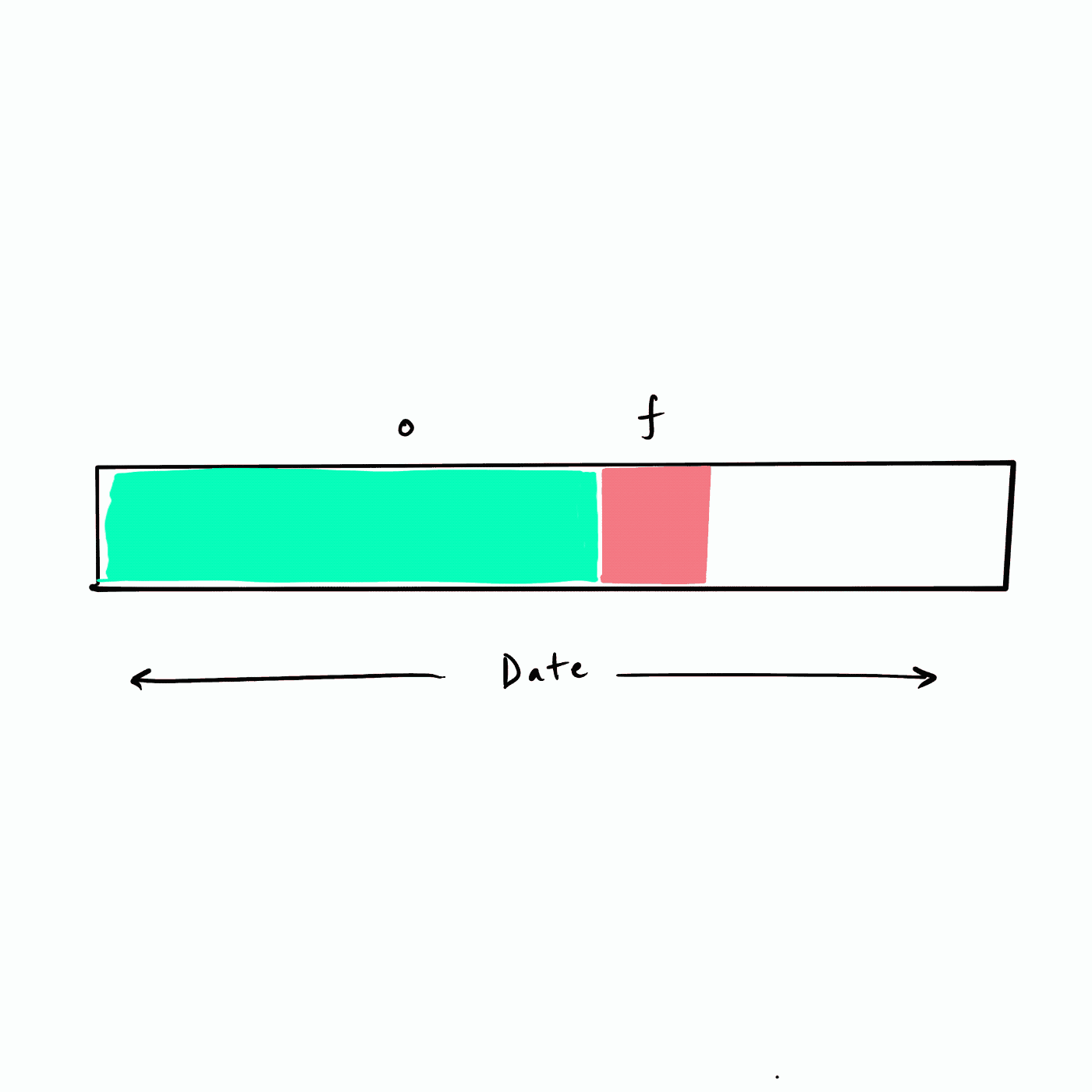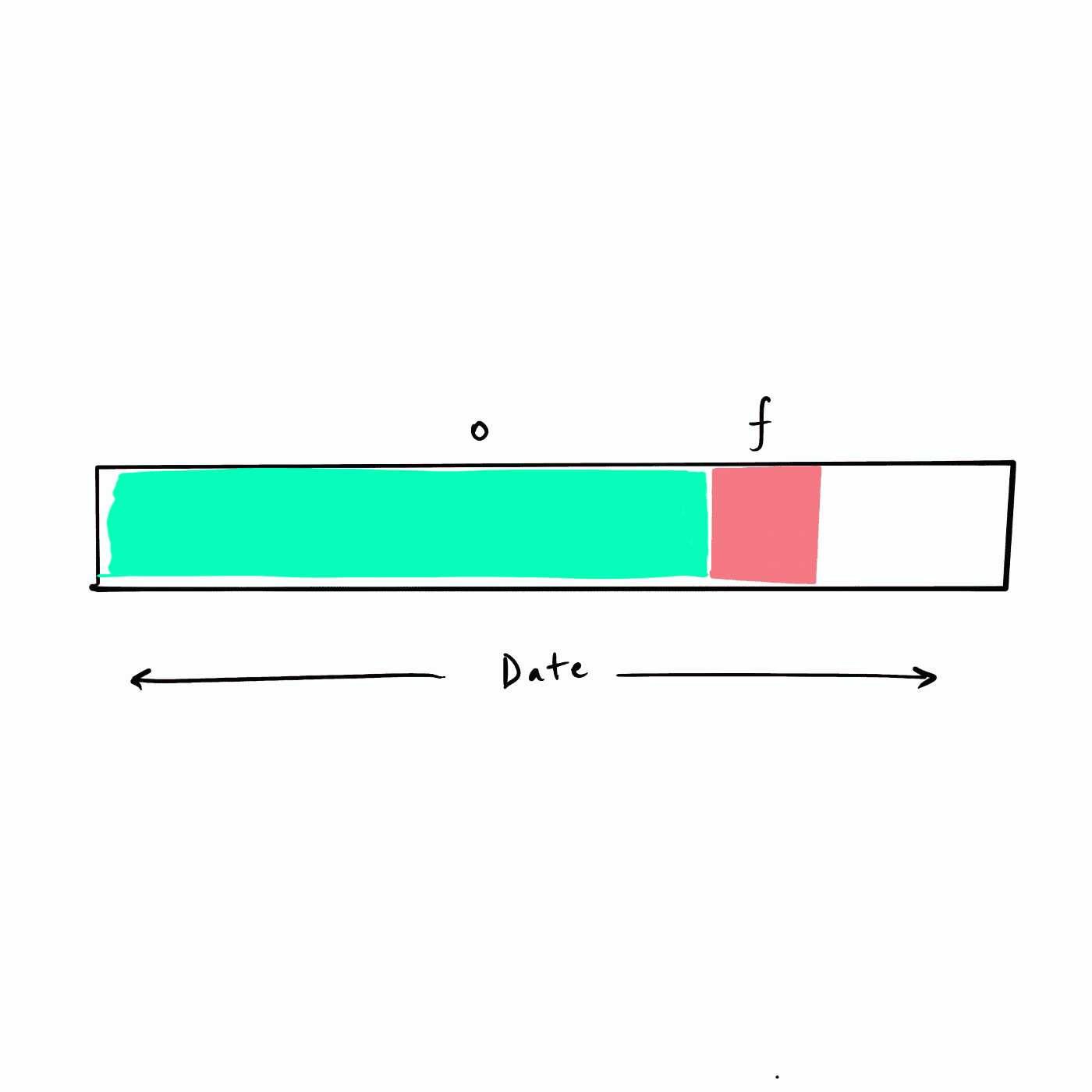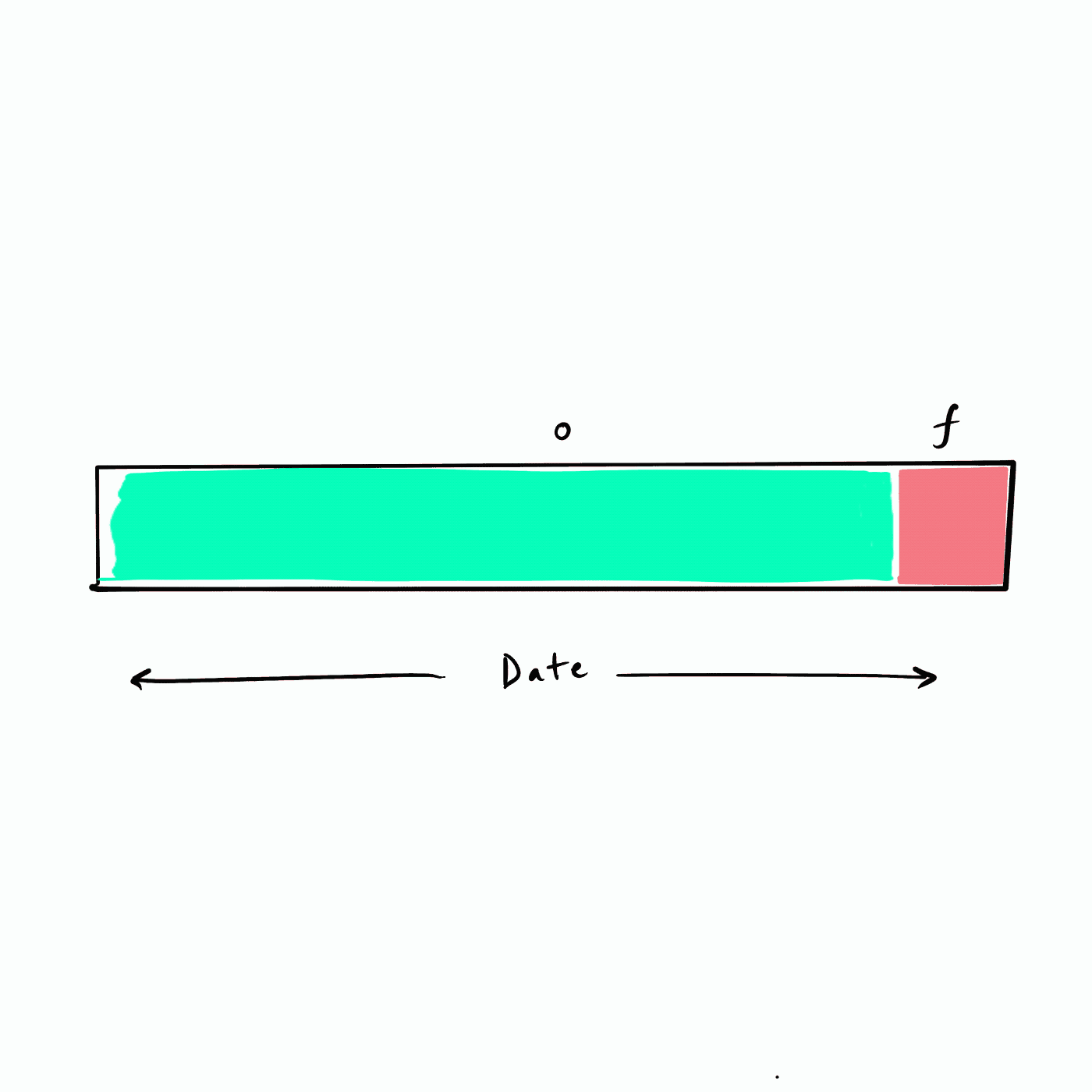 |
具體的實作代碼如下:
def recursive_rfm(data, date_col, id_col, value_col, freq='M', start_length=30, label_period_days=30):
dset_list = []
# 獲取資料集的起始時間
start_date = data[date_col].min() + pd.Timedelta(start_length, unit="D")
end_date = data[date_col].max() - pd.Timedelta(label_period_days, unit="D")
# 獲取時間段
dates = pd.date_range(start=start_date, end=end_date, freq=freq)
data[date_col] = pd.to_datetime(data[date_col])
for cut_off in dates:
# 切分
observed = data[data[date_col] < cut_off]
future = data[
(data[date_col] > cut_off) &
(data[date_col] < cut_off + pd.Timedelta(label_period_days, unit='D'))
]
rfm_columns = [date_col, id_col, value_col]
print(f"computing rfm features for {cut_off} to {future[date_col].max()}:")
_observed = observed[rfm_columns]
# 計算訓練資料特征部分(即observed部分)
rfm_features = customer_rfm(_observed, cut_off, date_col, id_col, value_col)
# 計算標簽(即future的總消費)
labels = future.groupby(id_col)[value_col].sum()
# 合并資料
dset = rfm_features.merge(labels, on=id_col, how='outer').fillna(0)
dset_list.append(dset)
# 完整資料
full_dataset = pd.concat(dset_list, axis=0)
res = full_dataset[full_dataset.recency != 0].dropna(axis=1, how='any')
return res
rec_df = recursive_rfm(data_for_rfm, 'Date', 'Customer_ID', 'Sales_Amount')
接下來我們進行資料切分,以便更好地進行建模和評估,這里依舊把資料切分為 80% 用于訓練,20% 用于測驗,
from sklearn.model_selection import train_test_split
# 資料采樣,如果大家本地計算資源少,可以設定百分比進行采樣
rec_df = rec_df.sample(frac=1)
# 確定特征與標簽
X = rec_df[['recency', 'frequency', 'value', 'age']]
y = rec_df[['Sales_Amount']].values.reshape(-1)
# 資料集切分
test_size = 0.2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42, shuffle=True)
?? 機器學習建模
關于機器學習建模部分,大家可以參考 ShowMeAI 的機器學習系列教程與模型評估基礎知識文章,
??圖解機器學習演算法:從入門到精通系列教程
??圖解機器學習 | 隨機森林模型詳解
??圖解機器學習演算法(2) | 模型評估方法與準則
有很多機器學習模型都可以進行建模,在本例中我們使用最常用且效果良好的隨機森林進行建模,因為是回歸任務,我們直接使用 scikit-learn 中的隨機森林回歸器,代碼如下,
from sklearn.ensemble import RandomForestRegressor
# 在訓練資料集上初始化和擬合模型
rf = RandomForestRegressor().fit(X_train, y_train)
擬合后,我們可以在資料框中查看我們對測驗集的預測,
from sklearn.metrics import mean_squared_error
# 訓練集:標準答案與預估值
predictions = pd.DataFrame()
predictions['true'] = y_train
predictions['preds'] = rf.predict(X_train)
# 測驗集:標準答案與預估值
predictions_test = pd.DataFrame()
predictions_test['true'] = y_test
predictions_test['preds'] = rf.predict(X_test)
# 模型評估
train_rmse = mean_squared_error(predictions.true, predictions.preds)**0.5
test_rmse = mean_squared_error(predictions_test.true, predictions_test.preds)**0.5
print(f"Train RMSE: {train_rmse}, Test RMSE: {test_rmse}")
輸出:
Train RMSE :10.608368028113563, Test RMSE :28.366171873961612
這里我們使用的均方根誤差 (RMSE) 作為評估準則,它計算的是訓練資料和測驗資料上『標準答案』和『預估值』的偏差平方和與樣本數 N 比值的平方根, 即如下公式:
 測驗集上評估結果 RMSE 約為 28.4,這意味著我們對未見資料的預測值相差約 28.40 美元, 不過,我們發現,訓練集上的 RMSE 明顯低于測驗集上的 RMSE,說明模型有一些過擬合了, 如果我們把訓練集和測驗集的每個樣本預估值和真實值繪制出來,是如下的結果,也能看出差異:
測驗集上評估結果 RMSE 約為 28.4,這意味著我們對未見資料的預測值相差約 28.40 美元, 不過,我們發現,訓練集上的 RMSE 明顯低于測驗集上的 RMSE,說明模型有一些過擬合了, 如果我們把訓練集和測驗集的每個樣本預估值和真實值繪制出來,是如下的結果,也能看出差異:
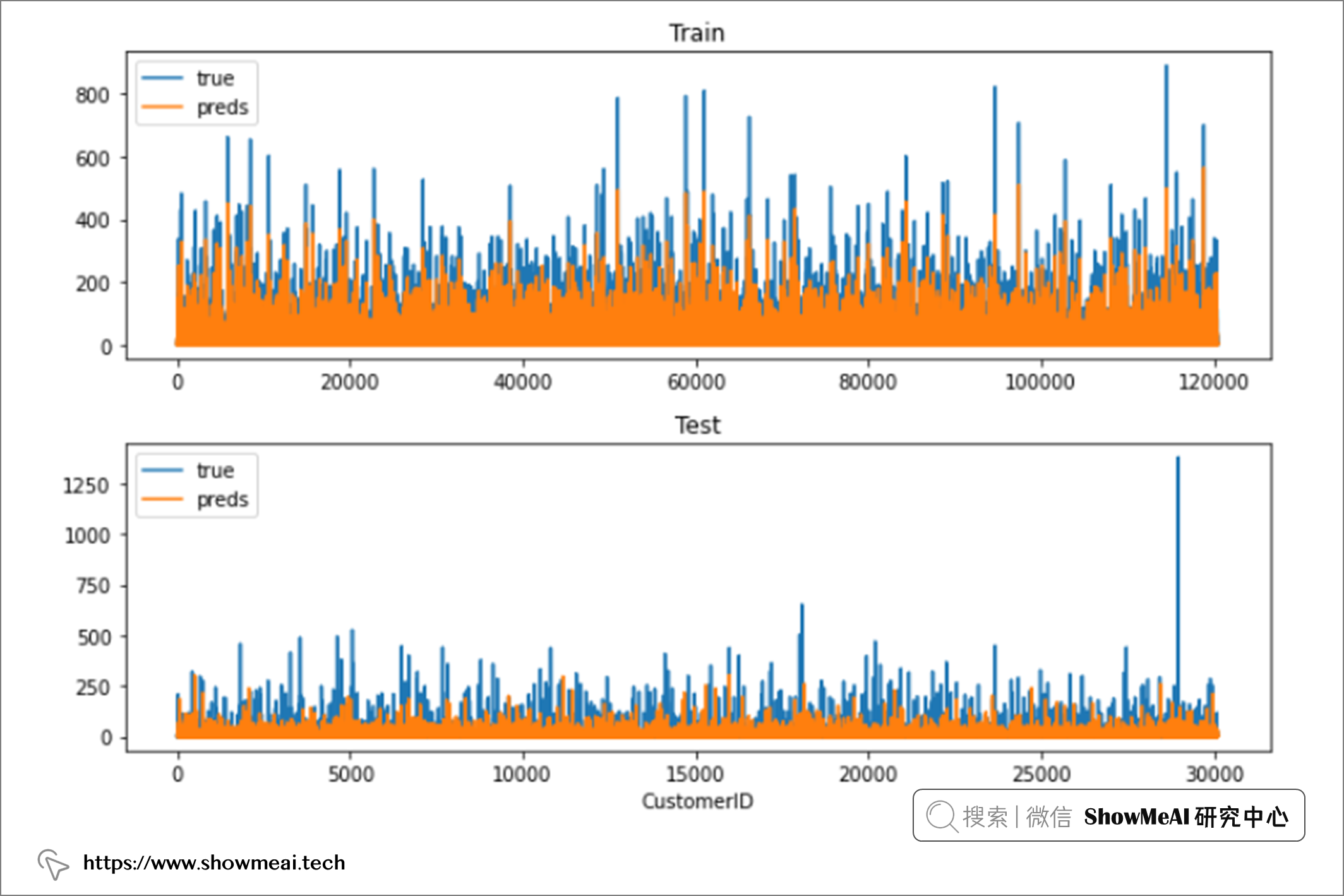
機器學中的過擬合問題,可以通過對模型的調參進行優化,比如在隨機森林模型中,可能是因為樹深太深,葉子節點樣本數設定較小等原因導致,大家可以通過調參方法(如網格搜索、隨機搜索、貝葉斯優化)等進行優化,可以在 ShowMeAI的過往機器學習實戰文章中找到調參模板:
人力資源流失場景機器學習建模與調優
基于Airbnb資料的民宿房價預測模型
參考資料
- ?? 資料科學工具庫速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- ?? 圖解資料分析:從入門到精通系列教程:https://www.showmeai.tech/tutorials/33
- ?? 圖解機器學習演算法:從入門到精通系列教程:https://www.showmeai.tech/tutorials/34
- ?? 圖解機器學習演算法| 模型評估方法與準則:https://www.showmeai.tech/article-detail/186
- ?? 圖解機器學習演算法 | 隨機森林模型詳解:https://www.showmeai.tech/article-detail/191
- ?? 機器學習實戰 | 機器學習特征工程最全解讀:https://www.showmeai.tech/article-detail/208
- ?? 人力資源流失場景機器學習建模與調優:https://www.showmeai.tech/article-detail/308
- ?? 基于Airbnb資料的民宿房價預測模型:https://www.showmeai.tech/article-detail/316
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/535199.html
標籤:其他
上一篇:帶你了解S12直播中的“黑科技”