摘要:本文結合Karmada社區對大規模場景的思考,揭示Karmada穩定支持100個大規模集群、管理超過50萬個節點和200萬個Pod背后的原理
本文分享自華為云社區《Karmada百倍集群規模多云基礎設施體系揭秘》,作者: 云容器大未來 ,
隨著云原生技術在越來越多的企業和組織中的大規模落地,如何高效、可靠地管理大規模資源池以應對不斷增長的業務挑戰成為了當下云原生技術的關鍵挑戰,
在過去的很長一段時間內,不同廠商嘗試通過擴展單集群的規模來擴展資源池,然而,Kubernetes社區很早就發布了大規模集群的最佳實踐,其中包括幾項關鍵資料:節點數不超過5k,Pod數不超過150k,單個節點的Pod數量不超過110 k等,這側面說明了支持超大規模的集群不是Kubernetes社區主要努力的方向,同時,以單集群的方式擴展資源池通常需要定制Kubernetes的原生組件,這在增加了架構復雜度的同時也帶來了不少弊端:
(1)集群運維復雜度急劇增加,
(2)與社區演進方向相左,后續的維護成本上升,升級路徑不清晰,
(3)單集群本質上屬于單個故障域,集群故障時將導致無法控制爆炸半徑,
而多集群技術能在不侵入修改Kubernetes單集群的基礎上橫向擴展資源池的規模,在擴展資源池的同時降低了企業的運維管理等成本,此外,多集群系統天然支持多故障域,符合多數業務場景,如多地資料中心、CDN就近提供服務等,

Karmada作為CNCF首個多云容器編排專案,提供了包括Kubernetes原生API支持、多層級高可用部署、多集群故障遷移、多集群應用自動伸縮、多集群服務發現等關鍵特性,致力于讓用戶輕松管理無限可伸縮的資源池,為企業提供從單集群到多云架構的平滑演進方案,
隨著以Karmada為代表的多集群架構在企業的逐步落地,大規模場景下多集群系統的性能問題往往是用戶的核心關注點之一,本文將圍繞以下幾個問題,結合Karmada社區對大規模場景的思考,揭示Karmada穩定支持100個大規模集群、管理超過50萬個節點和200萬個Pod背后的原理,
(1) 如何衡量一個多集群系統資源池的維度與閾值?
(2) 對多集群系統進行大規模環境的壓測時,我們需要觀測哪些指標?
(3) Karmada是如何支撐100個大規模K8s集群并納管海量應用的?
(4) 在Karmada的生產落地程序中,有哪些最佳實踐和引數優化手段可以參考?
多集群系統資源池的維度與閾值
當前,業界對于多云資源池的Scalability尚未達成統一標準,為此,Karmada社區結合企業用戶的實踐,率先對這一問題進行了深入探索,一個多集群系統資源池規模不單指集群數量,實際上它包含很多維度的測量標準,在不考慮其他維度的情況下只考慮集群數量是毫無意義的,在若干因素中,社區按照優先級將其描述為以下三個維度:
(1) 集群數量,集群數量是衡量一個多集群系統資源池規模和承載能力最直接且最重要的維度,
(2) 資源(API物件)數量,對于多集群系統的控制面來說,存盤并不是無限的,在控制面創建的資源物件的數量和總體大小受限于系統控制面的存盤,也是制約多集群系統資源池規模的重要維度,這里的資源物件不僅指下發到成員集群的資源模板,而且還包括集群的調度策略、多集群服務等資源,
(3) 集群規模,集群規模是衡量一個多集群系統資源池規模不可忽視的維度,一方面,集群數量相等的情況下,單個集群的規模越大,整個多集群系統的資源池越大,另一方面,多集群系統的上層能力依賴系統對集群的資源畫像,例如在多集群應用的調度程序中,集群資源是不可或缺的一個因素,綜上所述,單集群的規模與整個多集群系統息息相關,但單集群的規模同樣不是制約多集群系統的限制因素,用戶可以通過優化原生的Kubernetes組件的方式來提升單集群的集群規模,達到擴大整個多集群系統的資源池的目的,但這不是衡量多集群系統性能的關注點,在集群的標準配置中,Node與Pod毫無疑問是其中最重要的兩個資源,Node是計算、存盤等資源的最小載體,而Pod數量則代表著一個集群的應用承載能力,
大規模場景下多集群系統的性能指標
在多集群系統的大規模落地行程中,如何衡量多集群聯邦的服務質量是一個不可避免的問題,在參考了Kubernetes社區的SLI(Service Level Indicator)/SLO(Service Level Objectives)和多集群系統的落地應用后,Karmada社區定義了以下SLI/SLO來衡量大規模場景下多集群聯邦的服務質量,
API Call Latency
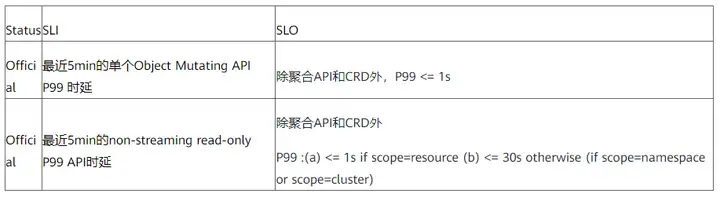
注:API呼叫時延仍然是衡量基于Kubernetes的多集群系統服務質量的關鍵指標,Karmada兼容Kubernetes原生API,用戶除了使用原生API創建K8s的資源模板外,也可以使用Karmada自有API來創建多集群策略和訪問跨集群的資源,
Resource Distribution Latency

Cluster Registration Latency

注:集群注冊時延是從集群注冊到控制面到集群在聯邦側可用的時延,它反映了控制面接入集群以及管理集群的生命周期的性能,但它在某種程度上取決于控制面如何收集成員集群的狀態,因此,我們不會對這個指標進行強制的限制,
Resource Usage

注:資源使用量是多集群系統中非常重要的指標,我們希望在納管海量的集群和資源的同時消耗盡量少的系統資源,但由于不同的多集群系統提供的上層服務不同,因此對于不同的系統,其對資源的要求也會不同,因此,我們不會對這個指標進行強制的限制,
Karmada百倍集群規模基礎設施揭秘
Karmada社區在結合對上述兩個問題的思考以及用戶在落地程序中的反饋后,測驗了Karmada同時管理100個5K節點和2w Pod的Kubernetes集群的場景,本文不詳細描述具體的測驗環境資訊與測驗程序,而是側重于對測驗結果進行分析
在整個測驗程序中,API呼叫時延均符合上述定義的SLI/SLO,

圖一:只讀API(cluster-scope)呼叫時延

圖二:只讀API(namespace-scope)呼叫時延
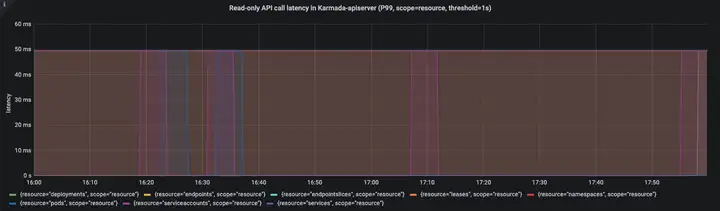
圖三:只讀API(resource-scope)呼叫時延
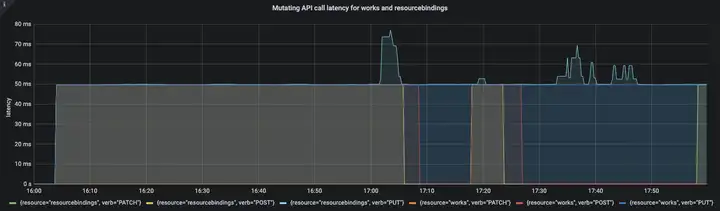
圖四:Mutating API呼叫時延
Karmada在百倍集群規模下,仍能做到快速的API回應,這取決于Karmada獨特的多云控制面架構,事實上,Karmada在架構設計之初就采用了關注點分離的設計理念,使用Kubernetes原生API來表達集群聯邦資源模板,使用可復用的策略API來表達多集群的管理策略,同時控制面的資源模板作為應用的模板,不會在控制面生成具體的Pod,不同集群的應用在控制面的映射(Work物件)通過命名空間來進行安全隔離,完整的API作業流如下圖所示,如此設計,不僅可以讓Karmada能夠輕松集成Kubernetes的生態, 同時也大大減少了控制面的資源數量和承載壓力,基于此,控制面的資源數量不取決于集群的數量,而是取決于多集群應用的數量,
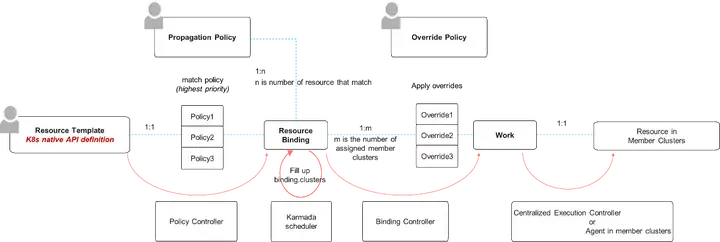
此外,Karmada的架構極具簡潔性和擴展性,karmada-apiserver作為控制面的入口與kube-apiserver類似,即使是在百倍集群規模下,Karmada仍能保持快速API回應,
Karmada支持通過命令列快速接入集群,以及集群的全生命周期管理,Karmada會實時采集集群心跳和狀態,其中集群狀態包括集群版本、支持的API串列、集群健康狀態以及集群資源使用量等,其中,Karmada會基于集群資源使用量對成員集群進行建模,這樣調度器可以更好地為應用選擇資源足夠的目標集群,在這種情況下,集群注冊時延與集群的規模息息相關,下表展示了加入一個5,000節點的集群直至它可用所需的時延,你可以通過關閉集群資源建模來使集群注冊時延與集群的大小無關,在這種情況下,集群注冊時延這個指標將小于2s,
Cluster Registration Latency:

Karmada支持多模式的集群統一接入,在Push模式下,Karmada控制面直連成員集群的kube-apiserver,而在Pull模式下,Karmada將在成員集群中安裝agent組件,并委托任務給它,因此Push模式多用于公有云的K8s集群,需要暴露APIServer在公網中,而Pull模式多用于私有云的K8s集群,下表展示了Karmada在不同模式下下發一個應用到成員集群所需的時延,
Resource Distribution Latency:
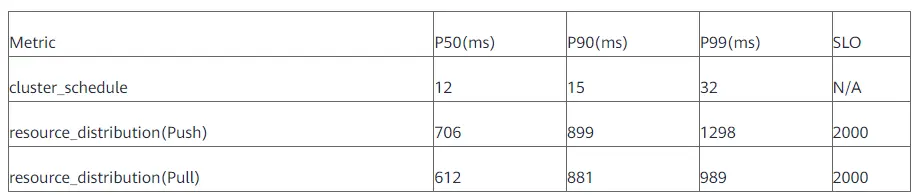
結論:我們容易得出,不論是Push模式還是Pull模式,Karmada都能高效地將資源下發到成員集群中,
在Karmada演進的數個版本中,大規模場景下使用Karmada管理多云應用的資源消耗一直是用戶比較關注的問題,Karmada社區做了許多作業來減少Karmada管理大型集群的資源使用量,比如我們優化了Informer的快取,剔除了資源無關的節點、Pod元資料;減少了控制器內不必要的型別轉換等等,相較于1.2版本,當前Karmada在大規模集群場景下減少了85%的記憶體消耗和32%的CPU消耗,下圖展示了不同模式下Karmada控制面的資源消耗情況,
Push模式:



Pull模式:



總的來說,系統消耗的資源在一個可控制面的范圍,其中Pull模式在記憶體使用上有明顯的優勢,而在其他資源上相差的不大,
Karmada大規模環境下的最佳實踐
Karmada支持性能引數的可配置化,用戶可以通過調整組件的引數來調整同一時間段內并發處理Karmada內部物件的數量、系統的吞吐量等以優化性能,同時Karmada在不同模式下的性能瓶頸并不相同,以下著重對此進行分析,
在Push模式中,控制面的資源消耗主要集中在karmada-controller-manager(約70%),而Karmada控制面基座(etcd/karmada-apiserver)的壓力不大,

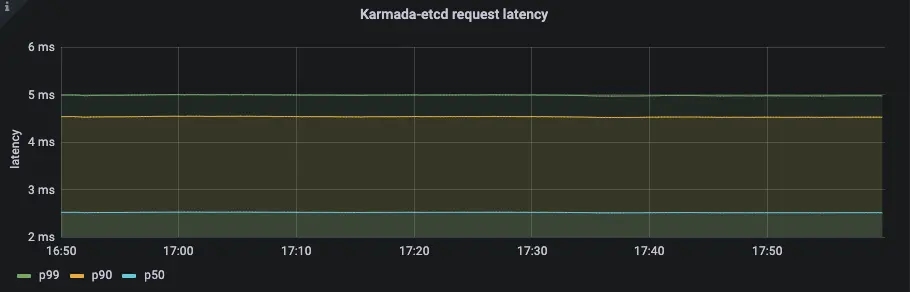
結合karmada-apiserver的qps以及karmada-etcd的請求時延我們可以看出karmada-apiserver的請求量保持在一個較低的水平,在Push模式中,絕大多數的請求來自karmada-controller-manager,因此我們可以通過調整karmada-controller-manager的--concurrent-work-syncs來調整同一時間段并發work的數量來提升應用下發的速度,也可以配置--kube-api-qps和--kube-api-burst這兩個引數來控制Karmada控制面的整體流控,
在Pull模式中,控制面的資源消耗主要集中在karmada-apiserver,而不是karmada-controller-manager,

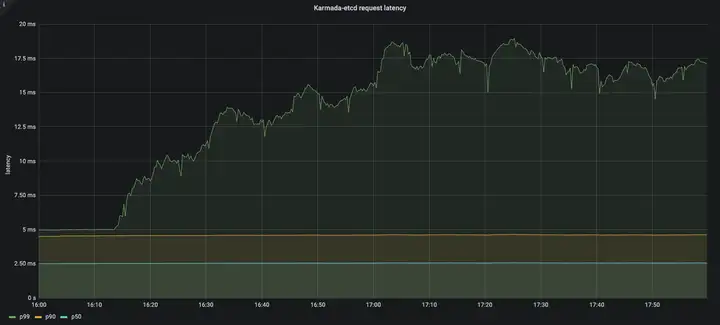
結合karmada-apiserver的qps以及karmada-etcd的請求時延我們可以看出karmada-apiserver的請求量保持在一個較高的水平,在Pull模式中,每個成員集群的karmada-agent需要維持一條與karmada-apiserver通信的長連接,我們很容易得出:在下發應用至所有集群的程序中請求總量是karmada-agent中配置的N倍(N=#Num of clusters),因此,在大規模Pull模式集群的場景下,Pull模式在資源下發/狀態收集方面有更好的性能,但同時需要考慮控制面的抗壓能力以及各個karmada-agent和控制面的整體流控,
當前,Karmada提供了集群資源模型的能力來基于集群空閑資源做調度決策,在資源建模的程序中,它會收集所有集群的節點與Pod的資訊,這在大規模場景下會有一定的記憶體消耗,如果用戶不使用這個能力,用戶可以關閉集群資源建模來進一步減少資源消耗,
總結
根據上述測驗結果分析,Karmada可以穩定支持100個大規模集群,管理超過50萬個節點和200萬個Pod,在Karmada落地行程中,用戶可以根據使用場景選擇不同的部署模式,通過引數調優等手段來提升整個多集群系統的性能,
受限于測驗環境和測驗工具,上述測驗尚未測驗到Karmada多集群系統的上限,同時多集群系統的分析理論以及測驗方法仍處于方興未艾的階段,下一步我們將繼續優化多集群系統的測驗工具,系統性地整理測驗方法,以覆寫更大的規模和更多的典型場景,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552217.html
標籤:其他
上一篇:IntelliJ IDEA 最新激活碼:2023、2022及以下版本通用(親測有效)
下一篇:返回列表