前言
這篇筆記記錄了線性回歸的梯度下降相關公式的推導,
符號說明:
- \(h\) :假設函式,是學習演算法對線性回歸問題給出的一個解決方案,
- \(J\) :代價函式,是對 \(h\) 和實際資料集之間的誤差的描述,
- \(m\) :資料集的大小,
- \(x^{(i)},y^{(i)}\): 第 \(i\) 個資料,(\(1\le i \le m\))
- \(\theta\) :\(h\)函式中各項的系數,
單變數線性回歸
\(h(x)=\theta_0 + \theta_1x\)
\(J(\theta_0,\theta_1)=\frac{1}{2m} \Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2\)
在這個演算法中需要找到最優的\(\theta_0\)和\(\theta_1\)使得代價函式\(J\)可以取得最小值,
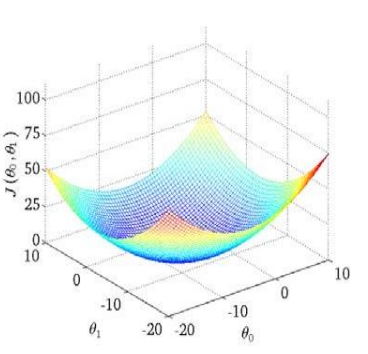
使用梯度下降可以計算得出區域最小值,由于線性回歸中的代價函式\(J\)是凸函式,因此區域最小值即全域最小值,
批量梯度下降演算法的公式如下:
repeat until convergence{
? \(\theta_j:=\theta_j-\alpha \frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)\) \(for\quad (j=0 \quad and \quad j=1)\)
}
其中 \(\alpha\) 是學習率,表示梯度下降的步長,
\(\frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)\) 是梯度,
通過不斷更新\(\theta\),向最低點逼近,最終使得\(J\)最小的\(\theta\)值,即對應一個最優的解決方案\(h\).
\[\theta_0:=\theta_0-\alpha\frac{\partial}{\partial \theta_0}J(\theta_0,\theta_1) \]其中
\[\begin{align*} \frac{\partial}{\partial \theta_0}J(\theta_0,\theta_1) &=\frac{\partial}{\partial\theta_0}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\ &=\frac{\partial}{\partial\theta_0}(\frac{1}{2m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\ &=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_0}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\ &= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta_0+\theta_1x^{(i)}-y^{(i)})\times1)\\ &= \frac{1}{m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})\\ &=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)}) \end{align*} \]\(\therefore\)
\[\theta_0:=\theta_0-\alpha\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)}) \]類似地,
\[\theta_1:=\theta_1-\alpha\frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1) \]其中
\[\begin{align*} \frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1) &=\frac{\partial}{\partial\theta_1}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\ &=\frac{\partial}{\partial\theta_1}(\frac{1}{2m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\ &=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\ &= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta_0+\theta_1x^{(i)}-y^{(i)})\times x^{(i)})\\ &= \frac{1}{m}\Sigma^m_{i=1}((\theta_0+\theta_1x^{(i)}-y^{(i)})\cdot x^{(i)})\\ &=\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)}) \end{align*} \]\(\therefore\)
\[\theta_1:=\theta_1-\alpha\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)}) \]多元線性回歸
基本概念
多元線性回歸中的假設函式 \(h\) 包含多個特征:
\[h_\theta(x) = \theta_0 + \theta_1x_1+...+\theta_nx_n \]如果假設 \(x_0=1\),那么上式可以改寫為:
\[h_\theta(x) =\theta_0x_0 + \theta_1x_1+...+\theta_nx_n \]此時,若將 \(\theta\) 和 \(x\) 視為向量(默認為列向量),則:
\[h_\theta(x) = \theta^Tx \]代價函式為:
\[J(\theta) = \frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2 \]梯度下降
對于梯度下降演算法的每一次迭代, \(\theta\) 按一下規則更新:
Repeat {
? \(\theta_j := \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta_0,...,\theta_n)\)
} \(for\ \ every\ \ j=0,...,n\)
上述公式中的偏導數計算:
\[\begin{align*} \frac{\partial}{\partial \theta_j}J(\theta) &=\frac{\partial}{\partial\theta_j}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\ &=\frac{\partial}{\partial\theta_j}(\frac{1}{2m}\Sigma^m_{i=1}(\theta^Tx^{(i)}-y^{(i)})^2)\\ &=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_j}(\theta^Tx^{(i)}-y^{(i)})^2)\\ &= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta^Tx^{(i)}-y^{(i)})\times x_j^{(i)})\\ &= \frac{1}{m}\Sigma^m_{i=1}((\theta^Tx^{(i)}-y^{(i)})\cdot x_j^{(i)})\\ &=\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x_j^{(i)}) \end{align*} \]上述推導程序中的 \(x\) 是向量, \(x_j\)是向量中的第 \(j\) 個元素,
\(\therefore\)
\[\theta_j:=\theta_j - \alpha\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x_j^{(i)}) \]特征縮放
當不同特征的取值范圍相差過大時, \(\theta\) 的取值可能不斷波動,需要花費較長時間才能收斂到全域最小值點,
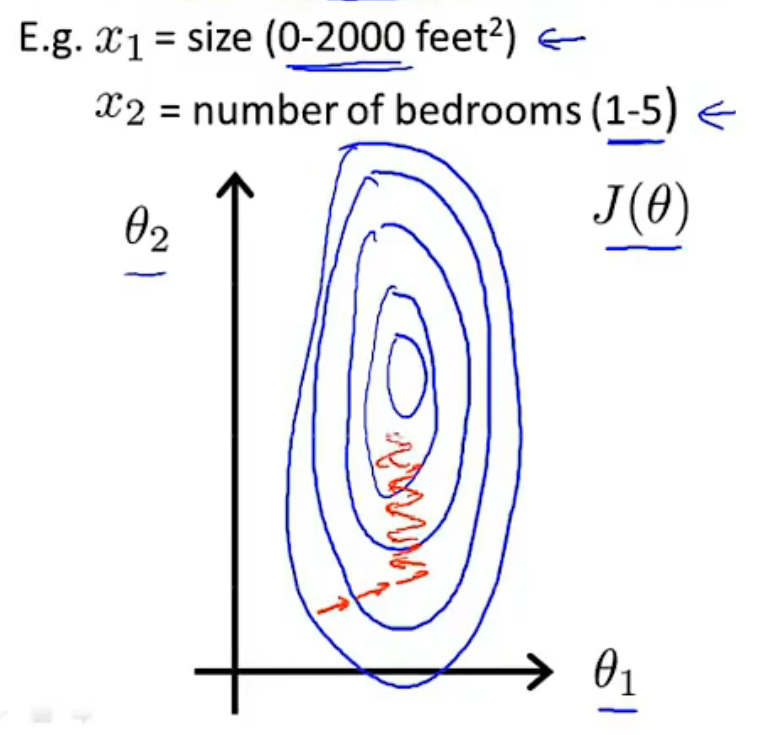
此時可以考慮縮放,
\[x_i = \frac{x_i}{max-min} \]均值歸一化
對于除了 \(x_0\) 以外的特征(因為\(x_0=1\)),
\[\begin{align*} x_i = \frac{x_i-average(x)}{max} \\ x_i = \frac{x_i-average(x)}{max-min} \end{align*} \]在分母中, 可以使用樣本的\(max\)或者\(max-min\),根據需求而定,
特征縮放和均值歸一化的作用都是為了減小樣本資料的波動使得梯度下降能夠更快速的尋找到一條捷徑,從而到達全域最小值,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551317.html
標籤:其他
下一篇:返回列表