?導讀
最近AIGC和LLM的浪潮層層迭起,大有把AI行業過去十年畫的餅,一夜之間完全變現的勢頭,而 AI Infra (構建AI所需的基礎設施),也成了討論的焦點之一,大眾對AI Infra的關注點,往往放在AI算力上——比如A100/H100的芯片封鎖;比如馬斯克又買了一萬張GPU,等等,
算力無疑是AI浪潮中至關重要的一環,然而AI Infra并不只與算力相關,冰凍三尺非一日之寒,正如GPT并不是突然的成功一樣,AI Infra行業其實也經歷了漫長的積累與迭代,筆者最近跟同事、朋友不斷地在討論AI的各種發展,每每聊到AI Infra,心里總會涌出千言萬語卻又難以言表,于是今天決定動手把想說的都寫下來,
如標題所說,整個AI的發展離不開大資料,而大資料的開端,自然是谷歌的三大件:Google File System、MapReduce和BigTable,其中GFS論文發表于2003年,距今剛好整整20年,這20年,也是大資料、AI、互聯網發展突飛猛進的20年,
本文試圖去梳理這20年間AI Infra的一個個里程碑事件 ,因為當我們身處其中時,往往分不清炒作與干貨,也看不清區域領先和最終取勝的架構之爭,只有當回顧歷史,觀察長周期的變革時,一些規律才會涌現,話不多說,讓我們就此開始!
目錄索引
【2003/2004年】【框架】:Google File System & MapReduce
【2005年】【資料】:Amazon Mechanical Turk
【2007年】【算力】:CUDA 1.0
【2012/2014年】【研發工具】:Conda/Jupyter
【小結】
【2012年】【框架】:Spark
【2013/2015/2016年】【框架】:Caffe/Tensorflow/Pytorch
【2014年】【框架/算力/研發工具】:Parameter Server & Production Level Deep learning
【2017年】【算力】:TVM/XLA
【2020年】【資料/算力】:Tesla FSD
【2022年】【資料】:Unreal Engine 5.0
【2022年】【資料/研發工具】:HuggingFace融資1億美元
【當下】OpenAI有什么AI Infra?
【結語】
【2003/2004年】【框架】:Google File System & MapReduce
2003年谷歌發布的GFS論文,可謂是掀開了這場20年大戲的序幕,宣告人類社會正式進入互聯網大資料的時代,一個小插曲是谷歌雖然開放了論文,卻沒有開源實作,導致后來的Apache Hadoop以「一言難盡」的性能占領了開源生態(也為Spark日后橫空出世埋下伏筆),而開源社區爆發式的發展想必也影響了后來谷歌對開源系統的態度,
GFS和MapReduce可以說是開啟了分布式計算的時代,同時也在傳統單機作業系統、編譯器、資料庫這些領域之外,讓「 Infrastructure 」這個詞開始逐步深入人心,關于GFS這里不多說,重點想討論下 MapReduce的「問題和缺點」 ,不知道有沒有人在第一次學習MapReduce編程模式后,也跟筆者一樣在心里犯嘀咕:這個Map和Reduce是有什么特殊之處嘛?為什么是它們而不是別的介面?為啥一定要用這個范式編程呢?是倒排索引必須用MR才能建么?種種疑問即便是后來通讀了Paper也未能完全理解,
而且后來發現,吐槽的還不止筆者一個,2008年,當時還沒獲得圖靈獎的資料庫大牛Michael Stonebraker 就撰文狠批《MapReduce: A major step backwards》,還直接點名批評西海岸某學校:“Berkeley has gone so far as to plan on teaching their freshman how to program using the MapReduce framework.” ,而Stonebraker教授主要抨擊的點,便是MR缺失了傳統資料庫的一大堆Feature,尤其是Schema & 高階SQL語言、Indexing查詢加速等等,咱阿里的同學看到這想必心里樂了:“嘿嘿,您老說的這些Feature,咱MaxCompute的湖倉一體/SQL查詢/自動加速,現在全都有啦!MR也可以棒棒滴”,
不過這已經是現代了,讓我們先回到2004年,看看為什么在沒有日后這些高級Feature的情況下,谷歌依然要推出MapReduce并定義了整個開源大資料生態的模式,這里想說是:「 了解成功架構的缺點,才能真正理解其優點到底帶來多大的收益,以至于可以抹殺掉所有的不足 」,MapReduce并不見得是一個好的編程范式(后來的發展也證明有各種更好的范式),它讓演算法實作變得復雜&教條,它只能實作很少一部分演算法,它的性能可能比原問題的最優實作差之甚遠,但是它在2004年的時候,讓普通程式員使用大規模分布式計算變得非常簡單!不需要了解Mpi,不需要了解分布式通信同步原理,寫完Mapper和Reducer,你就能在上千臺服務器的集群上運行程式,關鍵是還不用擔心出現機器故障等等各種例外問題,
歸根結底,MapReduce是一個妥協
MR犧牲了靈活性,犧牲了性能,卻讓用戶獲得了穩定可靠的分布式計算能力,而各種各樣的「妥協」,在后面一代代的AI Infra中,已然就是主旋律,不過我們也能驚喜地看到,隨著現代工程技術的發展,在靈活性、性能、穩定性三個維度均得高分的系統比比皆是,當然,新的妥協點依舊會存在,這也是AI Infra或者說Large-Scale Computer System這個領域令人著迷的原因之一,
關于GFS和MR要說的還有最后一點,那便是「 面向Workload的設計 」,谷歌在論文里也說了,整個大資料系統的設計與他們的搜索引擎業務息息相關:檔案系統只會Append寫而不會洗掉,讀取主要是順序讀而不是隨機讀,需要MR的任務也以掃庫建索引為主,而傳統資料庫、檔案系統對于其他通用需求的支持,必然也導致它們在大資料處理這個任務下,不會是最優解,
好了,讀到這有讀者可能會問,光一個20年前的GFS你就講這么多,我關心的GPT在哪里?怎么才能造出GPT?別急,太陽底下無新事,20年前對框架的設計思考,與最新的AI Infra相比未必有什么本質不同,
【2005年】【資料】:Amazon Mechanical Turk
時間來到2005,讓我們從系統領域抽出來,看看AMT給世界帶來了什么樣的驚喜,其實Web1.0剛開始的時候,也是互聯網泡沫期嘛,可能跟咱們現在的感覺也差不多,整個社會在一個癲狂的狀態,也不知道是誰在亞馬遜突發奇想,基于互聯網搞了這么個眾包平臺,但這可樂壞了在學校研究所里依靠學生、人工招募物件來標注資料的老師們,于是乎,Stanford的Fei-Fei Li團隊,開始基于AMT來標注了CV有史以來最大的一個Image Classification資料集:ImageNet,并從2010年開始舉辦比賽,最終在2012年AlexNet技驚四座,引發了第一次深度學習革命,
關于AMT和ImageNet這里想說3個點:
1.事后看關于「資料」方面的歷次革命,特點就很明顯了,每一次要么是極大地降低了獲取資料標注的成本,要么是極大地提高了資料的規模量,正是AMT或者說互聯網,讓人類第一次可以很方便地,為了研究AI而大規模地獲取標注資料,而到了2023年的LLM,大家對這個問題其實也想得很清楚了:『 原來根本不用什么眾包平臺,每個在互聯網上說過話的人,以及之前寫過書的古人,其實都是在幫AI標資料 』,
2.很多同學不知道為什么ImageNet有個Net,或者以為ImageNet的Net和AlexNet的Net一樣都指神經網路,其實根本不是,這里可以參考ImageNet的原始論文,主要是因為之前有另一個專案WordNet,是類似知識圖譜或者大詞典的一個作業,將各種范疇和概念都進行了記錄和網狀關聯,ImageNet在WordNet的基礎上,選擇性地構造了1000類物體類別,對視覺分類任務進行了設計,從現代來看,這叫圖文多模態,但其實這是很早就有的一個范式:「 借用NLP的Taxonomy,對CV的分類任務進行定義 」,
3.Fei-Fei Li有很多非常有意思的CV論文,Citation量一般都不高,因為其切入點經常與眾不同,另外Fei-Fei Li的高徒Andrej Karpathy想必大家都非常熟悉,雖然AK的論文大家倒是不一定記得(甚至不知道他也在ImageNet的author list里),但AK的博客和Github卻是有極高的影響力,從最早的《Hacker's guide to Neural Networks》到最近的nanoGPT,而且AK的博士論文題目就是:《Connecting Images and Natural Language》
【2007年】【算力】:CUDA 1.0
2007年,當游戲玩家們還在糾結買啥顯卡能跑孤島危機時,NVIDIA悄然發布了第一代CUDA,之所以用悄然一詞,是因為估計當時沒激起什么水花,因為幾年后筆者聽到做影像處理的師兄對CUDA的評價無一例外都是:「 真難用 」,是啊,畢竟已經被編譯器和高級語言慣壞了這么多年了,突然跟你說寫個程式還得思考GPU硬體是怎么運行的,還得手動管理高速快取,稍微一不注意程式反而會變得死慢死慢,誰能喜歡得起來呢?而且更要命的是CUDA的浮點數精度問題,當年筆者第一次用CUDA,興沖沖寫完一個矩陣乘法后,一對比發現,咦?怎么結果差這么多,難道哪里寫錯了?排查半天無果,畢竟「 用CPU的時候,結果有錯從來都是我的錯不會是硬體的錯 」,后來經同學指點,原來是CUDA的浮點數精度不夠,需要用上Kahan Summation.就是下面這段代碼:
float kahanSum(vector<float> nums) { float sum = 0.0f; float c = 0.0f; for (auto num : nums) { float y = num - c; float t = sum + y; c = (t - sum) - y; sum = t; } return sum; }
![]()
加上后結果就神奇地對了,而如今每天用著V100/A100,然后吐槽NPU/PPU這不好那不能適配的同學可能未必知道,當年CUDA剛推廣的時候,也好不到哪里去,尤其在高性能計算領域,由于大客戶都是各種跑偏微分方程的科研機構,常年使用科學家們寫的上古Fortran代碼,而硬體上從來都是CPU雙精度浮點數保平安,所以相當長一段時間,CUDA壓根不在考慮范圍內,Intel在高性能領域也成為絕對的霸主,
另外,在此還要介紹一位曾經被Intel寄予厚望的主角: Xeon Phi, Xeon Phi芯片最早發布于2010年,就是為了對抗CUDA而研發的眾核架構,筆者在13年參加ASC超算比賽時,當年Intel免費贊助了一大批Phi并直接出了一道題讓大家試用Phi,大家用完的體感嘛......方便是真方便,畢竟主打的是編譯器包辦所有事情,原有的高性能分布式代碼一行不用改,直接適配眾核架構,這也是Intel一直以來做CISC架構CPU和編譯器的思路:「 底層實作復雜的指令集,編譯器完成所有轉譯和優化 」,上層用戶完全無感,每年付費即可享受摩爾定律的紅利(值得一提的是,Intel的Icc高性能編譯器和MKL庫都是要額外付費的),可惜的是,Phi的目標和愿景雖然很美好,但它的編譯器和眾核架構沒有做到標稱所說的,一鍵切換后,性能得到極大提升,Phi專案始終沒有積累大量用戶,也在2020最終關停,
另一方面,CUDA卻取得了節節勝利:人們發現,寫SIMD模式的高性能應用時,CUDA其實比CPU更好用,原因恰恰是「 編譯器做得少 」,寫CUDA時,所寫即所得,不用再像寫CPU高性能應用那樣,時常需要編譯出匯編碼去檢查向量化有沒有生效、回圈展開對不對,由于無法對CPU Cache進行直接管理,更是只能靠經驗和實測來了解當前Cache的分配情況,這里也引出一個問題:「 編譯器和語言設計一定要滿足所有人的需求么? 」想必不是的,找準這個語言的真正用戶(高性能工程師)可能才是關鍵,
而與本文最相關的是,CUDA找到了AI這樣一個神奇的客戶,說它神奇,因為AI演算法真的要讓《數值分析》的老師拍案叫絕,讓《凸優化》老師吐血,為什么呢?這么大規模的一個數值計算應用,居然說「 精度不重要 」,而且「 全是CUDA最擅長的基本矩陣運算 」,機器學習不需要雙精度,直接單精度浮點數搞定,甚至在推理時連單精度都嫌多,半精度、int8、int4都能用,而在優化角度,也是打破了凸優化的所有傳統認知:一個非凸優化問題,傳統各種演算法通通不需要,而且搞全量資料優化反而效果不好,SGD的mini-batch雖然會自帶噪音,但噪音反而對訓練有益,于是乎,GPU另一個軟肋:顯存受限,在mini-batch的演算法下,也變得不是問題了,
總之,CUDA和GPU似乎就是為AI而生,缺點最終全變成了Feature,也讓老黃變成了廚房霸主,核彈之王,而目前集舉國之力攻堅自研芯片的我們也不要忘了,CUDA發布這16年以來,除了底層的芯片之外,軟體層工具鏈和用戶習慣用戶生態是怎樣從0到1一步步演進的,GPU未來是不是一定就一家獨大?TPU/NPU/PPU會不會彎道超車?讓我們靜觀其變,
【2012/2014年】【研發工具】:Conda/Jupyter
聊完了框架、資料和算力,我們再來看看AI的研發工具是什么情況,而這里不得不討論的問題便是:為什么AI的主流語言是Python?其實,不只是AI,Python的普及率本來就在逐年上升,開源社區很早就發現為一個專案提供Python介面后,用戶使用量會大增,而且大家更傾向于使用Python介面,究其原因,無需編譯的動態腳本語言的魅力實在是太大了,在這里無需多言,畢竟大家都知道:
人生苦短,我用Python
而Python的生態本身也在不斷的完善,基于Pip的包管理本來就很方便,2012年推出Conda之后,更是讓「 虛擬環境管理 」變得極為容易,要知道,對于一個頻繁需要復用開源軟體包的開發領域,這絕對是一個Killer Feature,
除了包管理,Python的另一大突破便是基于IPython的Jupyter ,它把Python本來就好用的互動功能提升到了新的標桿,并且打造了大家喜聞樂見的Jupyter Notebook,至于說Notebook算不算AI Infra,看看谷歌的Colab,看看目前各種AI開源專案的導引教程、以及咱們自己的PAI-DSW就能知道,Notebook已經是AI研發和知識分享中不可或缺的一環,其隔離后端集群的Web端的研發體驗,讓用戶一站式操控海量算力資源,再也不用只能用Vim或是遠程同步代碼了,
而對于筆者來說,寫Data相關Python實驗代碼的第一選擇也早已不是IDE,而是Jupyter Notebook.原因很簡單:處理影像、Dataframe、Json這樣的資料,并且需要頻繁「 迭代不同的演算法策略 」時,「 代碼怎么寫取決于其內在資料格式和前面的演算法結果 」,而資料和演算法結果都是在運行時才能看到其具體形式,所以,「 一邊運行代碼一邊寫代碼 」是資料處理、AI演算法工程師的家常便飯,很多不理解這一點的Infra工程師,設計出來的框架或者工具,難免讓人一言難盡,后面我們也會看到,在互動性和動態性上開倒車的Tensorflow,用戶也在一點點的流失,
【小結】
通過前面這4個板塊代表性作業的介紹,我們不難看到AI Infra全貌的雛形:
-
算力 :需要強大的CPU/GPU為各種數值計算任務提供算力支持,同時編譯器需要為高性能工程師提供良好的編程介面,
-
框架 :針對特定的Workload抽象出一個既有通用性,又滿足一定約束的編程范式,使得執行引擎可以一站式提供諸如分布式計算、容災容錯、以及各種運維監控的能力,
-
研發工具 :AI和資料演算法研發期望在代碼撰寫時是能實時互動反饋的;開源社區要求代碼和其他生產資料能夠被很容易地打包、發布、集成、以及版本管理,
-
資料 :需要一個提供AI訓練所需海量資料的工具或模式,
帶著這些思路,其實就很容易能看清后來AI Infra發展的基本脈絡了,讓我們繼續來看看,
【2012年】【框架】:Spark
還是2012年,這一年Berkeley的Matei Zaharia發表了著名的Resilient Distributed Datasets 論文,并且開源了Spark框架,Spark徹底改變了Hadoop生態「慢」和「難用」的問題,借助Scala和Pyspark/Spark SQL的普及,將很多編程語言領域的最新進展引入了大資料開源社區,其實目前來看,RDD是不是In Memory可能都不是最重要的,畢竟大部分Job并不是Iterative的,但是,光是借助Scala interactive shell實作的Spark shell,對于動輒啟動任務就要分鐘級別的Hadoop,本身就是顛覆性的(想想你告訴一個天天寫Java based MR介面的同學,你現在可以在Python命令列里搞大資料計算了是什么感受),更別提Scala的各種語法糖,以及對海量算子的支持了,
總而言之: Spark 用Scala、Python、SQL語言的極好互動式體驗對笨重的Java實作了降維打擊,并提供了更優的系統性能, 而人們也看到,只要「 用戶體驗 」足夠好,即便是一個成熟的開源生態也是可以被顛覆的,開源大資料生態也因此進入了百花齊放的階段,
【2013/2015/2016年】【框架】:Caffe/Tensorflow/Pytorch
2013年,最接近大眾認為的AI Infra作業來啦,那就是賈揚清大牛開源的Caffe,自此Deep Learning的門檻被大大降低,通過模型組態檔,就能搭建網路,完成訓練,利用GPU的算力,一時間模型創新開啟了大爆發時代,其實同一時期開源框架還有Theano,以及基于Lua的Torch,不過使用方式各有差異,隨后,大公司紛紛入局,谷歌和FB分別在15和16年發布了Tensorflow和PyTorch,再加上日后Amazon背書的MxNet,以及百度的PaddlePaddle,機器學習框架迎來了百家爭鳴的時代,關于機器學習框架可以討論的點太多了,公開的資料也很多,這里只討論其中的兩個點:
一個是從框架設計方面的「 Symbolic vs. Imperative 」,這個討論最早可以追溯到MxNet的技術博客 Deep Learning Programming Paradigm ,而MxNet也是最早兩種模式均支持的框架,并在博客里點明了:Imperative更靈活易用,Symbolic性能更好,再看看其他框架早期的版本,則專一到其中一種范式:Tensorflow是Symbolic,PyTorch是Imperative,而后面的事情大家也都知道了,Pytorch完整繼承了Python語言的優點,一向以靈活、適合科研使用著稱;TF則在工程化部署時更友好,但犧牲了互動性,而后經過漫長的迭代,兩種范式也基本走向了融合,TF也支持Eager模式,后面還直接推出了新框架Jax;Pytorch也可以把Symbolic Graph進行匯出和操作,比如TorchScript、Torch.fx,如同MapReduce是一種妥協,各個機器學習框架也都在「 易用性 」和「 性能 」上做著某種妥協,但整體看,主打Imperative,保持與Python使用習慣吻合的Pytorch還是在用戶量上逐漸占據上峰,當然,現在下任何結論都還為時尚早,機器學習框架的發展和迭代遠沒有結束,
另一個可討論的點是「 機器學習框架演進和演算法演進 」之間的關系,之所以要討論這個點,是因為很多演算法研發團隊和工程框架團隊習慣于甲方乙方的作業模式,把框架研發和框架升級理解為:演算法科學家為了實作某個模型或者想法,發現現有框架無法支持,于是給工程團隊提一些關于算子Op實作、新的分布式計算范式、性能優化方面的新需求,這樣的模式有很多弊端,比如只能支持區域的小創新,而且創新的周期可能會很長,甚至會出現經常被工程團隊吐槽的:「 上一個需求還沒實作完,演算法側又換了新想法 」,所以如何打磨好演算法團隊和工程團隊的協作模式,是很重要的課題:比如 Co-Design 的方法論,雙方都要換位思考,提前預判技術路徑,比如工程團隊不能把日常作業變成幫科學家實作功能代碼,而是要提供一個靈活的上層介面讓科學家自行探索,框架層重點解決卡脖子的工程技術問題,而且最重要的是:雙方一定要意識到:「 目前的模型結構和框架實作,可能只是歷史演講程序中的一個偶然 」,而「 模型設計和框架實作,會不斷地互相影響著對方的演進路線 」
?
原因也很簡單,在模型創新最前沿,有一個雞生蛋蛋生雞的問題:演算法科學家只能實作并驗證那些現有框架能實作的Idea,而框架支持的功能,往往又都是以往成功過的演算法架構或是科學家提出了明確需求的架構,那么 真正的系統級創新如何發生呢 ?可能還真回到了阿里的老話:
因為相信,所以看見
此外,演算法與框架的共生關系,近年來也引發了大量的討論,比如最近討論比較多的,LLM為什么是Decoder Only架構?還有《The Hardware Lottery》一文里提出的 “ A research idea wins because it is suited to the available software and hardware ”,
總而言之,對于機器學習框架而言,「框架」的意義早已超出了MapReduce/Spark這種大資料框架幫助工程師實作各種Data ETL功能的范疇,因為演算法、模型的形態本身就是在變化在革新的,框架如果限制過死,就反而會制約演算法的迭代和創新,
【2014年】【框架/算力/研發工具】:Parameter Server & Production Level Deep Learning
開源社區的框架引發了AI的新浪潮,而在互聯網大廠的搜推廣業務里,大家也開始琢磨,Deep Learning的成功是否能在傳統Ctr演算法中復現呢?答案是肯定的!基本上所有大廠都開始了相關的研發,這里打個廣告,以筆者熟悉的阿里媽媽展示廣告業務線為例,從2013年的 MLR ,再到后來的大規模分布式訓練框架 XDL ,再到 DIN 和 STAR ,搜推廣的同學們應該都非常了解了,開源框架不支持大規模Embedding Table和靠譜的分布式訓練,這也讓自研的類Parameter Server框架迎來了發展空間,大規模分布式訓練的框架也成為了這幾年搜推廣演算法迭代的主要推手,而與上文說的一樣,在模型高頻迭代,大促提效常態化的背景下,演算法創新和框架演進是一個復雜的共生關系,這里也推薦大家看看懷人老師寫的 廣告推薦技術發展周期 ,完整描述了整個演算法架構的演進歷程,
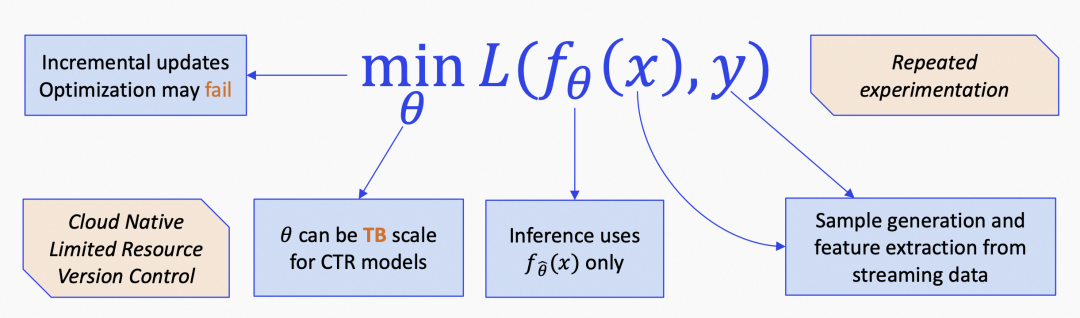
另一方面,訓練引擎僅僅只是整個搜推廣演算法工程化的冰山一角,模型推理引擎,實時資料流,ABTest實驗平臺,容器調度平臺等等都需要一整套完整的Infrastrature,這里寫得最詳細的當然是五福老師的 AI OS綜述 ,筆者也在下圖大致梳理了在工業級機器學習應用中,面臨的一些常見問題,
 ?
?
在這里不得不說,搜推廣的Ctr模型,由于與互聯網業務、營收高度相關,一直是大廠里的技術高地,經過無數人榷訓月累的不斷打磨,可以說是把 y = f(x) 這個學習范式的每個細節都做到了極致,上圖的每個小框都值得10+篇技術分享,而在GPT時代LLM、半監督學習范式以及未來前景廣闊的AI應用中,阿里在這一塊的積累一定可以得到遷移和復用,繼續發光發熱,
【2017年】【算力】:TVM/XLA
時間到了2017年,TVM和XLA都在這一年發布,而AI編譯器這個話題也值得我們單獨討論一下,與機器學習框架主要解決易用性問題不同,AI編譯器重點解決的是性能優化、計算芯片最優適配的問題,一般通過對單算子的底層計算代碼生成,或是對計算圖的重組和融合,來提升模型推理的性能,在芯片斷供、自研芯片百花齊放的當下,AI編譯器也成了目前AI Infra發展最為迅猛的領域之一,阿里PAI團隊的楊軍老師也寫過關于AI編譯器的綜述,
既然是編譯器,則又會出現我們前文所說的,編譯器用戶是誰以及介面約定的問題,此外還有通用編譯優化 vs. 專有編譯優化的問題,比如搜推廣業務,由于其模型結構的特殊性,往往就會自建專有編譯優化,專門總結出某些優化Pattern以支撐模型迭代帶來的海量推理算力需求,而通用的編譯優化演算法,其實很難將這些特定的Pattern抽象整合到優化規則中去,
另一方面,AI編譯器的圖優化演算法往往對普通演算法同學不太友好,原因在于很可能稍微對模型進行一些改動,就會導致原有優化規則無法命中,而無法命中的原因,往往也不會給出提示,這就又回到了前文所說的CPU高性能編譯器的問題,雖然編譯器看似很強大很通用,可以隱藏硬體細節,但 實際能寫出高性能代碼的用戶,一般還是需要對硬體的底層邏輯有充分的了解 ,并且了解編譯器的實作邏輯以進行檢查和驗證,
所以AI編譯器到底是像torch.compile那樣幫助小白用戶一鍵提升性能,還是僅作為一個自動化工具,為具備底層認知的高性能模型工程師提高研發效率呢?目前來看兩者均有,比如OpenAI也在2021年發布了Triton,可以用Python的語法更加方便地進行類CUDA GPU編程,像Triton這樣的作業就是既需要程式員大致了解GPU多執行緒模型的原理,又大幅降低了入門門檻,而TVM也同樣在不斷升級,比如可以看看天奇大神寫的 《新一代深度學習編譯技術變革和展望》 ,未來的AI編譯器會如何發展,讓我們拭目以待!
【2020年】【資料/算力】:Tesla FSD
時間來到21世紀的第三個10年,此時公眾感知到的AI領域稍微會有點沉悶,因為上一波AlphaGo帶起的RL革命還沒有在實際場景中取得大量收益,L4無人駕駛也陷入瓶頸,其他AI之前畫的餅都還在紙上,搜推廣的工程架構也從3.0做到了4.0再到5.0,6.0,7.0......
正當大家還在思考,AI有什么搞頭時,這一年Andrej Karpathy帶隊的的Tesla突然放了大招,發布了純視覺架構的Full Self-Driving無人駕駛方案,還直接在隨后每年的Tesla AI Day上公布完整的技術方案:BEV感知、資料倍訓Data Engine、端上FSD芯片,云端Dojo超大規模訓練引擎等,一石激起千層浪,Tesla一下改變了行業的認知,在國內大部分自動駕駛公司的PR稿里,都能看到其影子,

?

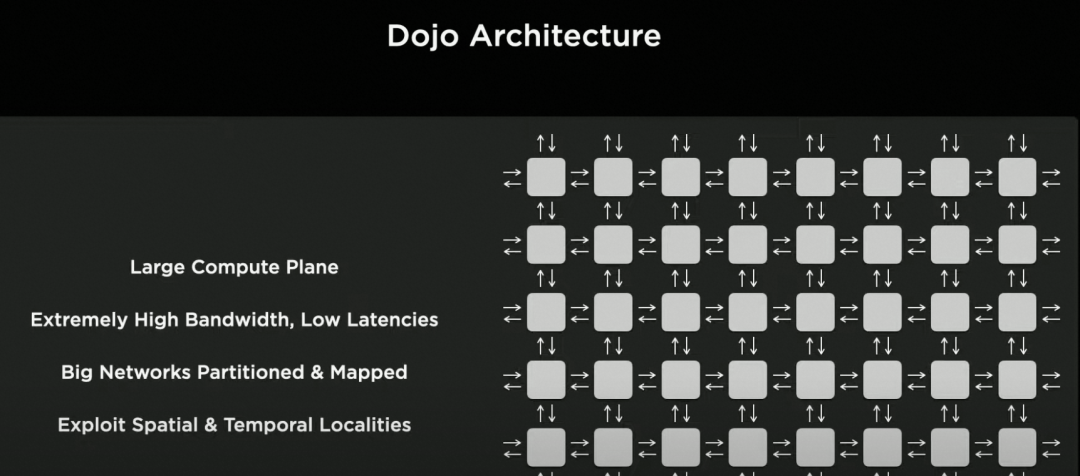
配圖來自Tesla AI day
可以說,Tesla把監督學習的工程架構又拔到了一個新高度:大規模的半自動標注引擎、大規模的主動難例資料收集、大規模的分布式訓練和模型驗證,底層的AI Infra支撐著幾十個感知規控模型的持續迭代,
【2022年】【資料】:Unreal Engine 5
時間來到2022年4月,ChatGPT還有8個月到達戰場,而這個月UE5正式發布,關注的同學想必都知道,效果那是無比的驚艷:Nanite的超大規模三角面片實時渲染,Lumen的動態全域光照,在官方DEMO《The Matrix Awakens》里我們也能看到現今實時渲染到底能做到什么水平,

配圖來自Unreal Engine官網
那UE 5是不是AI Infra呢?答案也是肯定的,首先,基于UE4的各種開源仿真渲染工具比如AirSim,CARLA早就在無人機、無人駕駛上被大規模用來生成訓練資料,而在GTA里面訓練無人車,在MuJoCo訓練小人跑步(MuJoCo已在2021年被Deepmind收購)也都不是新鮮事了,UE5如此革命性的更新,外加整個材質構建、3D模型產線的發展,也必然會讓實時渲染仿真的效果一步步逼近真實的物理世界,
恩,DeepMind + MuJoCo + UE5會不會在未來某天放大招?讓我們拭目以待,
【2022年】【資料/研發工具】:HuggingFace融資1億美元

關注AI、GPT的同學最近肯定經常看到這個笑臉,可是Hugging Face到底做了什么,為什么也能成為AI Infra的關鍵一環并在2022年成功融資一個億呢?如果你知道OpenCrawl、Pile、Bigscience、Bigcode、PubMed這些專案,那你一定也是在研究LLM訓練資料的老兄,而你會驚奇地發現,原來很多語料庫資料,都已經被整理好放在Hugging Face上了,他們還整了個Python包,名字就叫Datasets!
不知不覺中,Hugging Face已經成為了AI(至少NLP)領域的Github for Data & Model,看到這里有同學要問了,搞了這么多年AI的人臉識別、搜推廣、自動駕駛公司,從來都說資料就是最強壁壘,沒聽說過誰家會把最珍貴的資料和模型開源放到網上呀,但事情到了LLM、到了GPT這,卻發生了本質性的改觀,目前多模態大模型使用的這些資料,天然就是存在于互聯網上的,本身就是Open的,獲取比較容易(著作權問題除外),所以現在的模式變成了大家一點點地幫忙收集、整理資料,最終制作出了大量高質量的原始語料庫(比如LAION組織的創始人就是一位 高中老師 ),
其實對于LLM和AGI,未來很可能是這樣格局:資料 + 算力 + 演算法這個傳統AI三要素中,資料由于開源可能反而不是唯一壁壘了,在有芯片硬體的大廠里,最后比拼的就是演算法和基于AI Infra打造的迭代速度了!
【當下】:OpenAI有什么AI Infra?
那么,AI Infra對于打造GPT有什么幫助呢?從OpenAI被公開的 架構 來看,上文提到的方方面面基本都有涉及,而在Compute和Software-Engineering兩Topic下,也可以看到OpenAI自己發表的大量關于AI Infra的博客,其中很多是在算力-演算法Co-Design的方向,比如在2021年初,OpenAI管理的K8S集群達到了7500個節點的規模(4年前是2500節點),而后在21年7月份開源了前面提到的Trition,一個能用Python語法實作GPU高性能編程的編譯器,22年的時候也花很大的篇幅介紹了他們進行大規模分布式訓練的技巧,
不難看出,最大限度地讓演算法研發用上用好海量的算力資源,是OpenAI Infra的頭號目的,另一方面,從AI and Compute和AI and Efficiency兩篇文章中能看到,OpenAI花了不少精力在分析隨著時間的演進,最強模型所需算力的增量曲線,以及由于演算法改進而導致的算力效率變化曲線,而類似這樣的分析,也在GPT-4的 Predictable scaling 中得到了體現,也就是說,給定訓練演算法, 所消耗的算力與所能達到的智能程度是可被預測的 ,這種「 算力演算法Co-Design 」的指標就能很好地去指導演算法研發 vs. 工程架構升級的節奏和方向,
除了算力這條線,AI開源社區的進展也是日新月異,想必很多也為GPT的出現做出了貢獻,除了Hugging Face,還有很多值得稱道的AI創業公司不斷涌現,在此筆者還來不及去細細分析各家公司的作業和意義,但變革已然在不斷發生,新事物的出現速度已然是以周為單位,
【結語】
最近幾個月AI的發展速度,確實遠超筆者之前的認知,毫無疑問,AI2.0的時代已經到來,上一代基于純監督學習的范式已然不夠用,AI畫的餅大家也都吃進了嘴里,而且真香!作為AI從業者,過去幾個月也讓筆者心潮澎湃,雖然看完了本文,你還是無法做出GPT,但想必你也看到了AI Infra這20年的發展,無論未來AI演算法往哪走, 底層的算力層和底層的系統依然會是演算法研發的基石 ,
回望這20年的發展,從03年到13年這十年是Web1.0的時代,筆者還是個孩子;13~23年筆者全程目睹了AI1.0和Web2.0的發展浪潮,但更多時候也只是個吃瓜群眾,而未來的十年,自然是AI2.0和Web3.0革命性的十年,筆者完全無法想象10年后的今天,世界會是什么樣的樣子,但唯一確定的是,這一次終于可以完整參與其中,跟志同道合的小伙伴們一起做出能影響行業的事情!
話都說到這里了,不發廣告怎么行呢?我們是 高德視覺技術中心的訓練工程平臺團隊 ,負責支持資料倍訓、大規模訓練、演算法服務化等各種演算法工程化需求,我們力求在AI2.0時代打造有技術差異性的 端云協同一體AI Infra ,一方面會復用集團和阿里云大量的中間件,一方面會自建很多專用AI工具鏈,而 高德視覺,目前也成為了集團最大的視覺演算法團隊之一,支持高精地圖、車道級導航、智能出行等多種業務 ,涉及感知識別、視覺定位、三維重建和渲染等多個技術堆疊,
?轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552696.html
標籤:其他
上一篇:記錄內網Docker啟動Stable-Diffusion遇到的幾個坑
下一篇:返回列表