作者|Renu Khandelwal
編譯|VK
來源|Medium

我們從以下問題開始
- 回圈神經網路能解決人工神經網路和卷積神經網路存在的問題,
- 在哪里可以使用RNN?
- RNN是什么以及它是如何作業的?
- 挑戰RNN的消梯度失和梯度爆炸
- LSTM和GRU如何解決這些挑戰
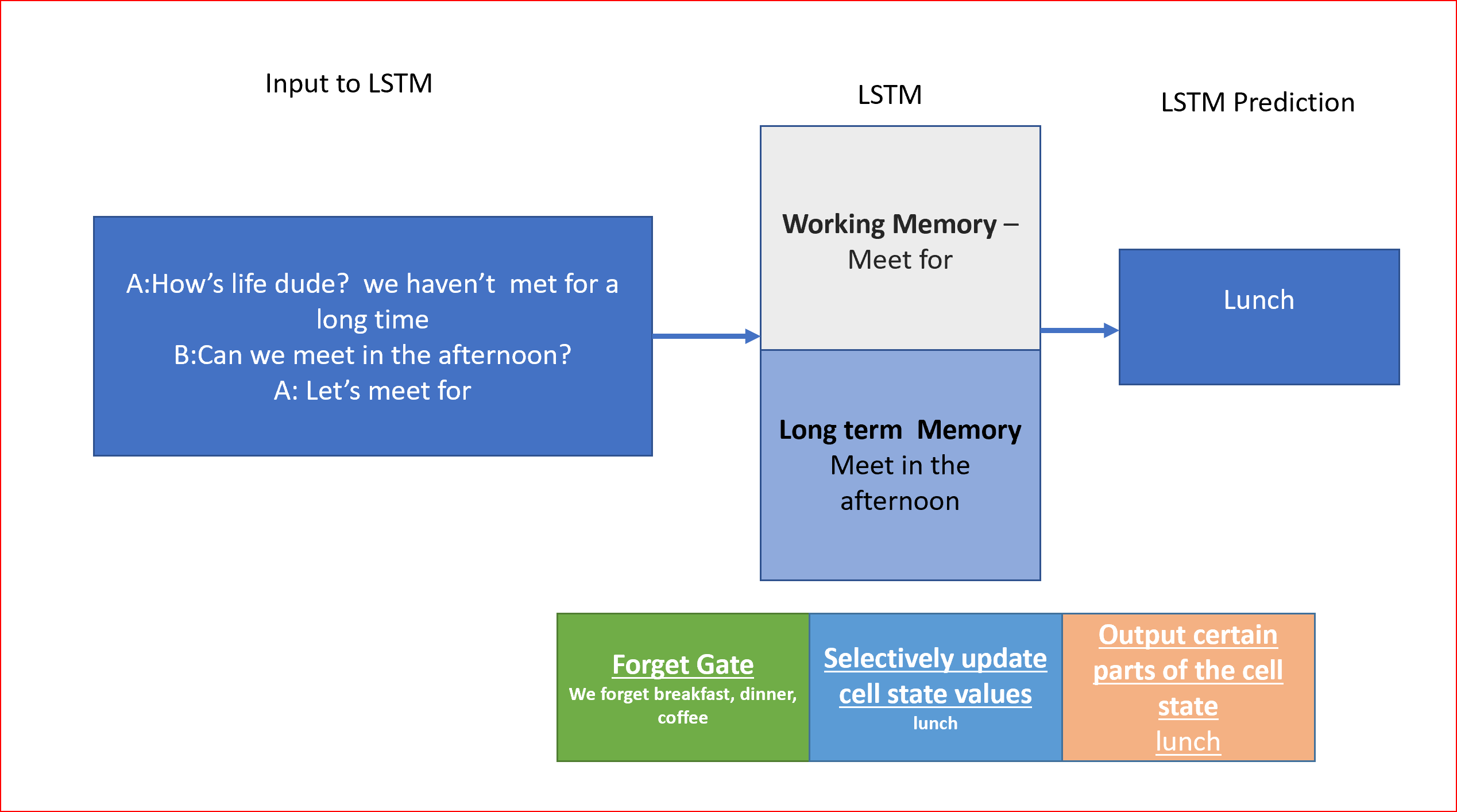
假設我們正在寫一條資訊“Let’s meet for___”,我們需要預測下一個單詞是什么,下一個詞可以是午餐、晚餐、早餐或咖啡,我們更容易根據背景關系作出推論,假設我們知道我們是在下午開會,并且這些資訊一直存在于我們的記憶中,那么我們就可以很容易地預測我們可能會在午餐時見面,
當我們需要處理需要在多個時間步上的序列資料時,我們使用回圈神經網路(RNN)
傳統的神經網路和CNN需要一個固定的輸入向量,在固定的層集上應用激活函式產生固定大小的輸出,
例如,我們使用128×128大小的向量的輸入影像來預測狗、貓或汽車的影像,我們不能用可變大小的影像來做預測
現在,如果我們需要對依賴于先前輸入狀態(如訊息)的序列資料進行操作,或者序列資料可以在輸入或輸出中,或者同時在輸入和輸出中,而這正是我們使用RNNs的地方,該怎么辦,
在RNN中,我們共享權重并將輸出反饋給回圈輸入,這種回圈公式有助于處理序列資料,
RNN利用連續的資料來推斷誰在說話,說什么,下一個單詞可能是什么等等,
RNN是一種神經網路,具有回圈來保存資訊,RNN被稱為回圈,因為它們對序列中的每個元素執行相同的任務,并且輸出元素依賴于以前的元素或狀態,這就是RNN如何持久化資訊以使用背景關系來推斷,
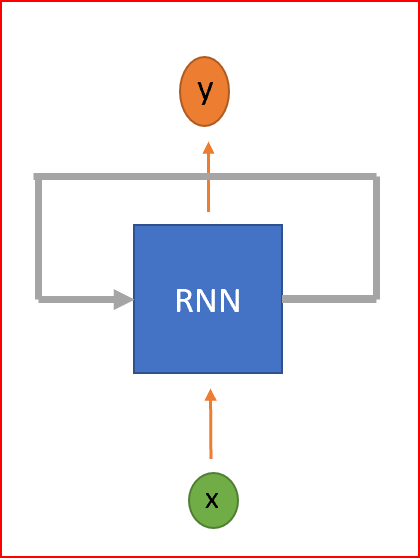
RNN是一種具有回圈的神經網路
RNN在哪里使用?
前面所述的RNN可以有一個或多個輸入和一個或多個輸出,即可變輸入和可變輸出,
RNN可用于
- 分類影像
- 影像采集
- 機器翻譯
- 視頻分類
- 情緒分析
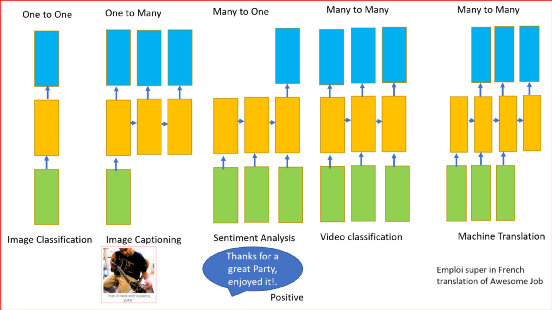
RNN是如何作業的?
先解釋符號,
- h是隱藏狀態
- x為輸入
- y為輸出
- W是權重
- t是時間步長
當我們在處理序列資料時,RNN在時間步t上取一個輸入x,RNN在時間步t-1上取隱藏狀態值來計算時間步t上的隱藏狀態h并應用tanh激活函式,我們使用tanh或ReLU來表示輸出和時間t的非線性關系,
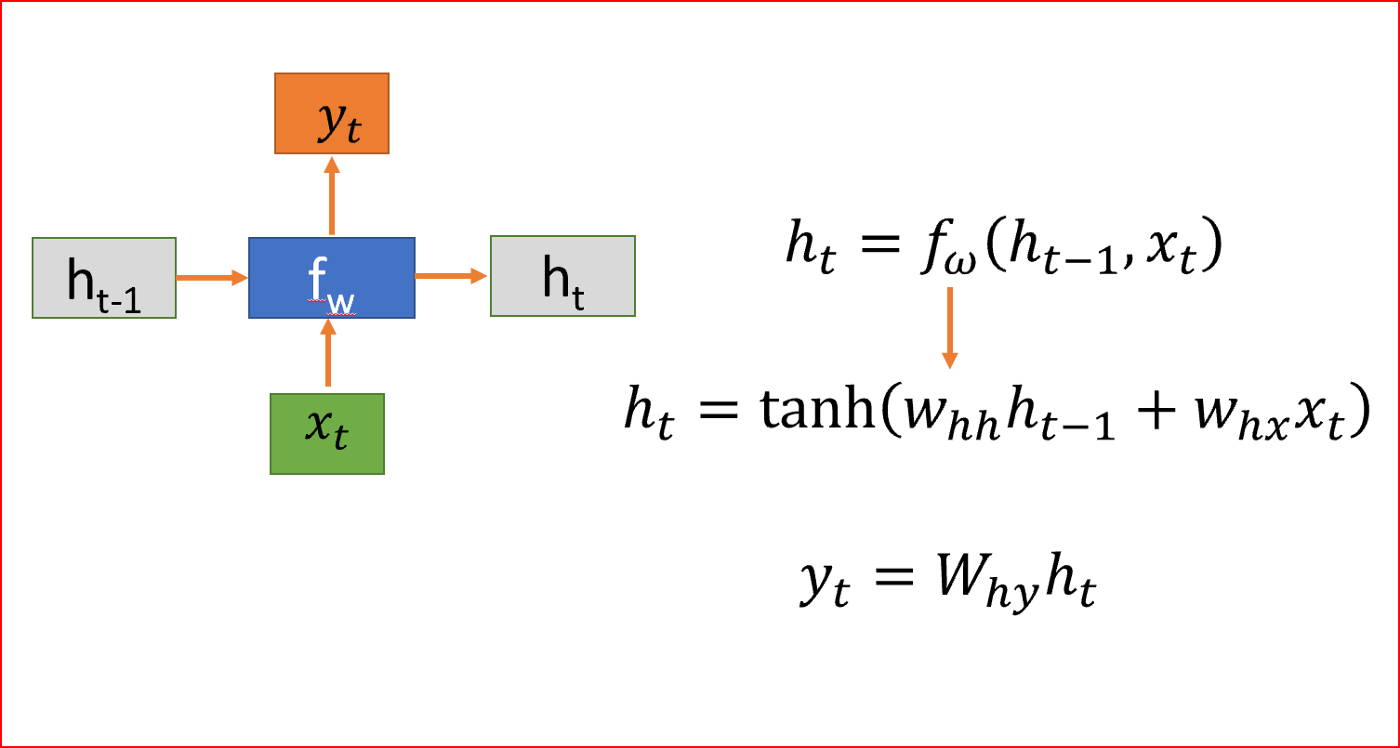
將RNN展開為四層神經網路,每一步共享權值矩陣W,
隱藏狀態連接來自前一個狀態的資訊,因此充當RNN的記憶,任何時間步的輸出都取決于當前輸入以及以前的狀態,
與其他對每個隱藏層使用不同引數的深層神經網路不同,RNN在每個步驟共享相同的權重引數,
我們隨機初始化權重矩陣,在訓練程序中,我們需要找到矩陣的值,使我們有理想的行為,所以我們計算損失函式L,損失函式L是通過測量實際輸出和預測輸出之間的差異來計算的,用交叉熵函式計算L,
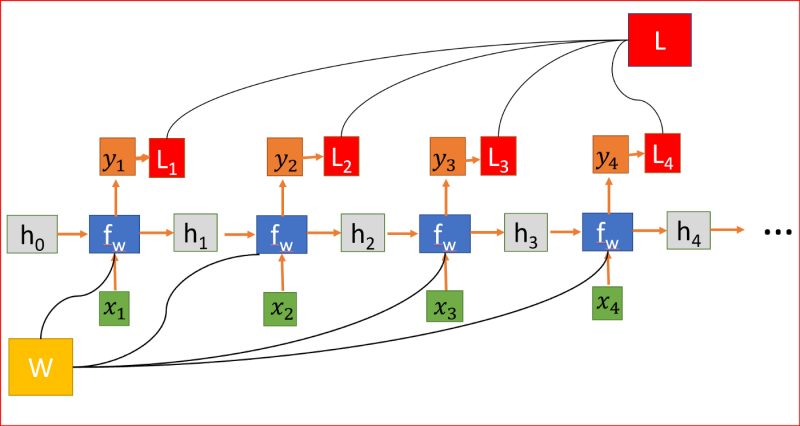
RNN,其中損失函式L是各層所有損失的總和
為了減少損失,我們使用反向傳播,但與傳統的神經網路不同,RNN在多個層次上共享權重,換句話說,它在所有時間步驟上共享權重,這樣,每一步的誤差梯度也取決于前一步的損失,
在上面的例子中,為了計算第4步的梯度,我們需要將前3步的損失和第4步的損失相加,這稱為通過Time-BPPT的反向傳播,
我們計算誤差相對于權重的梯度,來為我們學習正確的權重,為我們獲得理想的輸出,
因為W在每一步中都被用到,直到最后的輸出,我們從t=4反向傳播到t=0,在傳統的神經網路中,我們不共享權重,因此不需要對梯度進行求和,而在RNN中,我們共享權重,并且我們需要在每個時間步上對W的梯度進行求和,
在時間步t=0計算h的梯度涉及W的許多因素,因為我們需要通過每個RNN單元反向傳播,即使我們不要權重矩陣,并且一次又一次地乘以相同的標量值,但是時間步如果特別大,比如說100個時間步,這將是一個挑戰,
如果最大奇異值大于1,則梯度將爆炸,稱為爆炸梯度,
如果最大奇異值小于1,則梯度將消失,稱為消失梯度,
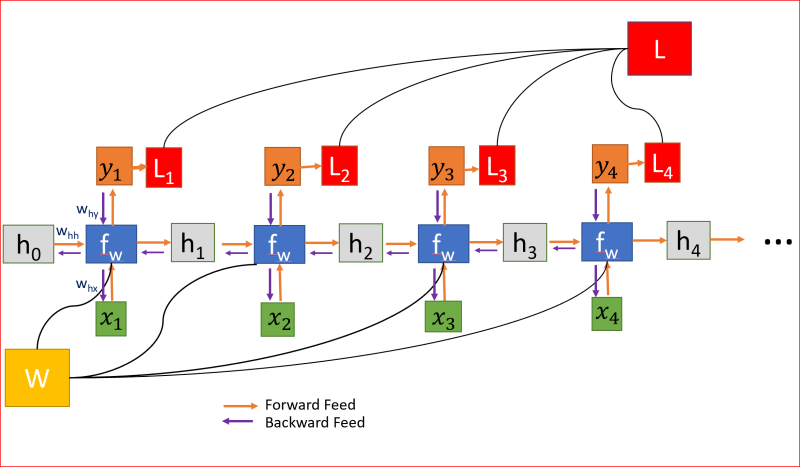
權重在所有層中共享,導致梯度爆炸或消失
對于梯度爆炸問題,我們可以使用梯度剪裁,其中我們可以預先設定一個閾值,如果梯度值大于閾值,我們可以剪裁它,
為了解決消失梯度問題,常用的方法是使用長短期記憶(LSTM)或門控回圈單元(GRU),
在我們的訊息示例中,為了預測下一個單詞,我們需要回傳幾個時間步驟來了解前面的單詞,我們有可能在兩個相關資訊之間有足夠的差距,隨著差距的擴大,RNN很難學習和連接資訊,但這反而是LSTM的強大功能,

長短時記憶網路(LSTM)
LSTMs能夠更快地學習長期依賴關系,LSTMs可以學習跨1000步的時間間隔,這是通過一種高效的基于梯度的演算法實作的,
為了預測訊息中的下一個單詞,我們可以將背景關系存盤到訊息的開頭,這樣我們就有了正確的背景關系,這正是我們記憶的作業方式,
讓我們深入了解一下LSTM架構,了解它是如何作業的

LSTMs的行為是在很長一段時間內記住資訊,因此它需要知道要記住什么和忘記什么,
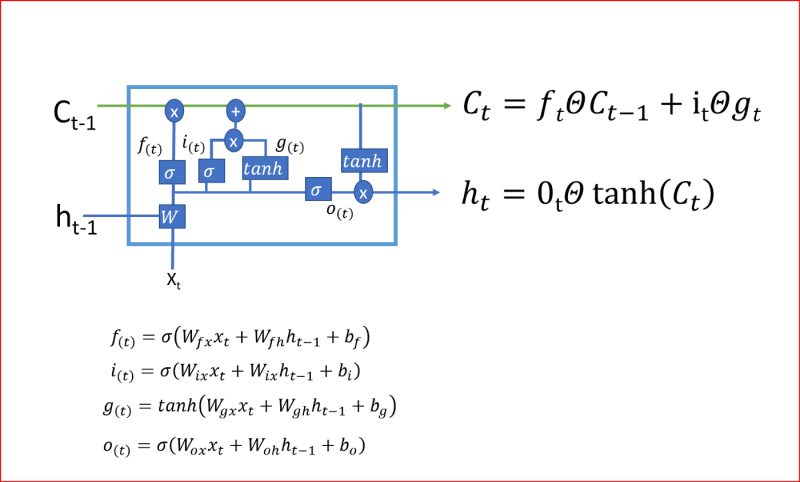
LSTM使用4個門,你可以將它們認為是否需要記住以前的狀態,單元狀態在LSTMs中起著關鍵作用,LSTM可以使用4個調節門來決定是否要從單元狀態添加或洗掉資訊,
這些門的作用就像水龍頭,決定了應該通過多少資訊,

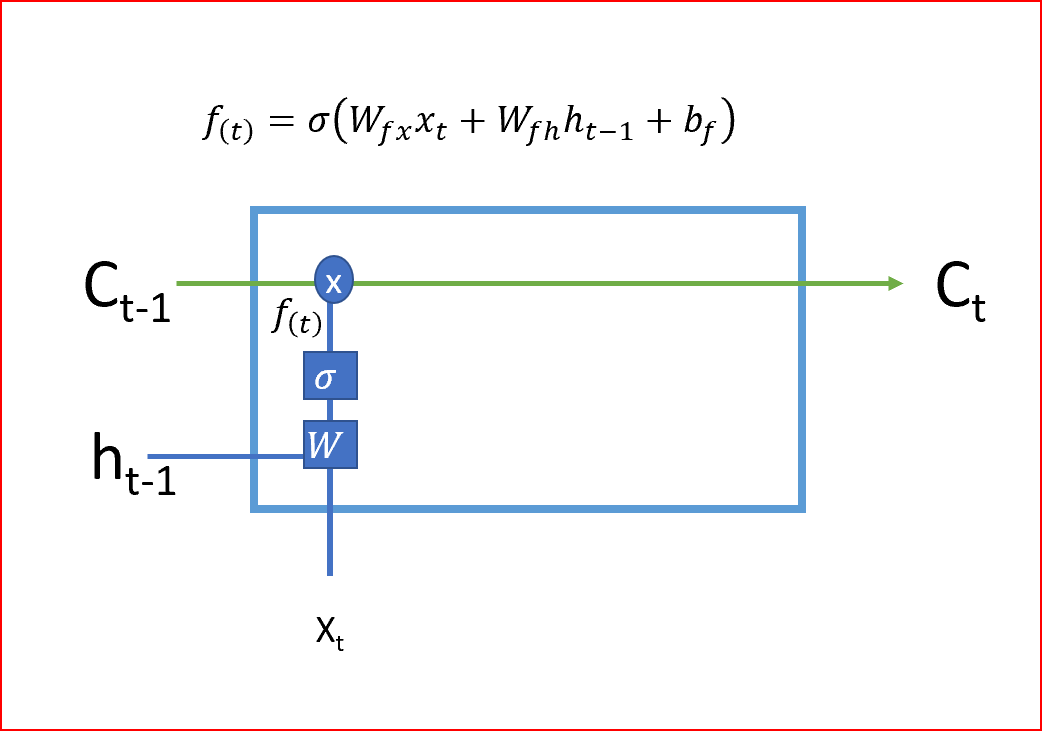
- LSTM的第一步是決定我們是需要記住還是忘記單元的狀態,遺忘門使用Sigmoid激活函式,輸出值為0或1,遺忘門的輸出1告訴我們要保留該值,值0告訴我們要忘記該值,
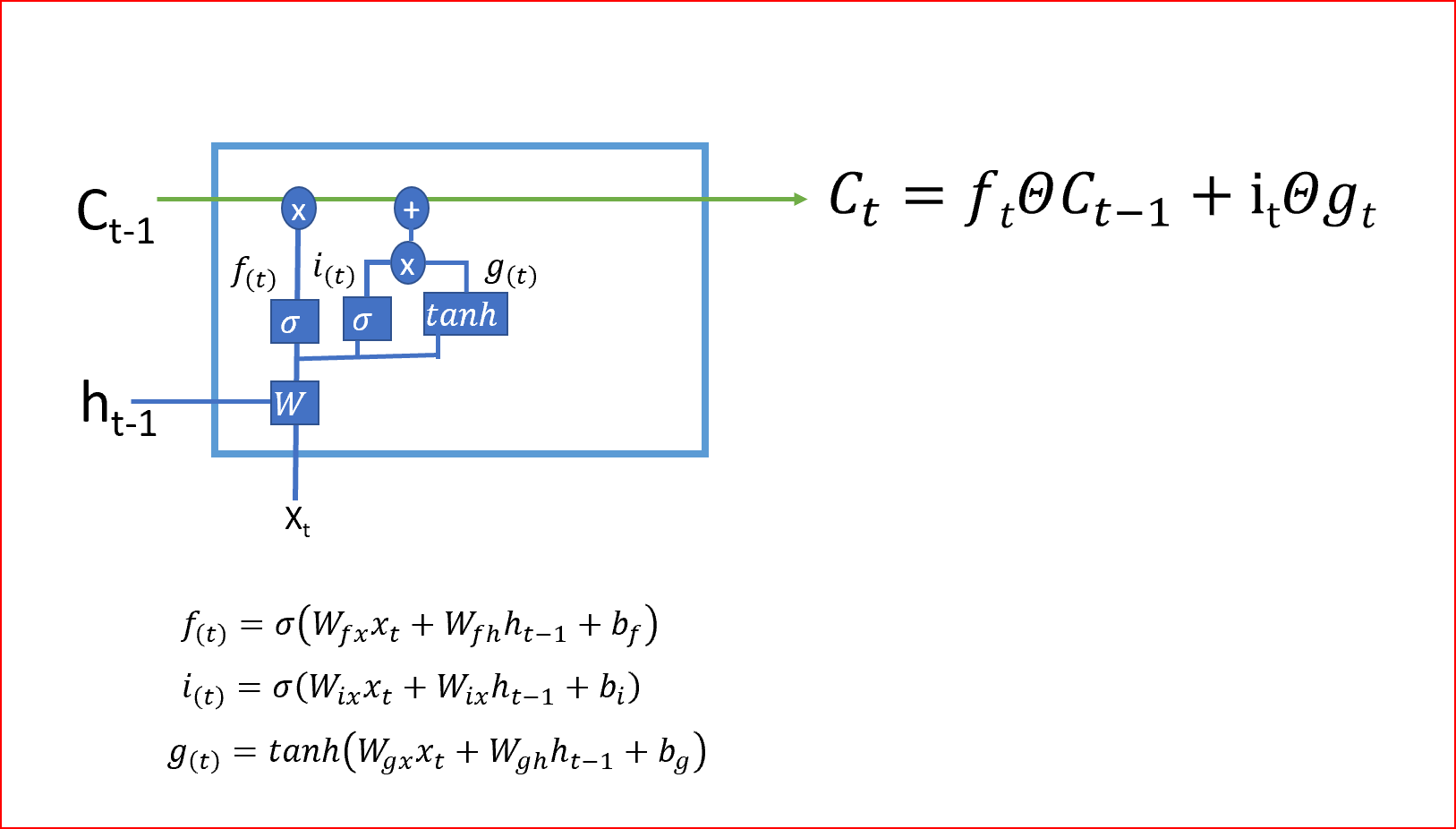
- 第二步決定我們將在單元狀態中存盤哪些新資訊,這有兩部分:一部分是輸入門,它通過使用sigmoid函式決定是否寫入單元狀態;另一部分是使用tanh激活函式決定有哪些新資訊被加入,

-
在最后一步中,我們通過組合步驟1和步驟2的輸出來創建單元狀態,步驟1和步驟2的輸出是將當前時間步的tanh激活函式應用于輸出門的輸出后乘以單元狀態,Tanh激活函式給出-1和+1之間的輸出范圍
-
單元狀態是單元的內部存盤器,它將先前的單元狀態乘以遺忘門,然后將新計算的隱藏狀態(g)乘以輸入門i的輸出,
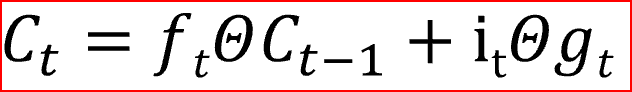
最后,輸出將基于單元狀態
從當前單元狀態到前一單元狀態的反向傳播只有遺忘門的單元相乘,沒有W的矩陣相乘,這就利用單元狀態消除了消失和爆炸梯度問題
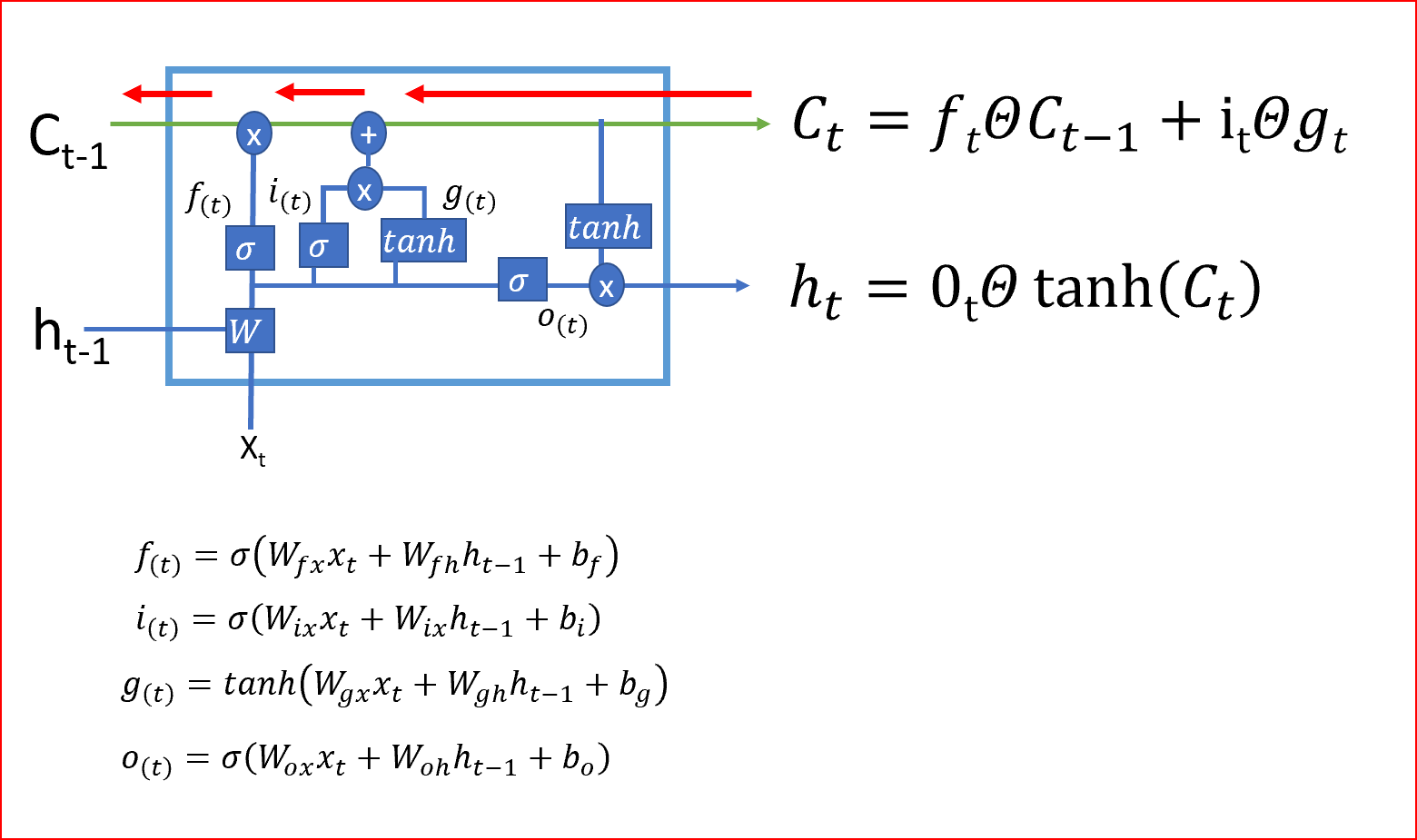
LSTM通過決定忘記什么、記住什么、更新哪些資訊來決定何時以及如何在每個時間步驟轉換記憶,這就是LSTMs如何幫助存盤長期記憶,
以下LSTM如何對我們的訊息進行預測的示例
GRU,LSTM的變體
GRU使用兩個門,重置門和一個更新門,這與LSTM中的三個步驟不同,GRU沒有內部記憶
重置門決定如何將新輸入與前一個時間步的記憶相結合,
更新門決定了應該保留多少以前的記憶,更新門是我們在LSTM中理解的輸入門和遺忘門的組合,
GRU是求解消失梯度問題的LSTM的一個簡單變種
原文鏈接:https://medium.com/datadriveninvestor/recurrent-neural-network-rnn-52dd4f01b7e8
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5353.html
標籤:其他