文章:
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS

讀到這篇論文,參考了博客:https://www.cnblogs.com/fourmi/p/10049998.html
摘要:
在語意分割中,我們開發了一個新的卷積網路模塊,專門設計用于密集預測,該模塊在不丟失解析度的情況下,采用了卷積法對多尺度背景關系資訊進行了系統化處理,該體系結構基于這樣一個假設,即擴展的解決方案支持在不損失解析度或覆寫范圍的情況下對該感知區域的指數擴展,結果表明,本文提出的背景關系模塊提高了語意分割系統的準確性,此外,我們還研究了影像分類網路對稠密預測的適應性,并表明簡化適應網路可以提高預測精度,
Unit 1:計算機視覺中的語意分割
語意分割是計算機視覺中十分重要的領域,它是指像素級地識別影像,即標注出影像中每個像素所屬的物件類別,下圖為語意分割的一個實體,其目標是預測出影像中每一個像素的類標簽,分割的目標一般是將一張RGB影像(height*width*3)或是灰度圖(height*width*1)作為輸入,輸出的是分割圖,其中每一個像素包含了其類別的標簽(height*width*1). 為了清晰起見,使用了低解析度的預測圖,但實際上分割圖的解析度應與原始輸入的解析度相匹配,(https://blog.csdn.net/Biyoner/article/details/82591370)
Unit 2:DILATED CONVOLUTIONS ---空洞卷積
普通卷積 i.e. dilation=1
空洞卷積 i.e. dilation=2
空洞卷積核中的點距離由 1 增加到了 dilation 值,即中間 dilation-1 的地方都是空著的,這個空著的地方,一方面保持了卷積的引數的單次卷積運算量的不變,同時擴大了卷積的視野,
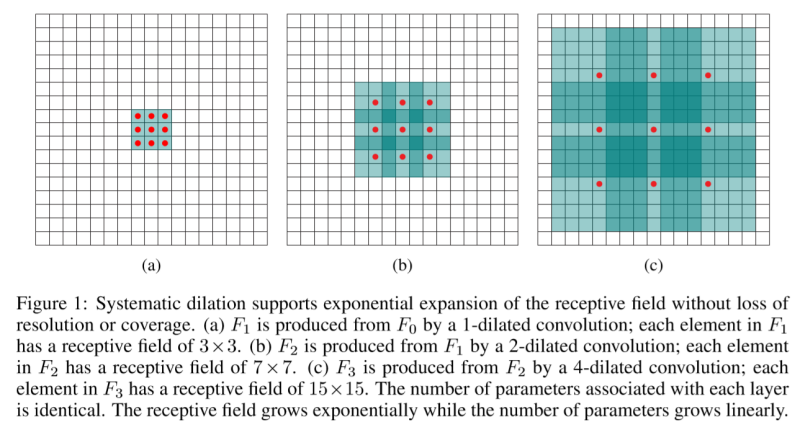
a圖中每個紅點表示3X3的視野范圍 b中每個紅點表示7X7的視野范圍(因為中間空出了2個格子) c中每個紅點視野范圍為15X15
視野范圍的計算公式為:M =(K+1)*N - 1 【K是卷積核維度 N是dilated數】
Unit 3:多級背景關系聚合
背景關系聚合模塊因為輸入輸出都是C特征圖的形式,所以可以插入現有的稠密預測結構中,
背景關系模塊的基本構成是:每個層都有C個通道; 每個層的表現是相同的; 每個層都可以用于直接獲得一個稠密類預測;
盡管沒有標準化特征圖也沒有定義LOSS 但是該模塊可以通過傳遞特征圖以揭示背景關系資訊以提高預測的準確性,
基本背景關系模塊由7層3X3卷積構成,只是膨脹因子不同,分別取值為1,1,2,4,8,16,1,
每層的3X3XC卷積都有前兩個維度的膨脹,所有后面都跟這一個逐點截取的 max(·,0)函式,最后一層為1X1XC 因為處理特征圖為64X64 所以到第六層就不膨脹了,要不視野就超了,
實驗的第一次嘗試失敗了,標準化的初始化程序不能達到良好的訓練效果,
通常卷積神經網路人們都是用隨機分布初始化,但是在本實驗中我們發現一種清空語意的選擇初始化方案更好用:
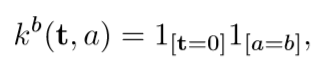
其中a,b分別為特征圖和輸出圖的索引
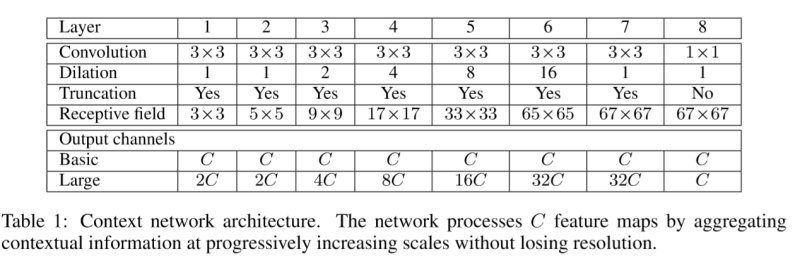
網路結構

大型網路的初始化函式
測驗結果:https://arxiv.org/abs/1511.07122
TensorFlow模型:https://github.com/ndrplz/dilation-tensorflow
論文提供模型:https://github.com/fyu/dilation
(本文的作業是朝著不受影像預分類約束的密集預測專用架構邁出的一步,隨著新的資料源的出現,未來的體系結構可能會變成端到端的密集訓練,不再需要預先訓練動物分類資料集,這可以實作架構的簡化和統一,具體地說,端到端的密集訓練可以實作完全密集的體系結構,類似于呈現的背景關系網路,通過輸出操作完全解析度,接受原始影像作為輸入,并以完全解析度生成密集的標簽分配作為輸出,----目標:端到端的密集標簽分配)
個人總結:本文用了一個使用空洞卷積的背景關系聚合模塊提高語意分割的精度,擴展卷積算子特別適合于密集預測,因為它能夠在不丟失解析度或覆寫率的情況下擴展接收場,本文還表明,現有的卷積網路用于語意分割的精度可以通過去除影像冗余來增加,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5366.html
標籤:其他