資料結構在研究的其實就是邏輯結構,其中包括線性結構、樹結構、圖結構。
線性結構:結構中的資料元素之間存在著一對一的線性關系。
樹結構:結構中的資料元素之間存在著一對多的層次關系。
圖結構:結構中的資料元素之間存在著多對多的任意關系。
演算法是對特定問題求解步驟的一種概述,它是指令的有限序列,其中每一條指令表示一個或多個動作。
演算法的特性:有窮性、確定性、可行性、輸入、輸出。
演算法設計需要滿足的要求:正確性、可讀性、健壯性、效率與低儲存量需求。
以上是對資料結構和演算法一個簡單的介紹,下面就是圍繞資料結構與演算法學習的一些知識。
1線性表:
線性表中講到了順序表和單鏈表,還分別講了它們的插入和洗掉。
順序表的插入特點就是你要插入哪個位置,它就會從最后一個元素開始往后移,直到空出要插入的位置。洗掉的話就把洗掉的位置的元素移出,緊接著后面的每一個元素都會往前移一位。單鏈表插入的特點就是定位在插入位置的前一位然后插入。洗掉的話就簡單了,直接洗掉那個位置的元素。
2堆疊和佇列:
堆疊的特點就很明顯了,后進先出。
堆疊的基本運算有:初始化堆疊、判定堆疊S是否為空、求堆疊S 的長度、獲取堆疊頂元素的值、將元素e進堆疊還有出堆疊。
堆疊的存盤結構:順序堆疊、鏈堆疊
佇列又簡稱隊,其中插入又叫做入隊,洗掉叫做出隊。佇列的存盤結構也是順序佇列和鏈式佇列。
在插入佇列的時候如果佇列為滿就會查詢溢位。解決這個問題就是用回圈佇列。
回圈佇列為滿的條件是:front==( rear+1) % MaxSize
3字串:
串是由零個或多個字符組成的有限序列,記作s=”s0s1…sn-1”(n≥0),其中s是串名,字符個數n稱作串的長度,雙撇號括起來的字符序列”s0s1…sn-1”是串的值。每個字符可以是字母、數字或任何其它的符號。零個字符的串(即:””)稱為空串,空串不包含任何字符。值得注意的是:
(1)長度為1的空格串" "不等同于空串"";
(2)值為單個字符的字串不等同于單個字符,如"a"與′a′;
(3)串值不包含雙撇號,雙撇號是串的定界符。
4陣列與矩陣:
陣列其實就是有序的元素序列,陣列在Java語言中有很多功能:分配存盤空間、獲得陣列長度、存陣列元素、取陣列元素。陣列包括一維陣列、二維陣列、三維陣列、四維陣列等等。
如何理解陣列呢?一維陣列中每一個元素都是一維陣列,那二維陣列也就是兩個元素在一塊,三維陣列呢,就可以把二維陣列比作是一頁紙,那三維陣列就是一本書。以此類推,四維陣列就是放書的書架、五維陣列就是圖書館了。
矩陣在數學中是一個按照長方陣列排列的復數或實數的集合。矩陣在生活中一般應用到影像處理、資訊加密等等。還有一些特殊的矩陣,零矩陣、方陣、對角矩陣、單位矩陣、上/下三角形矩陣和行/列矩陣。
5樹:
樹大家看到都知道是很有層次的,樹根、樹枝、樹葉。這就好像一個公司中的總經理、部門經理、員工。樹形結構是一種應用十分廣泛的非線性結構,客觀世界中廣泛存在。那么在計算機中如何表示樹呢。定義是這樣的,樹是由n(n≥0)個結點組成的有限集合。如果n=0,那就叫做空樹。如果n>0,則滿足:
有一個特定的稱之為根(root)的結點,它只有直接后繼,但沒有直接前驅;
除根以為的其他結點劃分為m(m>0)個互不相交的有限集合T1,T2,T3……Tm,每個集合又是一棵樹,并稱為根的子樹。(每棵子樹的根結點有且僅有一個直接前驅,但它可以有0個或多個直接后繼)
下面還有樹的一些基本術語:節點、節點的度、樹的度、葉子、分支、孩子、雙親、兄弟、有序樹和無序樹、森林、樹的深度。這些基本術語可以讓我們學習樹的時候更方便快速的理解和記憶。
還有一種特殊的樹,符合二孩政策的樹—二叉樹;二叉樹是n(n≥0)個結點組成的有限集合BT,它或者是空集、或者由一個根節點和兩顆分別稱為左子樹和右子樹的互不相交的二叉樹組成。
二叉樹的遍歷也有幾種方法:先根遍歷(TLR)、中根遍歷(LTR)、后根遍歷(LRT);
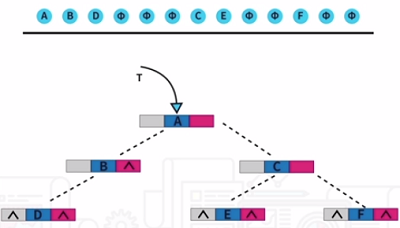
二叉樹的鏈式存盤結構,最常用的就是二叉鏈表和三叉鏈表。還有就是二叉樹的創建,如下圖所示:
還有一種稱為最優二叉樹的:哈夫曼樹
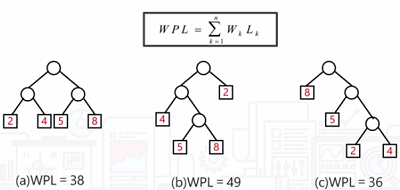
哈夫曼樹的基本概念有路徑長度和樹的路徑長度
結點的帶權路徑長度:從根結點到某個結點的路徑長度與該結點所帶的權值的乘積。
樹的帶權路徑長度就是所以葉子結點的帶權路徑長度之和。通常記作如下圖所示:
構造哈夫曼樹的方法如下圖所示:

6圖:
在實際應用中,有很多可以用圖結構來描述的問題,比如旅游路線可以用圖畫出來,而我們學習的這個圖就可以幫助我們用最少的資金和時間來規劃一個好的旅游方案。
? 圖是由頂點和邊組成的,定點表示圖中的資料元素,邊表示資料元素之間的關系記為G=(V,E),其中V是頂點的非空有窮集合,E是用頂點對表示的邊的有窮集合, 可以為空。
圖的基本術語:鄰接點、頂點的度、入度和出度、完全圖、稠密圖、稀疏圖、子圖、路徑、連通圖、連通分量、強連通圖、強連通分量、權、網。
圖的存盤結構:鄰接矩陣和鄰接表。
? 圖的遍歷:從中某一頂點出發遍歷圖中其余頂點,且使每一頂點僅被訪問一次。
演算法設計需要注意的幾個問題:1、演算法的引數要指定訪問的第一個頂點;2、要考慮遍歷路徑可能出現的死回圈問題;3、要使每一個頂點的所有鄰接頂點按照某種次序被訪問。
遍歷圖的基本方法:深度優先搜索和廣度優先搜索。
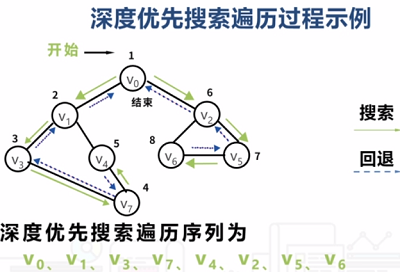
下面看看連通圖的深度優先搜索遍歷DFS和一個示例,如下圖所示:

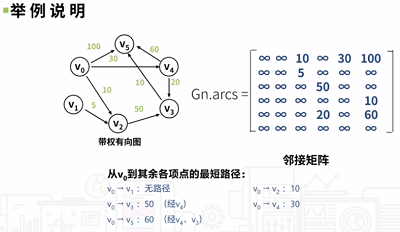
解決圖的最短路徑問題的方法:Dijkstra演算法和Floyd演算法。
Dijkstra演算法:按路徑長度的遞增次序,逐步產生最短路徑的演算法。首先求出長度最短的一條最短路徑,再參照它求出長度次短的一條最短路徑,依此類推,直到頂點V到其它各頂點的最短路徑求出為止。下面看一個示例,如下圖所示:
7查找:
查找分為靜態查找、動態查找和哈希查找,下面我們就一個一個看。
? 靜態查找又包括:順序查找、折半查找、分塊檢索。
順序查找:查找表的存盤結構是線性表;查找程序是依次用查找條件中給定的值與查找表中資料元素的關鍵字值比較。
下面我們看一下順序查找的完整演算法,如下圖所示:

折半查找:折半查找只適用于對有序順序表進行查找;每進行一次折半查找,要么查找成功,結束查找;要么將查找范圍縮小一半,繼續查找;如此重復,直到查找成功或查找范圍縮小為空即查找失敗為止。折半查找又稱二分查找。
分塊檢索:分塊檢索又稱索引順序查找,它是一種性能介于順序查找和二分查找之間的查找方法。查找表由 ‘分塊有序’ 的線性表和 ‘有序的‘ 索引表組成。
? 動態查找:表結構本身是在查找中動態生成,對于給定值K,如果表中存在則查找成功,否則在適當位置插入K。它的結構主要有二叉樹結構和樹結構兩種型別。
二叉排序樹又稱二叉查找樹,它或者是空樹,或者是滿足以下性質:1、若它左子樹非空,則左子樹上所有結點的均小于根結點的值;2、若它右子樹非空,則右子樹上所有結點的均小于根結點的值;3、它的左、右子樹本身又各是一棵二叉排序樹。
在二叉排序樹中查找的基本思想:用給定K值與根節點關鍵字值比較,如果K小于根節點的值,就繼續在左子樹中查找,否則將繼續在右子樹中查找,依此類推,一直查找下去,直到查找成功或者查找失敗為止。
下面看一個完整的二叉排序樹查找演算法,如下圖所示:

哈希查找,簡單的介紹,如下圖所示:


哈希查找中的方法,如下圖所示::


8排序:
排序也分為幾種:插入排序、交換排序和選擇排序。
? 插入排序:開始時有序表中只包含一個元素,無序表中包含n-1個元素;排序程序中每次從無序表中取出第一個元素,將它插入到有序表中的適當位置,使之成為新的有序表;每一趟都是將一個記錄插入到前面的有序段中,直到所有記錄都插入到有序段中,需要進行n-1趟。
注意:直接插入演算法的元素移動是順序的,該方法是穩定的。
直接插入排序適用于對排序元素較少、且基本有序的資料元素排序。
直接插入排序演算法描述如下圖所示:

? 交換排序:又叫做快速排序,基本思想就是從待排序序列的n個記錄中任取一個記錄R,作為基準記錄,以基準記錄為界限,將待排序序列劃分成兩個子序列,所以關鍵字小于Ki的記錄移動到Ri前面,反之,移動到后面,這個程序稱做一趟快速排序,然后用同樣的方法對兩個子序列排序,得到四個子序列;依次類推,直到每個子序列只有一個
記錄為止,此時就得到n個記錄的有序序列。
快速排序演算法描述和快速排序的遞回演算法如下圖所示:


? 選擇排序:基本思想就是每一趟從待排序記錄中選出關鍵字最小的記錄,按順序放到已排好序的子序列中,直到全部記錄排序完畢。選擇排序有兩種:直接選擇排序和堆排序。
直接選擇排序演算法描述如下圖所示:

在直接選擇排序程序中,所需移動記錄的次數較少。在最好情況下,即待排序序列正序時,該演算法記錄移動次數為0,反之待排序序列逆序時,該演算法記錄移動次數為(n-1)。
在直接選擇排序程序中需要的關鍵字的比較次數與序列原始順序無關,大概i=1時(外回圈執行第一次),內回圈比較n-1次,i=2時,內回圈比較n-2次;依次類推,演算法的總比較次數為(1+2+3+…+n-1) = n(n-1)/2。因此直接選擇排序的時間復雜度為O(n2),由于只用一個變數作輔助空間,所以空間復雜度為O(1),直接選擇排序是不穩定的。
以上就是資料結構與演算法的小總結,大家可以參考或學習。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/54149.html
標籤:數據結構與算法