摘要:作為兩次獲得全球總冠軍的軟挑老兵,劉露撰文分享其賽隊參賽體驗,包括解題思路及對抗策略、比賽識訓等,
本文分享自華為云社區《奪冠秘訣?華為軟體精英挑戰賽兩屆冠軍這樣復盤比賽經驗》,作者:華為云社區精選,
4月23日,2023第九屆華為軟體精英挑戰賽-“普朗克計劃”全球總決賽及頒獎典禮圓滿落幕,大賽吸引了來自全球645所高校、3887支隊伍、23078名大學生報名參賽,歷時一個多月的激烈角逐,經過八大賽區區域初賽、區域復賽、全球總決賽等環節的層層考驗,最終,成渝賽區來自電子科技大學的“_______”隊(“下劃線隊”)獲得全球總決賽冠軍,作為兩次獲得全球總冠軍的朋友,劉露撰文分享其賽隊參賽體驗,包括解題思路及對抗策略、比賽識訓等,

圖片▲ 圖左二為劉露
華為軟體精英挑戰賽是華為公司面向全球在校大學生舉辦的大型軟體編程競賽,向來有趣且具有挑戰性,受到眾多參賽選手的青睞,2021年我獲得軟挑冠軍后,開始忙于考研及科研等事情,因此遺憾于未能參加2022年的比賽,到了今年,我終于又有空參加軟挑,早在比賽正式開始前,我就和兩位隊友組好了隊共同備戰,
賽題介紹
今年賽題抽象自華為云智能機器人的真實業務,模擬了多機器人的運行環境以及真實機器人的狀態資訊,由參賽者通過代碼操控機器人完成特定任務以實作收益最大化,大賽賽題還原物理引擎、激光雷達、真實操控介面等機器人業務真實場景,引入業界熱門演算法難題,包括最優調度問題、多機器人路徑協調規劃問題、動態避障演算法等,在初賽、復賽、決賽進行有層次的難度遞進,

▲ 圖為總決賽地圖之一
初賽
初賽我們隊打得挺狼狽的,最終是以賽區第31名的成績茍進了復賽,原因在于我們出現了策略上的失誤,期望能通過一個較通用的演算法在四張公開的地圖上得到一個不錯的分數,但實際上,在資料集公開且數量較少的情況下,針對每個資料集分別設計擬合的演算法是更容易拿到高分的,我們在初賽快結束時才意識到這個問題和著手設計擬合資料集的演算法,但由于時間比較緊迫,分數提升得比較有限,最終只是勉強搭上了進入復賽的末班車,但塞翁失馬,焉知非福,我們在初賽設計的較通用的調度演算法,雖然在初賽作用不大,卻成為了我們在復賽和決賽中均取得第一的重要因素,
復賽
復賽增加了障礙物,要求機器人具有尋路及讓路功能,難度一下子增加了不少,復賽前期我們主要在實作機器人尋路及讓路功能并優化機器人的運動,后期發現我們的尋路演算法具有嚴重的bug,會將一些可達的作業臺判定為不可達(之前我們判定一個作業臺可達時會要求機器人能夠站在作業臺中心而不與障礙物碰撞,但實際上只要機器人離作業臺較近就能進行買賣),因此修復該bug就成為了一個極其緊急的任務,這個bug在復賽正式賽當天凌晨4點才被一位隊友修復完,凌晨5點我就起床進行代碼審查并進行一些細微的調整,以確保剛大改完的代碼在復賽現場能按預期運行,
由于復賽正式賽只有三個小時,并且地圖為兩張公開兩張隱藏,選手不易撰寫擬合資料的策略,因此我們使用了初賽準備的通用的調度策略,配合我們最終實作的尋路和讓路演算法,我們較為順利地拿下了復賽全國第一名,
決賽
決賽引入紅藍雙方對抗,敵方機器人作為己方機器人的移動障礙,難度大幅增加,但我們沒有在決賽初期就設計針對決賽的策略,而是重構了我們復賽階段最終的代碼,提升其簡潔性、可維護性和可拓展性,以便于在決賽階段我們能夠方便地修改代碼,重構完畢后,我們便著手設計決賽策略,通過四張公開的練習地圖評估了讓機器人占領敵方作業臺和追蹤敵方機器人兩種攻擊策略的效果,也嘗試了一些避免被敵方機器人卡死的策略,事實證明,決賽初期的重構確實是很有幫助的,我們嘗試的各種策略在重構后的代碼上都能較為方便地實作,
需要指出的是,在決賽練習賽階段,我們排名大多數時間都是第十幾名,這是因為我們沒有過多地擬合練習賽資料,而是將精力放到準備通用的策略上,我認為這也是我們最終奪冠的關鍵,在決賽正式賽的天梯賽階段,我們隊排名始終靠前,我們分析了少數幾場我們失敗的對局,稍微修改了機器人的運動控制,最終成功獲得天梯賽第一名,為我們在PK淘汰賽中爭取了一個占據優勢的分組,進而最終在PK淘汰賽中完勝,勇奪總冠軍,
決賽有一件比較有趣的事:由于我們的筆記本電腦本地跑測驗太慢了,一位隊友直接將自己的臺式機背到了決賽現場,這臺機器大大加快了我們的測驗速度,讓我們在修改代碼后能夠快速驗證其有效性,這也是我們能夠奪冠的不可忽略的因素,

▲ 總決賽現場圖
整體方案
此處我們以一種自頂向下的方式介紹我們隊的整體方案,我們首先介紹最高層的對抗策略,然后介紹中層的調度演算法、尋路演算法、讓路演算法,最后介紹最底層的運動控制演算法,
對抗策略
決賽地圖分為四種型別,賽題組在決賽前已經公布了四種型別的特征,相當于劃定了考試范圍,我們只需要分別考慮四種地圖對應的策略即可,而不必考慮各種復雜又不一定會出現的情況,
我們先介紹四種地圖的共同點以及我們隊在每種地圖上都使用的共同策略,決賽地圖保證資源足夠豐富,避免了出現敵方卡住某些作業臺導致己方被完全卡住的情況,因此占領敵方作業臺在決賽中收益不高,我們隊無論作為紅方還是藍方,都不會采用該策略,我們采用的(但不是每張圖都采用)唯一攻擊策略就是追隨敵方機器人,以限制其移動或將其完全卡住,但我們還是需要考慮敵方占領我們的作業臺的情況,應對措施為:如果發現某個己方機器人的目標作業臺被敵方占領了,就切換目標作業臺(由于決賽地圖保證資源足夠豐富,這是可行的),
接下來介紹我們針對四種地圖各自的特征設計的策略,
型別一:相對開闊的地形,各自的資源點都比較豐富,雙方運輸路徑存在交錯,
策略:對于這種型別,我們采取了最佛系的做法,無論我們是藍方還是紅方,我們都不會去進攻(占領敵方作業臺或追隨敵人),這是因為地圖較開闊時,難以將敵方機器人卡住,而由于資源點又比較豐富,讓機器人去從事生產會更加劃算,
型別二:相對開闊的地形,各自的資源點都比較豐富,地圖被分割為兩個不連通區域,其中一個區域為紅色基地,只有紅色作業臺,機器人初始為3紅1藍,另一個區域為藍色基地,只有藍色作業臺,機器人初始為3藍1紅,
策略:賽題組設計這樣的地圖的目的很明確,就是讓選手必須控制在敵方基地的己方機器人去進攻,在這種地圖上,無論在紅方還是藍方,我們都是讓在敵方基地的那個己方機器人去跟隨敵人機器人,以干擾其生產,
型別三:相對狹窄的地形,雙方有各自獨立基地,基地之間存在多條路徑連通,并且基地外部存在一些分散的紅藍作業臺可使用,
策略:由于地圖比較狹窄,如果己方機器人去跟隨的話,容易將敵方機器人卡在墻角,此時其他敵方機器人的路也可能被擋住,因此很有可能實作一換一甚至一換多的效果,所以,在這種圖上,無論我們是紅藍哪方,我們都選擇讓一個機器人去跟隨敵方機器人,其他三個機器人從事生產,此處的一個關鍵點是千萬別讓己方負責追隨的機器人在自己基地追隨敵人,因為敵方機器人也可能來到己方基地搗亂,如果在己方基地追隨它的話,容易卡住自己的基地,
型別四:極為開闊的地形,整張地圖完全沒有藍色作業臺,只有紅色作業臺,且紅色作業臺點比較豐富,
策略:在這種地圖上,作為藍方時,由于沒有藍色作業臺,只能去攻擊敵人,我們采取的策略是讓每個機器人都去追隨最近的敵方機器人,但我們會保證每個機器人追隨不同的敵人(否則極端情況下可能所有藍色機器人都去圍堵一個紅色機器人,四換一就太虧了),這樣就容易出現每個藍色機器人各自卡死一個紅色機器人,完全阻礙敵方生產的情況;作為紅方時,我們讓每個機器人都從事生產,期望獲得較高的收益,
調度演算法
調度演算法的總體邏輯為,每次為每個空閑的機器人分配一個買賣任務,該任務指定了機器人先去哪個作業臺買然后去哪個作業臺賣,為了避免出現所有購買的產品被其他機器人買掉和所有售賣物品賣不掉的情況,需要對購買的作業臺和售賣的作業臺加鎖,加鎖就需要考慮鎖的粒度,我們不是對整個作業臺加鎖,而是對購買的作業臺的產品格和售賣的作業臺的原料格加鎖,但如果購買的物品為1、2或3的話,我們不會對作業臺的產品格加鎖,這樣做是考慮到1、2和3號物品生產較快且不需要原料,即使被其他機器人先買掉了也能快速生產出來,
一個空閑的機器人可選擇的買賣任務可能有多個,選擇哪一個呢?我們總是選擇性價比最高的任務,具體地,我們評估每個任務能帶來的收益,并估計完成該任務需要的時間,選擇其中收益除以時間最大的那個,估計完成一個任務所需的時間較為容易,只需要計算機器人從當前位置移動到購買作業臺的路徑長度加上從購買作業臺移動到售賣作業臺的長度得到總移動距離,再除以運動速度即可,關鍵是估計一個任務的價值,最簡單的估價方式就是用物品的售出價格減去購買價格,但這個估價方式忽略了很多需要考慮的因素,
我們來考慮完成一個買賣任務會帶來哪些直接或間接的收益:
- 物品本身買賣會有一個直接的利潤;
- 如果一個作業臺生產被阻塞(生產所需的原料都有了,但由于產品格非空,無法消耗掉這些原料),則無法將任何物品賣給它,此處如果我們購買了它的產品,其材料格中的材料就能被消耗,我們就能賣物品給它了;
- 將一個物品賣給一個作業臺,可以促進該作業臺的生產,作業臺生產又帶來兩方面的好處:
1、已有的材料被消耗,可以將更多的材料賣給它;
2、生產出的產品可以被進一步賣給其他作業臺促進物品7的合成(如果作業臺的型別為4、5或6的話),
為了體現以上這些考慮,我們實作了以下代碼所示的任務估值函式:
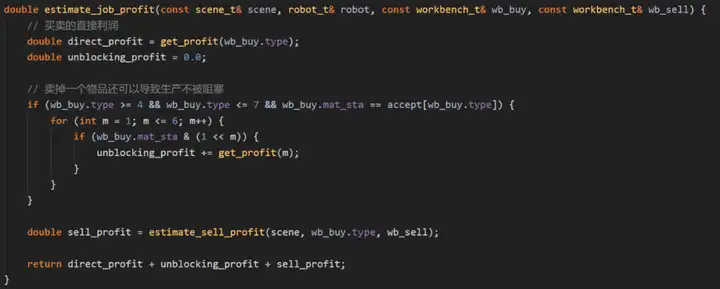
代碼中,direct_profit 表示買賣物品帶來的直接收益,unblocking_profit表示消除阻塞帶來的間接收益,sell_profit表示將一個物品賣給給定作業臺能夠帶來的間接收益,以下我們給出計算sell_profit的方法:
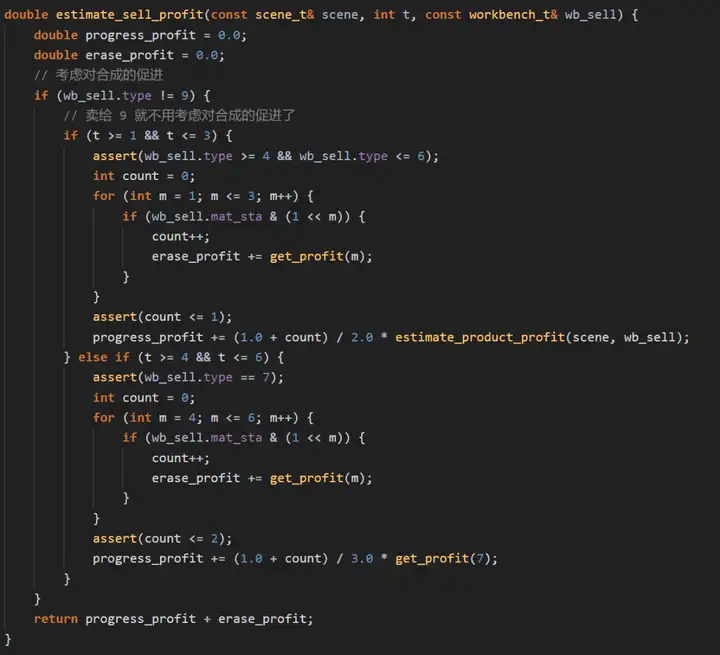
將物品賣給作業臺后,會導致作業臺消耗材料進行生產,這樣材料格就會空出,可以收購新的物品,這就帶來一個間接的收益,我們此處用erase_profit表示,如果我們是將物品賣給型別為4、5或6的作業臺,還能促進合成4、5、6,進而促進合成7,我們通過estimate_product_profit()函式計算在當前狀態下合成4、5或6能帶來的收益,此處用progress_profit表示,接下來再看下estimate_product_profit()的實作:
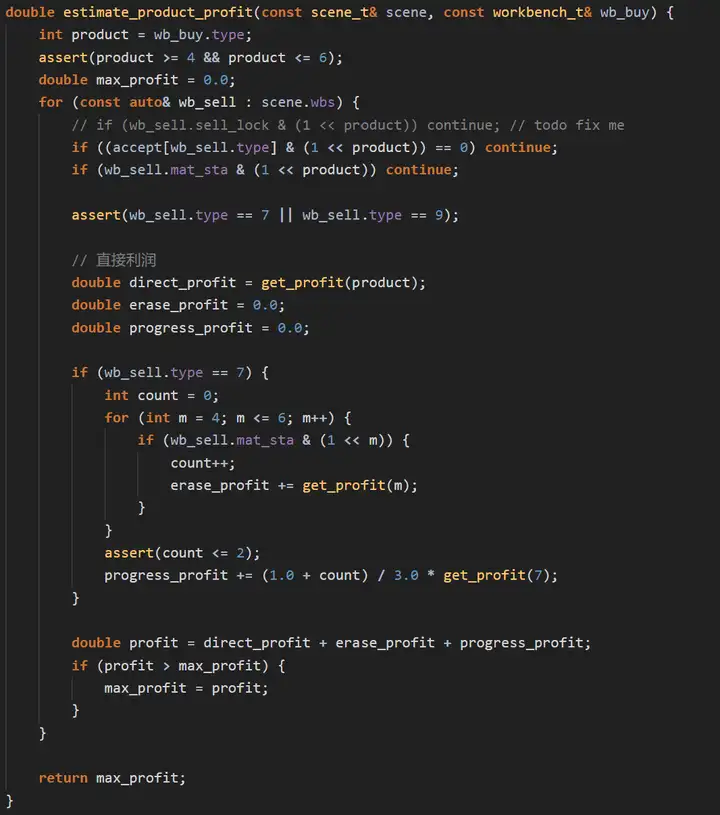
estimate_product_profit()計算將一個型別為4、5或6的物品賣給作業臺7或9所帶來的收益,該收益類似于前面由direct_profit、erase_profit和progress_profit三部分組成,選擇三者和最大的回傳,
尋路演算法
我們將地圖分為0.25*0.25的格子,考慮水平線和垂直線的交點(而不是格子的中心點),我們將這樣的點稱為格點,注意到,根據賽題設定,一開始所有作業臺和機器人的中心都落在某個格點上,一個障礙物的四個角都各是一個格點,此外,前面提到過,有些作業臺中心機器人是無法到達的,但機器人不必到達作業臺中心就能進行買賣,我們可以通過選擇一些距離作業臺中心距離小于0.4米的點作為一個作業臺的代表點來解決這個問題,實際實作時,我們選擇了4個距離作業臺中心距離為0.35米的點來作為代表點,尋路時,只要機器人能夠到達代表點中的任何一個,就可以認為機器人能夠到達對應作業臺,
在我們的實作中,機器人每幀都會進行尋路,尋路時只考慮八個方向的移動,求出最短路徑,然后計算該路徑上機器人能直接到達的最遠點,控制機器人向該點移去,
讓路演算法
讓路演算法分為碰撞檢測和尋找避讓點兩步,每一幀,由于我們都重新呼叫了尋路演算法,我們可以根據計算得到的路徑預測機器人是否會碰撞,如果預測會碰撞,我們讓優先級低的機器人尋找一個避讓點移動過去,避讓點的計算方法為:從機器人所在位置進行BFS搜索一個可達的且不靠近要避讓的機器人的路徑的點,如果一個機器人無法找到避讓點,則會提升其優先級以讓對方來避讓,
運動控制
運動控制這邊需要用到一點基礎的物理知識,設機器人當前在點A,其最大加速度為a(可以通過賽題所給引數計算出a),我們希望移動到并剛好停留在點B,假設機器人現在已經朝向B,那么當前幀機器人的速度應該設定為多少呢?首先我們希望該速度盡可能大,這樣機器人能夠快速到達B,但速度又不能太大以至于我們無法在B處剎住車,因此我們所要的速度應該滿足:當以最大加速度a減速時,能夠在到達B前剎住車,設AB間的距離為s,則容易計算出該速度為sqrt(2as),類似地,如果我們想讓機器人旋轉theta度,設角加速度為alpha,則將角速度設定為sqrt(2 * theta * alpha),
最終我們的運動控制如下:每一幀我們都計算機器人當前朝向與到目標點的方向的夾角theta,如果theta大于一定閾值,則將速度設定為0,按照上述方式設定角速度校正方向;如果theta小于一定閾值,則按照上述方式設定速度和角速度,
總結
此次軟挑,我們隊并非一帆風順,初賽險遭淘汰,復賽正式賽前還在修復嚴重的bug,決賽練習賽階段排名也不靠前,但好在有驚無險,我們最終拿到了總冠軍,我認為我們取勝的關鍵在于我們設計的演算法比較有通用性,沒有過分擬合資料集,因此能夠在復賽正式賽和決賽正式賽更換資料集后取得不錯的成績,——電子科技大學 劉露
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552321.html
標籤:其他
上一篇:軟體測驗工程師的技能樹
下一篇:返回列表