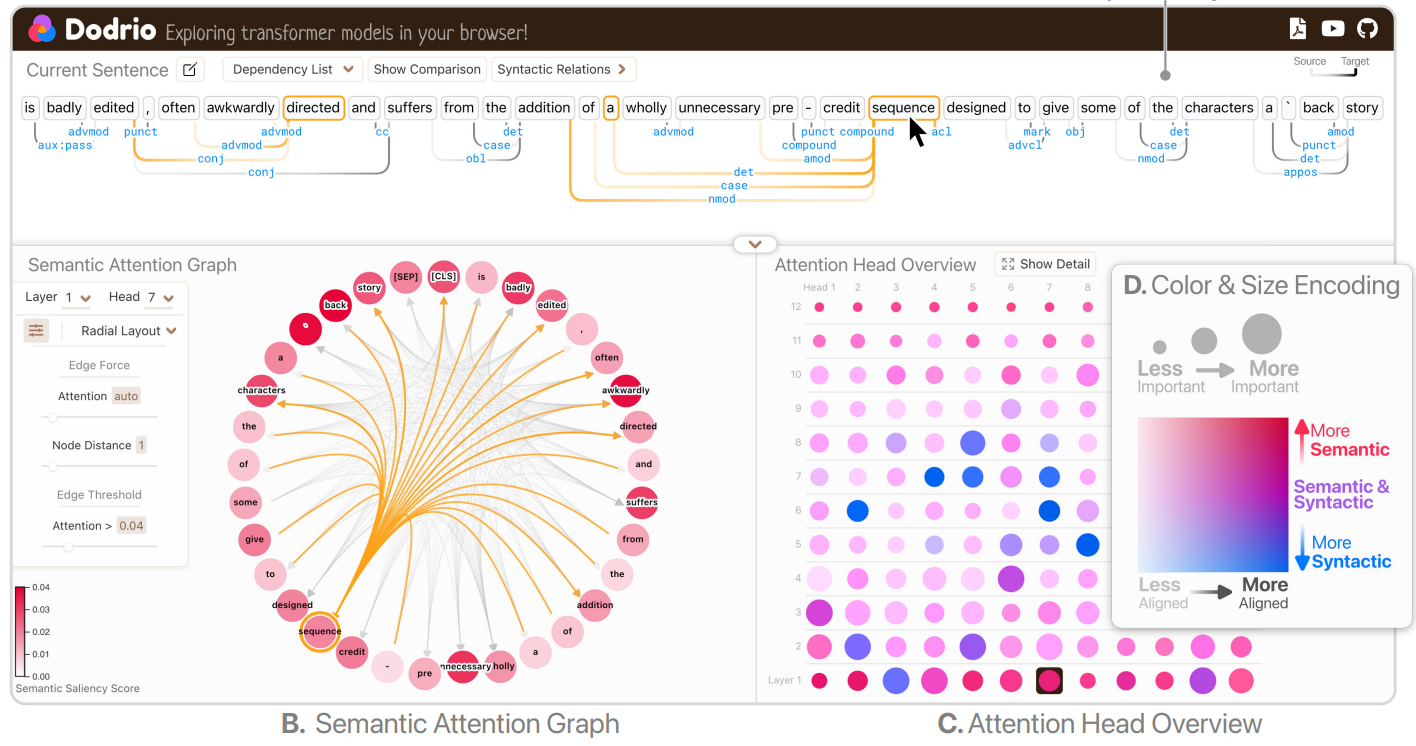
朋友們,朋友們,事情是這樣的,最近心血來潮,突然想起很久以前看過的一個NLP可視化包,它的效果是下面這個樣子:
 在此之前,已經有一些文章從論文的角度對這個包進行了介紹,詳情請見
在此之前,已經有一些文章從論文的角度對這個包進行了介紹,詳情請見
推薦一個可互動的 Attention 可視化工具!我的Transformer可解釋性有救啦?
當時我第一眼就被這個包的效果折服了,想著這么有意思的東西,我高低得去試一試,于是我懷著好奇的心點進了這個專案的github主頁,作者給出的使用介紹很簡單:
-
首先,復制專案
git clone [email protected]:poloclub/dodrio.git -
然后,進入專案目錄,安裝依賴
npm install -
最后,直接運行即可
npm run dev
該專案會默認在localhost:5000創建一個本地服務,一旦運行完成且資料無誤,就可以在本地看到上面炫酷的界面,
但事情遠遠沒有那么簡單,作者提供的模型只能解釋其預先選擇好的模型與資料集,要想真正用到自己的專案上,還需要對專案進行一定程度的客制化,于是大約在一年前,我嘗試按照作者寫在Readme中的方法,嘗試將自己的模型與自己的資料集使用這個包進行可視化,殊不知,這對于我來說是噩夢的開始,在實驗程序中,我遇到的困難包括且不僅限于以下幾點:
-
該專案需要安裝許多的依賴包,許多包存在著過期、更新等問題,同時,在本地部署時還會由于網路問題導致許多依賴無法正常安裝,最重要的是,由于該包使用的Transformers版本是3.3.1,Python版本高于3.7將無法正常地安裝與使用,
-
在遠程服務器(例如Google Colab)等部署時,就不用擔心出現網路問題導致的安裝依賴失敗,但由于服務是部署在本地,所以還需要使用nagrok、localtunnel等工具進行映射,
-
在data-generation.py中,除了修改模型與資料集外,一些函式的用法與位置也發生了改變,因此需要自己慢慢摸索與除錯,
-
... ... ... ...
總之,之前嘗試了很久之后還是沒有結果,遂放棄,但是最近機緣巧合之中又接觸到了這個包,恰逢《灌籃高手》上映,滿腔熱血無處釋放,遂決定與這個磨人的包一教高下,
直言結論,仍然可以使用,并且可以針對本地模型與本地資料集進行客制化,以下列舉除錯程序中的一些重點:
-
首先確保環境中的
Transformers==3.3.1,其次,請pip install umap-learn而不是pip install umap,并在dodrio-data-gen.py的開頭使用import umap.umap_ as umap代替import umap -
代碼中存在大量的從checkpoint中匯入模型,請根據實際需求注釋掉或修改路徑,
-
在運行
dodrio-data-gen.py前,要先在其同級目錄下創建outputs檔案夾,同時,在outputs檔案夾下創建你的模型名-attention-data檔案夾(用來儲存attention權重) -
在運行
dodrio-data-gen.py時,可能會遇到各種各樣的報錯,對此,耐心尋找原因,都不難改, -
成功運行完
dodrio-data-gen.py后,會在目錄下生成如下所示的這些檔案:

-
最重要的是!!!!!!!專案從json檔案中抽取資料時,在多個svelte檔案中默認選擇第1562個元素,但大多數情況下你的資料集中不一定有第1562項,因此你需要去多個檔案中手動修改(當然也可以通過寫config檔案修改,但我是java小白,所以煩請大佬指導)
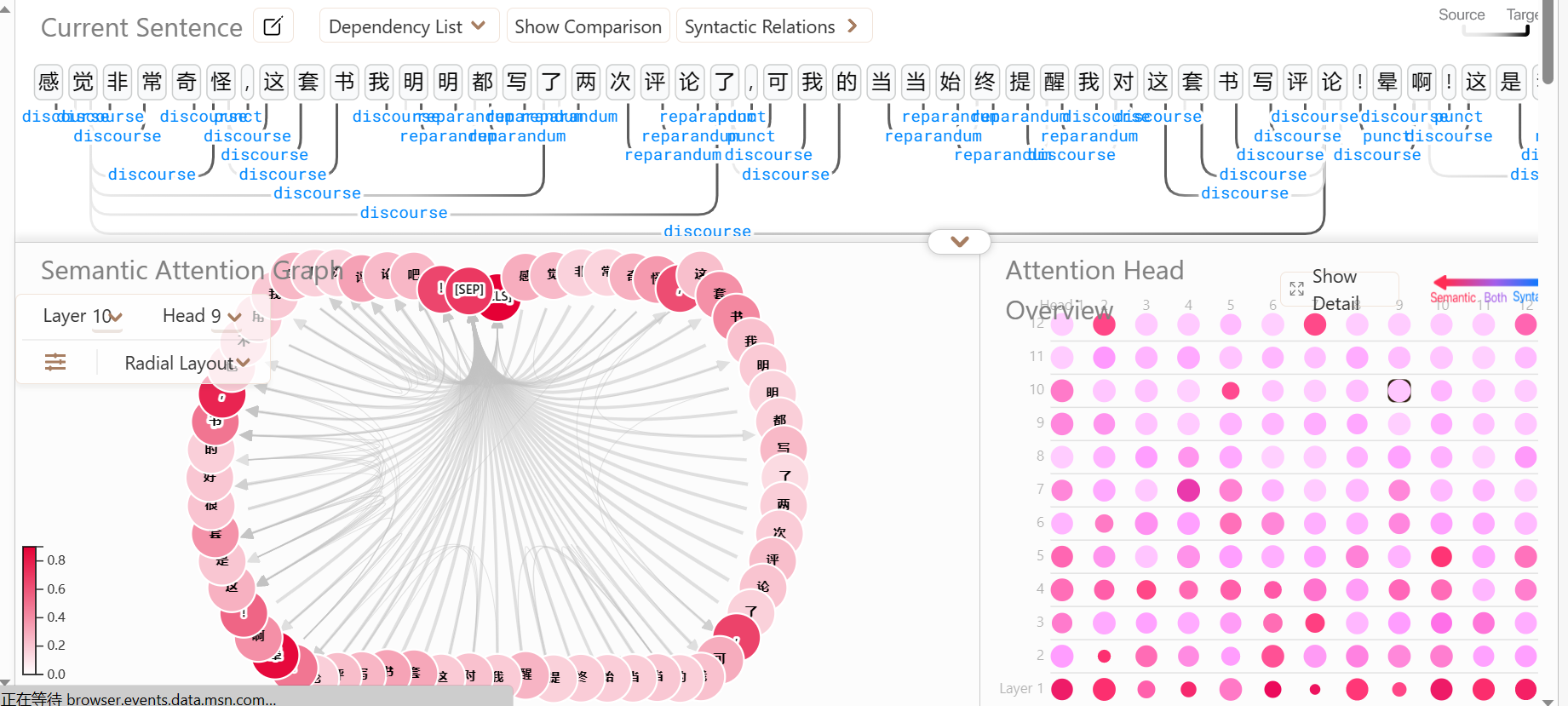
處理完以上這些步驟,就可以生成基于你自己模型與資料集的炫酷可視化影像了,效果如下:
## 好了,說了那么多,如果還是看不懂怎么辦,這里附上我自己的傻瓜式教程:
Step 1. 下載專案(或者直接使用遠程服務器也可以)
git clone [email protected]:poloclub/dodrio.git
Step 2. 安裝依賴
npm install
Step 3. 檢查你的環境
首先,要保證Python版本最好不大于3.7,以便安裝Transformers==3.3.1,然后,安裝一些必要的Python包,缺啥補啥,這個沒什么好說的,注意要安裝umap-learn而不是umap
Step 4. 進入dodrio檔案夾修改data-generation/dodorio-data-gen.py檔案:
首先,line65、line66、line71,line73分別修改你的標簽數量、標簽名、資料集名、要加載的Tokenizer;其次,line876左右,修改你的資料集地址,最好按照原資料集格式對你的資料集進行處理,我是這樣做的:
點擊查看代碼
dataset_test = load_dataset('seamew/ChnSentiCorp', split='train[:20%]')
dataset_test = dataset_test.rename_columns({"text": "sentence"})
idx = range(len(dataset_test))
dataset_test = dataset_test.add_column("idx", idx)
其次,在dodorio-data-gen.py中,有許多:
點擊查看代碼
checkpoint = torch.load('./outputs/saved-bert-' + dataset_name + '.pt')
my_model.load_state_dict(checkpoint['model'])
如果你本地有checkpoint,那么就改成你自己的地址,如果沒有,就直接注釋掉,代碼中有較多處,建議直接搜索并修改,
Step 5. 在運行dodrio-data-gen.py前,要先在其同級目錄下創建outputs檔案夾,同時,在outputs檔案夾下創建你的模型名-attention-data檔案夾(用來儲存attention權重),到這里為止,你應該已經成功運行完了dodrio-data-gen.py檔案,那么你會發現其同級目錄下多出了這些檔案:
然后,將生成的所有檔案以及所有檔案夾移到dodrio/public/data下,
Step 6. 然后,最重要的一步,打開dodrio/Main.svelte,修改檔案中的檔案路徑(與你上一步中生成的檔案名稱對應):

Step 7. 恭喜你到了這一步,接下來,要修改這個粗心作者犯下的錯誤,在專案中,作者將示例檔案的ID固定成了1562,但往往我們使用的樣本并沒有1562這個樣本,于是請你點擊進入longest-300-id.json檔案中,查看你的資料集包含哪些樣本,及其ID為多少,選擇一個你想測驗的句子,記住它的ID,這里我假設想要測驗的句子ID為1,、
去github中搜索所有存在Instence以及1562的欄位,然后將所有的1562替換成1即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551100.html
標籤:其他
下一篇:返回列表