高級人工智能系列(一)——貝葉斯網路、概率推理和樸素貝葉斯網路分類器
初學者整理,如有錯誤歡迎指正,
原創地址
一、概率論基礎
1.1 樣本空間 Ω
樣本空間是隨機試驗中所有可能的取值的集合,
比如,擲骰子,結果有1-6 六種可能,那么樣本空間即:
\(Ω = \{1, 2, 3, 4, 5, 6\}\)
1.2 事件空間
樣本空間的一個子集,
1.3 條件概率
簡單地,現有事件A和事件B,
條件概率 P(A|B)表示事件A在事件B發生的條件下發生的概率,
條件概率計算公式:
\(P(A|B)\) = \(P(AB) \over P(B)\)
\(P(A|B_1,B_2,...,B_n)\) = \(P(A,B_1,B_2,...,B_n) \over P(B_1,B_2,...,B_n)\)
根據條件概率公式,可得到乘法公式:
\(P(AB)\) = \(P(A|B) P(B)\)
\(P(A,B_1,B_2,...,B_n)\) = \(P(A|B_1,B_2,...,B_n) P(B_1,B_2,...,B_n)\)
根據上式可以看出,乘法公式可以鏈式遞回,
觀察上述乘法公式,等式右側仍然包含聯合概率
\(P(B_1,B_2,...,B_n)\)
\(P(B_1,B_2,...,B_n)\) = \(P(B_1|B_2,...,B_n) P(B_2,...,B_n)\)
\(P(B_2,...,B_n)\) = \(P(B_2|B_3,...,B_n) P(B_3,...,B_n)\)
\(...\)
\(P(B_{n-1},B_n)\) = \(P(B_{n-1}|B_n)P(B_n)\)
整理可得:
\(P(B_1,B_2,...,B_n)\) = \(∏^n_{i=1}P(B_i|B_1,...,B_{i-1})\)
1.4 伯努利大數定律
在日常生活中,我們很自然地會使用頻率去估計一個事件的概率,那么其背后的理論是什么?是伯努利大數定律(??定綠),
伯努利大數定律告訴我們:
進行n重伯努利試驗(e.g. 拋n次硬幣),其中A事件發生了m次,其概率是p,頻率是\(m \over n\).那么,存在任意一個正數ε,使得:
\(lim_{n->∞}\) \(P\{|{m \over n} - p| < ε\} = 1\)
即n->∞時,頻率是依概率收斂到概率的,
二、貝葉斯法則
我們可以將\(P(A|B)\)和\(P(B|A)\)這兩個條件概率通過貝葉斯公式聯系起來:
\(P(A|B)\) = \(P(B|A) P(A) \over P(B)\)
- 其中\(P(A|B)\)叫做后驗概率,所謂后驗概率,就是說A在B發生的條件下發生的概率,是有一個先決條件的;
- \(P(A)\)叫做先驗概率,因為\(P(A)\)表示在沒有任何前提條件的情況下A發生的概率;
- \(P(B|A)\)叫做似然;
- 而\(P(B)\)叫做歸一化常數(即只把\(P(B)\)當作一個系數來對待),它可以通過全概率公式:
\(P(B)\) = \(∑_iP(B|A_i)P(A_i)\)
這里有必要解釋一下全概率公式以更好理解,把A看作一個整體,而B是其中的一部分,那么很容易得到P(B)就是B在A中的占比,現在,將A分成n分,即\(A_1\),...,\(A_n\),此時P(B)就變成了B在\(A_i\)中的占比,比上\(A_i\)在A中的占比,i是從1~n的整數,即上述的全概率公式,
三、貝葉斯網路
貝葉斯網路的拓撲結構是一個有向無環圖(DAG),其節點表示隨機變數,如果兩個節點之間有因果關系或者非條件獨立,則兩節點之間會建立一條有向邊,有向邊由父節點指向子節點,
下面是一個警報網路的貝葉斯網路圖:
上述貝葉斯網路圖表達的意思是:入室盜竊和地震都可能引發警報器報警,而警報器報警可能會讓John和Mary給主人打電話以通知主人,
3.1 貝葉斯網路的三種連接方式
貝葉斯網路中節點的連接方式有三種:順連、分連和匯連(下圖依次從左到右)
順連
當B未知時,變數A的變化會影響B的置信度的變化,從而間接影響C的置信度,所以此時A間接影響C,A和C不獨立,當變數B的置信度確定時,A就不能影響B,從而不能影響C,此時A和C獨立,因為此時A和C的通道被阻斷了,
分連
分連代表一個原因導致多個結果,當變數D已知時,變數E和F之間就不能相互影響,是獨立的,而當變數D未知時,D可以在變數E和F之間傳遞資訊,從而使變數E和F相互影響從而不獨立,
匯連
匯連與分連恰好相反,代表多個原因導致一個結果,并且當變數J已知時,變數G的置信度的提高會導致變數H的置信度的降低,從而H和H之間會相互影響所以是不獨立的,而當J未知時,變數G和H之間置信度互不影響,他們之間是獨立的,
總結
- 順連中,中間變數B未知時,A C不獨立,已知時獨立;
- 分連中,中間變數D未知時,E F不獨立,已知時獨立;
- 匯連中,中間變數J未知時,G H獨立,已知時不獨立,
3.2 貝葉斯網路中的全概率公式與概率表
貝葉斯網路中的全概率公式有Parent原則,即:
\(P(X_i)\) = \(∏P(X_i|Parent(X_i))\)
例如上述貝葉斯網路圖中,全概率:
\(P(B,E,A,J,M)\) = \(P(J|A) P(M|A) P(A|B,E) P(B) P(E)\)
如果某些變數不需要,只需要邊緣化不需要的變數(即使其不參與運算即可)
ps.倒是不好理解了,直接考慮\(P(X_i)\) = \(∏P(X_i|Parent(X_i))\)更容易理解一些,
那么,如何在貝葉斯網路中進行事件判斷?仍然以警報網路為例,可以看到每個事件發生的概率如下圖,其中根節點(B、E)是先驗概率,非根節點(A、J、M)則是后驗概率(條件概率):
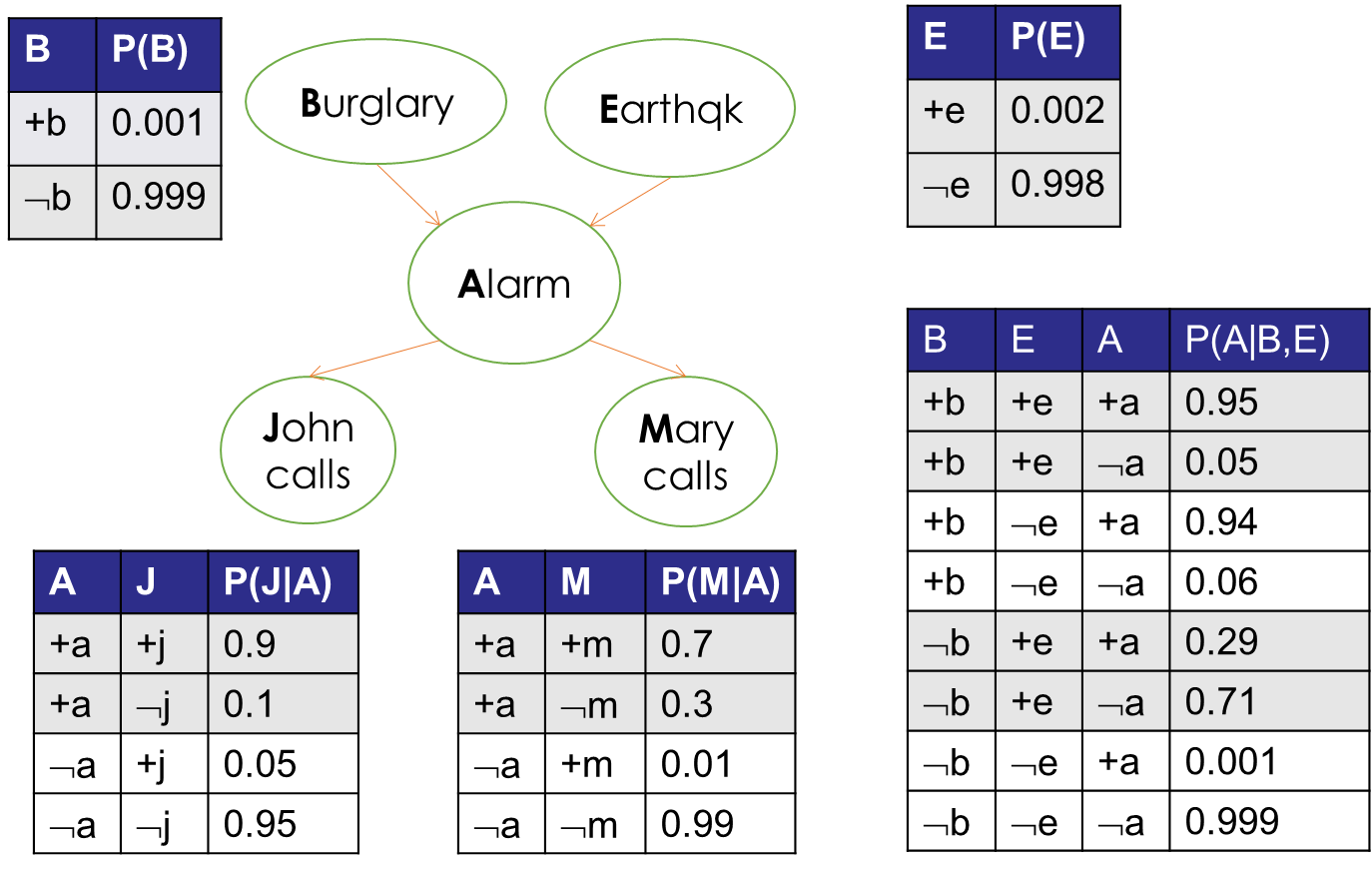
可以看到,上圖中每個節點都有一個概率表,表示當前節點在其父節點的條件下(后驗概率),不同取值的概率,通過概率表,可以方便地找到每個事件發生與否的可能性,比如:
說明在發生地震、沒有發生入室盜竊的情況下,警報器響鈴的概率
該事件定在了警報器,那么,只需要在警報器的概率表中尋找“+e、-b、+a”的概率,得到結果0.29,
四、概率推理
概率推理屬于推理的一種形式,是根據一系列不確定的資訊作出決定時的推理,比如,仍然是第三節中警報網路的例子,其中一個概率推理可以是:
John給主人打電話,警報響了,在這種情況下發生入室盜竊的概率,
實際上,概率推理在實際生活中應用非常廣泛,比如醫療行業,我們去醫院進行多項檢查,會得到很多結果,那么如果推斷我們可能會有哪些疾病呢?就可以根據一系列檢查數值作為前提,進行概率推理,從而得出患有某種疾病的概率,
概率推理是基于貝葉斯網路及其概率表進行計算的,概率表是根據一個節點的父節點進行條件概率計算得到的,然而只有概率表中的條件概率并不足夠推理,但是它可以作為概率推理計算的基礎,
概率推理有大類:精確推理和近似推理,我們依次進行介紹,
4.1 精確推理
顧名思義,精確推理需要完整地計算從而得到結果,我們通過例子來理解精確推理,
舉一個醫療相關例子:
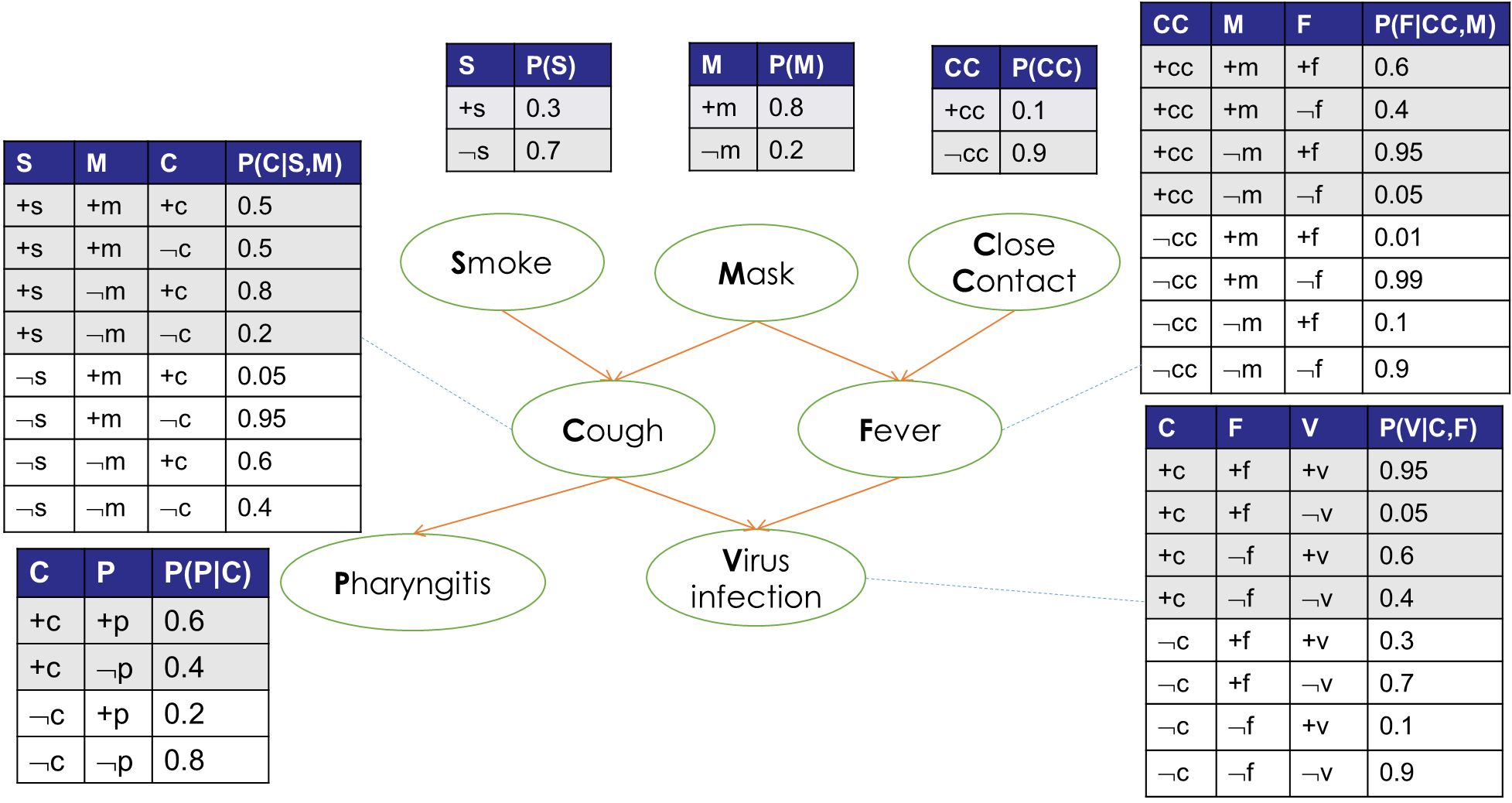
上圖是一個貝葉斯網路圖,其中概率表已經給出,下面,需要計算:
- 在一個人戴口罩(Mask+)、患了咽炎(Pharyngitis+)且沒有密接(Close Contact-)的情況下,他吸煙(Smoke+)的概率,
這看似是一個很奇怪的問題,事實上,通過概率推理,可以得出結果,因為這是一個簡單的條件概率:
\(P(S+|M+,P+,CC-)\) = \(P(S+,M+,P+,CC-) \over P(M+,P+,CC-)\)
= \(P(S+,M+,P+,CC-) \over {P(S+,M+,P+,CC-) + P(S-,M+,P+,CC-)}\)
現在,只需要計算\(P(S+,M+,P+,CC-)\)和\(P(S-,M+,P+,CC-)\),即可得到目標結果,
其中,
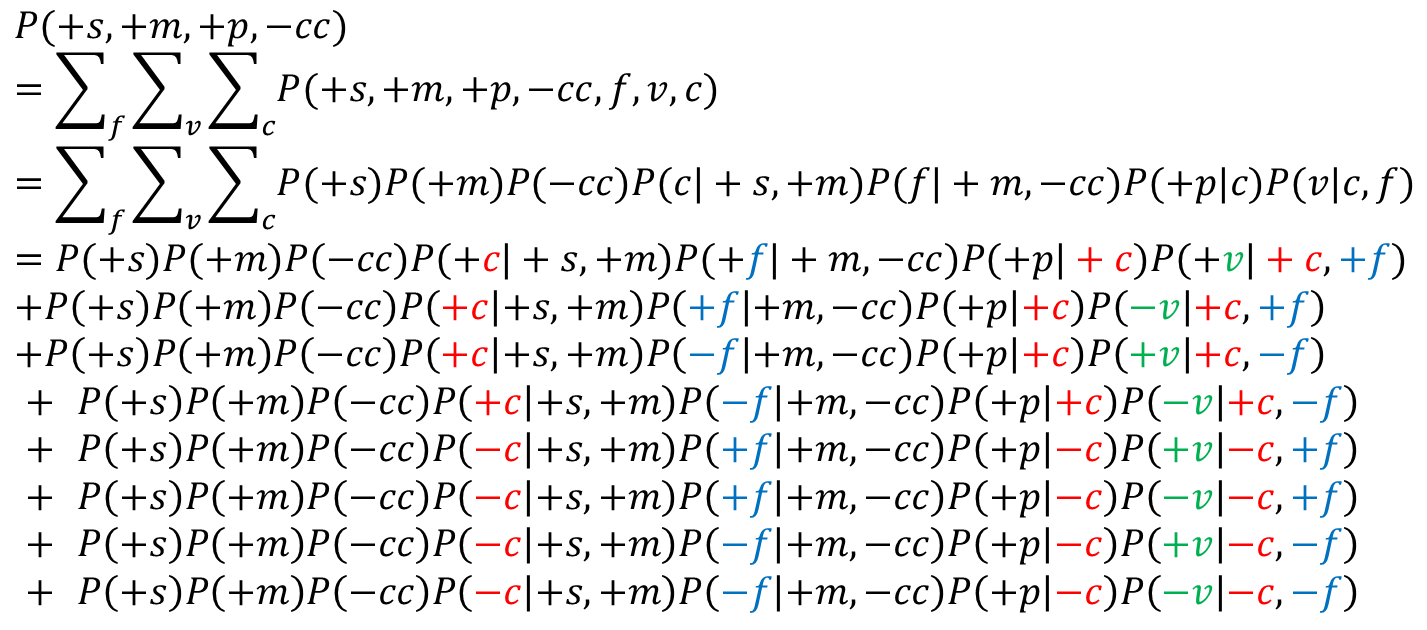
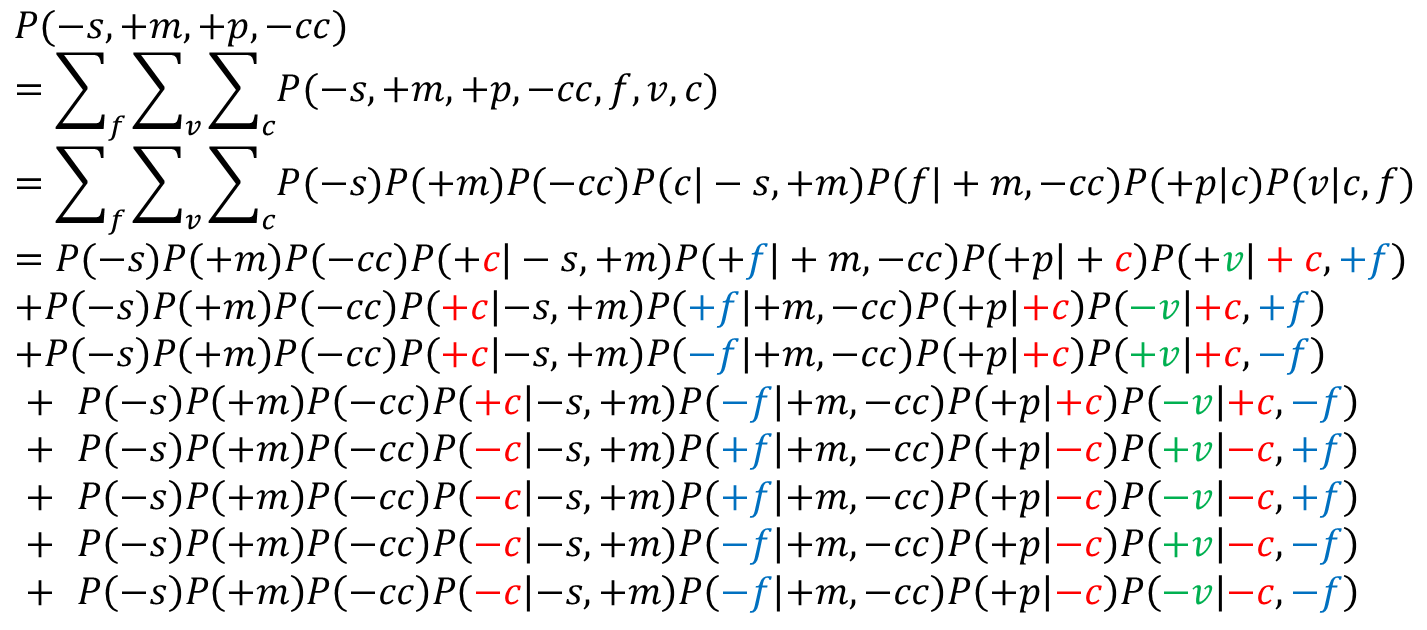
其中,聯合概率計算通過3.2節介紹的Parent原則得到,這里不再贅述,
可以看到,未參與聯合概率運算的隱變數,需要對其每個可能的取值都取一遍,因為在這個例子中,F,V,C的取值均為“取或不取”兩種,所以可以看到,每個隱變數都需要取+和-兩個值,這時,∑求和項數為 \(2^n,(n=3)\)個
為何將分母拆成兩項?不拆開不也是計算分子和分母兩個聯合概率嗎?其實拆開后更加簡單,因為原分母有三個變數已知,S、C、F、V四個變數未知,這樣會增加計算項數,即∑求和項數會從\(2^3\)增加到\(2^4\)個,
其中,聯合概率分解后的條件概率或先驗概率,均可以在概率表中查閱到,進行計算即可得到最終結果,
4.2 近似推理
可以看到,精確推理計算復雜度非常高,上述例子僅僅是三個隱變數,就已經需要大量計算了,在實際情況下,隱變數個數甚至可以為百余個,假設每個變數取值有兩個,那么也需要\(2^{100}\)項,這是無法在短時間計算出結果,
此時,需要進行近似推理,近似推理的思想就是采樣,采樣是以概率論相關知識作為背景的,即:從一個總體中采樣,那么得到的樣本是可以近似總體的,因為樣本和總體具有一致性,
近似推理有三種方法:亂數生成法、拒絕采樣和似然加權采樣,下面分別進行介紹,
4.2.1 亂數生成法
對于精確計算比較復雜的情況,可以使用亂數生成器進行采樣,得到樣本來進行近似估計,
舉一個例子以更好理解,貝葉斯網路和概率表見下圖:
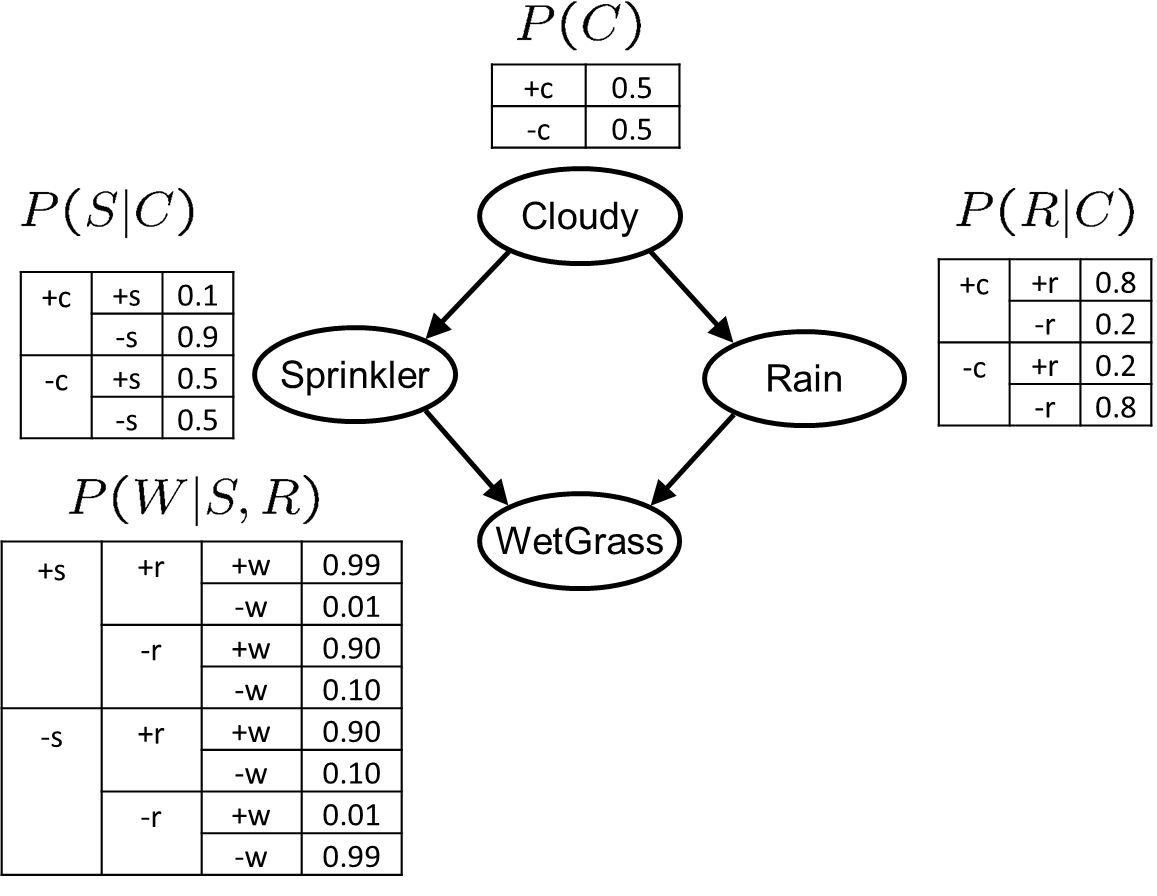
其中,Cloudy表示是否是多云天氣;Sprinkler表示草叢澆灌設備是否作業;Rain表示是否下雨;WetGrass表示草叢是否干燥,
現在問:
草叢不是干燥的,那么今天下雨的概率是多少?
如果進行精確推理,需要計算:
\(P(+R|-W)\) = \(P(+R,-W) \over P(-W)\)
= \(P(+R,-W) \over {P(+R,-W) + P(-R,-W)}\)
除W、R外,還有隱變數C,S,即共需要計算 \(2 * 2^2\)項,每項需要計算3次乘法,計算量對于人工來說還是有一些的,
那么,如何使用亂數生成法呢?步驟如下:
- 對于n個節點,需要n個亂數生成器,每個亂數生成器負責一個節點的亂數生成;
- 需要從根節點開始進行亂數生成,直到所有節點均已生成亂數;
- 對于每個節點,根據亂數的范圍(0-1)進行選擇(e.g. +或者-);
- 需要注意的是,父節點的選擇,會影響其選擇,具體可通過下面例子感受,
根據上述步驟,我們實際操作一遍,
1.首先根節點C的亂數生成器開始作業,假設生成了亂數0.3,即對應了+C;
2.下面節點S的亂數生成器開始作業,假設生成了亂數0.6,請注意!S是要受父節點C的選擇的影響,
因為C選擇了+C,那么就要在+C的條件下去對應0.6,得到了結果-S;
3.同理,假設節點R的亂數生成器生成了0.4,那么需要在+C的條件下去對應0.4,得到了結果+R;
4.節點W的亂數生成器生成了0.9,那么需要在-S和+R的條件下對應0.9,得到了結果+W,
這一次生成得到的結果是:
+C -S +R +W (1)
假設接下來生成的結果如下:
-C +S -R -W (2)
+C -S +R -W (3)
+C -S +R +W (4)
-C +S -R +W (5)
...
還記得問題嗎?
草叢不是干燥的,那么今天下雨的概率是多少?
如何通過上述生成的5個樣本,來估計這個概率?
- 首先,要找到符合結果的樣本,即草叢不是干燥的:-W;
- 然后,在符合-W的樣本中,去計算下雨:+R的概率,
得到的5個樣本中,符合-W的是(2)(3)樣本,其中+R的是(3),那么可以得到問題的答案是:50%,
(因為樣本過少,得到的結果不夠準確,這里是用頻率來估計概率,考慮伯努利大數定律,當樣本數量足夠大時,頻率是依概率收斂到概率的,)
4.2.2 拒絕采樣
考慮4.2.1中的問題,其中只有W和R兩個變數用到了,而隱變數C和S完全沒有用到,但是使用亂數生成法時,仍然耗費時間去生成了它們對應的亂數了,
所以,可以考慮在生成亂數的程序中檢測是否是一定不符合需要的一個結果,如果是,則在中途就停止本次結果的生成,這可以減少一定的時間耗費,
仍然是4.2.1中的問題,因為我們需要-W和+R的結果,那么,可以在檢測到+W或者-R時,直接停止本次結果生成:
+C -S +R (停止) (1)
-C +S (停止) (停止) (2)
+C -S +R -W (3)
+C -S +R (停止) (4)
-C +S (停止) (停止) (5)
...
這就是所謂的拒絕采樣,即,拒絕繼續采樣每個結果中對計算概率無用的部分,
4.2.3 似然加權采樣
拒絕采樣的確可以減少一定的計算量,但是還不夠徹底,因為中途停止的一次結果浪費掉了,但仍然耗費了一定的時間,
那么,可不可以直接生成完全符合目標的依次結果呢?答案是可以的,
仍然以4.2.1中的問題為例:
草叢不是干燥的,那么今天下雨的概率是多少?
其中只有一個條件,那就是-W,那么此時就把-W固定,即相當于讓每次結果中W的值都為-W,然后其余的變數結果繼續隨機生成,通過這樣,可以完全減少一個變數的隨機生成,假設前5次的結果如下:
+C -S +R | -W (1)
-C +S -R | -W (2)
+C -S +R | -W (3)
+C -S +R | -W (4)
-C +S -R | -W (5)
現在,我們需要在-W的基礎上計算+R的概率,得到結果60%,
但是,這真的是正確的嗎?不正確,
因為我們定了一個大前提,就是-W,也就是說,現在W一定是-W,這很顯然是不正確的,
此時,需要進行似然加權,即給每一行結果加上一個概率權值,這個概率權值,就是我們定的變數值發生的概率是多少,這個概率就是這個變數的概率表中對應本行中其父節點們的取值的那一行,來看例子(下圖是4.2.1節中的概率表,為了方便這里再次參考):
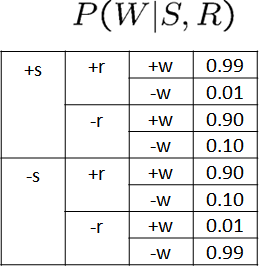
比如:W的父節點們是S和R,在(1)行中,取值是-S和+R,那么就是在\(P(W|S,R)\)這個概率表中找對應-W,-S和+R的那一行,其概率是0.1,依次得到其余行的概率表中的概率:
+C -S +R | -W (1) p = 0.1
-C +S +R | -W (2) p = 0.01
+C -S +R | -W (3) p = 0.1
+C -S -R | -W (4) p = 0.99
-C +S -R | -W (5) p = 0.1
其中p是發生概率,也就是權值,
這個權值代表什么?因為這個權值表示:這一個結果出現的概率是p,可以認為,現在并不是一個結果,而是“p”個結果,比如(1),其p=0.1,可以理解為,如果這一條結果出現了0.1次,
這樣,我們在計算頻率時,不應該將一行當作一個資料看,而是應該當作p個看,此時,要計算-W的前提下+R出現的概率,就應該是:
\((0.1 + 0.01 + 0.1) \over (0.1+0.01+0.1+0.99+0.1)\) = \(16\%\)
這就是似然加權估計,即,每一條結果不是一個結果,而是出現的概率個結果,
五、樸素貝葉斯網路分類器(Naive Bayesian Classifier)
這里只做簡單介紹,
所謂樸素,就是簡單的意思,
一個樸素貝葉斯網路只有一個根節點,其余全部是葉子節點:
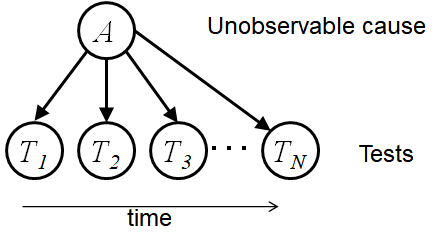
通過這個貝葉斯網路,我們可以計算:
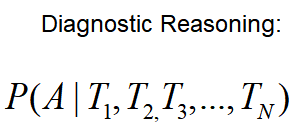
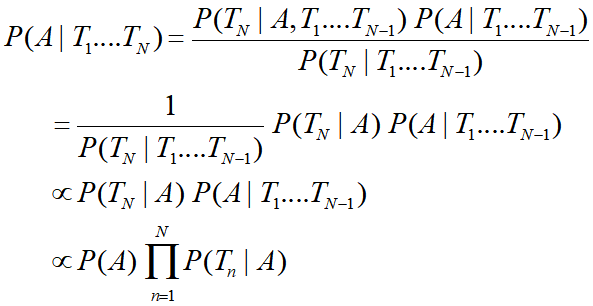
(這里用到了“3.1貝葉斯網路三種連接方式”的知識)
假設\(T_1\)-\(T_n\)是一次體檢的各項指標,那么A就可以是體檢的一個結果(某項疾病),
參考資料
1.東北大學 高級人工智能 2022秋
2.https://blog.csdn.net/cxjoker/article/details/81878188
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/536902.html
標籤:其他
下一篇:NOIP考綱(參考)