分類問題
分類問題和回歸問題的區別是:分類問題的值域是離散的,
- 線性回歸不能應用于分類問題,
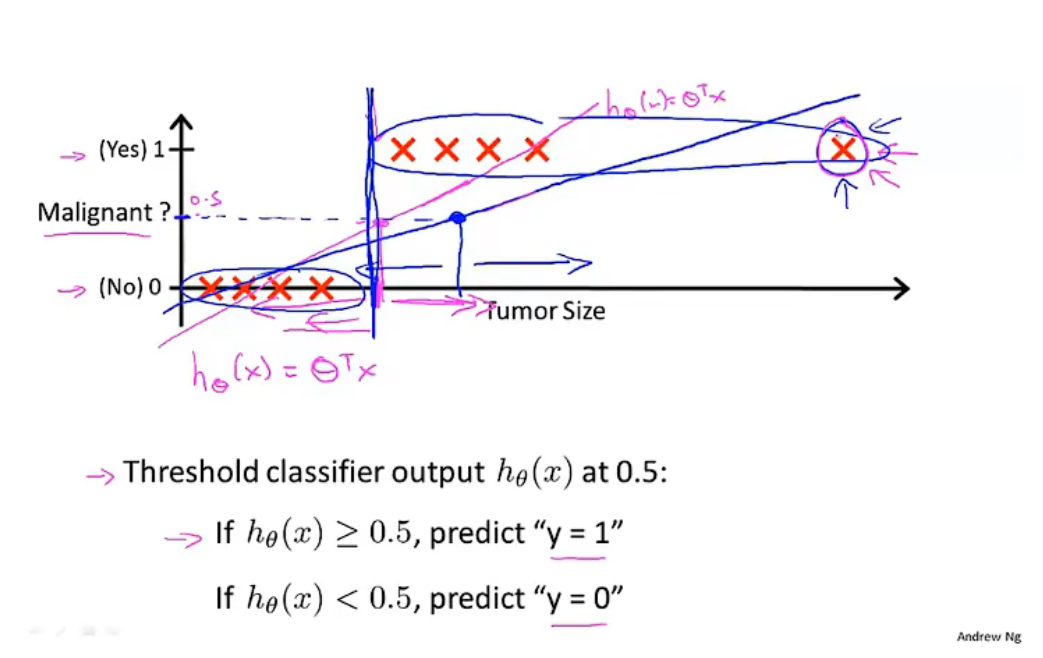
- 邏輯回歸模型
(此處為一元分類問題)
預測函式:
\[h_\theta(x)=g(\theta^Tx) \]其中:
\[g(z) = \frac{1}{1+e^{-z}} \]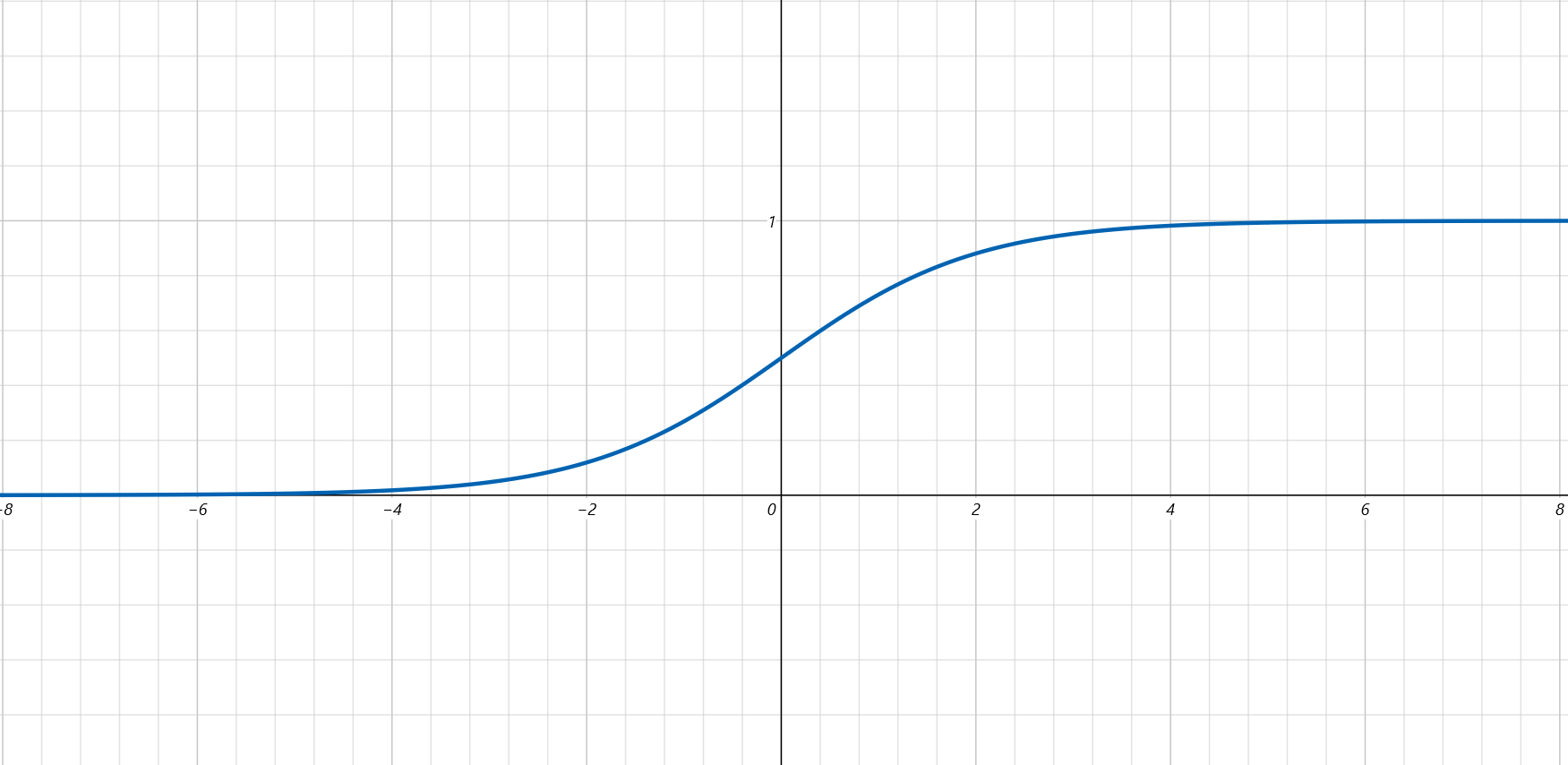
能夠使得:
\[0\le h_\theta(x)\le1 \]預測函式的函式值:
\[y=1\Leftrightarrow h_\theta(x)\ge0.5\Leftrightarrow\theta^Tx\ge0\\ y=0\Leftrightarrow h_\theta(x)<0.5\Leftrightarrow\theta^Tx<0 \]決策界限
\(y=1\ \ or\ \ 0\) 取決于 \(h_\theta(x)\ge0.5\ \ or\ \ h_\theta(x)<0.5\) ,此處的 \(h_\theta(x)=0.5\) 即為決策界限,
將其可視化后,表現為線性界限將空間分為不同型別,
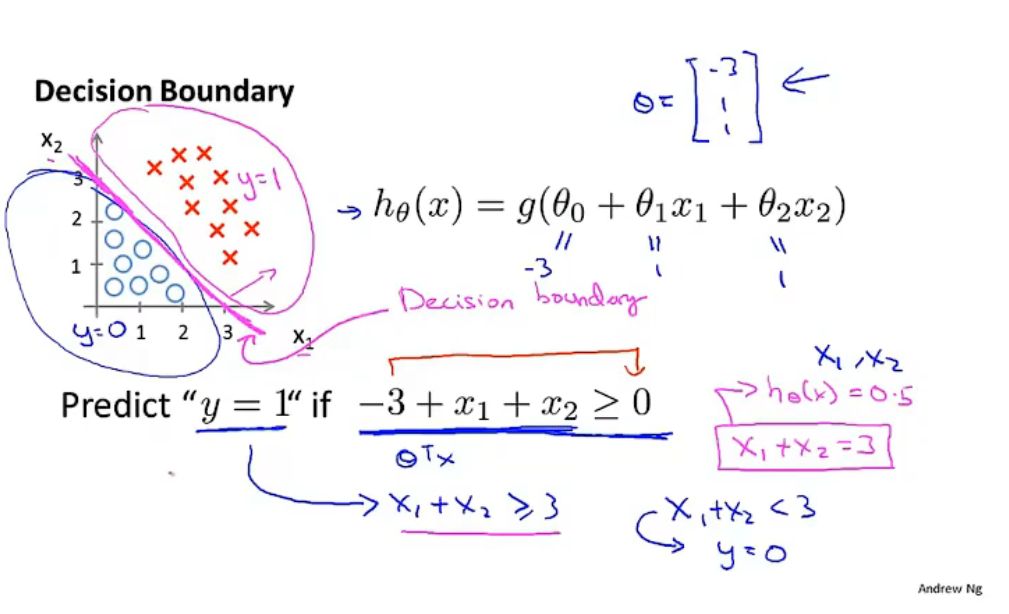
決策邊界由引數 \(\theta\) 確定,引數 \(\theta\) 使用訓練集來擬合,
預測函式使用高階多項式可以得到非線性決策邊界,

擬合
代價函式: \(J(\theta) = \frac{1}{m}\Sigma_{i=1}^mcost(h_\theta(x),y)\)
在線性回歸問題中,\(cost(h_\theta(x),y)=\frac{1}{2}(h_\theta(x)-y)^2\),其中的\(h_\theta(x)\)是線性的,因此\(cost()\)函式是凸函式,使用梯度下降即可求得全域最小值,
而在邏輯回歸問題中,\(h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}\)是非線性的,因此\(cost()\)函式不是凸函式,使用梯度下降只能求得區域最小值,無法確認是否是全域最小值,
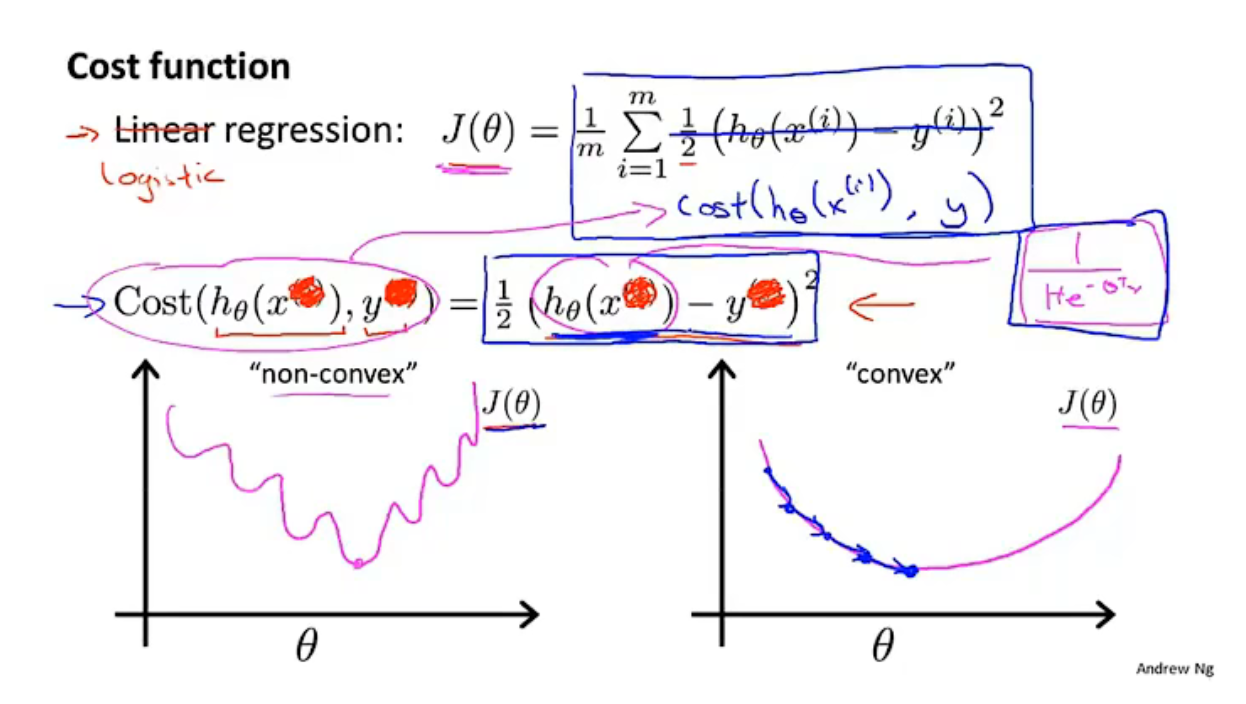
代價函式
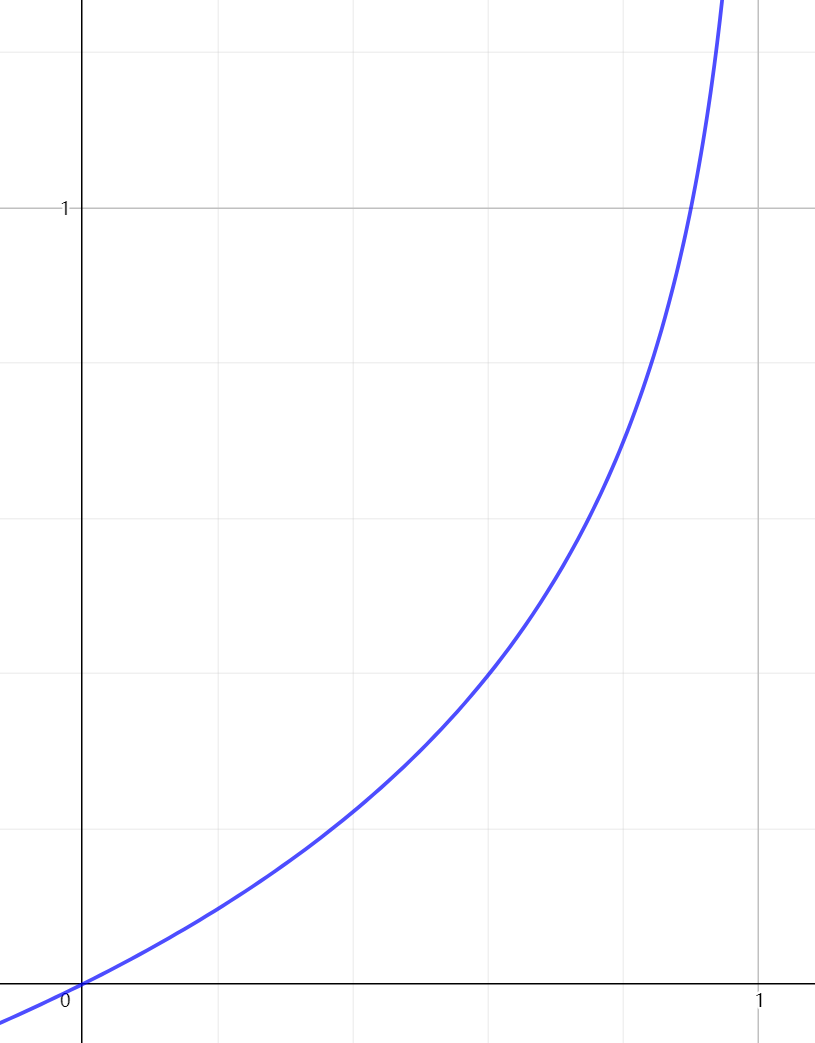
\[cost(h_\theta(x),y)= \left\{ \begin{array}{lr} -log(h_\theta(x))\qquad \quad y=1 \\ -log(1-h_\theta(x)) \quad \ y=0 \end{array} \right. \]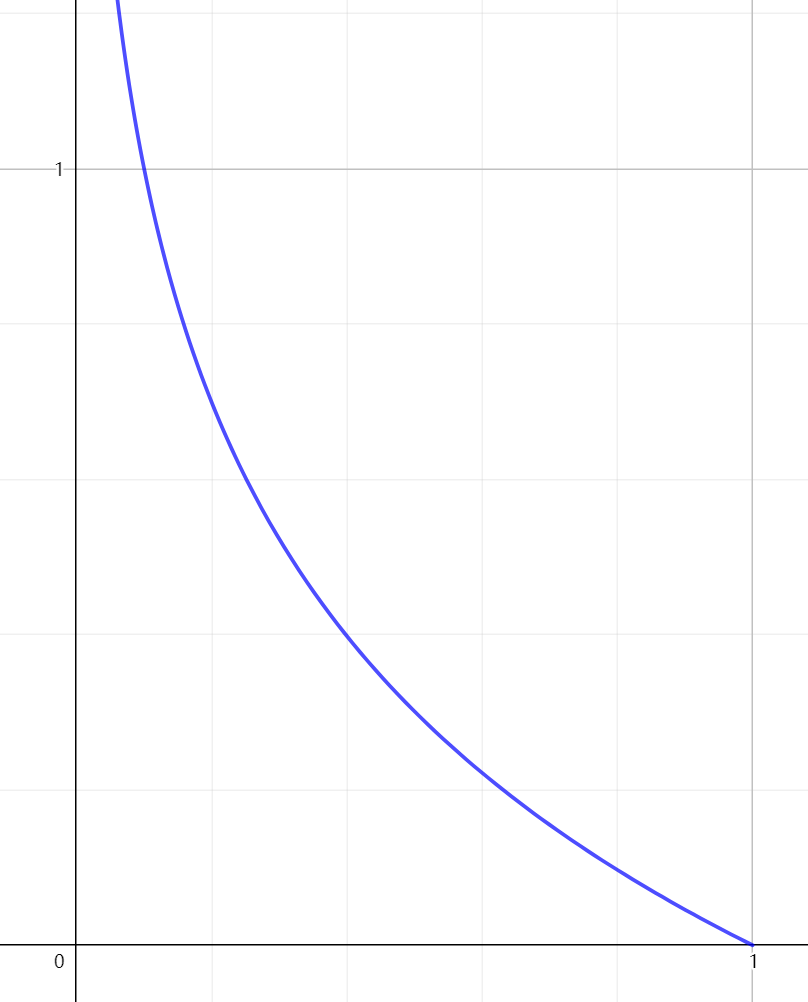
這個函式取自統計學中的極大似然法
對于\(y=1\)的情況來說:
- 如果\(x\rightarrow1\),那么表示猜測效果好,代價很低,\(cost\rightarrow0\).
- 如果\(x\rightarrow0\),那么表示猜測效果很差,代價很高,趨近于\(\infty\),以此來“懲罰”演算法,
由于\(y\)的取值只有0和1兩種情況,可以考慮合并:
\[cost(h_\theta(x),y) = -ylog(h_\theta(x))-(1-y)log(1-h_\theta(x)) \]- 代價函式:
-
目標:求解使得\(\mathop{min}\limits_\theta J(\theta)\)的 \(\theta\).
-
求解方法:使用梯度下降迭代 \(\theta\),使其不斷趨近于最小值點,
多類別分類問題
-
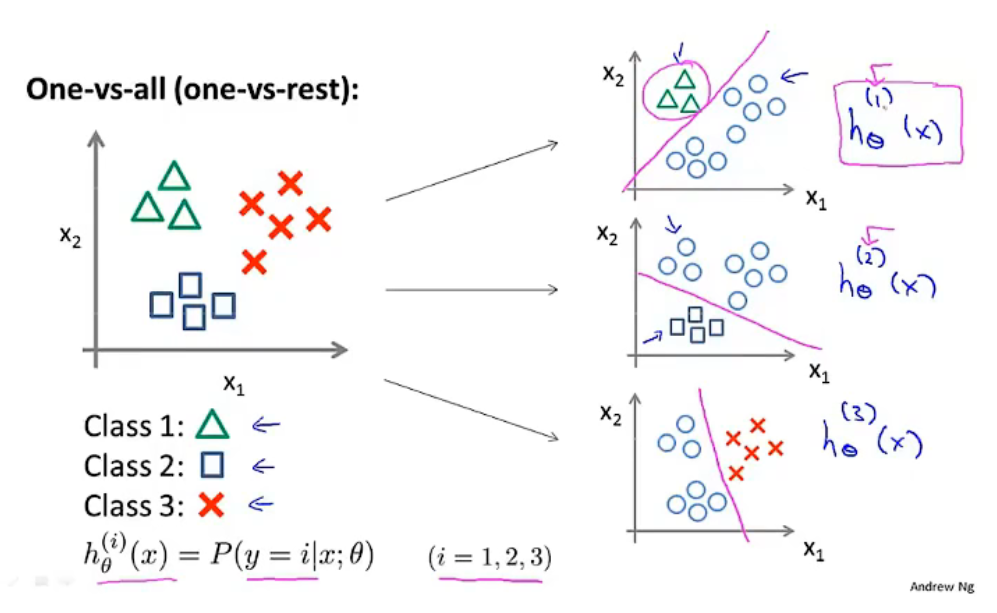
多類別分類問題可以分解為“一對余”方法,
-
將 \(n\) 類別分類問題,分解為 \(k\) 個二元分類問題,得到 \(k\) 個預測模型 \(h_\theta^{(i)}(x)=p(y=i\ | \ x;\ \theta)\),其中: \(i=(1,2,3,...,k)\) .
-
最終預測:
- 在 \(k\) 個預測模型中輸入 \(x\);
- 選擇一個使得 \(h_\theta^{(i)}(x)\)最大的 \(i\) ;
- 則 \(h_\theta^{(i)}(x)\) 為最終的預測結果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551446.html
標籤:其他
上一篇:ChatGPT在工業領域的研究與應用探索-資料與工況認知
下一篇:返回列表