系列文章
- Grafana 系列文章
概述
我們是基于這篇文章: Grafana 系列文章(十二):如何使用 Loki 創建一個用于搜索日志的 Grafana 儀表板, 創建一個類似的, 但是基于 ElasticSearch 的日志快速搜索儀表板.
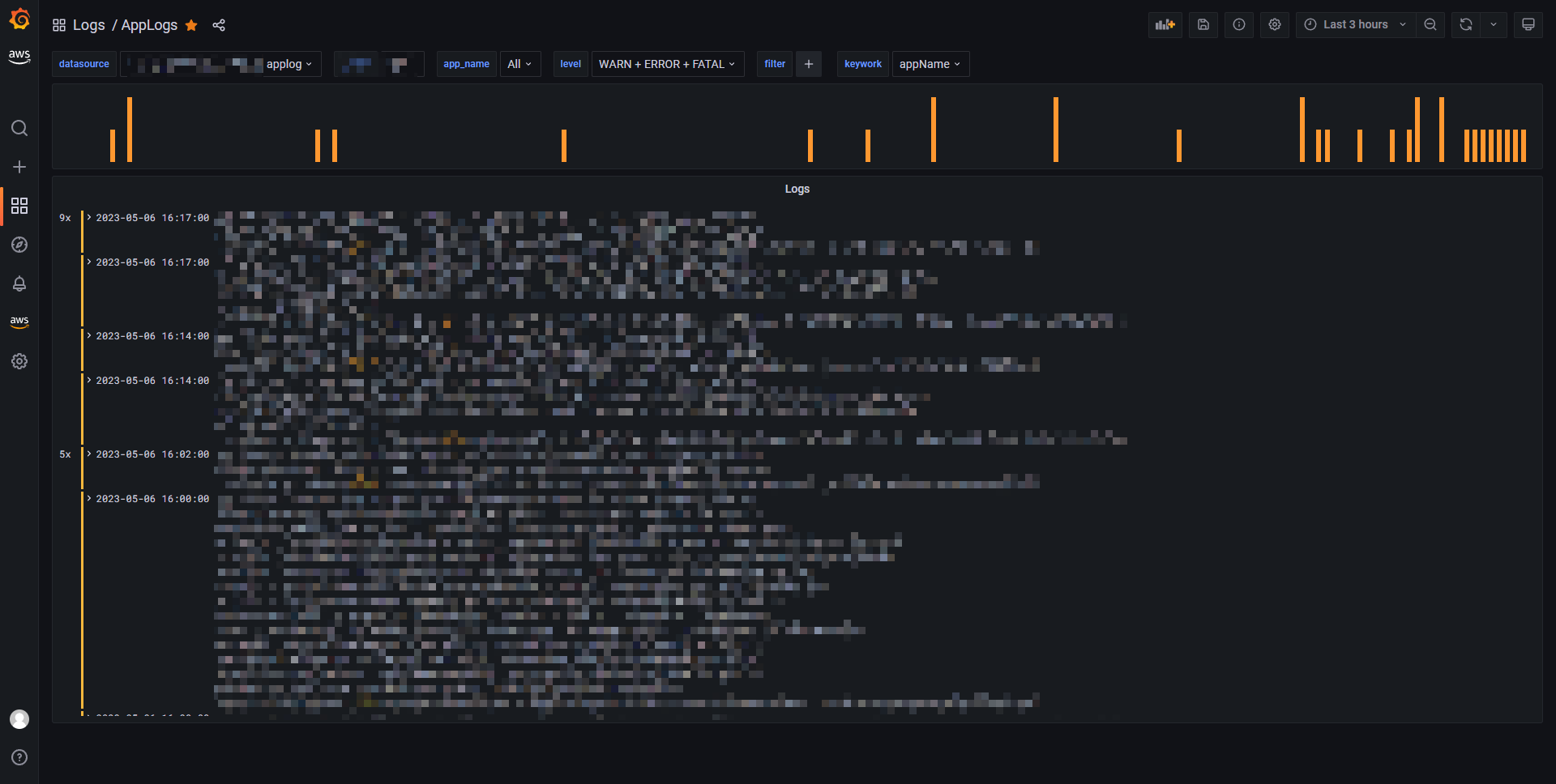
最終完整效果如下:
??Notes:
其實我基于 ElasticSearch 做了2個儀表板
- 用于檢索 Applog 的
- 用于檢索 accesslog 的
在下面的講解中會綜合2個儀表板來進行說明.
這次不會講述詳細細節, 只選擇部分關鍵點進行說明.
知識儲備
創建 Query
使用自定義的JSON字串撰寫查詢,field 在Elasticsearch索引映射中被映射為一個 keyword,
如果查詢是 multi-field 的 text 和 keyword 型別,使用 "field": "fieldname.keyword"(有時是fieldname.raw)來指定你查詢中的關鍵字欄位,
Query
| Query | Description |
|---|---|
{"find": "fields", "type": "keyword"} |
回傳一個索引型別為keyword 的欄位名串列, |
{"find": "terms", "field": "hostname.keyword", "size": 1000} |
使用 terms 聚合回傳一個 keyword 的值串列,查詢將使用當前儀表板的時間范圍作為時間范圍查詢, |
{"find": "terms", "field": "hostname", "query": '<Lucene query>'} |
使用terms 聚合和指定的Lucene查詢過濾器,回傳一個keyword field 的值串列,查詢將使用當前儀表板的時間范圍作為查詢的時間范圍, |
terms 的查詢默認有500個結果的限制,要設定一個自定義的限制,需要在你的查詢中設定size屬性,
Variable 語法
面板標題和 metric 查詢可以使用多種不同的語法來參考變數:
$varname, 這種語法很容易閱讀,但它不允許你在詞的中間使用變數,例如:apps.frontend.$server.requests.count${var_name}, 當你想在運算式的中間插值一個變數時,請使用這種語法,${var_name:<format>}這種格式讓你對Grafana如何插值有更多控制,[[varname]]不建議使用,廢棄的舊語法,將在未來的版本中洗掉,
高級變數格式選項
變數插值的格式取決于資料源,但在有些情況下,你可能想改變默認的格式,
例如,MySql資料源的默認格式是以逗號分隔的方式連接多個值,并加引號, 如:'server01', 'server02'.在某些情況下,你可能希望有一個不帶引號的逗號分隔的字串, 如:server01,server02,你可以用下面列出的高級變數格式化選項來實作這一目的,
通用語法
語法: ${var_name:option}
可以在Grafana Play網站上測驗格式化選項,
如果指定了任何無效的格式化選項,那么 glob 就是默認/回退選項,
CSV
將具有多個值的變數形成一個逗號分隔的字串,
servers = ['test1', 'test2']
String to interpolate: '${servers:csv}'
Interpolation result: 'test1,test2'
分布式 - OpenTSDB
以OpenTSDB的自定義格式對具有多個值的變數進行格式化,
servers = ['test1', 'test2']
String to interpolate: '${servers:distributed}'
Interpolation result: 'test1,servers=test2'
雙引號
將單值和多值變數形成一個逗號分隔的字串,在單個值中用\"轉義",并將每個值用""引號括起來,
servers = ['test1', 'test2']
String to interpolate: '${servers:doublequote}'
Interpolation result: '"test1","test2"'
Glob - Graphite
將具有多個值的變陣列成一個glob(用于Graphite查詢),
servers = ['test1', 'test2']
String to interpolate: '${servers:glob}'
Interpolation result: '{test1,test2}'
JSON
將具有多個值的變數形成一個逗號分隔的字串,
servers = ['test1', 'test2']
String to interpolate: '${servers:json}'
Interpolation result: '["test1", "test2"]'
Lucene - Elasticsearch
以Lucene格式對Elasticsearch的多值變數進行格式化,
servers = ['test1', 'test2']
String to interpolate: '${servers:lucene}'
Interpolation result: '("test1" OR "test2")'
URL 編碼 (Percentencode)
對單值和多值變數進行格式化,以便在URL引數中使用,
servers = ['foo()bar BAZ', 'test2']
String to interpolate: '${servers:percentencode}'
Interpolation result: 'foo%28%29bar%20BAZ%2Ctest2'
Pipe
將具有多個值的變數形成一個管道分隔的字串,
servers = ['test1.', 'test2']
String to interpolate: '${servers:pipe}'
Interpolation result: 'test1.|test2'
Raw
關閉資料源特定的格式化,如SQL查詢中的單引號,
servers = ['test.1', 'test2']
String to interpolate: '${var_name:raw}'
Interpolation result: 'test.1,test2'
Regex
將有多個值的變數形成一個regex字串,
servers = ['test1.', 'test2']
String to interpolate: '${servers:regex}'
Interpolation result: '(test1\.|test2)'
單引號
將單值和多值變數形成一個逗號分隔的字串,在單個值中用\'轉義',并將每個值用'引號括起來,
servers = ['test1', 'test2']
String to interpolate: '${servers:singlequote}'
Interpolation result: "'test1','test2'"
Sqlstring
將單值和多值變陣列成一個逗號分隔的字串,每個值中的'用''轉義,每個值用'引號括起來,
servers = ["test'1", "test2"]
String to interpolate: '${servers:sqlstring}'
Interpolation result: "'test''1','test2'"
Text
將單值和多值變數轉換成其文本表示法,對于一個單變數,它將只回傳文本表示法,對于多值變數,它將回傳與+相結合的文本表示法,
servers = ["test1", "test2"]
String to interpolate: '${servers:text}'
Interpolation result: "test1 + test2"
查詢引數
將單值和多值變數編入其查詢引數表示法,例如:var-foo=value1&var-foo=value2
servers = ["test1", "test2"]
String to interpolate: '${servers:queryparam}'
Interpolation result: "servers=test1&servers=test2"
配置變數選擇選項
Selection Options 是一個你可以用來管理變數選項選擇的功能,所有的選擇選項都是可選的,它們在默認情況下是關閉的,
Multi-value Variables
內插一個選擇了多個值的變數是很棘手的,因為如何將多個值格式化為一個在使用該變數的給定環境中有效的字串并不直接,Grafana試圖通過允許每個資料源插件告知模板插值引擎對多個值使用什么格式來解決這個問題,
??Notes:
變數上的Custom all value選項必須為空,以便Grafana將所有值格式化為一個字串,如果它留空,那么Grafana就會把查詢中的所有值連接起來(加在一起),類似于
value1,value2,value3,如果使用了一個自定義的所有值,那么該值將是類似于*或all的東西,
帶有Prometheus或InfluxDB資料源的多值變數
InfluxDB和Prometheus使用regex運算式,所以host1, host2, host3 變數會被插值為{host1,host2,host3},每個值都會被regex轉義,
使用Elastic資料源的多值變數
Elasticsearch使用lucene查詢語法,所以同樣的變數會被格式化為("host1" OR "host2" OR "host3"),在這種情況下,每一個值都必須被轉義,以便該值只包含lucene控制詞和引號,
Include All 選項
Grafana在變數下拉串列中添加了一個 All 選項,如果用戶選擇了這個選項,那么所有的變數選項都被選中,
自定義 all 的值
這個選項只有在選擇了 Include All option 時才可見,
在Custom all value欄位中可以輸入regex、globs或lucene語法來定義All選項的值,
默認情況下,All 值包括組合運算式中的所有選項,這可能會變得非常長,而且會產生性能問題,有時,指定一個自定義的所有值可能會更好,比如通配符,
為了在 Custom all value 選項中擁有自定義的regex、globs或lucene語法,它永遠不會被轉義,所以你將不得不考慮什么是你的資料源的有效值,
ElasticSearch Template Variables
選擇一種 Variable 語法
如上文所述, Elasticsearch資料源支持在查詢欄位中使用多種變數語法.
當啟用 Multi-value 或 Include all value 選項時,Grafana 會將標簽從純文本轉換為與 Lucene 兼容的條件,即隱式轉換 $varname 為 ${varname:lucene}
實戰
1. 弄清楚有哪些索引欄位
首先, 最重要的, 就是弄清楚該索引有哪些索引欄位(fields), 以及有哪些keywords, 選擇部分欄位和 keywords 作為 varibles. 可以直接通過 Kibana 界面進行查詢和嘗試.
如本次選擇的有:
app_namelevelrequest_path(?? 通過多次在 Kibana 上使用發現, 查詢時應該使用request_path.keyword而不是request_path)request_methodstatus_code
2. 創建 Variables
app_name
設定如下:
- Name:
app_name - Type: Query
- Data source: ES
- Query:
{"find": "terms", "field": "current_app_name"}, 另外, 如果嵌套使用, 可以類似這樣{"find": "terms", "field": "pod_name", "query": "app_name:$app_name"}
request_path
設定如下:
- Name:
request_path - Type: Query
- Data source: ES
- Query:
{"find": "terms", "field": "request_path.keyword", "query": "app_name:$app_name"} - Multi-value: ??
- Include All option: ??
- Custom all value:
*
?? 注意, 這里使用了 Custom all value, 最終 Query All 的運算式就會變成: request_path.keyword:* 而不是 request_path.keyword:(<path1> OR <path2> ...)
request_method
request_method 常用的就這么幾個:
- GET
- POST
- DELETE
- HEAD
- PUT
- PATCH
- OPTIONS
所以可以將其設定為 Custom variable, 設定如下:
- Name:
request_method - Type: Custom
- Values separated by comma:
GET,POST,DELETE,HEAD, PUT,PATCH,OPTIONS - Multi-value: ??
- Include All option: ??
- Custom all value:
*
level
日志級別可以直接使用 Custom 型別變數. 如下:
- Name:
level - Type:
Custom - Values separated by comma:
INFO, WARN, ERROR,FATAL - Multi-value: ??
- Include All option: ??
如果只關注錯誤日志, 那么 level 變數的默認值可以設定為同時勾選: ERROR 和 FATAL
status_code
這里會將 status_code variable 用于 Lucene 的范圍語法 [](包括開頭和結尾的2個數字), 所以有用到Custom all value 以及 Variable 語法配置.
- Name:
status_code - Type:
Custom - Values separated by comma:
200 TO 299, 300 TO 399, 400 TO 499, 500 TO 599 - Include All option: ??
- Custom all value:
200 TO 599(??Note: 即包括所有的 http 狀態碼, 從 200 到 599)
后續要在 Query 中使用, 用法如下:
status_code:[${status_code:raw}]
直接使用 ${status_code:raw}, 這樣傳入就會變成:
status_code:[200 TO 299]
status_code:[200 TO 599]
按期望完成對 ES 的查詢.
filter
最后, 還添加一個 Ad hoc filters variable, 方便用戶進行更多自定義的過濾篩選.
- Name: filter
- Type:
Ad hoc filters - Data source:
${datasource}
后續會在該 Dashboard 的所有 Query 中自動使用. 一個典型使用場景如下:
對于 request_path, 需要過濾監控/健康檢查等請求(包含info health metric 等關鍵詞), 那么可以將該 filter 保存為默認的變數值.

3. Panel
Dashboard 只有 2 個面板組成:
- 上圖: Time series, 顯示日志柱狀圖, 并著色,
INFO日志為綠色,WARN日志為黃色,ERROR和FATAL日志為紅色. - 下日志
Time series panel
如下圖:
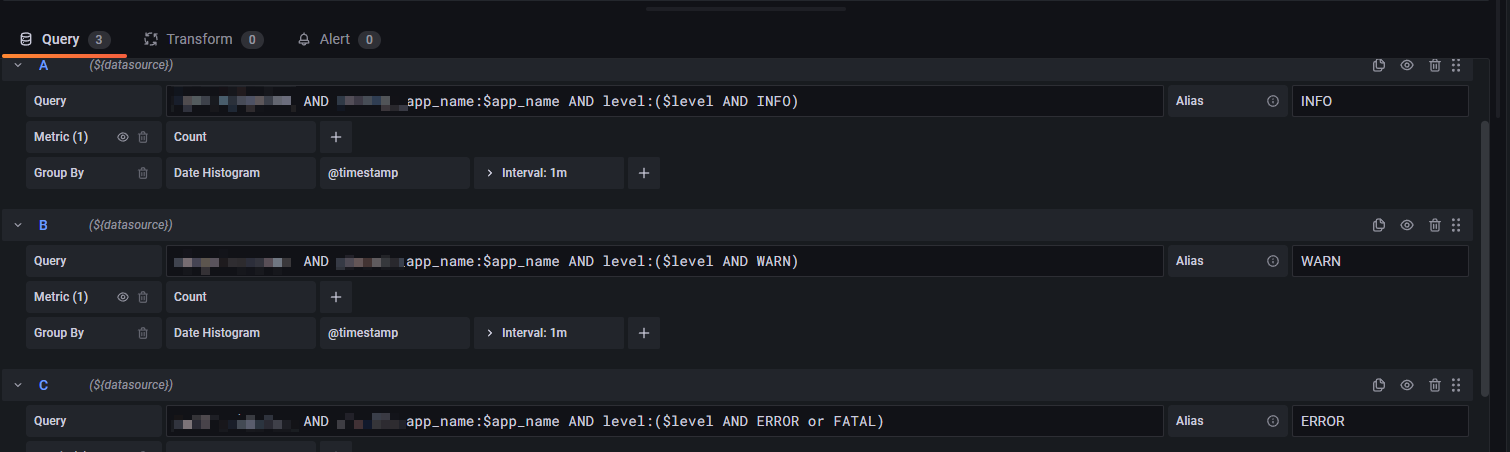
可以通過如下 Query 實作:
app_name:$app_name AND level:($level AND INFO)
app_name:$app_name AND level:($level AND ERROR or FATAL)
$level AND INFO 這種寫法是一個 workaround, 為的是在 level 變數改變時, Time series panel 隨之改變.
另外一個需要注意的點是, Metric 是 Count(日志條數) 而不是 Logs (具體日志).
還有, 需要配置 Override -> Color, 如下:
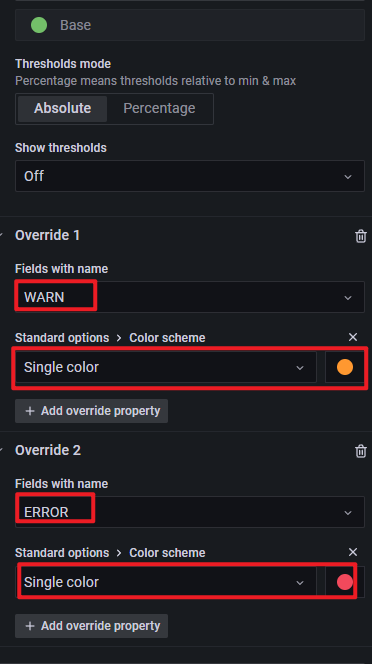
最后, 如果柱子太密, 可以通過調整如 3 Colors Time series panel 圖中的 Interval 來調整時間間隔, 本例調整為 1m
Logs panel
在 Logs panel 中, 也可以根據實際情況做一系列調整.
如下圖, 可以對日志展示方式做調整:
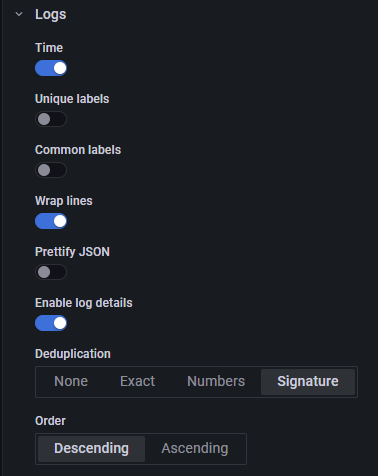
- Time: 是否加時間戳
- Unique labels: 是否每條日志加 label
- Common labels: 是否對 logs panel 左上角對所有日志加 common labels
- Wrap lines
- Pretify JSON: JSON 美化
- Enable log details: 啟用查看日志詳細資訊
- Deduplication: 日志去重, 去重方式有:
- None: 不去重
- Exact: 精確去重
- Numbers: 不同數字記為同一類的去重方式
- Signature: 根據計算得出的 Signature 去重
- Order: 排序.
另外, 考慮到 ES 日志的 log details 會有很多我們不關注的 fields, 如: _source _id 等, 可以通過 Transform 進行轉換調整. 具體如下圖:
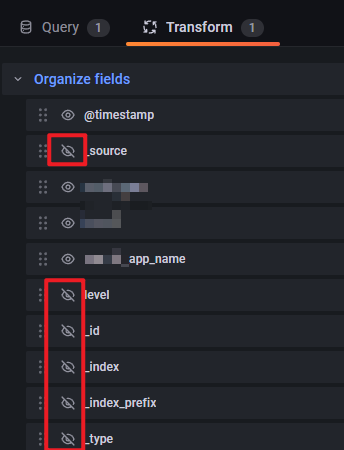
總結
這篇文章算是該系列文章的一個重點了. 包含了非常多的實用細節.
如:
- ES Query
- Variable 語法
- Variable raw 語法
- Lucene - Elasticsearch 語法
- …
- Multi-value Variables
- Include All 選項
- 自定義 all 的值
Ad hoc filtersVariable- ES Metric Type
- Count
- Logs
- …
- 調整Query 時間間隔
- Logs panel 設定
- Panel Transform
希望對你有所幫助.
三人行, 必有我師; 知識共享, 天下為公. 本文由東風微鳴技術博客 EWhisper.cn 撰寫.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552379.html
標籤:其他
上一篇:聯邦學習:聯邦場景下的域泛化
下一篇:返回列表