該文獻的作者是清華大學的高飛飛老師,于2019年11月發表在IEEE COMMUNICATIONS LETTERS上,
文章給出了當用戶位置到信道的映射是雙射時上行到下行的確定映射函式;還提出了一個稀疏復值神經網路( sparse complex-valued neural network,SCNet)來逼近映射函式,SCNet直接根據預估的上行鏈路CSI預測下行鏈路CSI,不需要下行鏈路訓練,也不需要上行鏈路反饋,
1 研究背景
在大規模MIMO中,BS使用CSI用于波束形成、用戶調度等,UE使用CSI用于信號檢測,但由于下行鏈路訓練和上行鏈路反饋相關的開銷過高,因此需要進行優化作業,
由于BS和用戶的信道只有很小的角度擴展,并且信道尺寸非常大,所以MIMO信道在角域上表現出稀疏性,因為在大規模MIMO中方便獲取上行CSI,所有許多研究從上行CSI反饋中獲取下行CSI的資訊,從而減少下行訓練開銷和上行反饋開銷,如基于CS的方法和基于DL的方法,
與以上兩種方法不同,這篇文獻提出了一種稀疏復值神經網路(SCNet)用于FDD大規模MIMO的下行CSI預測,主要的貢獻有:
- 得出了當位置到信道映射為雙射時,給定通信環境下的確定上行到下行的映射函式,還證明了該映射函式可以用前饋網路以任意小的誤差來逼近;
- 提出了預測MIMO下行鏈路CSI的SCNet,適用于具有復值表示的復值函式逼近,
2 系統模型
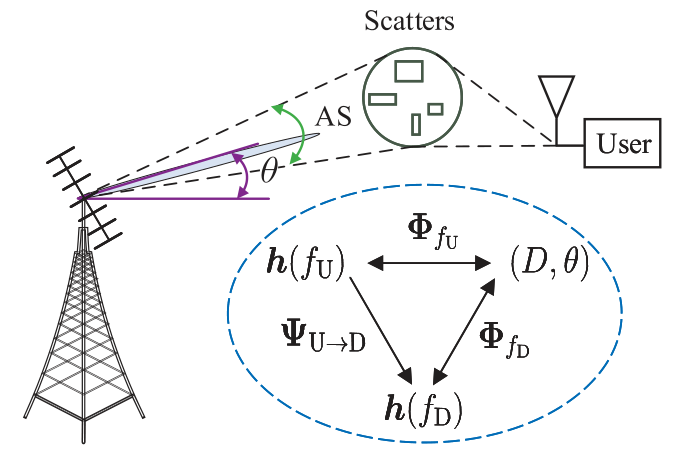
如圖1所示,考慮FDD大規模MIMO系統,BS有M根均勻線性陣列(ULA)天線,UE處為單天線,由于提出的方法可以適用于不同的UE,因此只需要對單個UE進行說明,設UE和BS之間的信道\(h\)由P個射線組成,表示為:
\[\boldsymbol{h}(f)=\sum_{p=1}^{P} \alpha_{p} e^{-j 2 \pi f \tau_{p}+j \phi_{p}} \boldsymbol{a}\left(\theta_{p}\right), \]其中\(f,\alpha_{p}, \phi_{p}, \tau_{p}\) 和 \(\theta_{p}\)分別為第P條路徑的頻率、衰減、相移、延遲和到達方向(DOA),\(\boldsymbol{a}\left(\theta_{p}\right)\)為陣列流形向量:
\[\boldsymbol{a}\left(\theta_{p}\right)=\left[1, e^{-j \chi \sin \theta_{p}}, \cdots, e^{-j \chi(M-1) \sin \theta_{p}}\right]^{T} \]其中\(\chi=2 \pi d f / c\), \(d\)為天線間距,\(c\)為光速,平均DOA \(\theta_{p} \in[\theta-\Delta \theta / 2, \theta+\Delta \theta / 2]\),
路徑衰減\(\alpha_{p}\)取決于:
- UE與BS之間的距離;
- 發射和接收天線的增益;
- 載波頻率;
- 散射環境,
相位\(\phi_{p}\)取決于散射體材料和波在散射體處的入射角,延遲 \(\tau_{p}\) 取決于信號沿P路徑傳播的距離,
3 信道映射函式
用\(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\)和\(\boldsymbol{h}\left(f_{\mathrm{D}}\right)\) 表示上行和下行信道,\(f_{\mathrm{U}}\)和\(f_{\mathrm{D}}\)表示上行和下行頻率,由于下行鏈路和上行鏈路有相同的傳播環境和共同的物理路徑,并且無線信道的空間傳播特性在一定帶寬內幾乎不變,因此上行鏈路和下行鏈路CSI之間存在著內在的聯系,文獻首先定義了一個上行到下行的映射函式,并證明了它的存在性,然后利用深度學習來找到這個映射函式,
3.1 上下行信道映射的存在性
如公式(1)所示,信道函式由引數\(\alpha_{p}\), \(\phi_{p}, \tau_{p}, P, \Delta \theta\) 和 \(\theta\)決定,
定義1:位置到信道的映射\(\Phi_{f}\)可以寫成:
\[\boldsymbol{\Phi}_{f}:\{(D, \theta)\} \rightarrow\{\boldsymbol{h}(f)\}, \]其中集合\(\{(D, \theta)\}\) 和 \(\{\boldsymbol{h}(f)\}\)分別是映射\(\Phi_{f}\)的域和上域,
假設1:位置到通道的映射函式(3)\(\boldsymbol{\Phi}_{f}:\{(D, \theta)\} \rightarrow\{\boldsymbol{h}(f)\}\)是雙射的,
假設1意味著每個用戶位置都有一個唯一的通道函式\(\boldsymbol{h}(f)\),每個信道函式也對應唯一的用戶位置,在實際無線通信場景中,$$\Phi_{f}$$為雙射的概率在實際中是非常高的,并且隨著BS處天線數量的增加,該概率趨于1,因此在大規模MIMO系統中采用假設1是合理的,信道到位置的映射,即\(\Phi_{f}\)的逆映射表示為:
\[\boldsymbol{\Phi}_{f}^{-1}:\{\boldsymbol{h}(f)\} \rightarrow\{(D, \theta)\}, \]命題1:根據假設1,對于給定的通信環境,存在上行到下行的映射可以寫成:
\[\boldsymbol{\Psi}_{\mathrm{U} \rightarrow \mathrm{D}}=\boldsymbol{\Phi}_{f_{\mathrm{D}}} \circ \boldsymbol{\Phi}_{f_{\mathrm{U}}}^{-1}:\left\{\boldsymbol{h}\left(f_{\mathrm{U}}\right)\right\} \rightarrow\left\{\boldsymbol{h}\left(f_{\mathrm{D}}\right)\right\}, \]其中\(\boldsymbol{\Phi}_{f_{\mathrm{D}}} \circ \boldsymbol{\Phi}_{f_{U}}^{-1}\) 表示\(\boldsymbol{\Phi}_{f_{\mathrm{D}}}\) 和\(\boldsymbol{\Phi}_{f_{\mathrm{U}}}^{-1}\)相關的復合映射,
證明:根據定義1,得到在候選集\(\{(D, \theta)\}\)中存在\(\boldsymbol{\Phi}_{f_{\mathrm{D}}}:\{(D, \theta)\} \rightarrow\left\{\boldsymbol{h}\left(f_{\mathrm{D}}\right)\right\}\)和\(\boldsymbol{\Phi}_{f_{\mathrm{U}}}:\{(D, \theta)\} \rightarrow\left\{\boldsymbol{h}\left(f_{\mathrm{U}}\right)\right\}\)的映射,在假設1下,映射\(\boldsymbol{\Phi}_{f_{U}}^{-1}\)存在,其上域等于\(\boldsymbol{\Phi}_{f_{\mathrm{D}}}\)的域,因此,復合映射 \(\boldsymbol{\Phi}_{f_{\mathrm{D}}} \circ \boldsymbol{\Phi}_{f_{\mathrm{U}}}^{-1}\)存在于\(\{(D, \theta)\}\),
3.2 用于上下行信道映射的深度學習
命題1證明上下行信道映射的存在性,根據萬能近似定理,得到定理1:
定理1:對于給定任意小的誤差 \(\varepsilon>0\),總存在一個足夠大的正常數\(N\)使:
\[\sup _{\boldsymbol{x} \in \mathbb{H}}\left\|\operatorname{NET}_{N}(\boldsymbol{x}, \boldsymbol{\Omega})-\boldsymbol{\Psi}_{\mathrm{U} \rightarrow \mathrm{D}}(\boldsymbol{x})\right\| \leq \varepsilon, \quad \mathbb{H}=\left\{\boldsymbol{h}\left(f_{\mathrm{U}}\right)\right\} \]其中\(\operatorname{NET}_{N}(\boldsymbol{x}, \boldsymbol{\Omega})\)是三層前饋網路的輸出,\(\boldsymbol{x}, \Omega\) 和 \(N\) 分別表示輸入資料、網路引數和隱藏單元數,
根據定理1,具有單個隱藏層的前饋網路可以以任意小的誤差逼近上行到下行的映射函式,因此,我們可以訓練深度學習網路從上行CSI預測出下行CSI,并且可以使用離線訓練,顯著降低下行訓練和上行反饋所需的開銷,
4 基于SCNet的下行CSI預測
4.1 SCNet的網路結構
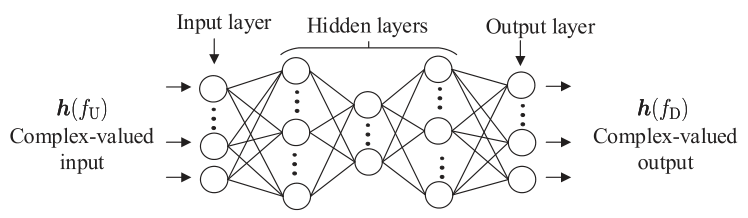
如圖2所示,SCNet的輸入為上行CSI矩陣\(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\),輸出是\(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\)的非線性變換級聯,即:
\[\hat{\boldsymbol{h}}\left(f_{\mathrm{D}}\right)=\operatorname{NET}\left(\boldsymbol{h}\left(f_{\mathrm{U}}\right), \boldsymbol{\Omega}\right)=\boldsymbol{f}^{(L-1)}\left(\cdots \boldsymbol{f}^{(1)}\left(\boldsymbol{h}\left(\left(f_{\mathrm{U}}\right)\right)\right),\right) \]其中\(L\)為網路層數,\(\boldsymbol{\Omega} \triangleq\left\{\boldsymbol{W}^{(l)}, \boldsymbol{b}^{(l)}\right\}_{l=1}^{L-1}\) 為待訓練的網路引數,\(f^{(l)}\)是是第\(l\)層的非線性變換函式,寫作:
\[\boldsymbol{f}^{(l)}(\boldsymbol{x})= \begin{cases}\boldsymbol{g}\left(\boldsymbol{W}^{(l)} \boldsymbol{x}+\boldsymbol{b}^{(l)}\right), & 1 \leq l<L-1 ; \\ \boldsymbol{W}^{(l)} \boldsymbol{x}+\boldsymbol{b}^{(l)}, & l=L-1,\end{cases} \]\(g\)為激活函式:
\[\boldsymbol{g}(\boldsymbol{z})=\max \{\Re[\boldsymbol{z}], \mathbf{0}\}+j \max \{\Im[\boldsymbol{z}], \mathbf{0}\} \]\(\Re[\cdot]\) 和 \(\Im[\cdot]\)為信道向量的實部與虛部,
在SCNet中,中間隱藏層的神經元數量比輸出層中的神經元數量少得多,作為SCNet的壓縮輸入功能,由于上行信道\(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\)存在稀疏結構,SCNet能夠發現大規模MIMO系統中\(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\)的固有稀疏性,因此SCNet不僅可以減少網路引數的冗余,而且性能和魯棒性更強,
4.2 SCNet的訓練和部署
文章提出的下行CSI預測分為離線訓練和在線部署兩個階段,
在離線訓練階段,BS同時采集下行和上行CSI作為訓練樣本,對SCNet進行訓練,具體來說,在一個相干時間內,下行CSI首先在UE端通過下行訓練進行估計,然后反饋給BS,上行CSI則通過上行訓練在BS處估計,對SCNet網路進行訓練,使輸出\(\hat{\boldsymbol{h}}\left(f_{\mathrm{D}}\right)\)與標簽\(\boldsymbol{h}\left(f_{\mathrm{D}}\right)\)之間的差異最小化,損失函式為:
\[\operatorname{Loss}(\boldsymbol{\Omega})=\frac{1}{V N_{h}} \sum_{v=0}^{V-1}\left\|\hat{\boldsymbol{h}}\left(f_{\mathrm{D}}\right)^{(v)}-\boldsymbol{h}\left(f_{\mathrm{D}}\right)^{(v)}\right\|_{2}^{2}, \]其中\(V\)為批大小,上標(\(v\))為第\(v\)個訓練樣本,\(\|\cdot\|_{2}\)為\(\ell_{2}\)范數,\(N_h\)為向量\(\boldsymbol{h}\left(f_{\mathrm{D}}\right)\)的長度,利用復雜設計自適應矩估計(ADAM)演算法最小化損失函式直到SCNet收斂,
在部署階段,SCNet的引數是固定的,SCNet直接根據上行CSI \(\boldsymbol{h}\left(f_{\mathrm{U}}\right)\) 生成下行鏈路CSI \(\hat{\boldsymbol{h}}\left(f_{\mathrm{D}}\right)\) 的預測值,
5 實驗結果
BS配置由128根天線,上行頻率遵循3GPP R15標準\(f_{\mathrm{U}}=2.5 \mathrm{GHz}\),在5.1中,每條路徑的衰減服從瑞利分布,相位和延遲在\([-\pi, \pi)\) 和\(\left[0,10^{-4}\right] s\)內均勻分布,在訓練和部署階段路徑的數量都是200條;在5.2中,每條路徑的引數是根據射線追蹤模擬器生成的,訓練階段路徑數為200條,部署階段路徑數不同,
把SCNet與FNN對比,FNN最初是為大規模MIMO系統的上行/下行信道校準而設計的,也可用于FDD大規模MIMO系統的下行信道預測,選擇隱藏層的神經元個數為\((128,64,128)\),ADAM演算法的初始學習率為0.001,批大小為128,網路分別對每個AS度和每個下行頻率進行訓練,訓練樣本數為102400個,epoch數為400個,
5.1 預測精度分析
用歸一化均方誤差(NMSE)來衡量預測精度:
\[\mathrm{NMSE}=E\left[\left\|\boldsymbol{h}_{\mathrm{D}}-\hat{\boldsymbol{h}}_{\mathrm{D}}\right\|_{2}^{2} /\left\|\boldsymbol{h}_{\mathrm{D}}\right\|_{2}^{2}\right] \]圖3為不同的AS下,上下行頻率差分別為120 MHz和480 MHz時SCNet和FNN的性能比較,可以看到隨著AS的增加,SCNet和FNN的NMSE性能下降,NMSE曲線的斜率隨AS的增加而減小,這是因為隨著AS的增加,信道在角域中的稀疏度降低,網路學習信道結構和準確預測信道CSI的難度增大,而且在AS較大情況下,網路對AS的敏感性較低,這是寬AS情況下斜率減小的原因,
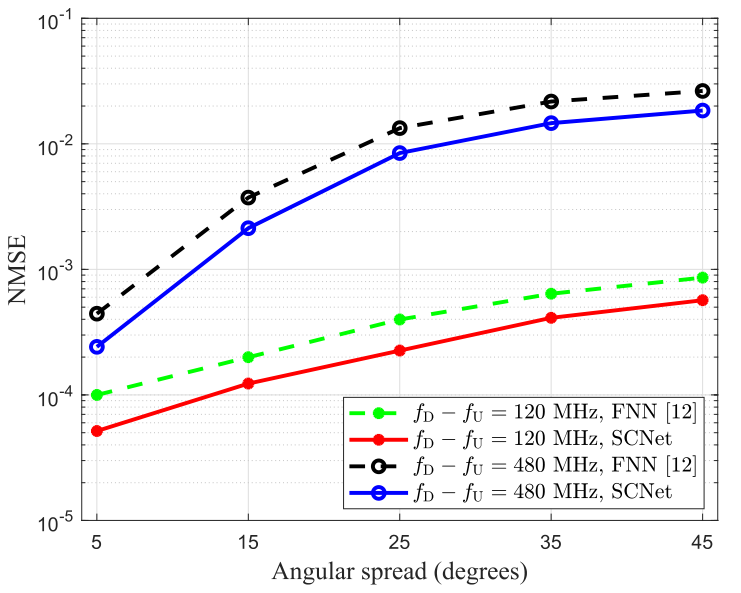
圖4為不同頻率差\(f_{\mathrm{D}}-f_{\mathrm{U}}\)下,AS分別為\(5°\)和\(45°\)時SCNet和FNN的性能比較,可以看出,隨著頻率差的增加SCNet和FNN的性能都有所下降,這是因為上行鏈路和下行鏈路之間的CSI相關性隨著頻率差的增加而趨于消失,
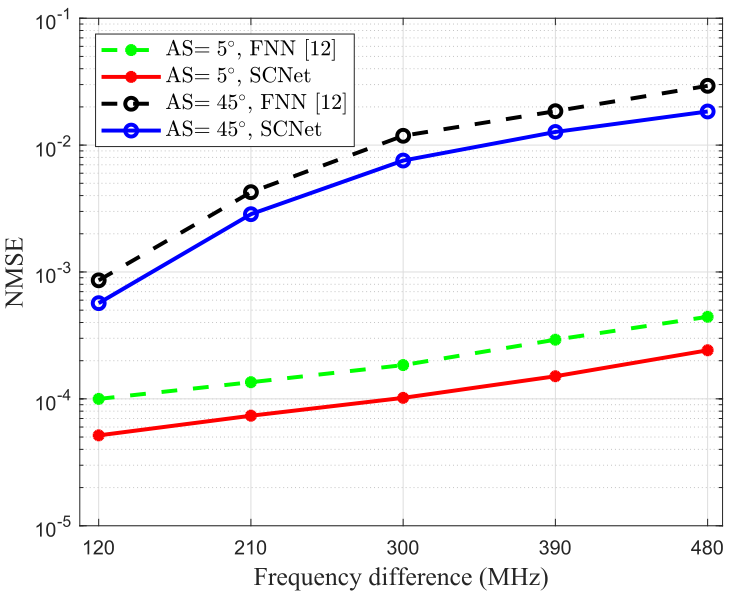
由圖3、圖4可以看出SCNet在所有場景下都優于FNN,驗證了SCNet可以從復雜表示提供的豐富表示能力中受益,
5.2 魯棒性分析
在5.1中,通道是基于公式(1)生成的,具有相同的統計量,然而現實中的信道環境可能更加復雜,訓練階段和部署階段的統計不匹配也是不可避免的,為了測驗SCNet和FNN的魯棒性,使用不同場景下Wireless InSite[2]生成的資料進行訓練和測驗,
如圖4所示,訓練階段的路徑數為200條,部署階段的路徑數有140~260條,結果表明,信道統計量的變化會導致性能下降,但SCNet較FNN仍然具有預測精度的性能優勢,驗證了深度神經網路良好的泛化能力,
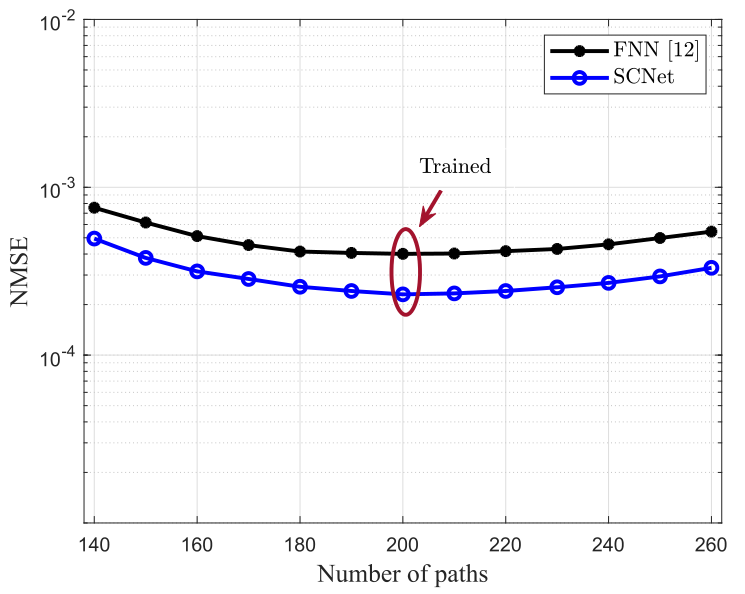
6 結論
文獻得出了在給定的通信環境中存在一個確定的上行到下行鏈路映射函式;然后提出了用于下行CSI預測的SCNet,
仿真結果表明,SCNet在預測精度方面優于FNN,它對無線信道預測也有較強的魯棒性,
重要文獻
[1] C. Huang, G. C. Alexandropoulos, A. Zappone, C. Yuen, and M. Debbah, “Deep learning for UL/DL channel calibration in generic massive MIMO systems,” in Proc. IEEE Int. Conf. Commun. (ICC),Shanghai, China, Mar. 2019, pp. 1–6.
[2] Remcom Wireless Insite. Accessed: Apr. 2019. [Online]. Available:https://www.remcom.com/wireless-insite-em-propagation-software
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/550694.html
標籤:其他
上一篇:時而實踐、時而學習
下一篇:返回列表