我們都知道,計算機是處理資料的設備,而資料的主要存盤位置就是磁盤和記憶體,并且對于程式員來講,CPU 和記憶體是我們必須了解的兩個物理結構,它是你通向高階程式員很重要的橋梁,那么本篇文章我們就來介紹一下基本的記憶體知識,
我們都知道,計算機是處理資料的設備,而資料的主要存盤位置就是磁盤和記憶體,并且對于程式員來講,CPU 和記憶體是我們必須了解的兩個物理結構,它是你通向高階程式員很重要的橋梁,那么本篇文章我們就來介紹一下基本的記憶體知識,
什么是記憶體
記憶體(Memory)是計算機中最重要的部件之一,它是程式與CPU進行溝通的橋梁,計算機中所有程式的運行都是在記憶體中進行的,因此記憶體對計算機的影響非常大,記憶體又被稱為主存,其作用是存放 CPU 中的運算資料,以及與硬碟等外部存盤設備交換的資料,只要計算機在運行中,CPU 就會把需要運算的資料調到主存中進行運算,當運算完成后CPU再將結果傳送出來,主存的運行也決定了計算機的穩定運行,
記憶體的物理結構
在了解一個事物之前,你首先得先需要見過它,你才會有印象,才會有想要了解的興趣,所以我們首先需要先看一下什么是記憶體以及它的物理結構是怎樣的,

記憶體的內部是由各種IC電路組成的,它的種類很龐大,但是其主要分為三種存盤器
-
隨機存盤器(RAM):記憶體中最重要的一種,表示既可以從中讀取資料,也可以寫入資料,當機器關閉時,記憶體中的資訊會 丟失,
-
只讀存盤器(ROM):ROM 一般只能用于資料的讀取,不能寫入資料,但是當機器停電時,這些資料不會丟失,
-
高速快取(Cache):Cache 也是我們經常見到的,它分為一級快取(L1 Cache)、二級快取(L2 Cache)、三級快取(L3 Cache)這些資料,它位于記憶體和 CPU 之間,是一個讀寫速度比記憶體更快的存盤器,當 CPU 向記憶體寫入資料時,這些資料也會被寫入高速快取中,當 CPU 需要讀取資料時,會直接從高速快取中直接讀取,當然,如需要的資料在Cache中沒有,CPU會再去讀取記憶體中的資料,
記憶體 IC 是一個完整的結構,它內部也有電源、地址信號、資料信號、控制信號和用于尋址的 IC 引腳來進行資料的讀寫,下面是一個虛擬的 IC 引腳示意圖
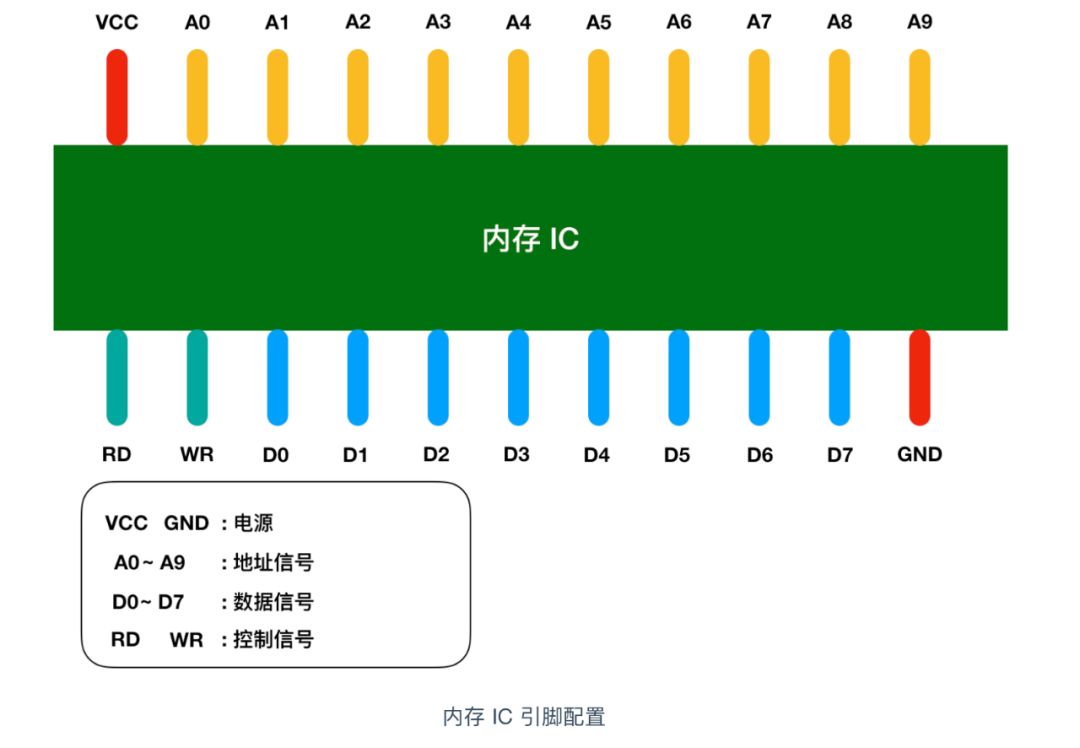
圖中 VCC 和 GND 表示電源,A0 - A9 是地址信號的引腳,D0 - D7 表示的是控制信號、RD 和 WR 都是好控制信號,我用不同的顏色進行了區分,將電源連接到 VCC 和 GND 后,就可以對其他引腳傳遞 0 和 1 的信號,大多數情況下,+5V 表示1,0V 表示 0,
我們都知道記憶體是用來存盤資料,那么這個記憶體 IC 中能存盤多少資料呢?D0 - D7 表示的是資料信號,也就是說,一次可以輸入輸出 8 bit = 1 byte 的資料,A0 - A9 是地址信號共十個,表示可以指定 00000 00000 - 11111 11111 共 2 的 10次方 = 1024個地址,每個地址都會存放 1 byte 的資料,因此我們可以得出記憶體 IC 的容量就是 1 KB,
如果我們使用的是 512 MB 的記憶體,這就相當于是 512000(512 * 1000) 個記憶體 IC,當然,一臺計算機不太可能有這么多個記憶體 IC ,然而,通常情況下,一個記憶體 IC 會有更多的引腳,也就能存盤更多資料,
記憶體的讀寫程序
讓我們把關注點放在記憶體 IC 對資料的讀寫程序上來吧!我們來看一個對記憶體IC 進行資料寫入和讀取的模型
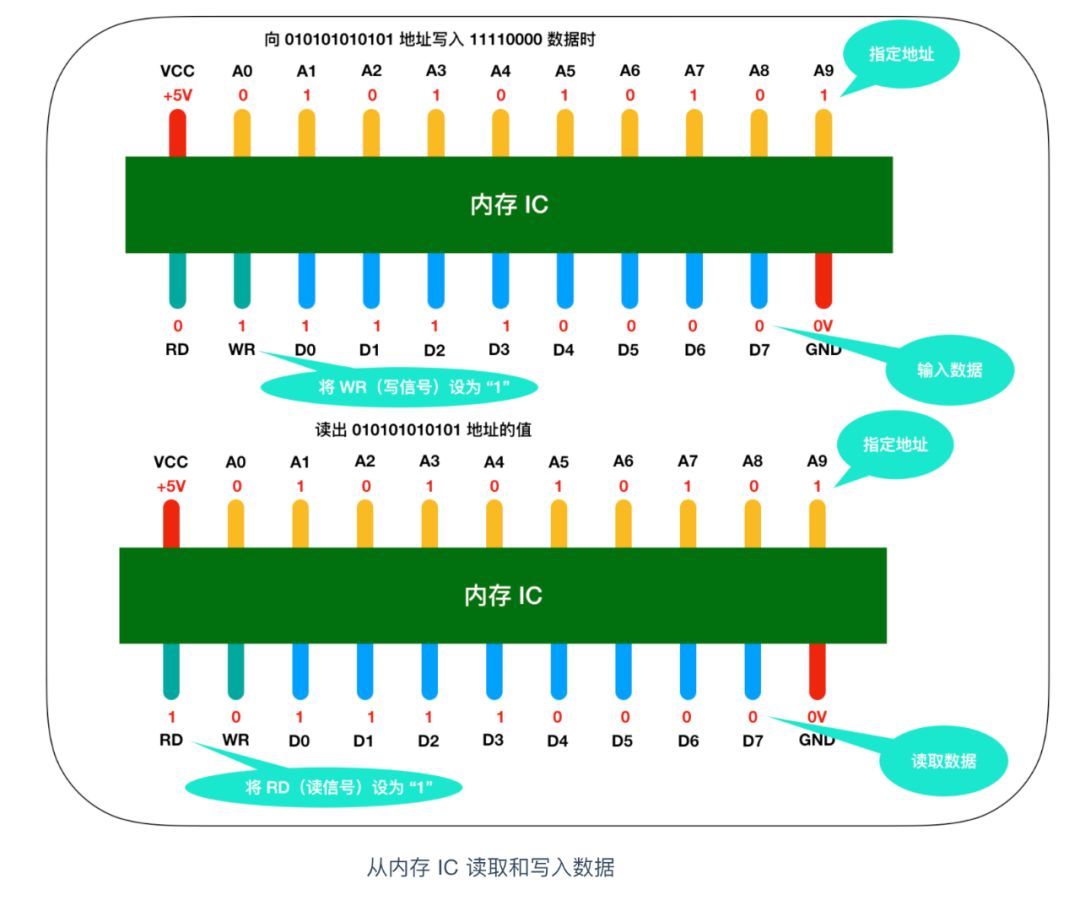
來詳細描述一下這個程序,假設我們要向記憶體 IC 中寫入 1byte 的資料的話,它的程序是這樣的:
-
首先給 VCC 接通 +5V 的電源,給 GND 接通 0V 的電源,使用 A0 - A9 來指定資料的存盤場所,然后再把資料的值輸入給 D0 - D7 的資料信號,并把 WR(write)的值置為 1,執行完這些操作后,即可以向記憶體 IC 寫入資料
-
讀出資料時,只需要通過 A0 - A9 的地址信號指定資料的存盤場所,然后再將 RD 的值置為 1 即可,
-
圖中的 RD 和 WR 又被稱為控制信號,其中當WR 和 RD 都為 0 時,無法進行寫入和讀取操作,
記憶體的現實模型
為了便于記憶,我們把記憶體模型映射成為我們現實世界的模型,在現實世界中,記憶體的模型很像我們生活的樓房,在這個樓房中,1層可以存盤一個位元組的資料,樓層號就是地址,下面是記憶體和樓層整合的模型圖
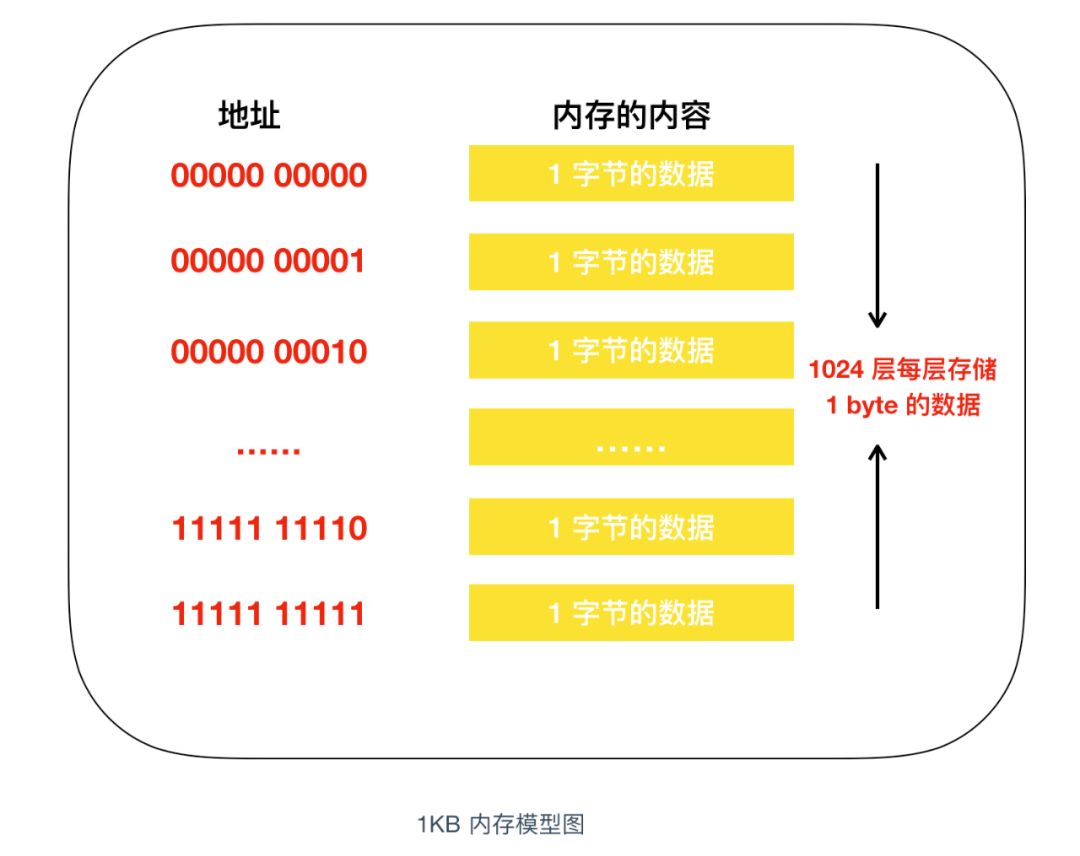
我們知道,程式中的資料不僅只有數值,還有資料型別的概念,從記憶體上來看,就是占用記憶體大小(占用樓層數)的意思,即使物理上強制以 1 個位元組為單位來逐一讀寫資料的記憶體,在程式中,通過指定其資料型別,也能實作以特定位元組數為單位來進行讀寫,
下面是一個以特定位元組數為例來讀寫指令位元組的程式的示例
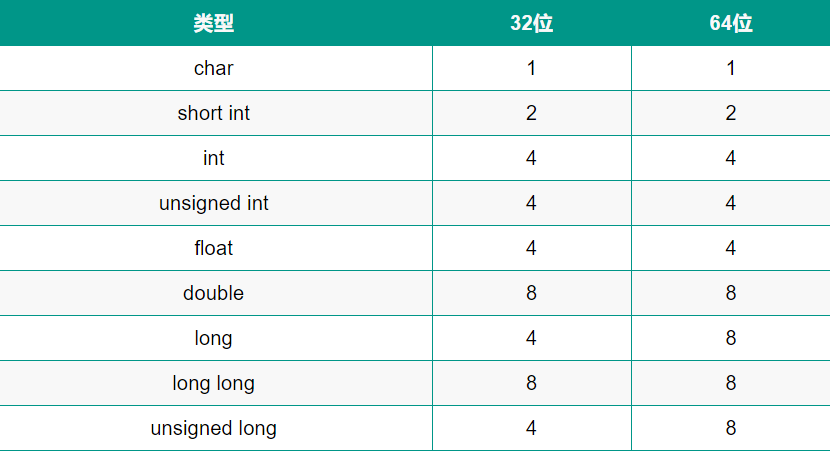
這三個變數分別表示 1 個位元組長度的 char,2 個位元組長度的 short,表示4 個位元組的 long,因此,雖然資料都表示的是 123,但是其存盤時所占的記憶體大小是不一樣的,如下所示
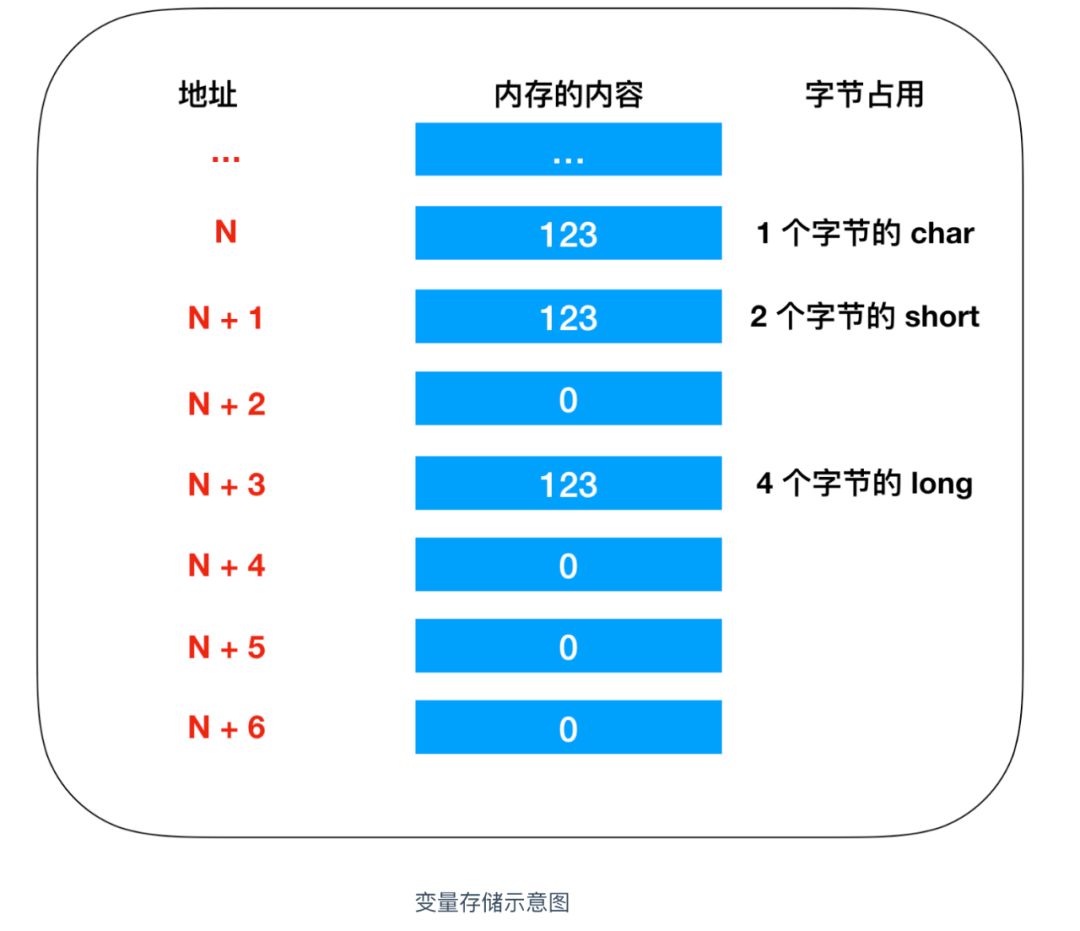
這里的 123 都沒有超過每個型別的最大長度,所以 short 和 long 型別為所占用的其他記憶體空間分配的數值是0,這里我們采用的是低位元組序列的方式存盤
低位元組序列:將資料低位存盤在記憶體低位地址,
高位元組序列:將資料的高位存盤在記憶體地位的方式稱為高位元組序列,
記憶體的使用
指標
指標是 C 語言非常重要的特征,指標也是一種變數,只不過它所表示的不是資料的值,而是記憶體的地址,通過使用指標,可以對任意記憶體地址的資料進行讀寫,
在了解指標讀寫的程序前,我們先需要了解如何定義一個指標,和普通的變數不同,在定義指標時,我們通常會在變數名前加一個 * 號,例如我們可以用指標定義如下的變數
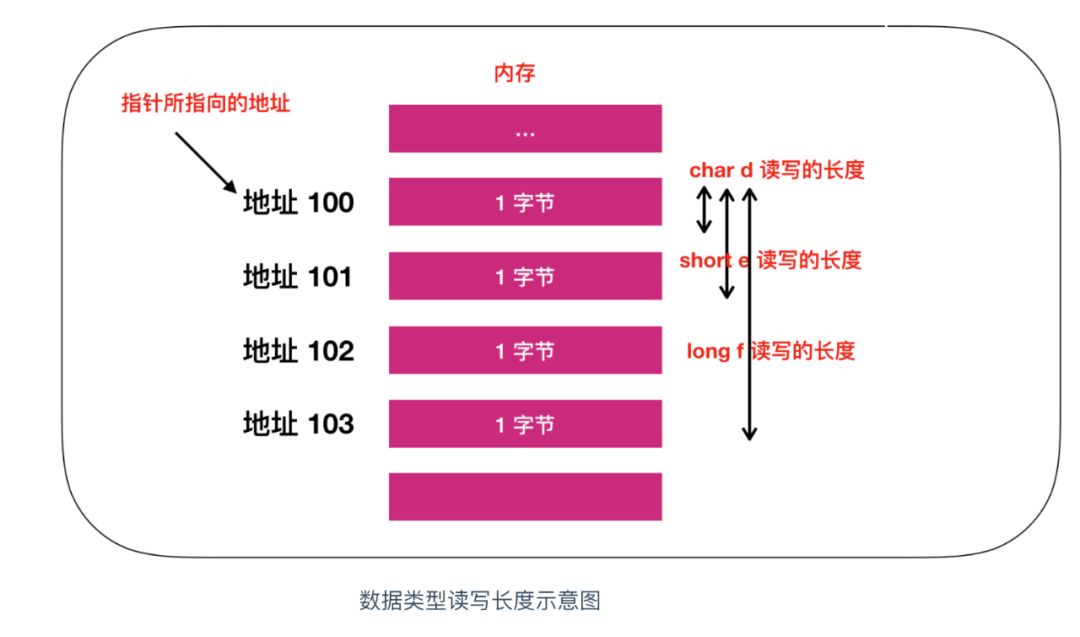
實際上,這些資料表示的是從記憶體中一次讀取的位元組數,比如 d e f 的值都為 100,那么使用 char 型別時就能夠從記憶體中讀寫 1 byte 的資料,使用 short 型別就能夠從記憶體讀寫 2 位元組的資料, 使用 long 就能夠讀寫 4 位元組的資料,下面是一個完整的型別位元組表
我們可以用圖來描述一下這個讀寫程序
陣列是記憶體的實作
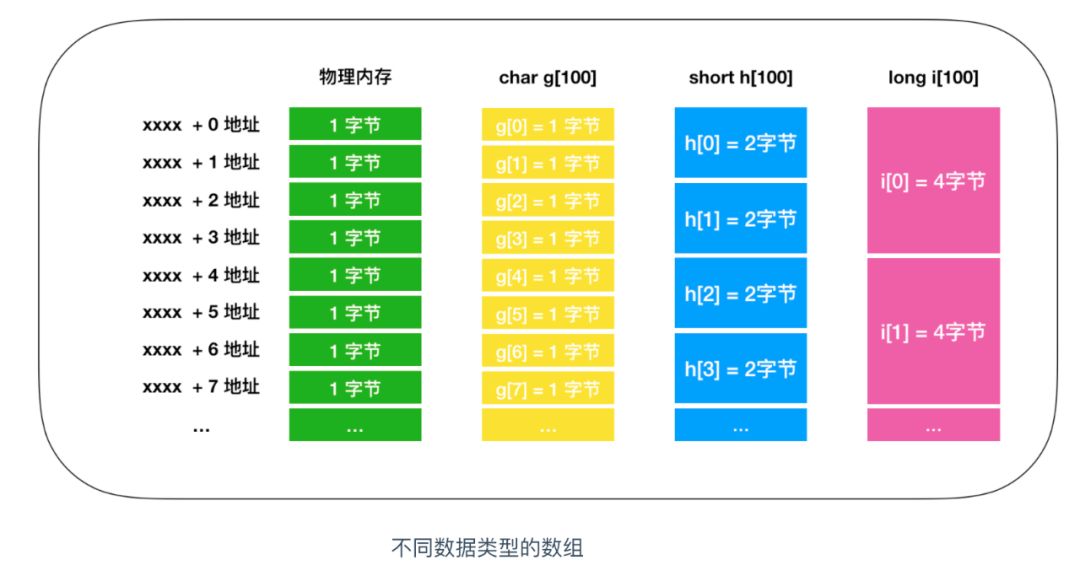
陣列是指多個相同的資料型別在記憶體中連續排列的一種形式,作為陣列元素的各個資料會通過下標編號來區分,這個編號也叫做索引,如此一來,就可以對指定索引的元素進行讀寫操作,
首先先來認識一下陣列,我們還是用 char、short、long 三種元素來定義陣列,陣列的元素用[value] 擴起來,里面的值代表的是陣列的長度,就像下面的定義
陣列是記憶體的實作,陣列和記憶體的物理結構完全一致,尤其是在讀寫1個位元組的時候,當位元組數超過 1 時,只能通過逐個位元組來讀取,下面是記憶體的讀寫程序
陣列是我們學習的第一個資料結構,我們都知道陣列的檢索效率是比較快的,至于陣列的檢索效率為什么這么快并不是我們這篇文章討論的重點,
堆疊和佇列
我們上面提到陣列是記憶體的一種實作,使用陣列能夠使編程更加高效,下面我們就來認識一下其他資料結構,通過這些資料結構也可以操作記憶體的讀寫,
堆疊
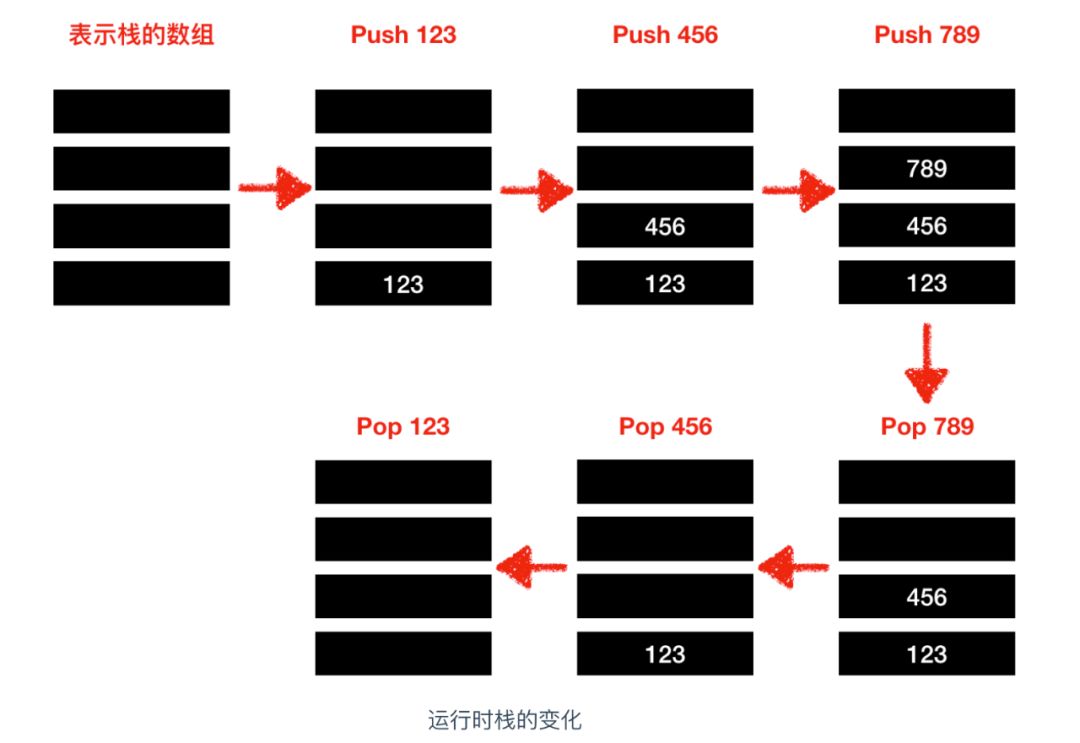
堆疊(stack)是一種很重要的資料結構,堆疊采用 LIFO(Last In First Out)即后入先出的方式對記憶體進行操作,它就像一個大的收納箱,你可以往里面放相同型別的東西,比如書,最先放進收納箱的書在最下面,最后放進收納箱的書在最上面,如果你想拿書的話, 必須從最上面開始取,否則是無法取出最下面的書籍的,
堆疊的資料結構就是這樣,你把書籍壓入收納箱的操作叫做壓入(push),你把書籍從收納箱取出的操作叫做彈出(pop),它的模型圖大概是這樣
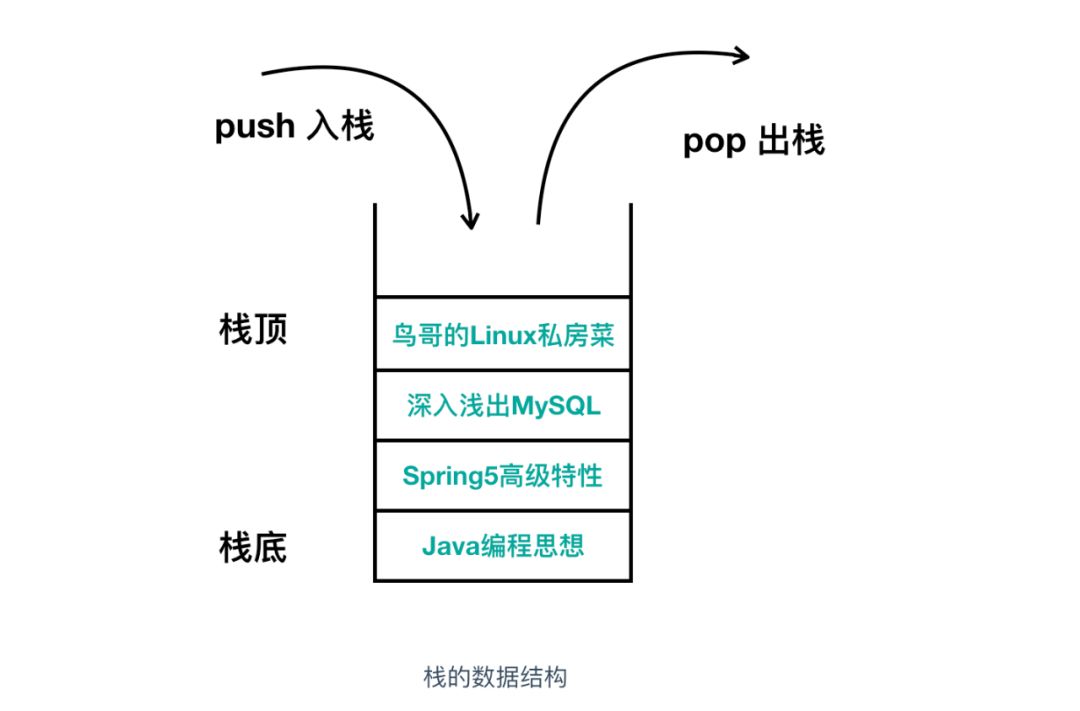
入堆疊相當于是增加操作,出堆疊相當于是洗掉操作,只不過叫法不一樣,堆疊和記憶體不同,它不需要指定元素的地址,它的大概使用如下
佇列
佇列和堆疊很相似但又不同,相同之處在于佇列也不需要指定元素的地址,不同之處在于佇列是一種 先入先出(First In First Out) 的資料結構,佇列在我們生活中的使用很像是我們去景區排隊買票一樣,第一個排隊的人最先買到票,以此類推,俗話說: 先到先得,它的使用如下
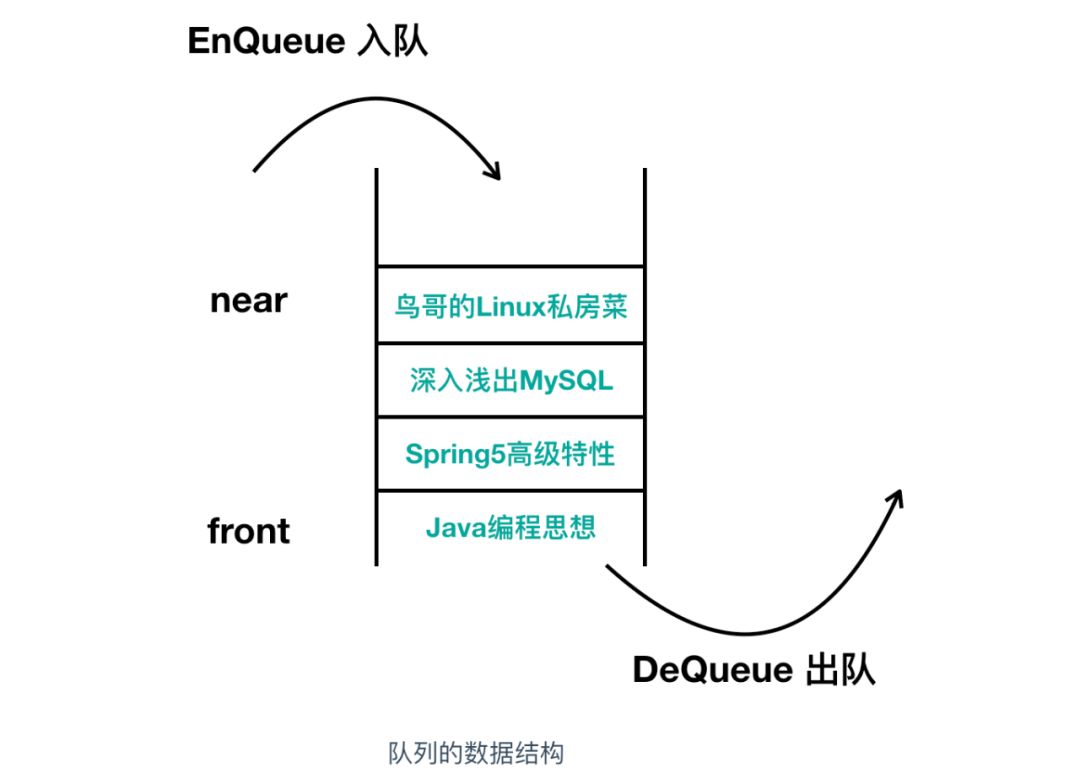
與堆疊相對,FIFO 的方式表示佇列中最先所保存的資料會優先被讀取出來,
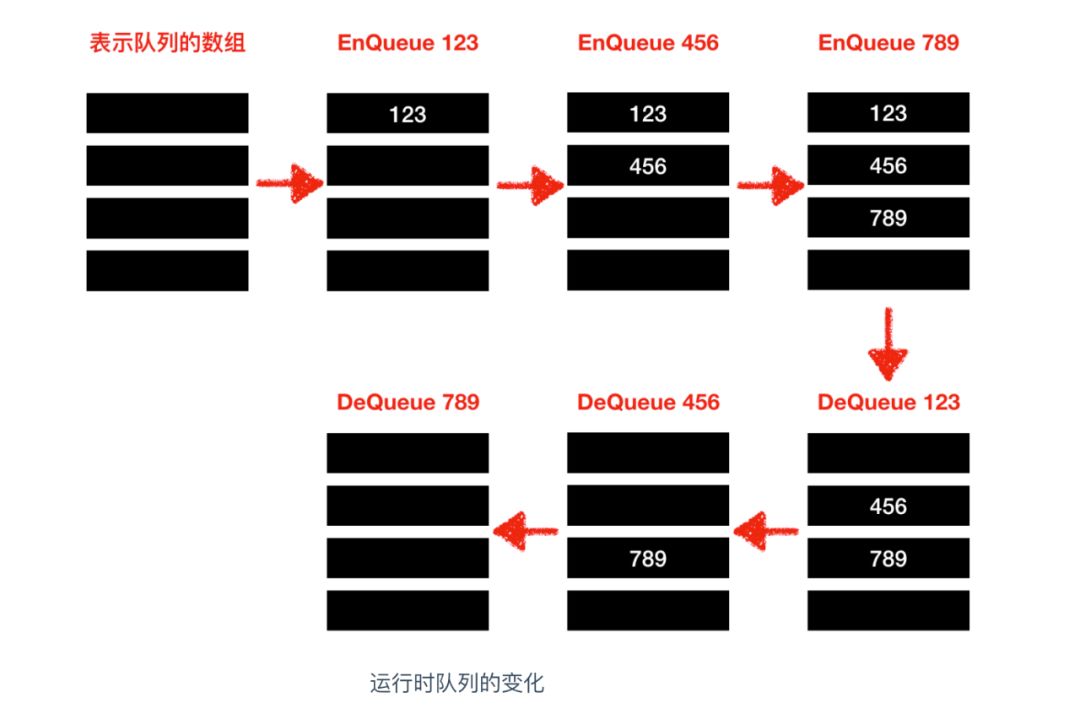
佇列的實作一般有兩種:順序佇列 和 回圈佇列,我們上面的事例使用的是順序佇列,那么下面我們看一下回圈佇列的實作方式
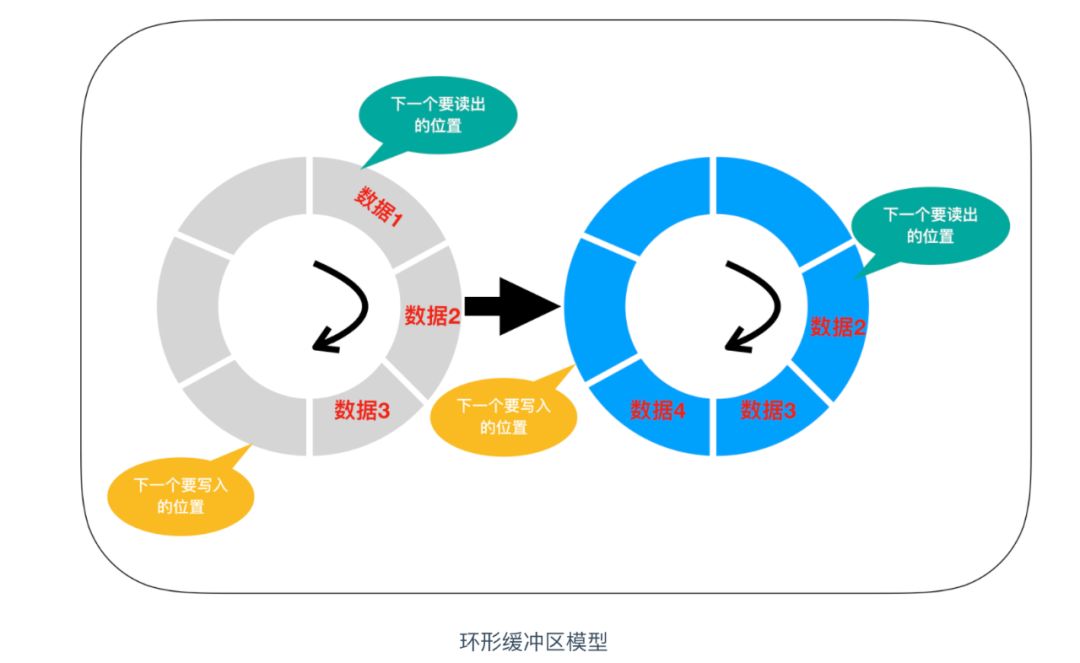
環形緩沖區
回圈佇列一般是以環狀緩沖區(ring buffer)的方式實作的,它是一種用于表示一個固定尺寸、頭尾相連的緩沖區的資料結構,適合快取資料流,假如我們要用 6 個元素的陣列來實作一個環形緩沖區,這時可以從起始位置開始有序的存盤資料,然后再按照存盤時的順序把資料讀出,在陣列的末尾寫入資料后,后一個資料就會從緩沖區的頭開始寫,這樣,陣列的末尾和開頭就連接了起來,
鏈表
下面我們來介紹一下鏈表和 二叉樹,它們都是可以不用考慮索引的順序就可以對元素進行讀寫的方式,通過使用鏈表,可以高效的對資料元素進行添加 和 洗掉操作,而通過使用二叉樹,則可以更高效的對資料進行檢索,
在實作陣列的基礎上,除了資料的值之外,通過為其附帶上下一個元素的索引,即可實作鏈表,資料的值和下一個元素的地址(索引)就構成了一個鏈表元素,如下所示
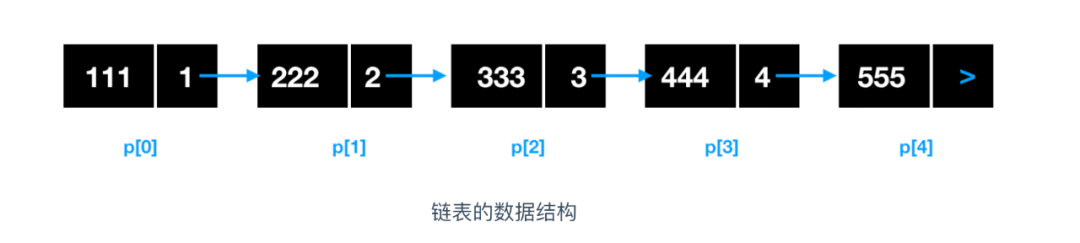
對鏈表的添加和洗掉都是非常高效的,我們來敘述一下這個添加和洗掉的程序,假如我們要洗掉地址為 p[2] 的元素,鏈表該如何變化呢?
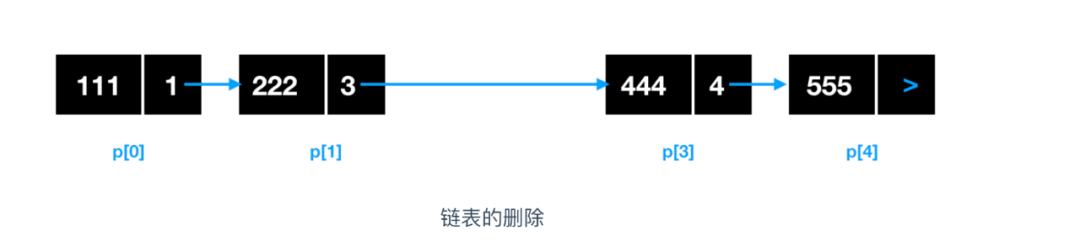
我們可以看到,洗掉地址為 p[2] 的元素后,直接將鏈表剔除,并把 p[2] 前一個位置的元素 p[1] 的指標域指向 p[2] 下一個鏈表元素的資料區即可,
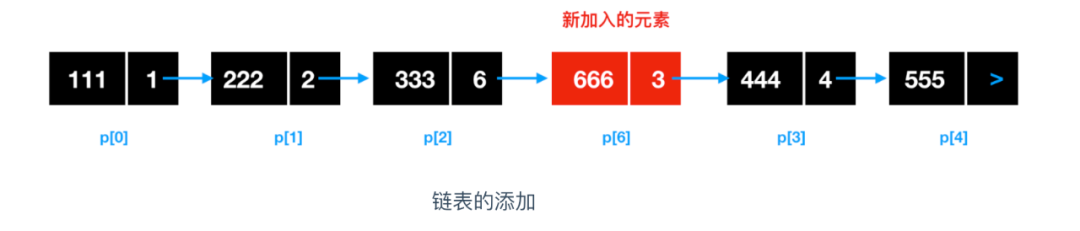
那么對于新添加進來的鏈表,需要確定插入位置,比如要在 p[2] 和 p[3] 之間插入地址為 p[6] 的元素,需要將 p[6] 的前一個位置 p[2] 的指標域改為 p[6] 的地址,然后將 p[6] 的指標域改為 p[3] 的地址即可,
鏈表的添加不涉及到資料的移動,所以鏈表的添加和洗掉很快,而陣列的添加涉及到資料的移動,所以比較慢,通常情況下,使用陣列來檢索資料,使用鏈表來進行添加和洗掉操作,
二叉樹
二叉樹也是一種檢索效率非常高的資料結構,二叉樹是指在鏈表的基礎上往陣列追加元素時,考慮到陣列的大小關系,將其分成左右兩個方向的表現形式,假如我們把 50 這個值保存到了陣列中,那么,如果接下來要進行值寫入的話,就需要和50比較,確定誰大誰小,比50數值大的放右邊,小的放左邊,下圖是二叉樹的比較示例
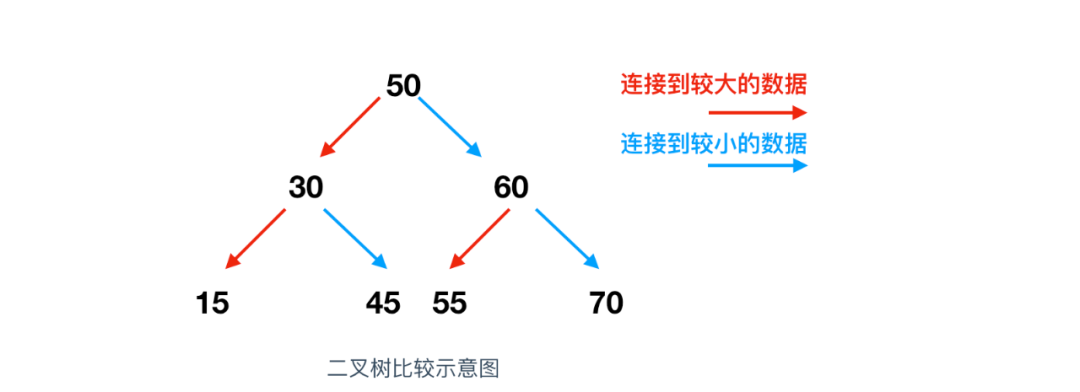
二叉樹是由鏈表發展而來,因此二叉樹在追加和洗掉元素方面也是同樣有效的,
這一切的演變都是以記憶體為基礎的,
作者簡介:cxuan 一個正在路上堅持信仰的技術人
最近他正在創作很多原創文章,都非常不錯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5368.html
標籤:其他