百度飛槳(PaddlePaddle)安裝
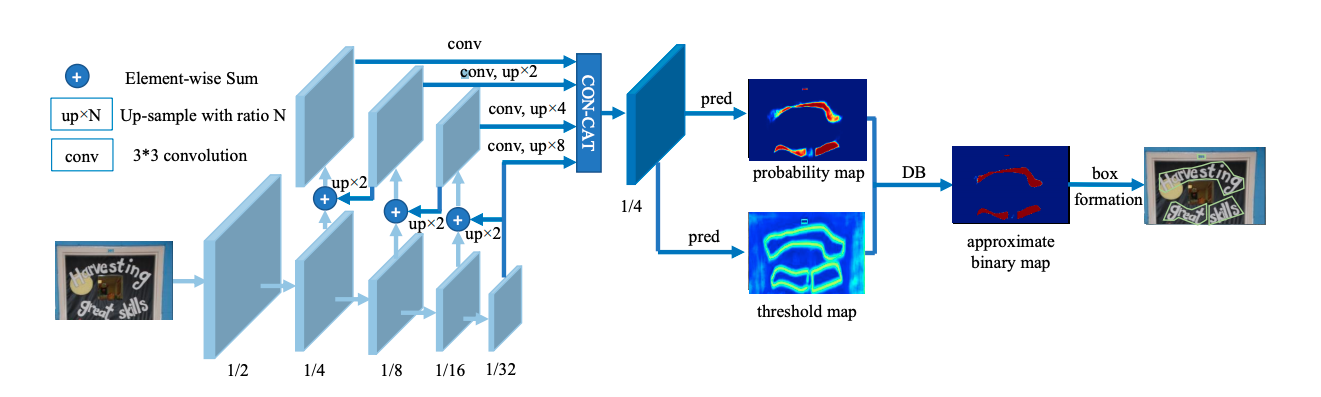
OCR 文字檢測(Differentiable Binarization --- DB)
OCR的技術路線

PaddleHub 預訓練模型的網路結構是 DB + CRNN, 可微的二值化模塊(Differentiable Binarization,簡稱DB)
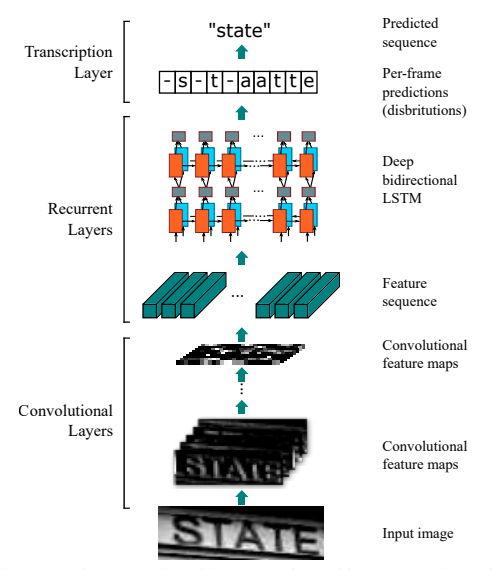
CRNN(Convolutional Recurrent Neural Network)即卷積遞回神經網路, 是DCNN和RNN的組合
DB(Differentiable Binarization)是一種基于分割的文本檢測演算法,將二值化閾值加入訓練中學習,可以獲得更準確的檢測邊界,從而簡化后處理流程,DB演算法最終在5個資料集上達到了state-of-art的效果和性能
CRNN(Convolutional Recurrent Neural Network)即卷積遞回神經網路,是DCNN和RNN的組合,專門用于識別影像中的序列式物件,與CTC loss配合使用,進行文字識別,可以直接從文本詞級或行級的標注中學習,不需要詳細的字符級的標注
安裝庫
Building wheel for opencv-python (pyproject.toml):https://www.cnblogs.com/vipsoft/p/17386638.html
# 安裝 PaddlePaddle
python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安裝 PaddleHub Mac 電腦上終端會感覺卡死的狀態,可以添加 --verbose,查看進度
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
# 該Module依賴于第三方庫shapely、pyclipper,使用該Module之前,請先安裝shapely、pyclipper
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
定義待預測資料
將預測圖片存放在一個檔案中 picture.txt
./images/231242.jpg
./images/234730.jpg
測驗輸出
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 將預測圖片存放在一個檔案中(picture.txt)
with open('picture.txt', 'r') as f:
test_img_path=[]
for line in f:
test_img_path.append(line.strip())
# 顯示圖片
img1 = mpimg.imread(line.strip())
plt.figure(figsize=(10, 10))
plt.imshow(img1)
plt.axis('off')
plt.show()
print(test_img_path) # => ['images/231242.jpg', 'images/234730.jpg']
加載預訓練模型
PaddleHub提供了以下文字識別模型:
移動端的超輕量模型:僅有8.1M,chinese_ocr_db_crnn_mobile
服務器端的精度更高模型:識別精度更高,chinese_ocr_db_crnn_server,
識別文字演算法均采用CRNN(Convolutional Recurrent Neural Network)即卷積遞回神經網路,其是DCNN和RNN的組合,專門用于識別影像中的序列式物件,與CTC loss配合使用,進行文字識別,可以直接從文本詞級或行級的標注中學習,不需要詳細的字符級的標注,該Module支持直接預測, 移動端與服務器端主要在于骨干網路的差異性,移動端采用MobileNetV3,服務器端采用ResNet50_vd
import paddlehub as hub
# 加載移動端預訓練模型
# ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服務端可以加載大模型,效果更好
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
預測
PaddleHub對于支持一鍵預測的module,可以呼叫module的相應預測API,完成預測功能,
module 'numpy' has no attribute 'int'.: 解方法見:https://www.cnblogs.com/vipsoft/p/17385169.html
import paddlehub as hub
import cv2
# 加載移動端預訓練模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服務端可以加載大模型,效果更好 -- 【個人電腦,記憶體不夠用】
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
# 將預測圖片存放在一個檔案中(picture.txt)
test_img_path = []
with open('picture.txt', 'r') as f:
for line in f:
test_img_path.append(line.strip())
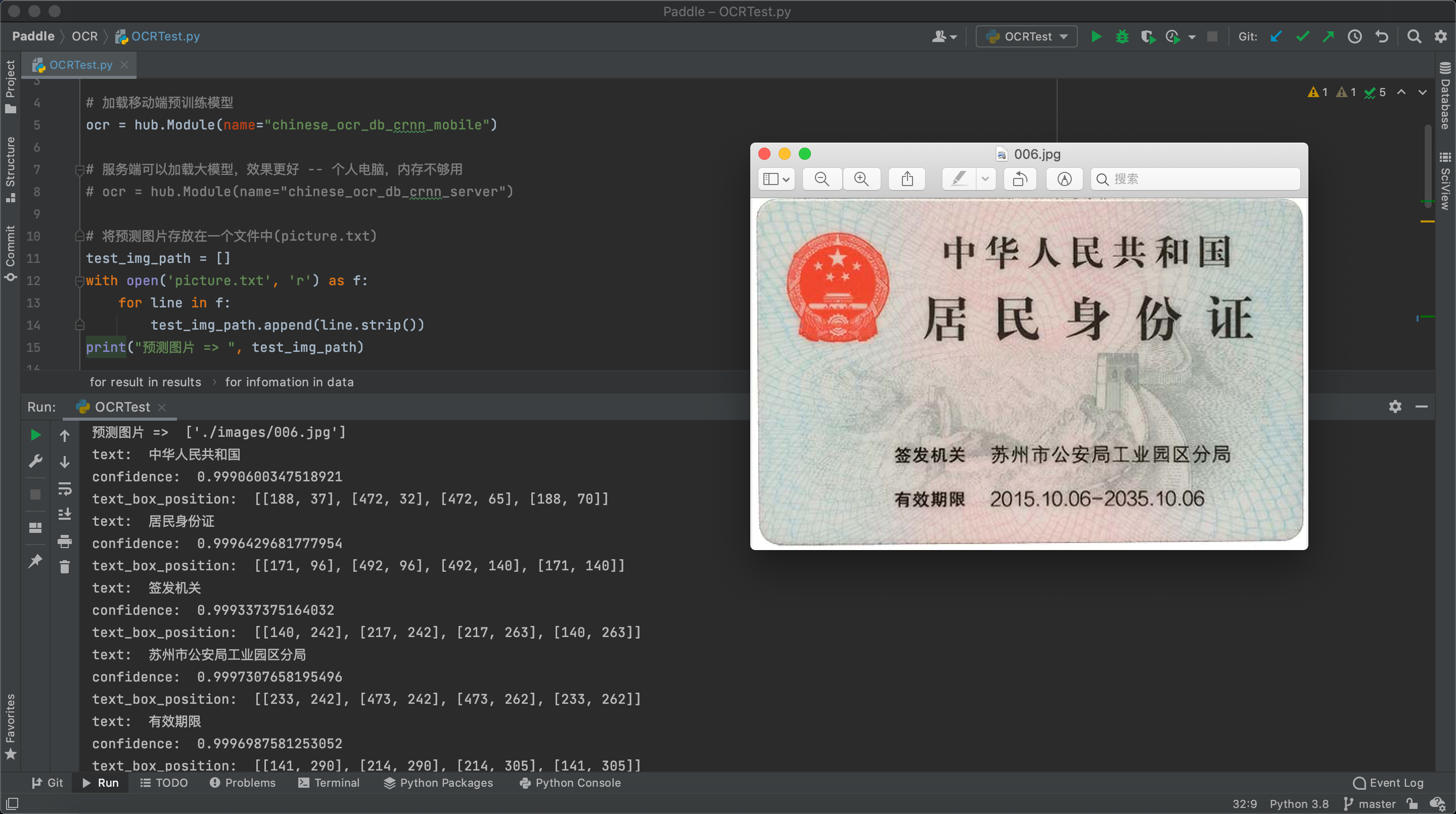
print("預測圖片 => ", test_img_path)
# 讀取測驗檔案夾test.txt中的照片路徑
np_images = [cv2.imread(image_path) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 圖片資料,ndarray.shape 為 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,請先設定CUDA_VISIBLE_DEVICES環境變數
output_dir='ocr_result', # 圖片的保存路徑,默認設為 ocr_result;
visualization=True, # 是否將識別結果保存為圖片檔案;
box_thresh=0.5, # 檢測文本框置信度的閾值;
text_thresh=0.5) # 識別中文文本置信度的閾值;
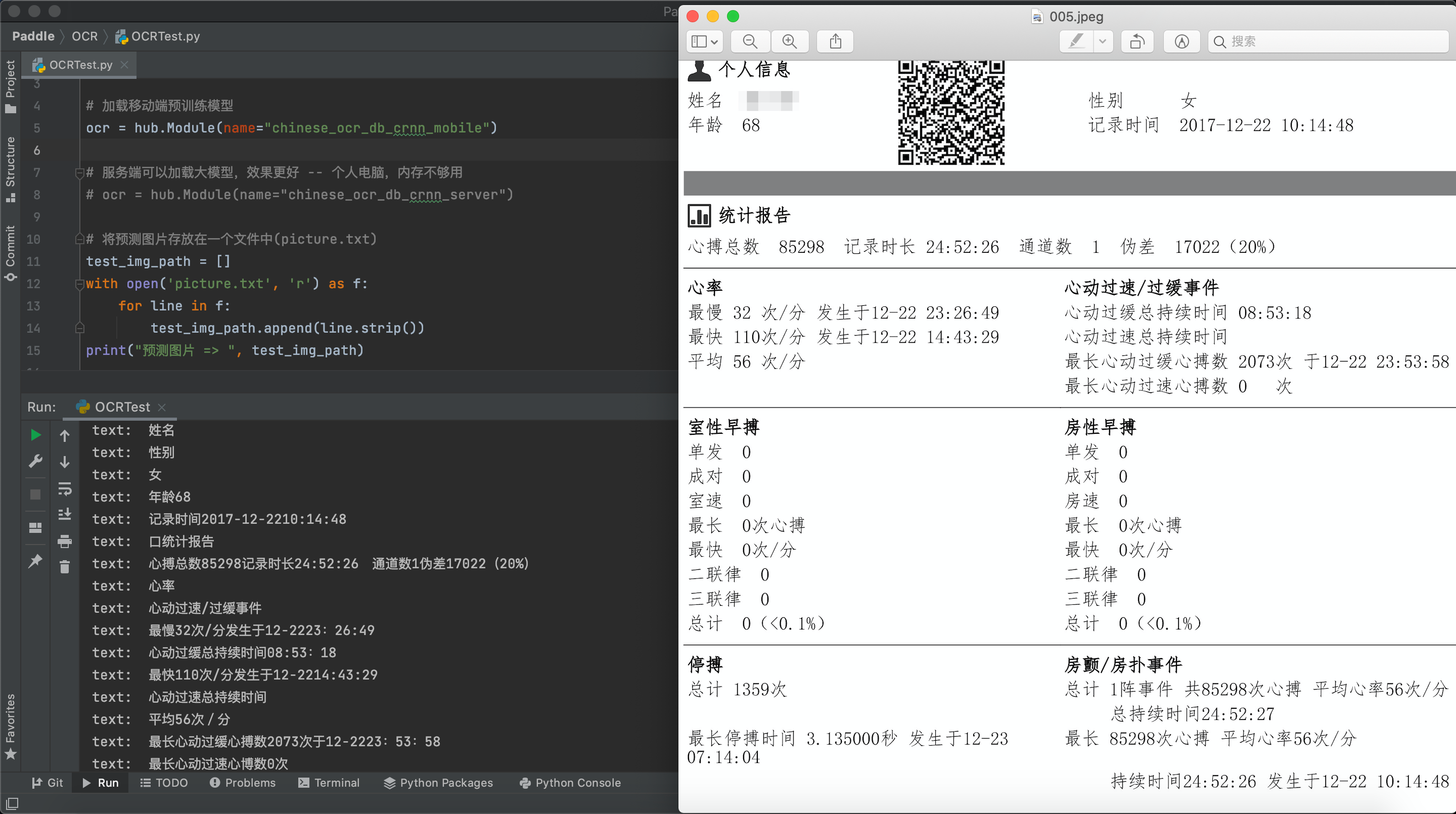
for result in results:
data = https://www.cnblogs.com/vipsoft/p/result['data']
save_path = result['save_path']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
輸出
"D:\Program Files\Python38\python.exe" D:/OpenSource/PaddlePaddle/OCR/OCRTest.py
預測圖片 => ['./images/123.jpg']
text: 中華人民共和國
confidence: 0.9990600347518921
text_box_position: [[188, 37], [472, 32], [472, 65], [188, 70]]
text: 居民身份證
confidence: 0.9996429681777954
text_box_position: [[171, 96], [492, 96], [492, 140], [171, 140]]
text: 簽發機關
confidence: 0.9993374347686768
text_box_position: [[140, 242], [217, 242], [217, 263], [140, 263]]
text: 蘇州市公安局工業園區分局
confidence: 0.9997307658195496
text_box_position: [[233, 242], [473, 242], [473, 262], [233, 262]]
text: 有效期限

百度飛槳:https://aistudio.baidu.com/aistudio/projectdetail/507159
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552516.html
標籤:其他
下一篇:返回列表