前預訓練時代的自監督學習自回歸、自編碼預訓練的前世

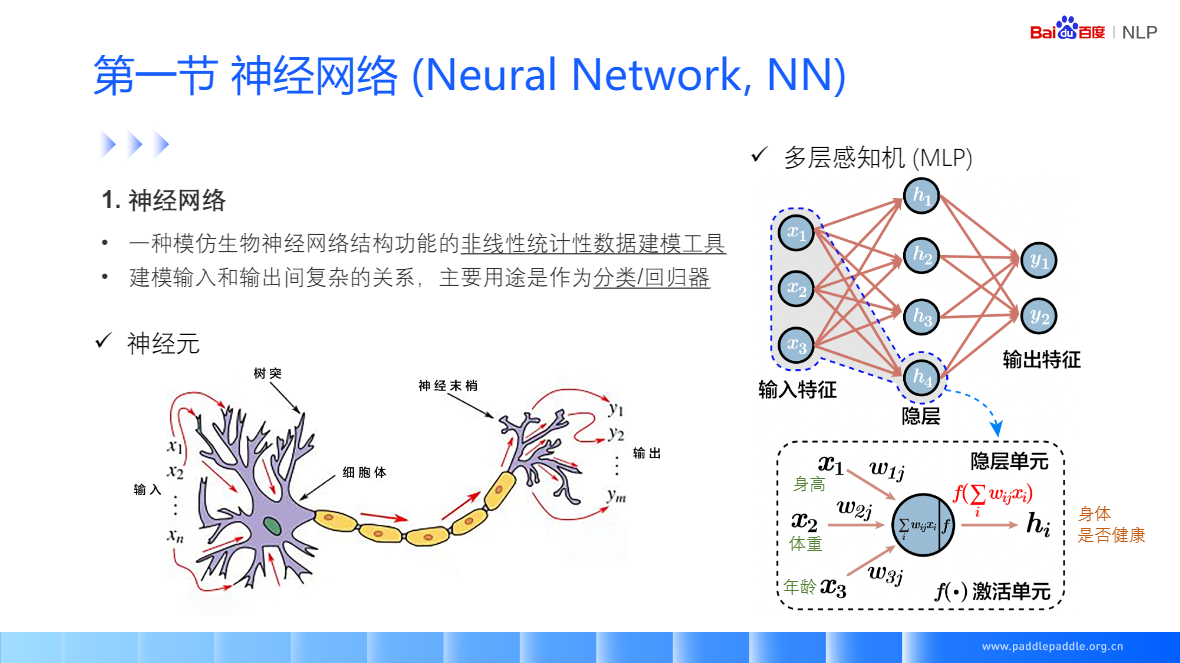
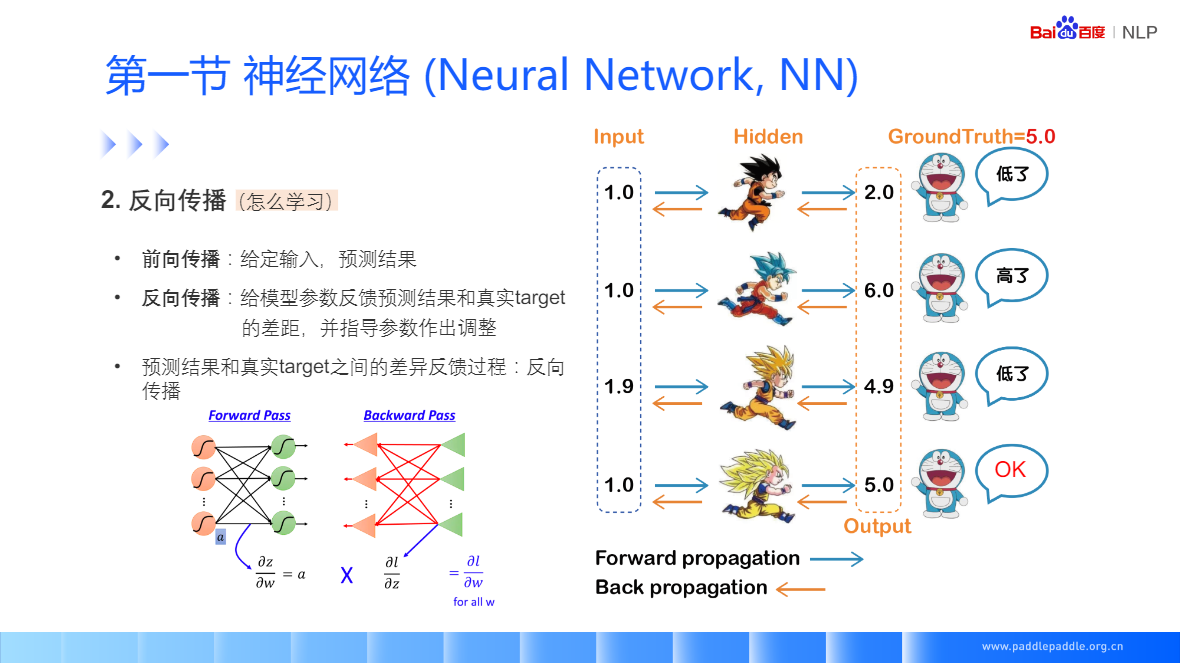
神經網路(Neural Network, NN)
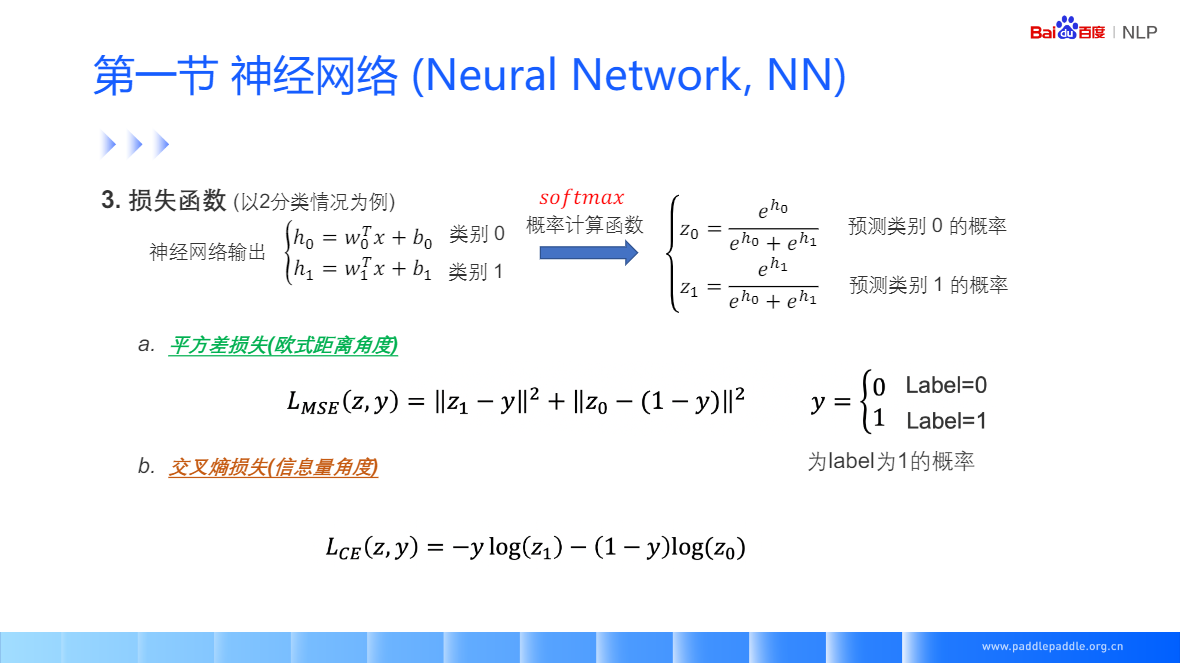
損失函式,度量神經網路的預測結果和真實結果相差多少
- 平方差損失(歐式距離角度)預測概率分部和實際標簽概率的歐式距離
- 交叉熵損失(資訊量角度)預測概率分部和真實概率分部的差異,指導神經網路學習時,更加穩定
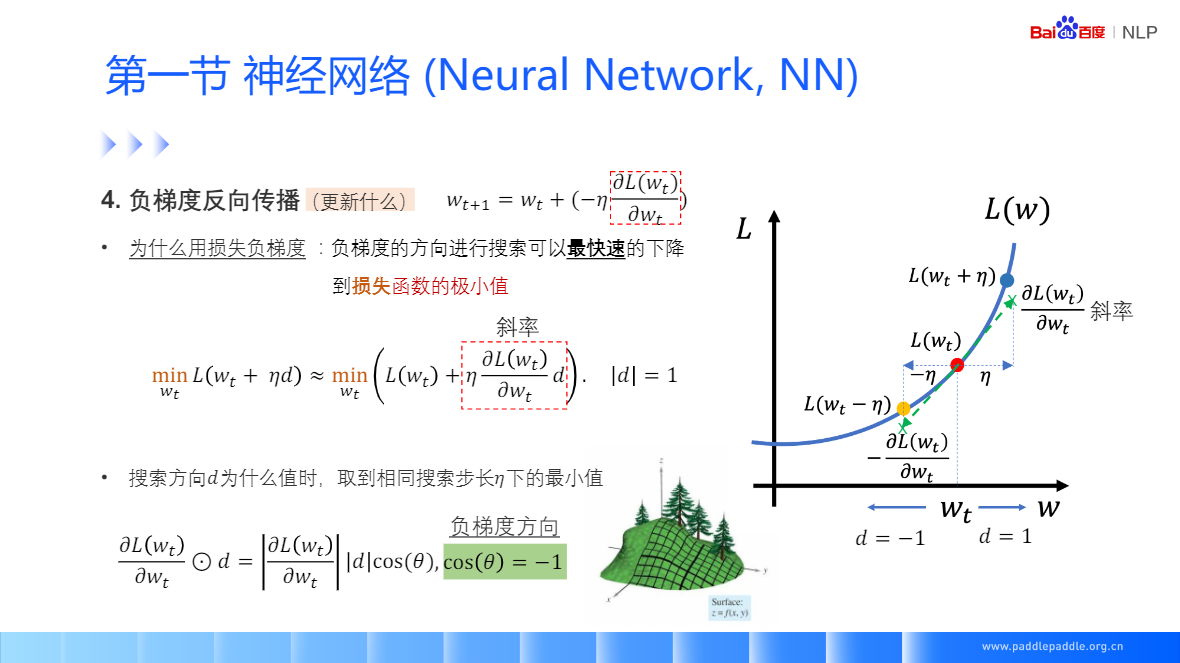
對引數W更新損失的負梯度
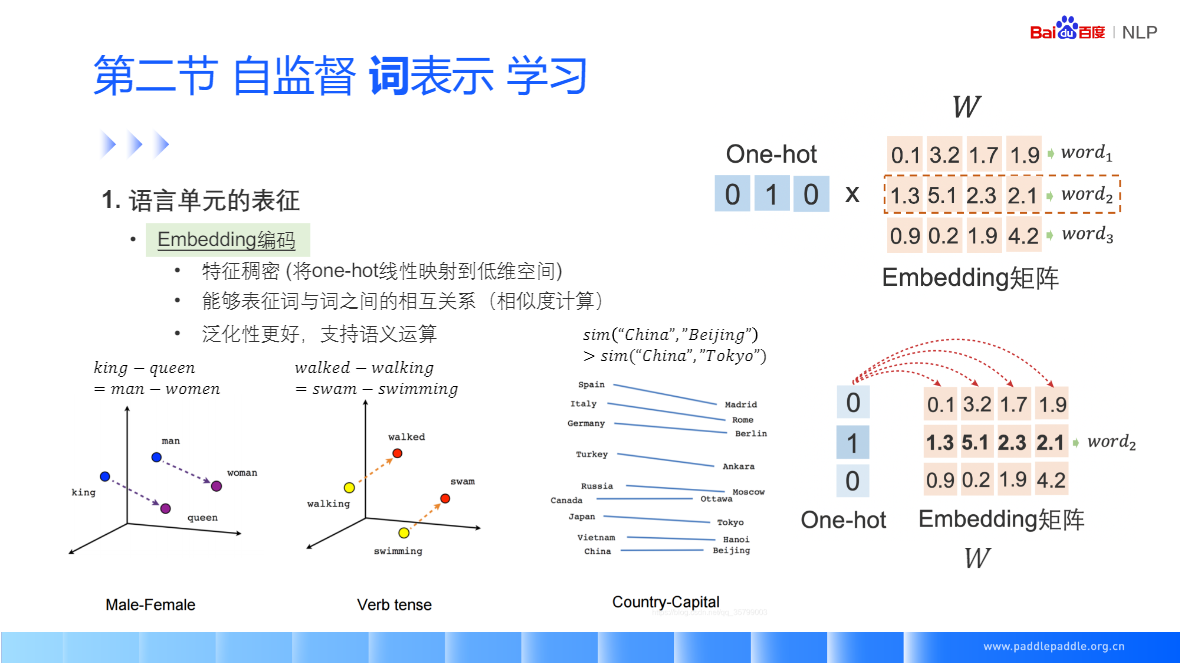
One-hot 人為規定,不需要學習,在推薦里有非常多的用處,(可以理解成完全命中)

詞向量需要學習,可以很好的泛化結果,泛化性能比 one-hot 更好(可以理解成泛化關系的建模)
評估模型的好壞:有全體指標,以及一些公開的資料集,去評估詞向量的相關性

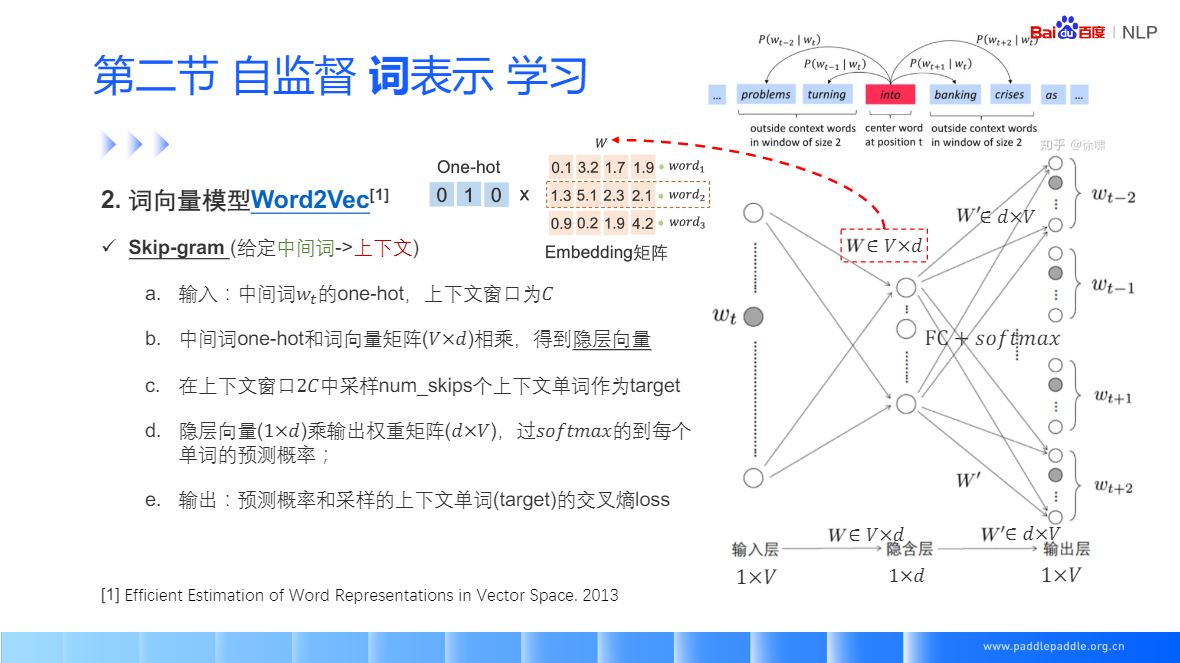
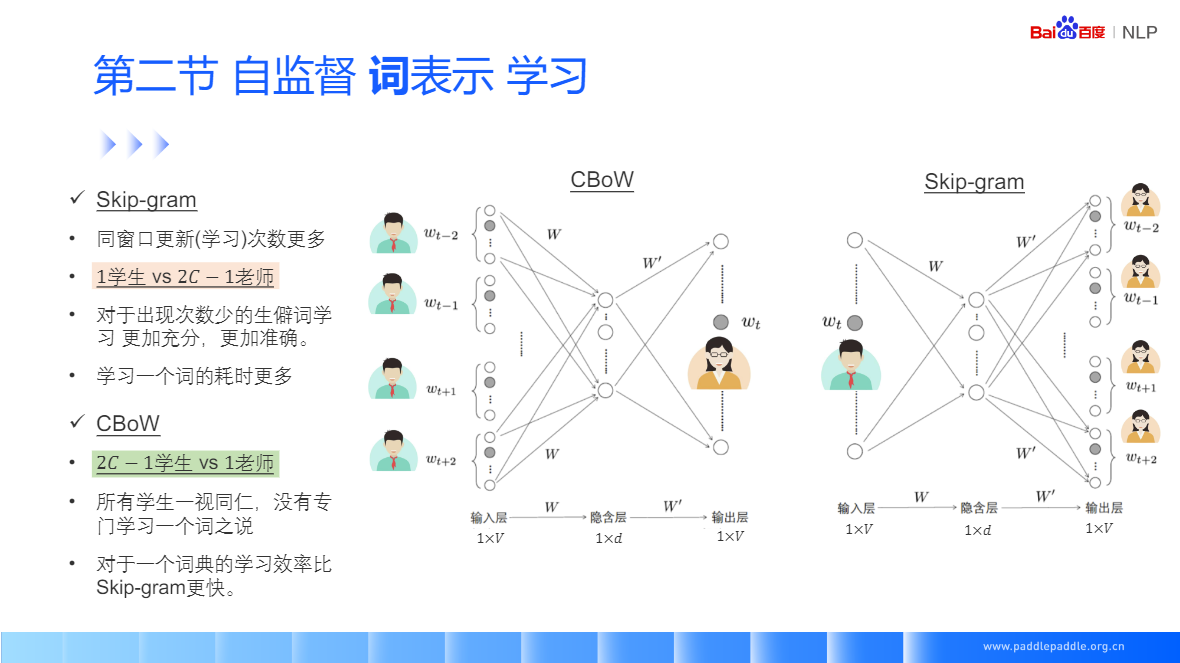
Skip-gram: 給定一個中間值,預測背景關系視窗中的一個詞

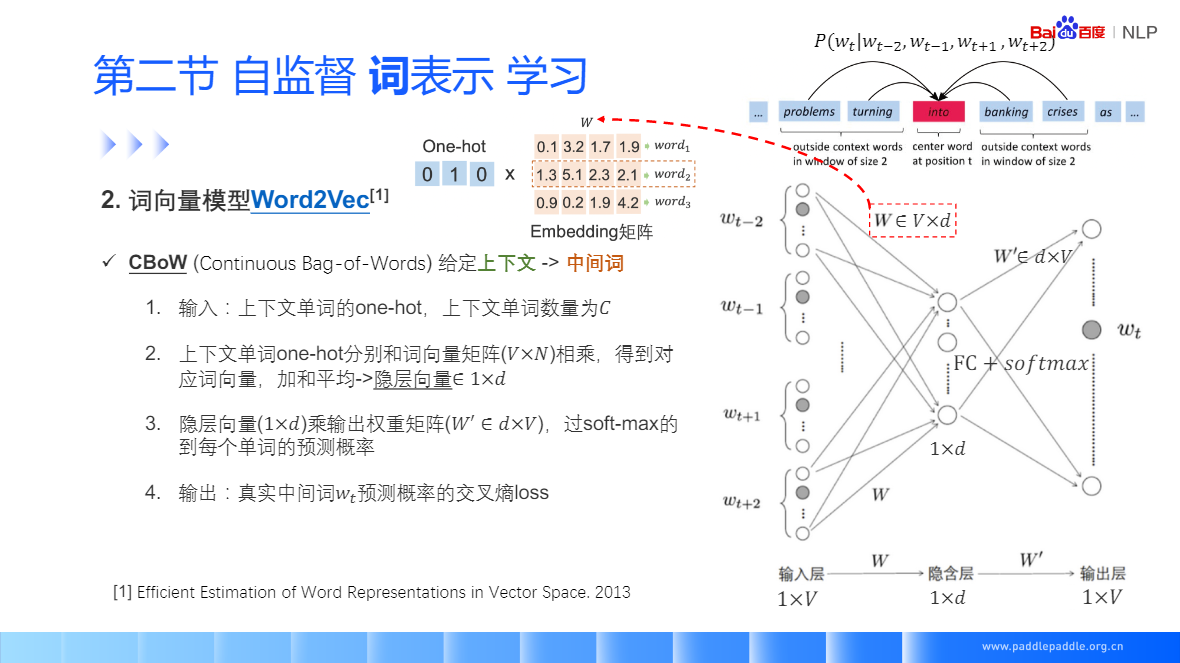
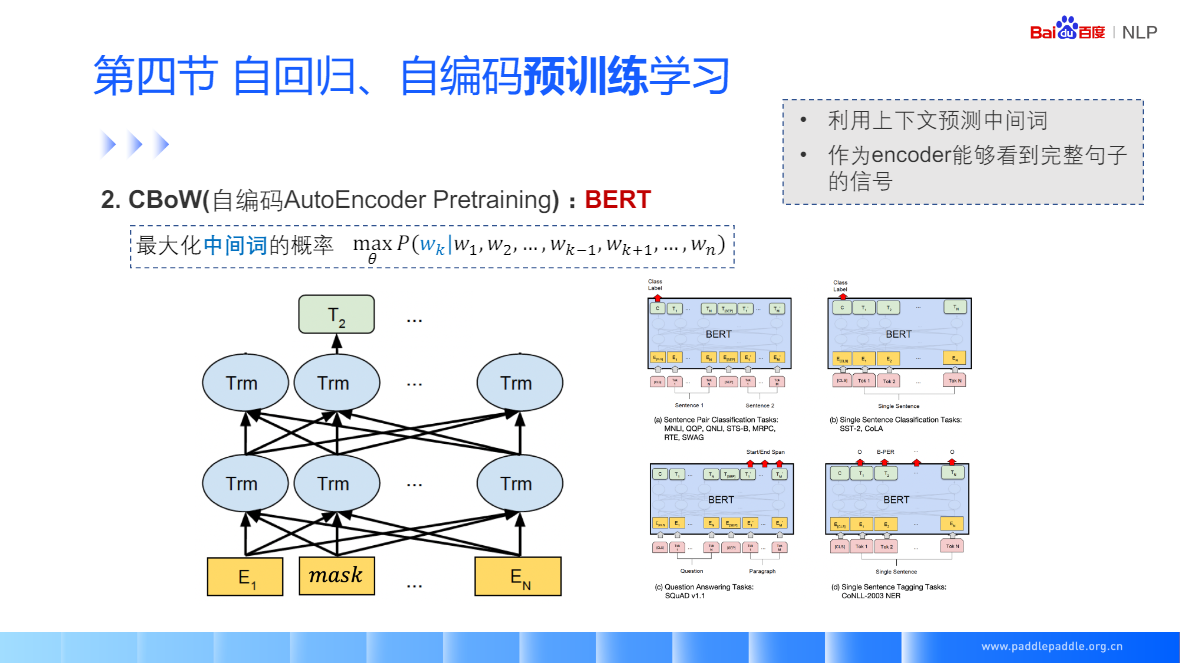
CBoW:給定一個背景關系詞,預測中間值
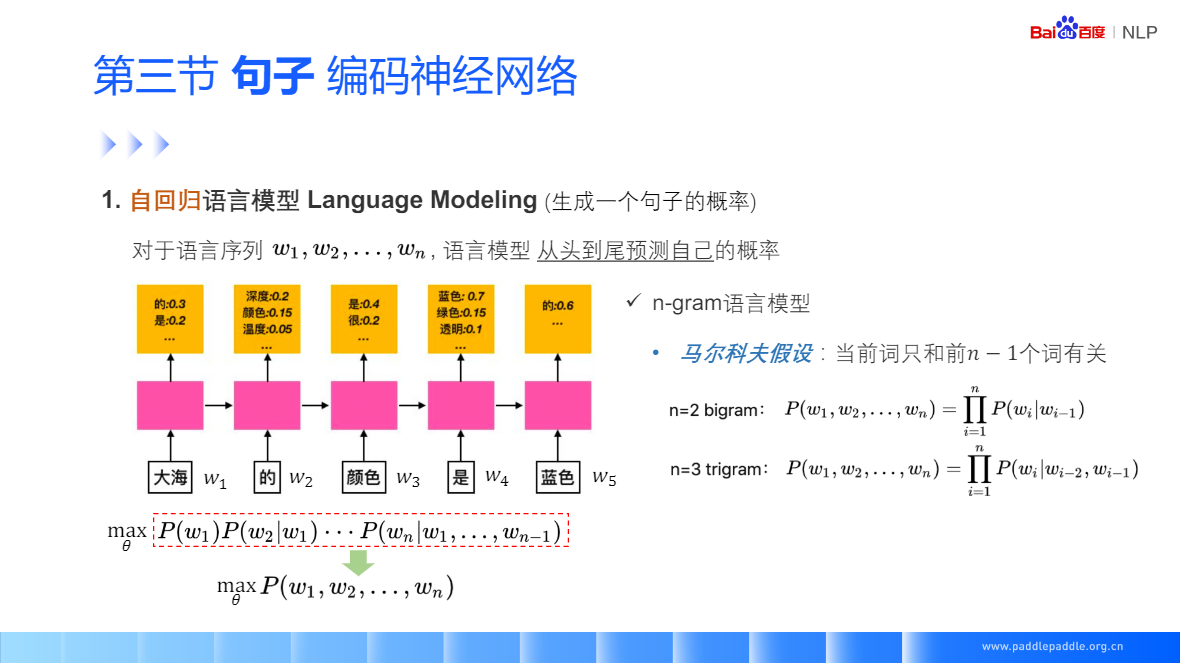
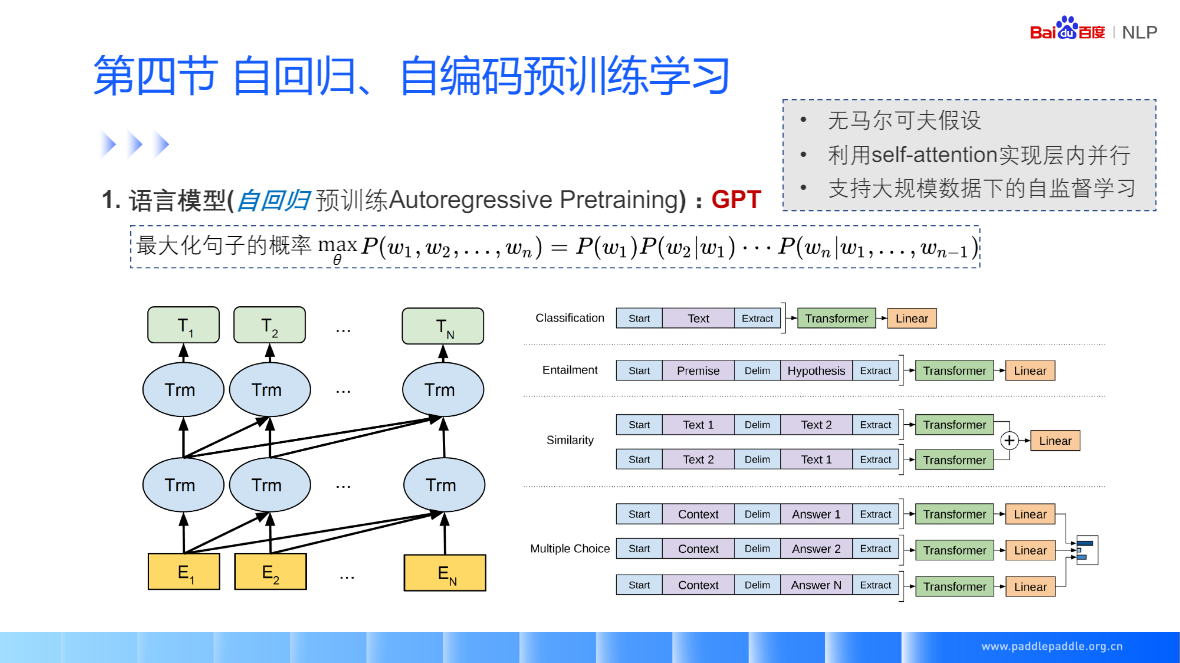
RNN 拋開馬爾科夫假設,
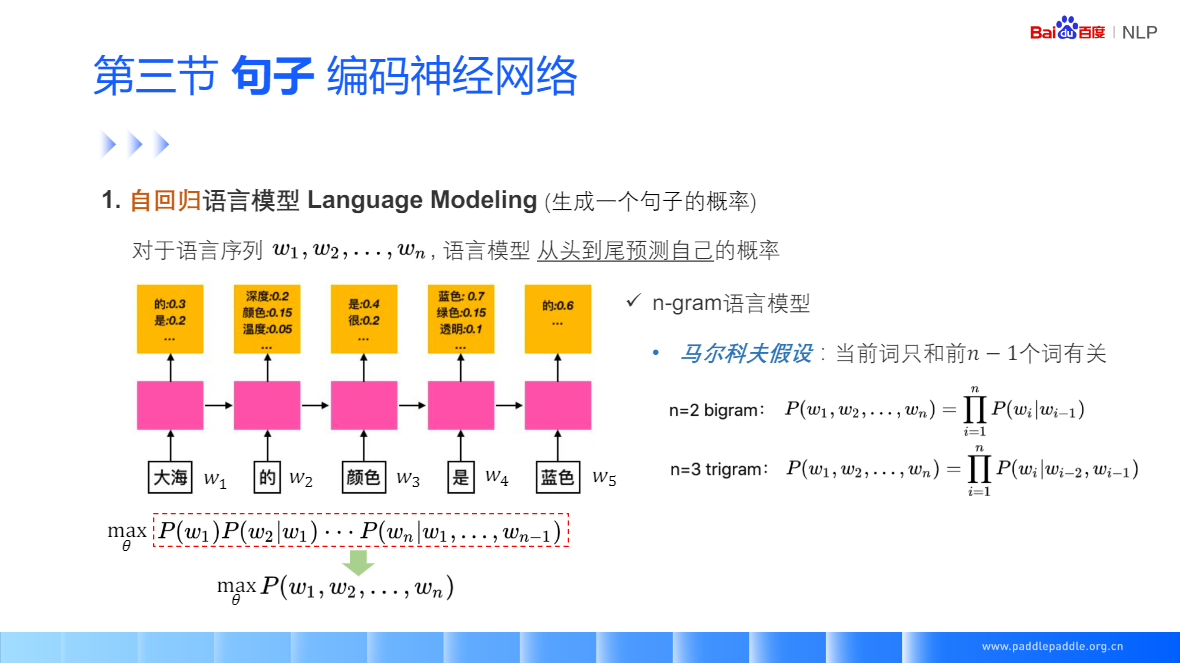
Self-Attention:每個單詞和整句所有話進行匹配,來獲取當前單詞對每個單詞的重視程度,利用這個重視程式,對整句話的每個單詞進行加權,加權的結果用于表示當前這個單詞
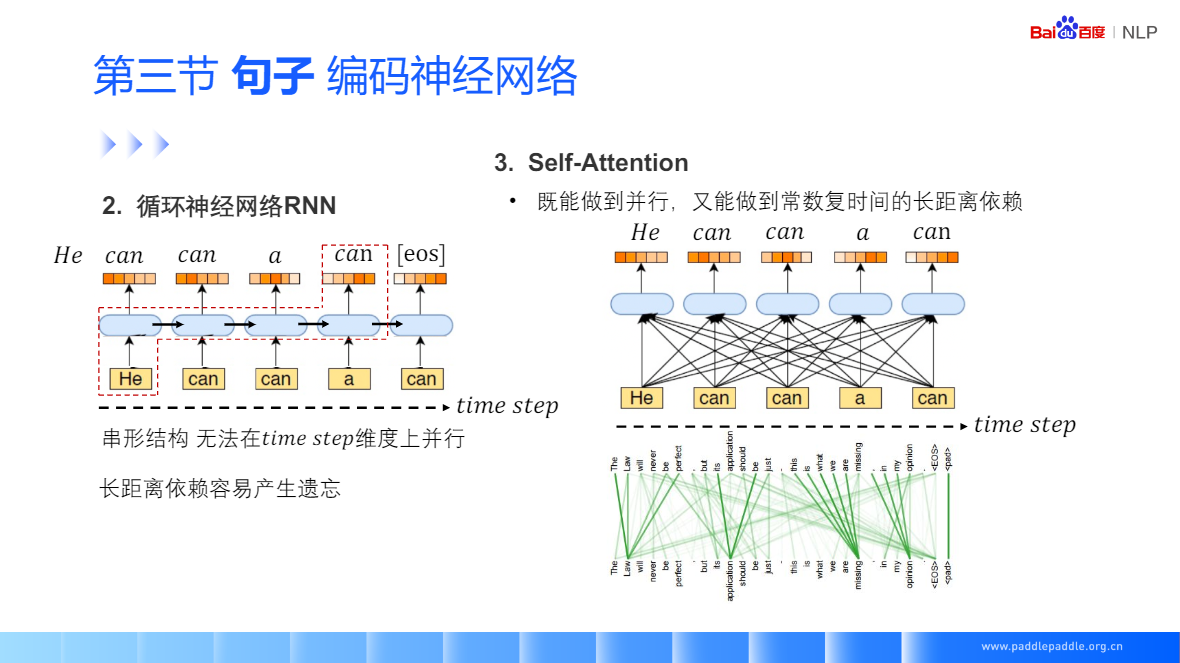
Self-Attention:也是非常流行的 Transformer 的核心模塊,
Seft-Attention 沒有考慮單詞的順序,所以為了更精裝的表示位置資訊,需要對句子的輸入加個位置的序號 Positional Embedding
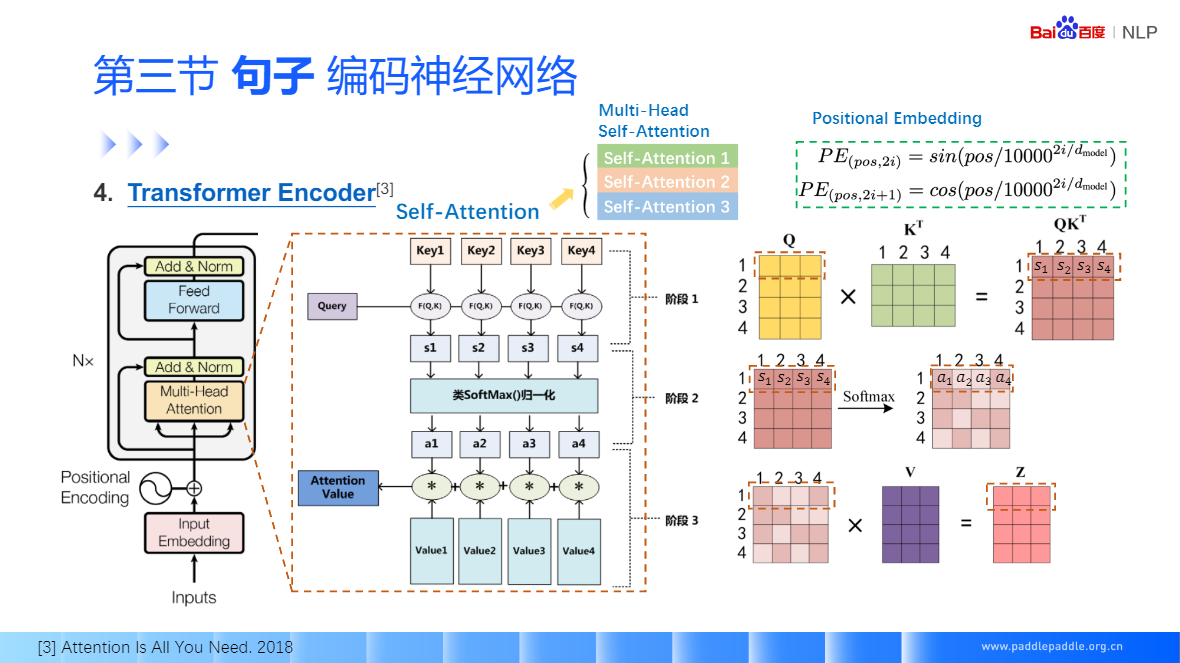
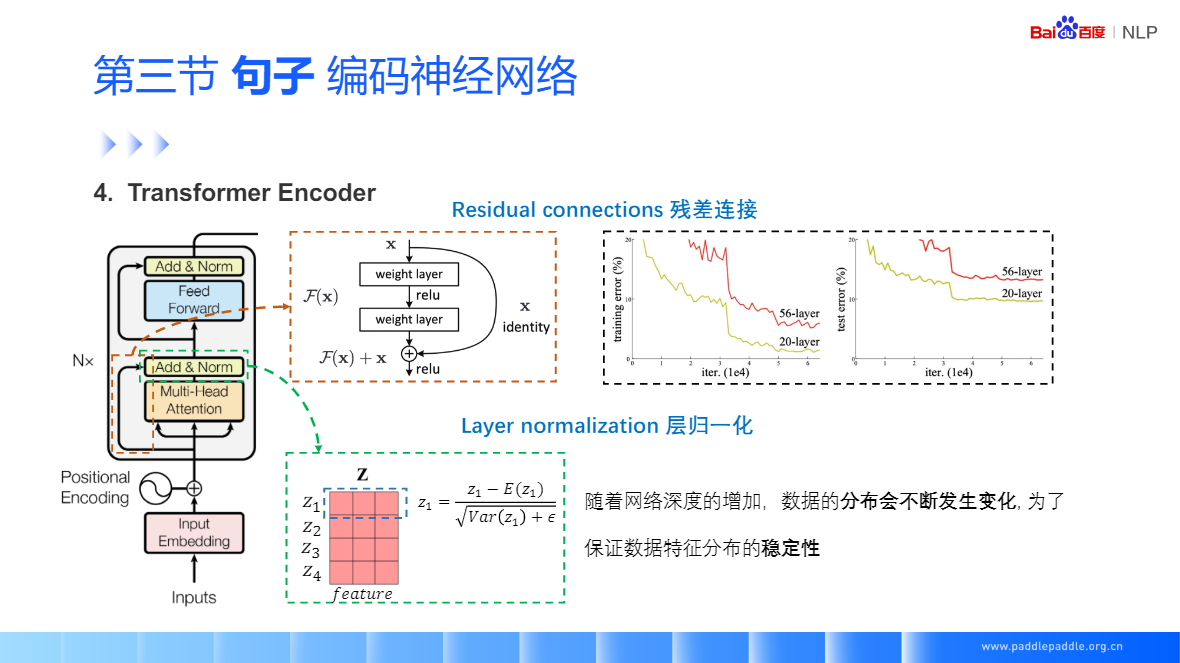
殘差連接,很好的緩解梯度消失的問題,包括映射和直連接部分
https://aistudio.baidu.com/aistudio/education/lessonvideo/1451160
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554165.html
標籤:其他
上一篇:手把手實踐丨基于STM32+華為云設計的智慧煙感系統
下一篇:返回列表