宣告
本文參考Deep-Learning-Specialization-Coursera/Convolution_model_Step_by_Step_v1.ipynb at main · abdur75648/Deep-Learning-Specialization-Coursera · GitHub,力求理解,
資料下載
鏈接:https://pan.baidu.com/s/1LoMe9bS_ig0wB7ubR9m39Q
提取碼:afhc,請在開始之前下載好所需資料,
【博主使用的python版本:3.9.12】,當然也使用tensorflow2.
1. 神經網路的底層搭建
??這里,我們要實作一個擁有卷積層(CONV)和池化層(POOL)的網路,它包含了前向和反向傳播,
nH,nW,nc,是指分別表示給定層的影像的高度、寬度和通道數,如果你想特指某一層,那么可以這樣寫:nH[L],nW[L],nc[L]
1 - Packages
我們先要引入一些庫:
import numpy as np import h5py import matplotlib.pyplot as plt from public_tests import * %matplotlib inline plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray' np.random.seed(1)
2 - Outline of the Assignment
我們將實作一個卷積神經網路的一些模塊,下面我們將列舉我們要實作的模塊的函式功能:
- 卷積模塊,包含了以下函式:
- 使用0擴充邊界
- 卷積視窗
- 前向卷積
- 反向卷積(可選)
2.池化模塊,包含了以下函式:
- 前向池化
- 創建掩碼
- 值分配
- 反向池化(可選)
- 我們將在這里從底層搭建一個完整的模塊,之后我們會用TensorFlow實作,模型結構如下:
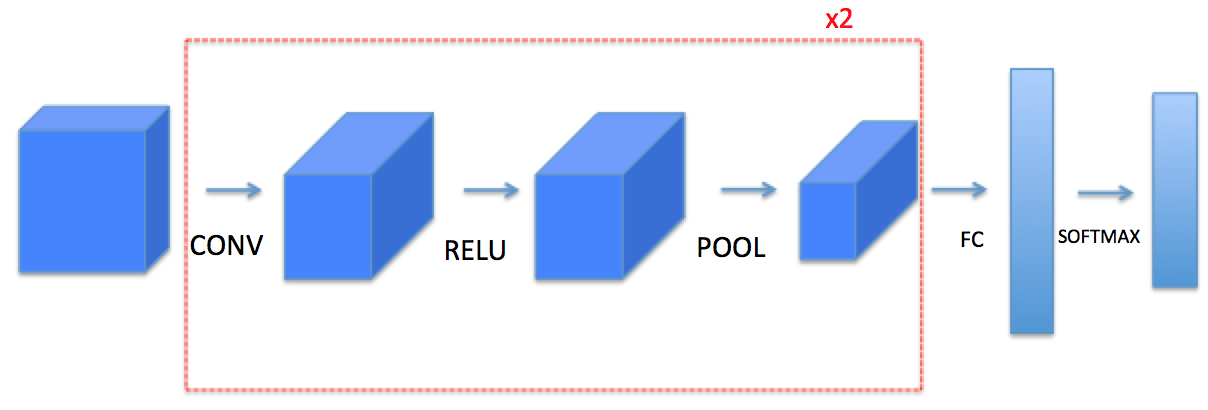
需要注意的是我們在前向傳播的程序中,我們會存盤一些值,以便在反向傳播的程序中計算梯度值,
3 - Convolutional Neural Networks
盡管編程框架使卷積容易使用,但它們仍然是深度學習中最難理解的概念之一,卷積層將輸入轉換成不同維度的輸出,如下所示,
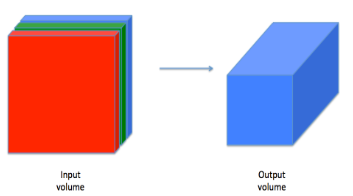
我們將一步步構建卷積層,我們將首先實作兩個輔助函式:一個用于零填充,另一個用于計算卷積,
3.1 - Zero-Padding
邊界填充將會在影像邊界周圍添加值為0的像素點,如下圖所示:
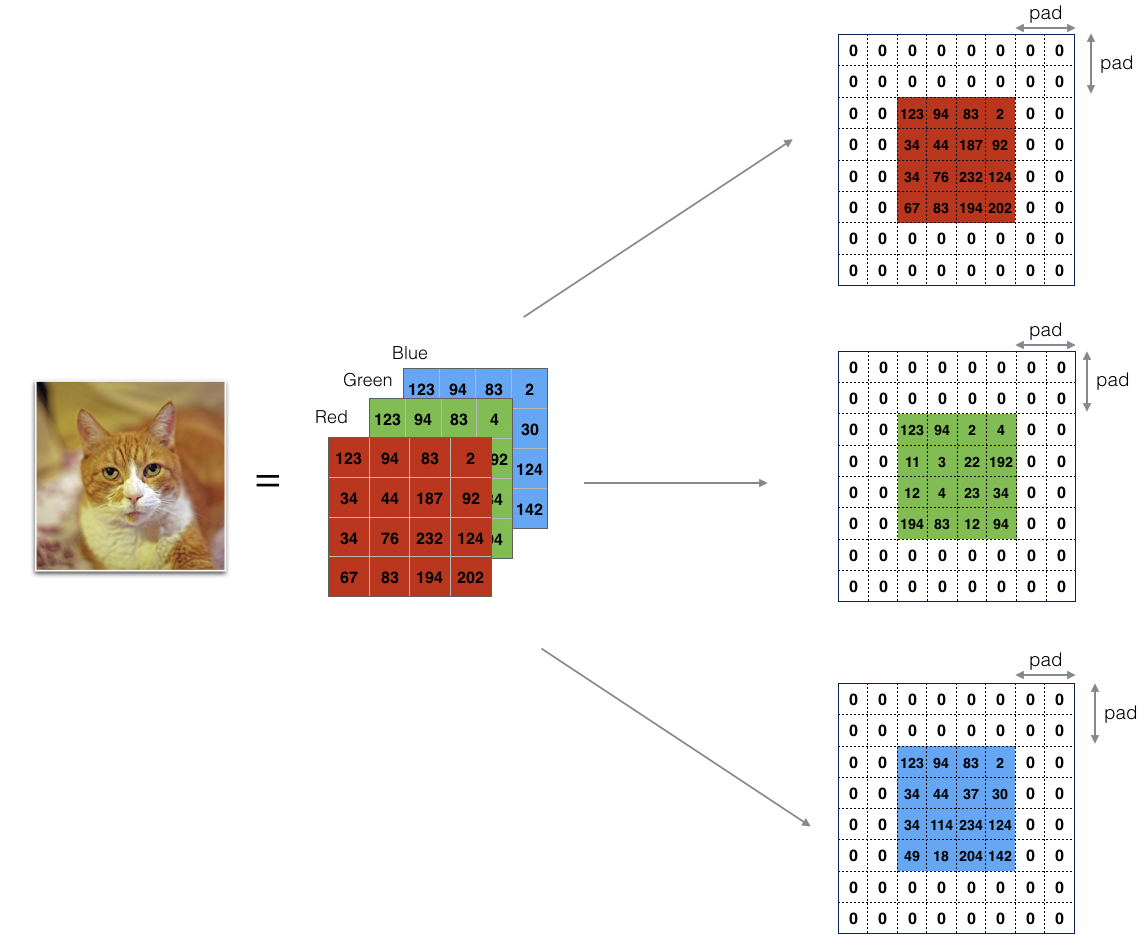
使用0填充邊界有以下好處:
卷積了上一層之后的CONV層,沒有縮小高度和寬度, 這對于建立更深的網路非常重要,否則在更深層時,高度/寬度會縮小, 一個重要的例子是“same”卷積,其中高度/寬度在卷積完一層之后會被完全保留,
它可以幫助我們在影像邊界保留更多資訊,在沒有填充的情況下,卷積程序中影像邊緣的極少數值會受到過濾器的影響從而導致資訊丟失,
??我們將實作一個邊界填充函式,它會把所有的樣本影像X XX都使用0進行填充,我們可以使用np.pad來快速填充,需要注意的是如果你想使用pad = 1填充陣列**a**.shape = ( 5 , 5 , 5 , 5 , 5 )的第二維,使用pad = 3填充第4維,使用pad = 0來填充剩下的部分,我們可以這么做:
a = np.pad(a, ((0,0), (1,1), (0,0), (3,3), (0,0)), mode='constant', constant_values = (0,0))
def zero_pad(X,pad): """ 把資料集X的影像邊界全部使用0來擴充pad個寬度和高度, 引數: X - 影像資料集,維度為(樣本數,影像高度,影像寬度,影像通道數) pad - 整數,每個影像在垂直和水平維度上的填充量 回傳: X_paded - 擴充后的影像資料集,維度為(樣本數,影像高度 + 2*pad,影像寬度 + 2*pad,影像通道數) """ X_paded = np.pad(X,( (0,0), #樣本數,不填充 (pad,pad), #影像高度,你可以視為上面填充x個,下面填充y個(x,y) (pad,pad), #影像寬度,你可以視為左邊填充x個,右邊填充y個(x,y) (0,0)), #通道數,不填充 'constant', constant_values=0) #連續一樣的值填充 return X_paded
我們來測驗一下:
np.random.seed(1) x = np.random.randn(4, 3, 3, 2) x_pad = zero_pad(x, 3) print ("x.shape =\n", x.shape) print ("x_pad.shape =\n", x_pad.shape) print ("x[1,1] =\n", x[1, 1]) print ("x_pad[1,1] =\n", x_pad[1, 1]) assert type(x_pad) == np.ndarray, "輸出必須是numpy陣列" assert x_pad.shape == (4, 9, 9, 2), f"Wrong shape: {x_pad.shape} != (4, 9, 9, 2)" print(x_pad[0, 0:2,:, 0]) # 查看第0行到第1行的資料 assert np.allclose(x_pad[0, 0:2,:, 0], [[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]], 1e-15), "Rows are not padded with zeros" assert np.allclose(x_pad[0, :, 7:9, 1].transpose(), [[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]], 1e-15), "Columns are not padded with zeros" assert np.allclose(x_pad[:, 3:6, 3:6, :], x, 1e-15), "Internal values are different" #繪圖 fig, axarr = plt.subplots(1, 2) axarr[0].set_title('x') axarr[0].imshow(x[0, :, :, 0]) axarr[1].set_title('x_pad') axarr[1].imshow(x_pad[0, :, :, 0])
3.2 - Single Step of Convolution
在這里,我們要實作第一步卷積,我們要使用一個過濾器來卷積輸入的資料,先來看看下面的這個gif:
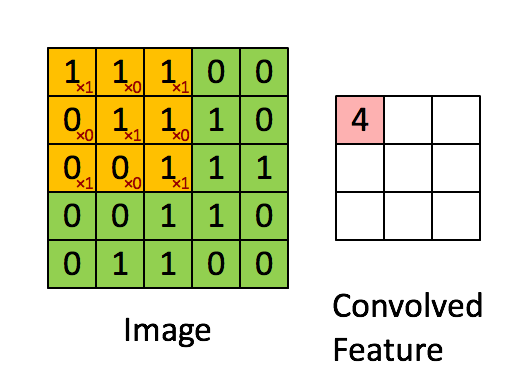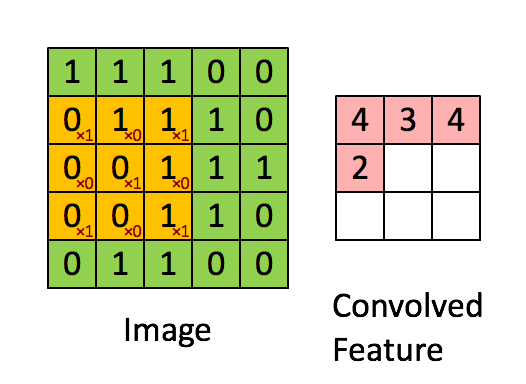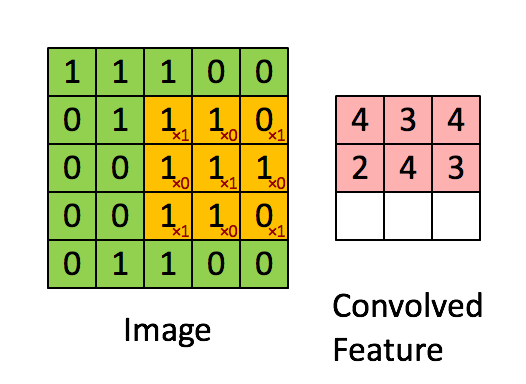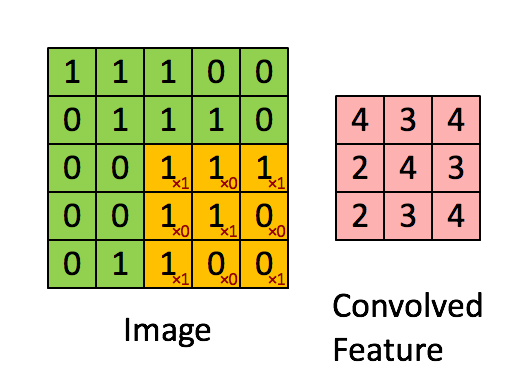
在計算機視覺應用中,左側矩陣中的每個值都對應一個像素值,我們通過將其值與原始矩陣元素相乘,然后對它們進行求和來將3x3濾波器與影像進行卷積,我們需要實作一個函式,可以將一個3x3濾波器與單獨的切片塊進行卷積并輸出一個實數,現在我們開始實作conv_single_step()
def conv_single_step(a_slice_prev, W, b): """ 在前一層的激活輸出的一個片段上應用一個由引數W定義的過濾器, 這里切片大小和過濾器大小相同 引數: a_slice_prev - 輸入資料的一個片段,維度為(過濾器大小,過濾器大小,上一通道數) W - 權重引數,包含在了一個矩陣中,維度為(過濾器大小,過濾器大小,上一通道數) b - 偏置引數,包含在了一個矩陣中,維度為(1,1,1) 回傳: Z - 在輸入資料的片X上卷積滑動視窗(w,b)的結果, """ s = np.multiply(a_slice_prev,W) # Sum over all entries of the volume s. Z = np.sum(s) # Add bias b to Z. Cast b to a float() so that Z results in a scalar value. b = np.squeeze(b) Z = Z + b return Z
我們來測驗一下:
np.random.seed(1) a_slice_prev = np.random.randn(4, 4, 3) W = np.random.randn(4, 4, 3) b = np.random.randn(1, 1, 1) Z = conv_single_step(a_slice_prev, W, b) print("Z =", Z) assert (type(Z) == np.float64 or type(Z) == np.float32), "You must cast the output to float"
Z = -6.999089450680221
3.3 - Convolutional Neural Networks - Forward Pass
在前向傳播的程序中,我們將使用多種過濾器對輸入的資料進行卷積操作,每個過濾器會產生一個2D的矩陣,我們可以把它們堆疊起來,于是這些2D的卷積矩陣就變成了高維的矩陣,我們可以看一下下面的圖:
如果我想要自定義切片,我們可以這么做:先定義要切片的位置,vert_start、vert_end、 horiz_start、 horiz_end,它們的位置我們看一下下面的圖就明白了,
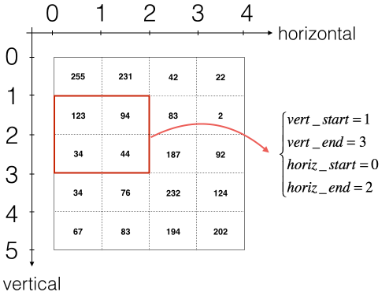
我們還是說一下輸出的維度的計算公式吧~

這里我們使用for回圈
def conv_forward(A_prev, W, b, hparameters): """ 實作卷積函式的前向傳播 引數: A_prev - 上一層的激活輸出矩陣,維度為(m, n_H_prev, n_W_prev, n_C_prev),(樣本數量,上一層影像的高度,上一層影像的寬度,上一層過濾器數量) W - 權重矩陣,維度為(f, f, n_C_prev, n_C),(過濾器大小,過濾器大小,上一層的過濾器數量,這一層的過濾器數量) b - 偏置矩陣,維度為(1, 1, 1, n_C),(1,1,1,這一層的過濾器數量) hparameters - 包含了"stride"與 "pad"的超引數字典, 回傳: Z - 卷積輸出,維度為(m, n_H, n_W, n_C),(樣本數,影像的高度,影像的寬度,過濾器數量) cache - 快取了一些反向傳播函式conv_backward()需要的一些資料 """ #獲取來自上一層資料的基本資訊 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape #獲取權重矩陣的基本資訊 ( f , f ,n_C_prev , n_C ) = W.shape #獲取超引數hparameters的值 stride = hparameters["stride"] pad = hparameters["pad"] #計算卷積后的影像的寬度高度,參考上面的公式,使用int()來進行板除 n_H = int(( n_H_prev - f + 2 * pad )/ stride) + 1 n_W = int(( n_W_prev - f + 2 * pad )/ stride) + 1 #使用0來初始化卷積輸出Z Z = np.zeros((m,n_H,n_W,n_C)) #通過A_prev創建填充過了的A_prev_pad A_prev_pad = zero_pad(A_prev,pad) for i in range(m): #遍歷樣本 a_prev_pad = A_prev_pad[i] #選擇第i個樣本的擴充后的激活矩陣 for h in range(n_H): #在輸出的垂直軸上回圈 for w in range(n_W): #在輸出的水平軸上回圈 for c in range(n_C): #回圈遍歷輸出的通道 #定位當前的切片位置 vert_start = h * stride #豎向,開始的位置 vert_end = vert_start + f #豎向,結束的位置 horiz_start = w * stride #橫向,開始的位置 horiz_end = horiz_start + f #橫向,結束的位置 #切片位置定位好了我們就把它取出來,需要注意的是我們是“穿透”取出來的, #自行腦補一下吸管插入一層層的橡皮泥就明白了 a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:] #執行單步卷積 Z[i,h,w,c] = conv_single_step(a_slice_prev,W[: ,: ,: ,c],b[0,0,0,c]) #資料處理完畢,驗證資料格式是否正確 assert(Z.shape == (m , n_H , n_W , n_C )) #存盤一些快取值,以便于反向傳播使用 cache = (A_prev,W,b,hparameters) return (Z , cache)
我們來測驗一下;
np.random.seed(1) A_prev = np.random.randn(2, 5, 5, 3) hparameters = {"stride" : 1, "f": 3} A, cache = pool_forward(A_prev, hparameters, mode = "max") print("mode = max") print("A.shape = " + str(A.shape)) print("A[1, 1] =\n", A[1, 1]) print() A, cache = pool_forward(A_prev, hparameters, mode = "average") print("mode = average") print("A.shape = " + str(A.shape)) print("A[1, 1] =\n", A[1, 1])
Z's mean = 0.5511276474566768 Z[0,2,1] = [-2.17796037 8.07171329 -0.5772704 3.36286738 4.48113645 -2.89198428 10.99288867 3.03171932] cache_conv[0][1][2][3] = [-1.1191154 1.9560789 -0.3264995 -1.34267579]
Finally, a CONV layer should also contain an activation, in which case you would add the following line of code:
# Convolve the window to get back one output neuron Z[i, h, w, c] = ... # Apply activation A[i, h, w, c] = activation(Z[i, h, w, c])
You don't need to do it here, however.
4 - Pooling Layer
池化層會減少輸入的寬度和高度,這樣它會較少計算量的同時也使特征檢測器對其在輸入中的位置更加穩定,下面介紹兩種型別的池化層:
- 最大值池化層:在輸入矩陣中滑動一個大小為fxf的視窗,選取視窗里的值中的最大值,然后作為輸出的一部分,
- 均值池化層:在輸入矩陣中滑動一個大小為fxf的視窗,計算視窗里的值中的平均值,然后這個均值作為輸出的一部分,
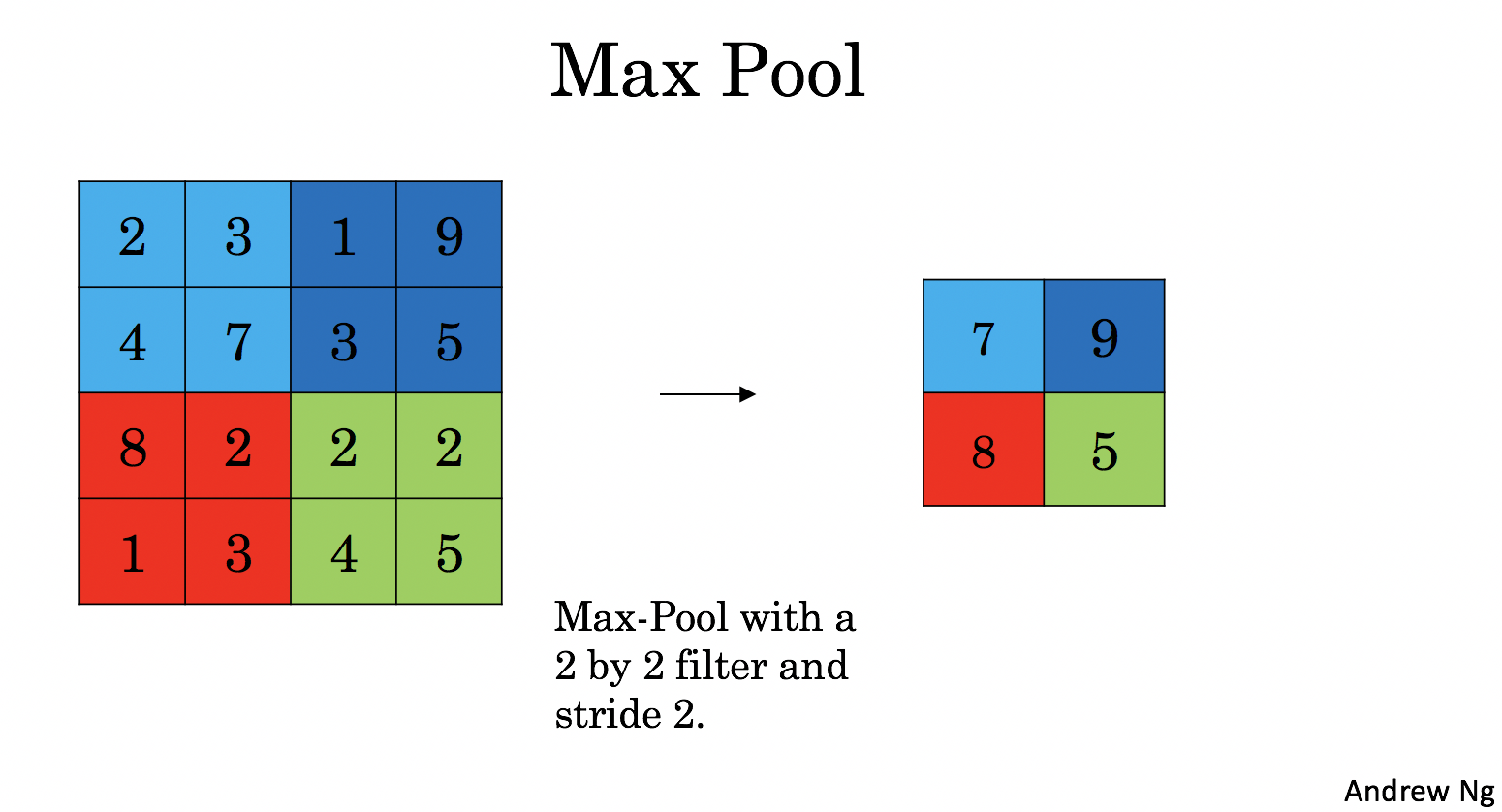
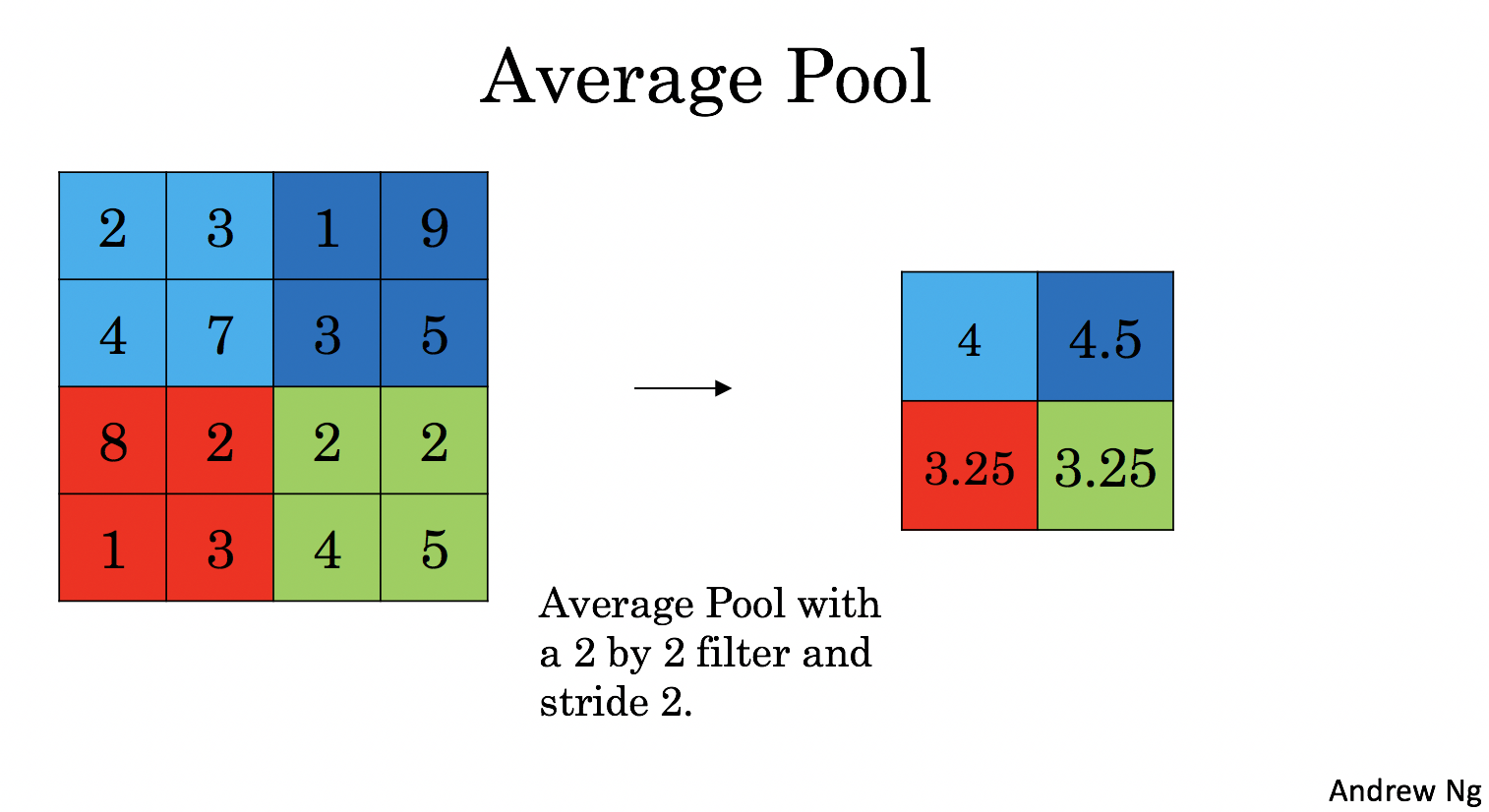
4.1 - Forward Pooling
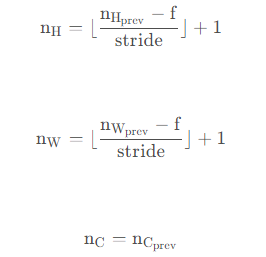
def pool_forward(A_prev,hparameters,mode="max"): """ 實作池化層的前向傳播 引數: A_prev - 輸入資料,維度為(m, n_H_prev, n_W_prev, n_C_prev) hparameters - 包含了 "f" 和 "stride"的超引數字典 mode - 模式選擇【"max" | "average"】 回傳: A - 池化層的輸出,維度為 (m, n_H, n_W, n_C) cache - 存盤了一些反向傳播需要用到的值,包含了輸入和超引數的字典, """ #獲取輸入資料的基本資訊 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape #獲取超引數的資訊 f = hparameters["f"] stride = hparameters["stride"] #計算輸出維度 n_H = int((n_H_prev - f) / stride ) + 1 n_W = int((n_W_prev - f) / stride ) + 1 n_C = n_C_prev #初始化輸出矩陣 A = np.zeros((m , n_H , n_W , n_C)) for i in range(m): #遍歷樣本 for h in range(n_H): #在輸出的垂直軸上回圈 for w in range(n_W): #在輸出的水平軸上回圈 for c in range(n_C): #回圈遍歷輸出的通道 #定位當前的切片位置 vert_start = h * stride #豎向,開始的位置 vert_end = vert_start + f #豎向,結束的位置 horiz_start = w * stride #橫向,開始的位置 horiz_end = horiz_start + f #橫向,結束的位置 #定位完畢,開始切割 a_slice_prev = A_prev[i,vert_start:vert_end,horiz_start:horiz_end,c] #對切片進行池化操作 if mode == "max": A[ i , h , w , c ] = np.max(a_slice_prev) elif mode == "average": A[ i , h , w , c ] = np.mean(a_slice_prev) #池化完畢,校驗資料格式 assert(A.shape == (m , n_H , n_W , n_C)) #校驗完畢,開始存盤用于反向傳播的值 cache = (A_prev,hparameters) return A,cache
我們來測驗一下:
np.random.seed(1) A_prev = np.random.randn(2, 5, 5, 3) hparameters = {"stride" : 1, "f": 3} A, cache = pool_forward(A_prev, hparameters, mode = "max") print("mode = max") print("A.shape = " + str(A.shape)) print("A[1, 1] =\n", A[1, 1]) print() A, cache = pool_forward(A_prev, hparameters, mode = "average") print("mode = average") print("A.shape = " + str(A.shape)) print("A[1, 1] =\n", A[1, 1])
mode = max A.shape = (2, 3, 3, 3) A[1, 1] = [[1.96710175 0.84616065 1.27375593] [1.96710175 0.84616065 1.23616403] [1.62765075 1.12141771 1.2245077 ]] mode = average A.shape = (2, 3, 3, 3) A[1, 1] = [[ 0.44497696 -0.00261695 -0.31040307] [ 0.50811474 -0.23493734 -0.23961183] [ 0.11872677 0.17255229 -0.22112197]]
5 - Backpropagation in Convolutional Neural Networks(選學)
因為在深度學習框架中,已經為您準備好反向傳播程序了,
函式實作
def conv_backward(dZ, cache): """ 實作卷積層的反向傳播 引數: dZ - 卷積層的輸出Z的 梯度,維度為(m, n_H, n_W, n_C) cache - 反向傳播所需要的引數,conv_forward()的輸出之一 回傳: dA_prev - 卷積層的輸入(A_prev)的梯度值,維度為(m, n_H_prev, n_W_prev, n_C_prev) dW - 卷積層的權值的梯度,維度為(f,f,n_C_prev,n_C) db - 卷積層的偏置的梯度,維度為(1,1,1,n_C) """ #獲取cache的值 (A_prev, W, b, hparameters) = cache #獲取A_prev的基本資訊 (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape #獲取權重的基本資訊 (f, f, n_C_prev, n_C) = W.shape # 獲取超參的基本資訊 stride = hparameters["stride"] pad = hparameters["pad"] # 獲取dZ的基本資訊 (m, n_H, n_W, n_C) = dZ.shape #初始化各個梯度的結構 dA_prev = np.zeros(A_prev.shape) dW = np.zeros(W.shape) db = np.zeros(b.shape) # b.shape = [1,1,1,n_C] #前向傳播中我們使用了pad,反向傳播也需要使用,這是為了保證資料結構一致 A_prev_pad = zero_pad(A_prev, pad) dA_prev_pad = zero_pad(dA_prev, pad) for i in range(m): # loop over the training examples # select ith training example from A_prev_pad and dA_prev_pad a_prev_pad = A_prev_pad[i] da_prev_pad = dA_prev_pad[i] for h in range(n_H): # loop over vertical axis of the output volume for w in range(n_W): # loop over horizontal axis of the output volume for c in range(n_C): # loop over the channels of the output volume #定位切片位置 vert_start = stride * h vert_end = vert_start + f horiz_start = stride * w horiz_end = horiz_start + f #定位完畢,開始切片 a_slice = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:] #切片完畢,使用上面的公式計算梯度 da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c] dW[:,:,:,c] += a_slice * dZ[i, h, w, c] db[:,:,:,c] += dZ[i, h, w, c] #設定第i個樣本最終的dA_prev,即把非填充的資料取出來, dA_prev[i, :, :, :] = da_prev_pad[pad:-pad, pad:-pad, :] # Making sure your output shape is correct assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev)) return dA_prev, dW, db
我們來測驗一下:
np.random.seed(1) A_prev = np.random.randn(10, 4, 4, 3) W = np.random.randn(2, 2, 3, 8) b = np.random.randn(1, 1, 1, 8) hparameters = {"pad" : 2, "stride": 2} Z, cache_conv = conv_forward(A_prev, W, b, hparameters) # Test conv_backward dA, dW, db = conv_backward(Z, cache_conv) print("dA_mean =", np.mean(dA)) print("dW_mean =", np.mean(dW)) print("db_mean =", np.mean(db)) print("\033[92m All tests passed.")
dA_mean = 1.4524377775388075
dW_mean = 1.7269914583139097
db_mean = 7.839232564616838
All tests passed.
5.2 Pooling Layer - Backward Pass
Max Pooling - Backward Pass
我們創建了一個掩碼矩陣,以保存最大值的位置,當為1的時候表示最大值的位置,其他的為0,這個是最大值池化層,均值池化層的向后傳播也和這個差不多,但是使用的是不同的掩碼,
def create_mask_from_window(x): """ 從輸入矩陣中創建掩碼,以保存最大值的矩陣的位置, 引數: x - 一個維度為(f,f)的矩陣 回傳: mask - 包含x的最大值的位置的矩陣 """ mask = x == np.max(x) return mask
測驗一下:
np.random.seed(1) x = np.random.randn(2, 3) mask = create_mask_from_window(x) print('x = ', x) print("mask = ", mask) x = np.array([[-1, 2, 3], [2, -3, 2], [1, 5, -2]]) y = np.array([[False, False, False], [False, False, False], [False, True, False]]) mask = create_mask_from_window(x) assert type(mask) == np.ndarray, "Output must be a np.ndarray" assert mask.shape == x.shape, "Input and output shapes must match" assert np.allclose(mask, y), "Wrong output. The True value must be at position (2, 1)" print("\033[92m All tests passed.")
x = [[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]]
mask = [[ True False False]
[False False False]]
All tests passed.
Average Pooling - Backward Pass
在最大值池化層中,對于每個輸入視窗,輸出的所有值都來自輸入中的最大值,但是在均值池化層中,因為是計算均值,所以輸入視窗的每個元素對輸出有一樣的影響,我們來看看如何反向傳播吧~
def distribute_value(dz,shape): """ 給定一個值,為按矩陣大小平均分配到每一個矩陣位置中, 引數: dz - 輸入的實數 shape - 元組,兩個值,分別為n_H , n_W 回傳: a - 已經分配好了值的矩陣,里面的值全部一樣, """ #獲取矩陣的大小 (n_H , n_W) = shape #計算平均值 average = dz / (n_H * n_W) #填充入矩陣 a = np.ones(shape) * average return a
測驗一下:
a = distribute_value(2, (2, 2)) print('distributed value =https://www.cnblogs.com/kk-style/archive/2022/11/19/', a) assert type(a) == np.ndarray, "Output must be a np.ndarray" assert a.shape == (2, 2), f"Wrong shape {a.shape} != (2, 2)" assert np.sum(a) == 2, "Values must sum to 2" a = distribute_value(100, (10, 10)) assert type(a) == np.ndarray, "Output must be a np.ndarray" assert a.shape == (10, 10), f"Wrong shape {a.shape} != (10, 10)" assert np.sum(a) == 100, "Values must sum to 100" print("\033[92m All tests passed.")
distributed value = https://www.cnblogs.com/kk-style/archive/2022/11/19/[[0.5 0.5]
[0.5 0.5]]
All tests passed.
Putting it Together: Pooling Backward
def pool_backward(dA,cache,mode = "max"): """ 實作池化層的反向傳播 引數: dA - 池化層的輸出的梯度,和池化層的輸出的維度一樣 cache - 池化層前向傳播時所存盤的引數, mode - 模式選擇,【"max" | "average"】 回傳: dA_prev - 池化層的輸入的梯度,和A_prev的維度相同 """ #獲取cache中的值 (A_prev , hparaeters) = cache #獲取hparaeters的值 f = hparaeters["f"] stride = hparaeters["stride"] #獲取A_prev和dA的基本資訊 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape (m , n_H , n_W , n_C) = dA.shape #初始化輸出的結構 dA_prev = np.zeros_like(A_prev) #開始處理資料 for i in range(m): a_prev = A_prev[i] for h in range(n_H): for w in range(n_W): for c in range(n_C): #定位切片位置 vert_start = h vert_end = vert_start + f horiz_start = w horiz_end = horiz_start + f #選擇反向傳播的計算方式 if mode == "max": #開始切片 a_prev_slice = a_prev[vert_start:vert_end,horiz_start:horiz_end,c] #創建掩碼 mask = create_mask_from_window(a_prev_slice) #計算dA_prev dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c] += np.multiply(mask,dA[i,h,w,c]) elif mode == "average": #獲取dA的值 da = dA[i,h,w,c] #定義過濾器大小 shape = (f,f) #平均分配 dA_prev[i,vert_start:vert_end, horiz_start:horiz_end ,c] += distribute_value(da,shape) #資料處理完畢,開始驗證格式 assert(dA_prev.shape == A_prev.shape) return dA_prev
測驗一下:
np.random.seed(1) A_prev = np.random.randn(5, 5, 3, 2) hparameters = {"stride" : 1, "f": 2} A, cache = pool_forward(A_prev, hparameters) print(A.shape) print(cache[0].shape) dA = np.random.randn(5, 4, 2, 2) dA_prev1 = pool_backward(dA, cache, mode = "max") print("mode = max") print('mean of dA = ', np.mean(dA)) print('dA_prev1[1,1] = ', dA_prev1[1, 1]) print() dA_prev2 = pool_backward(dA, cache, mode = "average") print("mode = average") print('mean of dA = ', np.mean(dA)) print('dA_prev2[1,1] = ', dA_prev2[1, 1]) print("\033[92m All tests passed.")
(5, 4, 2, 2)
(5, 5, 3, 2)
mode = max
mean of dA = 0.14571390272918056
dA_prev1[1,1] = [[ 0. 0. ]
[ 5.05844394 -1.68282702]
[ 0. 0. ]]
mode = average
mean of dA = 0.14571390272918056
dA_prev2[1,1] = [[ 0.08485462 0.2787552 ]
[ 1.26461098 -0.25749373]
[ 1.17975636 -0.53624893]]
All tests passed.
到此就結束了,下面我們進行應用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/536230.html
標籤:其他
上一篇:我上半年深陷泥淖的往事