論文簡介
Sibylla: To Retry or Not To Retry on Deep Learning Job Failure 這篇論文發表在ATC 2022上,主題是提出了一個基于半監督學習的深度學習訓練(DLT)作業調度的系統,該系統減少了GPU集群中不必要的作業重啟操作,
背景知識
深度學習作業調度中的錯誤型別與處理機制
目前的大規模GPU訓練任務集群中存在后端分布式存盤系統專門用于存盤在整個集群中訓練期間生成的stdout和stderr日志,這些日志中記載了不同虛擬機或者容器的啟動,運行情況,
論文中將深度學習作業中發生的錯誤(failure),分類為決定性(DT failure)或非決定性(NDT failure),以此來確定后續需要針對這些錯誤的回應機制,決定性錯誤(或DT failure)是由固有的代碼語法錯誤、API誤用、錯誤配置的設定等引起的,這種錯誤一般無法正常恢復,即使重啟虛擬機或者容器鏡像也不能正常運行,與此相對,非決定性錯誤(或NDT failure)是偶然的,通常與臨時網路連接丟失或作業分配節點的瞬態問題有關,這種錯誤可能會因為重啟或者在運行而得到恢復,下圖展示了論文中認為的這些錯誤,
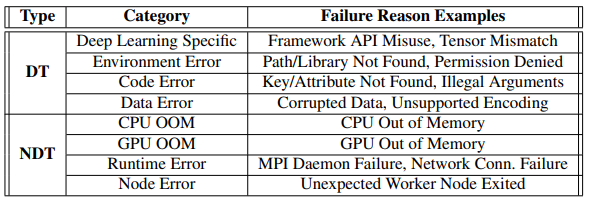
在目前Microsoft Philly深度學習訓練集群中,失敗的訓練作業會重啟(Retry)固定次數,以克服NDT failure,并在重啟后繼續或開始運行深度學習訓練作業,除了這種重啟的作業例外處理機制,企業中的NoRetry機制則會終止每一個發生錯誤的作業,以避免在DT failure中毫無價值地嘗試重新執行作業,占用固定的GPU資源,
Observation
在調度初始作業和失敗后重啟作業中,使用日志追蹤,我們可以估計作業重啟率(即經歷重啟的作業÷所有作業)以及重啟期間花費的GPU時間占所有GPU時間的比例,
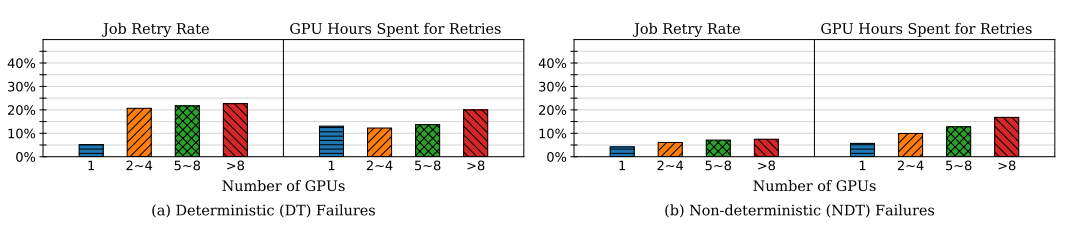
其中可以發現,深度學習訓練作業的重啟率在分布式任務上大約為20-40%,這也就說明實際集群中深度學習作業失敗率并不容忽視,除開顯而易見的結論,論文中還提到了一些重要的觀察,具體而言,使用更多GPU的作業更頻繁地重試執行,而重試期間消耗的GPU時間占作業大小的12.3-19.9%,我們記一個深度學習作業從正常運行到出現例外的時間為RTF(runtime to failure),那么對于失敗的作業,DT failure和NDT failure的中值RTF為614秒和2458秒,這也表明重啟的開銷也并不低,
如果堅持Retry策略,例如retry所有出現問題的作業固定次數,那么勢必會造成嚴重的資源浪費,但是堅持NoRetry策略是否合適呢?作者提到這樣做的訓練成功率將下降4.5%左右,其實對于那些可以通過重啟正常運行的作業而言的體驗會非常不好,
論文方法
論文提出的Sibylla是一個判定出現failure的深度學習作業是否需要重啟的系統,其設計目標是高精度、易用、易集成,前兩個都好解釋,易集成則需要簡單說明,Sibylla設計在一個獨立的agent中運行,或者在應用程式端運行(例如,Apache YARN中的application Master)以與調度器獨立互動,所以并不需要更改原集群的調度器就能將Sibylla集成入集群調度系統中,
Sibylla的思路非常簡單,將本問題建模為一個二分類問題再利用AI的方法解決,具體思路是將原本集群中的stdlog和stderr檔案作為輸入訓練一個神經網路,由神經網路的輸出判定是否需要重啟改作業,有此基礎,下面我們來看看它的具體方法,
training workflow
data preprocessing
雖然思路是將log檔案作為輸入,但實際的log檔案資訊量并不小,且大部分是與出現failure無關或不起太大作用的,而神經網路如果一次性接受整個不加處理的檔案,那么資訊提取的結果也會相當有限,如何減少資訊的輸入呢,論文的思路是選擇在出現與特定的failure相關關鍵字的行之后最多5行,Sibylla還包括關鍵字前面的一些行,因為它們可能指示導致失敗的日志子序列,這樣有效的完成了資訊提取的第一步,
但僅僅如此問題依然存在,因為log檔案是一個具備大量資訊的半結構化資料,其中很多類似用戶定義的error表達,或者特定的型別名稱,函式路徑等等都會極大得增加輸入長度的不確定性,這些資訊很多對最終判定的幫助也并不大,論文的思路是,在決議階段,每個日志行被分類到一個結構化模板中,該模板主要重新移動與判定語意無關的單詞,如非字符單詞和停止單詞,就如下圖的左側顯示的那樣:
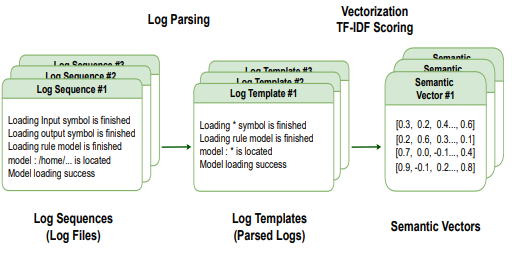
解決了輸入資訊量的問題,下面就是如何完成輸入的embedding了,Sibylla的思路是采用非深度學習方法進行embedding,這個程序如上圖右側,首先將每個單詞數字化為一個矢量,然后,它通過基于TF-IDF(術語頻率逆檔案頻率)得分對每個單詞進行加權,將模板中每行的所有單詞向量累積到單個語意向量條目中,
Model training
Embedding完成后的語意向量序列用作模型訓練的輸入,有兩種具有代表性的RNN模型參與訓練Sibylla:LSTM和基于注意力的GRU,所以模型本身比較簡單,但值得一提的是其訓練方式選擇了半監督訓練,采用投票自標注的方法進行模型訓練,Sibylla用部分標記的資料開始模型訓練,并通過在線方式自動標記未標記的資料來不斷更新模型,
Automatic sample labeling
訓練和自動標注的流程如下:
Sibylla利用了對預測結果進行投票的集成方法來決定失敗型別,從而減輕了單個模型錯誤預測的影響,總的來說就是自標注的半監督學習+集成學習的方式構成其模型訓練的整個程序,
神經網路的訓練資料則是從操作NoRetry的公司獲得了97個錯誤日志檔案,并通過手動搜索Stack Overflow收集了另外159條錯誤訊息得到的,此外這點資料很容易過擬合,所以論文還使用了兩種流行的文本資料增強方法,WordNet和Word2Vec,用于用認知同義詞替換原始日志檔案中的單詞,并創建一個新的資料增強檔案,
實驗
實驗需要提到的并不多,本篇論文的實驗純模擬,通過深度學習集群資料集the Philly trace of MS來作業調度性能,
討論
總的來說,這是一篇應用深度學習方法的典型文章,主要突出的創新點在于問題的切入點非常新,考慮了以往深度學習作業調度中基本被避開的失敗問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552979.html
標籤:其他
上一篇:AtCoder Beginner Contest 302
下一篇:返回列表