??網路爬蟲的發展為使用者了解和收集網路資訊提供便利的同時,也帶來了許多大大小小的問題,甚至對網路安全造成了一定危害,所以,在真正開始了解網路爬蟲之前,我們也需要先了解一下網路爬蟲的特性、帶來的問題以及開發和使用網路爬蟲的程序中需要遵循的規范,
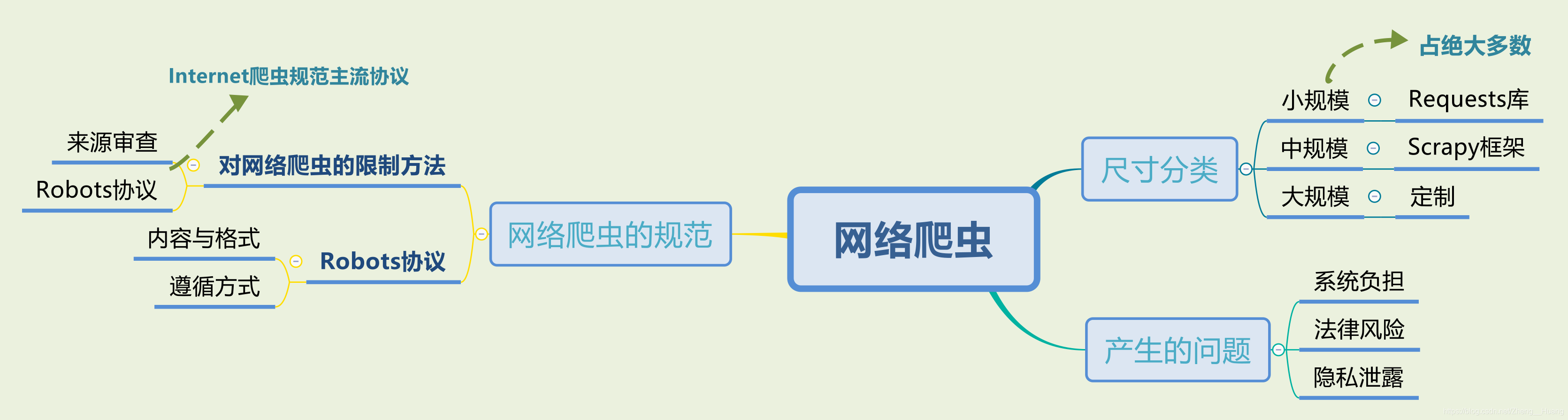
網路爬蟲的尺寸分類
| 尺寸 | 特性 | 目的 | 實作方式 |
|---|---|---|---|
| 小規模 | 資料量較小,對爬取速度不敏感,數量非常多 | 爬取網頁,探索網頁資訊 | Requests庫 |
| 中規模 | 資料量較大,對爬取速度較敏感 | 爬取網站和系列網站 | Scrapy框架 |
| 大規模 | 資料量和規模極大,多用于搜索引擎,爬取速度極為關鍵 | 爬取所有Internet上的網站 | 定制 |
網路爬蟲帶來的問題
?系統負擔
??由于技術限制和爬取目的,部分網路爬蟲產生的網路負載遠大于用戶訪問負載,這給網站造成了很大的帶寬負擔和Web服務器系統資源開銷,為網站的正常運行造成一定的負擔,所以對于網站的所有者來說,網路爬蟲(特別是不規范運行的爬蟲)給網站造成了一定的騷擾,
?法律風險
??由于網站上的資料一般具有產權歸屬,某些網路爬蟲獲取資料后如果進行分析販賣牟取利益將給網站帶來經濟損失,同時為開發和使用者帶來法律風險,所以網路爬蟲的設計者在設計爬蟲時要嚴格遵循互聯網和企業關于爬蟲的管理規定,否則可能承擔一定后果,
?隱私泄露
??網站上可能存在部分所有者原本不想讓用戶訪問到的隱私資料,部分網站可能使用較弱的訪問控制來保護資料,但部分網路爬蟲可能具有繞過或突破這類訪問控制的能力,如果網站沒有做好資訊保護導致資訊不慎泄露,就會引發嚴重的資訊安全問題,
網路爬蟲的規范
??由于網路爬蟲可能會帶來上述的問題,但同時網路爬蟲本身并不是一個危害性的工具,所以Internet和各個網站都在給出限制條件的基礎上允許網路爬蟲的運行,下面,我們就來了解一下網站和互聯網對爬蟲的限制方式
?網路爬蟲的限制方法
??來源審查
??部分網站使用較為簡單的來源審查來進行訪問限制,原理是通過分析網路請求中請求首部的User-Agent欄位來篩選請求,網站只回應來自瀏覽器和友好爬蟲的訪問請求,來源審查對網站開發人員的技術水平有一定要求
??發布公告(Robots協議)
??網站使用發布公告的方法告知所有爬蟲對這個網站的爬取策略,要求每一個爬取該網站的爬蟲遵守,目前Internet上主流的公告協議是Robots協議,這個協議規定了網站中可以爬取和不可爬取的內容,這種方法更加簡單,對網站開發人員的要求較低,但是,這種發布公告的方法部分情況下僅對爬蟲開發者有道德限制,如果沒有配合其他訪問控制方式,如果爬蟲有目的地訪問,其能非常容易地找到隱私內容,但是違反該協議的爬蟲的開發和使用者將面臨很高的法律風險,我們在設計爬蟲時也應該遵循這些公告的要求,
?Robots協議
Robots協議(Robots Exclusion Standard網路爬蟲排除標準)通過放置在網站根目錄下的robots.txt檔案來告知網路爬蟲哪些頁面允許爬取而哪些不能,如果一個網站沒有在根目錄下提供這個檔案,則默認允許網路上的所有爬蟲爬取網站內容
??Robots協議格式
Robots協議內容主要由下列關鍵字、通配符與具體名稱和路徑構成
| 關鍵字、通配符 | 說明 |
|---|---|
| User-agent: | 對特定名稱的爬蟲的規定(開始) |
| Allow: | 允許抓取的內容 |
| Disallow: | 禁止抓取的內容 |
| * | 通配符,指任意內容 |
| $ | 通配符,指以前面內容為結尾 |
- 注意:關鍵字的冒號均為英文,冒號后有一個空格
User-agent關鍵字與爬蟲請求中的User-agent首部欄位向對應- 針對不同爬蟲的規則之間有一空行分隔
Allow關鍵字具有與Disallow關鍵字相反的作用,可以排除某些被其拒絕的子目錄- 如果沒有需要禁止訪問的網頁,也應該寫一行規則,一般在
Disallow關鍵字的空格后直接換行(或在Allow關鍵字后使用/表示根目錄) - ?沒有特殊含義,僅表示?字面意思
下面節選百度的robots.txt內容進行介紹,
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Googlebot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
...
User-agent: *
Disallow: /
百度對Baiduspider百度搜索引擎主爬蟲限制了特定的目錄,而對Googlebot谷歌搜索引擎主爬蟲限制了更多內容,在所有允許串列后有一個User-agent: *,并禁止根目錄,表示百度網站禁止除了上述友好爬蟲外的所有爬蟲對網頁的抓取,
??Robots協議的遵循方式
??網路爬蟲應當能夠自動或人工識別robots.txt檔案內容,按照協議要求對網站進行爬取,雖然Robots協議對爬蟲的運行規定僅是建議性的,但并不意味著不遵循該協議對網站的任意爬取不會存在任何法律風險,尤其是包含商業價值的內容,如果使用爬蟲違規爬取獲益,將可能面臨被起訴風險,
??原則上來說,所有網路爬蟲都應該遵循Robots協議規范,如果網路爬蟲的訪問量較大或者以商業利益為目的,則必須遵守Robots協議,但如果僅僅以個人非盈利目的,且對網站訪問量較小,則可以適當減少協議的約束性,如果一個爬蟲對網站的訪問(頻率和爬取內容)與用戶的訪問模式相當,則該類行為被稱為類人行為,這類行為可不遵守Robots協議,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/54120.html
標籤:其他
上一篇:怎么獲得積分