隱私資訊檢索(Private information retrieval PIR)也稱為隱匿查詢或匿蹤查詢,在醫療、股票、金融、社交等領域中都有大量應用場景,近年來PIR技術研究逐漸豐富,行業對應用PIR實作隱私保護的呼聲也隨之高漲,
引言
[SealPIR][1]是微軟開源的PIR實作,實作了2018年發表在IEEE S&P的論文[ACLS18][2]中的PIR方案,論文題目《PIR with Compressed Queries and Amortized Query Processing》已經包含了兩個主要的貢獻點:-
對查詢進行了壓縮,通信量降低了274倍;
- 通過概率批量編碼(probabilistic batch codes PBCs)可以同時執行多個查詢,分攤查詢處理的開銷,
在近年的PIR協議研究中,特別是基于HE的PIR協議有很多進展,且大多數都是和SealPIR進行對比,因此理解SealPIR的原理也就有助于理解和跟蹤he-based PIR近年來的發展,
本文將為小伙伴們介紹基于同態的隱私資訊檢索協議-SealPIR,歡迎大家在本文留言討論,
1.PIR定義及分類
1.1 PIR定義
隱私資訊檢索(Private information retrieval PIR)是對資訊檢索(information retrieval IR)的一種擴展,最早在[CKGS95][3]中提出,用于保護用戶查詢資訊,防止資料持有方得到用戶的檢索條件,
PIR協議目標可以定義為:Alice有共N行的資料庫D,每一行的資料大小為L,Bob希望查詢獲得其中指定位置的某一行,但是不想告訴Alice自己查詢的是哪一行,
隱私資訊檢索協議(PIR)需要滿足正確性和安全性兩方面的要求:
-
正確性:用戶得到要查詢的資料
-
安全性:服務端 無法知道 用戶查詢的是哪條資料
1.2 PIR分類
1.2.1 服務器數量分類
按照服務器數量分類可分為多服務器PIR和單服務器PIR,-
多服務器PIR(MultiServer-PIR)
多服務器PIR協議大體流程如下:
- 客戶端生成查詢條件的分量,發送給不同的服務器;
- 服務器收到查詢條件的分量后進行相應的計算,回傳給客戶端;
- 客戶端接收到所有服務器的回應后,將服務器查詢回應看做秘密共享的分量進行合成,得到查詢結果,
-
單服務器PIR(SingleServer-PIR)
基于同態的單服務器PIR方案,大體流程如下:
- 客戶端生成加密的查詢向量,發送給服務端;
- 服務端接收到查詢向量后,在本地執行同態運算,將結果回傳給客戶端;
- 客戶端收到回應后,解密得到查詢結果,
1.2.2 按照檢索條件分類
- Index PIR/Dense PIR
服務端有n個元素的資料庫??={??1,??2,…,????},用戶查詢第??個元素,通過執行PIR協議,用戶得到????,服務端不知道用戶查詢??的資訊,由于用戶的查詢條件在一個連續的集合[1…??],Index PIR也稱為Dense-PIR,
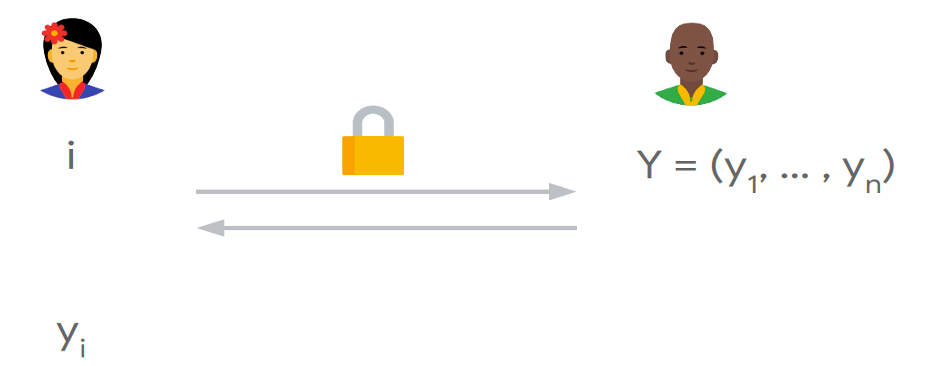
-
Keyword PIR/Sparse PIR
服務端的資料是(key,value)對構成的n個元素的資料庫,用戶選擇自己要查詢的key,通過執行PIR協議,用戶得到key對應的value,這里查詢條件key不能覆寫一個連續集合,例如:手機號或身份證,也稱為Sparse PIR,
1.3 PIR性能指標
PIR的性能指標主要包括計算量和通信量,
-
計算量:計算量一般指的是服務端的計算量,
-
通信量:通信量可細分為查詢請求的通信量和回應的通信量,
Trivial PIR中服務端沒有計算量,將資料全部發給客戶端,客戶端在本地查詢,通信量跟資料庫中資料量n相關,因此PIR的通信量要求小于資料庫的容量,對比IT-PIR和CPIR的計算量和通信量可以看到,IT-PIR在計算量較少,但通信量較大;CPIR計算量較大,但通信量較小,
除了計算量和通信量兩個指標外,有些論文里還引入了成本(monetary)作為指標,成本(monetary)指標實際上是對計算量和通信量平衡得到的指標,更適用于實際業務需求,
2.基礎知識
目前Single-PIR最好的協議大多基于近似同態演算法(Somewhat homomorphic encryption SHE)設計的,SealPIR中用到的是[BFV12][5]演算法,2.1 BFV方案
[BFV12]將[Brakerski12][6]中的同態演算法從LWE遷移到RLWE,RLWE因為有特殊的結構比LWE性能更好,例如,RLWE選擇特定引數時,乘法可以使用NTT(Number Theoretic Transform),BFV演算法的引數包括:- 多項式次數: ??
- 明文模: ??,素數
- 密文模: ??,若干素數的乘積
| 多項式次數 | 明文模 | 密文模 |
| 2048 |
54bit |
|
|
4096 |
38bit |
109bit 2*36+37 |
|
8192 |
17bit |
218bit 243+344 |
SealPIR中用到的同態運算:
-
密文加法:
明文??1(??),??2(??)對應的密文是??1和??2,??1+??2是??1(??)+??2(??)的密文,
-
明文乘密文:
明文??1(??)對應的密文是??1,??2(??)·??1是??1(??)·??2(??)的密文,
-
替換:
明文??(??)對應的密文是??,對于奇數??,??????(??,??)是??(????)的密文,
例如,??(??)=7+??2+2??3,??????(??,3)得到??(??3)=7+{??3}2+2{??3}3=7+??6+2??9的密文,
SHE的同態運算會引起噪聲的增長,當噪聲超過一定限制時,無法解密得到明文,所以要適當選擇SHE演算法的引數,及控制同態運算的噪聲增長,
2.2 HE-based PIR
HE-based PIR基本原理如下圖所示:
假設服務端資料量為??,基本流程如下
- 客戶端生成BFV演算法的私鑰和公鑰(????,????);
- 客戶端生成查詢??維0-1向量(0,...,0,1,0,...,0),其中查詢index ??的位置位1,其它位置為0;
- 客戶端使用公鑰加密查詢向量的每個分量,得到(??(0),...,??(0),??(1),??(0),...,??(0)),發送給服務端;
- 服務端接收到密態查詢向量后,和本地資料構成的??維向量(??1,??2,...,????),進行點乘,得到??(0·??1+...+0·????-1+????+0·????+1+...+0·????),發送給客戶端;
- 客戶端對查詢回應密文解密,得到待查詢的資料????,
HE-based PIR協議可以抽象為四個子演算法,即(Setup,Query,Answer,Extract),如下圖所示:
- SETUP: 服務端 將資料庫中的資料轉換為HE明文
- QUERY: 客戶端根據查詢index,生成密態查詢向量
- ANSWER: 服務端計算明文向量和密文向量的內積
- EXTRACT: 客戶端使用私鑰解密查詢回應密文,得到查詢資料
3.SealPIR協議
HE-based PIR基本原理中的協議,存在的問題是-
查詢請求的計算量和通信量都大,需要生成和發送??個密文;
- 服務端每個資料表示為一個HE明文,需要計算n為向量的內積,容易導致噪聲太大,無法解密
3.1 將多個資料pack到一個HE明文
查詢的db_index需要轉換為plaintext_index
假設資料庫中資料長度為288位元組(SealPIR論文中給出的長度),BFV引數選擇:多項式次數8192,明文模16bit,舉例說明一下pack的效果:
- 資料庫中每條資料,需要HE 明文多項式中個系數來表示????????(288*8/16)=144,
- HE 一個明文多項式可以包含??????????(8192/144)=56調資料庫資料,
- 對資料庫的查詢db_idx,需要轉換為明文的查詢plain_index=??????????/56,
- 用戶得到查詢相應密文,通過私鑰進行解密,得到HE明文,將HE明文對應的系數進行組合,得到真正查詢的資料,
3.2 將查詢向量壓縮到一個密文
顯著減少通信量,服務端增加一個額外的Expand操作得到查詢密文向量,
查詢向量(0,...,0,1,0,...,0)壓縮到一個HE明文多項式為例,查詢向量中的每個分量對應為HE明文多項式中的系數,
??0+??1??+...+????-2????-2+????-1????-1=????????????_??????????,其中:????=0,??≠??????????_?????????? , ????=1,??=??????????_??????????,
對查詢明文進行加密,得到??(??0+??1??+...+????-2????-2+????-1????-1)=??(????????????_??????????),
服務端接收到查詢密文后,執行Expand演算法,得到查詢密文向量:(??(0),...,??(0),??(1),??(0),...,??(0)),
還是以上面packing的引數舉例,每個HE明文可以pack 56個資料庫資料,客戶端查詢時,將db_index轉換為plain_index,即對HE明文資料庫進行查詢,最多可以查詢8192個HE明文,轉換成資料庫資料,最多可以查詢8192*56=458752條資料,不能滿足實際業務中的需求,
為了滿足實際將查詢向量壓縮到多個HE明文來表示查詢向量,對于百萬資料來講,需要????????(1000000/8192)=123個HE明文,對應123個HE密文,才能表示百萬資料的查詢向量,為了進一步壓縮查詢密文的數量,可以使用下面的多維表示方法,
Expand演算法的詳細描述和證明可以參考[ACLS18][2]論文中的內容,
3.3 將資料庫一維向量轉換為多維向量
二維查詢時將資料庫資料表示為√??*√??的矩陣,減少查詢向量
服務端:
- 將HE明文表示為√??′*√??′的矩陣??,其中√??′<8192,
- ????是密文查詢列向量,????=??·????,其中????是√??′ * 1的密文列向量,
- 將????中每個密文拆分為??份明文多項式,得到√??′ * ??矩陣??????,
- ????是密文查詢行向量,????????·????,?? * 1得到的密文向量,
客戶端:
-
客戶端收到??個密文向量,使用私鑰????解密,將其組合成密文??????(??[??,??]),對使用私鑰????解密??????(??[??,??])得到真正的查詢HE明文??[??,??],對HE明文??[??,??]中對應的系數進行組合,得到真正查詢的資料,
3.4 通過一次進行多個查詢降低整體性能開銷
SealPIR論文中還給出了通過PBC(probabilistic batch code)將資料庫中的內容分成若干batch,同時執行k個查詢時,分別對不同的batch進行查詢,降低整體的性能開銷,論文給出了基于CuckooHash的PBC構造方案,
CuckooHash的hash數為3,bin數量為1.5??,k為同時查詢的數量,
服務端 預處理:
-
對DB中n個index,分別計算cuckooHash的3個Hash,得到3個bin_index,將(db_index, data)插入到3個bin_index中,
客戶端 預處理:
-
對DB中n個index,分別計算cuckooHash的3個Hash,得到3個bin_index,將(db_index)插入到3個bin_index中,
-
將k個查詢,通過cuckooHash,插入到??=1.5??個bin中,對空的bin進行隨機填充,
- 對每個bin執行PIR,共計b個PIR,每個PIR的index,是客戶端實際查詢的data_idx,在bin中的索引,
從上圖中可以看到,客戶端生成的是CuckooHashTable和SimpleHashTable兩張表,服務端生成的SimpleHashTable,客戶端和服務端SimpleHashTable的差別在于,服務端SimpleHashTable有實際待查詢的資料,服務端SimpleHashTable只是模擬了服務端插入程序,bin中有db_index,
3.5 SealPIR的性能
SealPIR論文Figure里給出single_query和multi-query的性能資料,多項式次數是2048,明文模式20bit,密文模式60bit,資料長度288位元組,資料量220,4.其它改進協議
這里介紹一下21年的兩篇PIR方面的文章:-
發表在USENIX21年的[ALP+21][7]
-
發表在CCS21年的OnionPIR:[MCR21][8]
[ALP+21]題目是《Communication–Computation Trade-offs in PIR》是計算量和通信量平衡的PIR方案,該方案顯著降低了查詢回應的通信量,從成本(monetary)的角度看比SealPIR降低了35%,
OnionPIR利用了somewhat homomorphic encryption(SHE)最新的進展,將兩種lattice-based SHE 方案(BFV 和 RGSW)組合在一起,降低了查詢回應的大小和計算量,還設計了基于狀態(stateful)的PIR,
從上面的資料看到,雖然相應的改進協議對查詢回應大小都有較大改進,但整體運行時間方面和SealPIR差別不大,由于引入了更復雜的演算法,實作成本也會變得更高,綜合來看SealPIR在實際應用中還是相對較好的選擇,
參考文獻
[1][SealPIR] SealPIR: A computational PIR library that achieves low communicationcosts and high performance, 2020. https://github.com/microsoft/SealPIR.[2][ACLS18] S. Angel, H. Chen, K. Laine and S. Setty,"PIR with Compressed Queries and Amortized Query Processing,"2018 IEEE Symposium on Security and Privacy (SP), 2018, pp. 962-979, doi: 10.1109/SP.2018.00062.
[3][CKGS95] B. Chor, O. Goldreich, E. Kushilevitz, and M. Sudan"Private information retrieval", in Proceedings of IEEE 36th Annual Foundations of Computer Science, pp. 41-50, Oct 1995.
[4][BGI16] Elette Boyle, Niv Gilboa, and Yuval Ishai.Function secret sharing: Improvements and extensions. In CCS, 2016.
[5][BFV12] Junfeng Fan and Frederik Vercauteren. 2012.Somewhat Practical Fully Homomorphic Encryption.IACR Cryptol. ePrint Arch. 2012 (2012), 144.
[6][Brakerski12] Zvika Brakerski.Fully Homomorphic Encryption without Modulus Switching from Clas-sical GapSVP. IACR Cryptology ePrint Archive, 2012:78, 2012.
[7][ALP+21] Asra Ali, Tancrède Lepoint, Sarvar Patel, Mariana Raykova, Phillipp Schoppmann, Karn Seth, and Kevin Yeo.
Communication-computation trade-o?s in PIR. In USENIX Security, 2021.
[8][MCR21] M. Mughees, Hao Chen, Ling RenOnionPIR: Response Efficient Single-Server PIR, CCS'21.
[9][CGN98] Benny Chor, Niv Gilboa, and Moni Naor.Private information retrieval by keywords.
IACR Cryptology ePrint Archive, 1998:3, 1998.
Labeled PSI from fully homomorphic encryption with malicious security.
In ACM Conference on Computer and Communications Security, pages 1223–1237. ACM, 2018.P.S.文中素材來自公開發表論文,如有不妥,將立即洗掉 關注微信公眾號:隱語的小劇場
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/537727.html
標籤:其他
上一篇:地平線機器人實習總結