文本識別的應用場景很多,有檔案識別、路標識別、車牌識別、工業編號識別等等,根據實際場景可以把文本識別任務分為兩個大類:規則文本識別和不規則文本識別,
-
規則文本識別:主要指印刷字體、掃描文本等,認為文本大致處在水平線位置
-
不規則文本識別: 往往出現在自然場景中,且由于文本曲率、方向、變形等方面差異巨大,文字往往不在水平位置,存在彎曲、遮擋、模糊等問題,
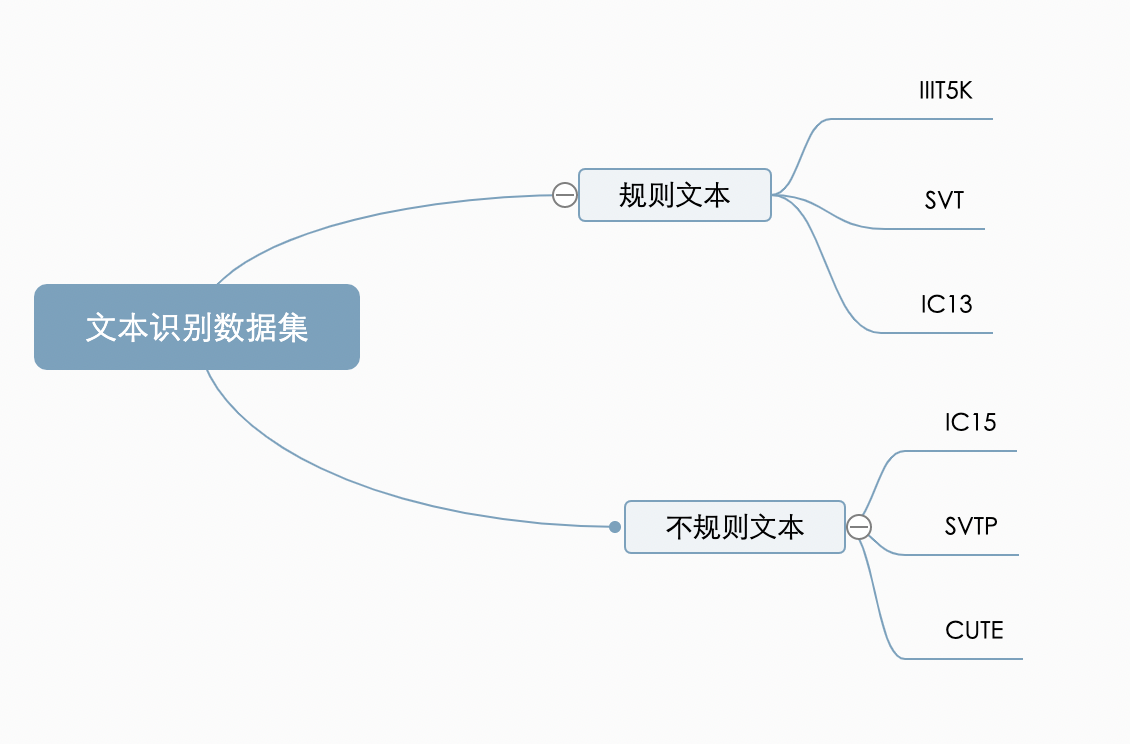
下圖展示的是 IC15 和 IC13 的資料樣式,它們分別代表了不規則文本和規則文本,可以看出不規則文本往往存在扭曲、模糊、字體差異大等問題,更貼近真實場景,也存在更大的挑戰性,
因此目前各大演算法都試圖在不規則資料集上獲得更高的指標,


不同的識別演算法在對比能力時,往往也在這兩大類公開資料集上比較,對比多個維度上的效果,目前較為通用的英文評估集合分類如下:
2 文本識別演算法分類
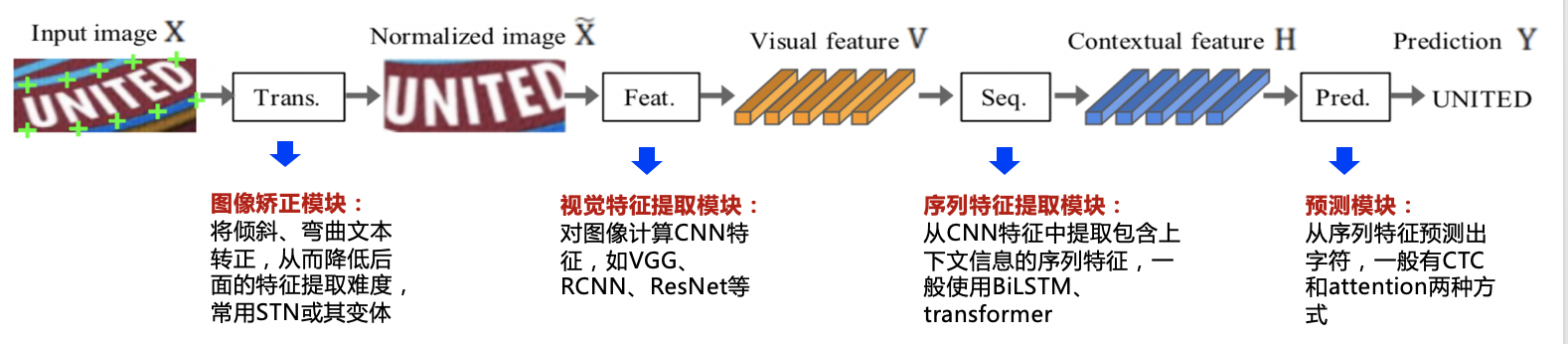
在傳統的文本識別方法中,任務分為3個步驟,即影像預處理、字符分割和字符識別,需要對特定場景進行建模,一旦場景變化就會失效,面對復雜的文字背景和場景變動,基于深度學習的方法具有更優的表現,
多數現有的識別演算法可用如下統一框架表示,演算法流程被劃分為4個階段:
我們整理了主流的演算法類別和主要論文,參考下表:
| 演算法類別 | 主要思路 | 主要論文 |
|---|---|---|
| 傳統演算法 | 滑動視窗、字符提取、動態規劃 | - |
| ctc | 基于ctc的方法,序列不對齊,更快速識別 | CRNN, Rosetta |
| Attention | 基于attention的方法,應用于非常規文本 | RARE, DAN, PREN |
| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |
| 校正 | 校正模塊學習文本邊界并校正成水平方向 | RARE, ASTER, SAR |
| 分割 | 基于分割的方法,提取字符位置再做分類 | Text Scanner, Mask TextSpotter |
2.1 規則文本識別
文本識別的主流演算法有兩種,分別是基于 CTC (Conectionist Temporal Classification) 的演算法和 Sequence2Sequence 演算法,區別主要在解碼階段,
基于 CTC 的演算法是將編碼產生的序列接入 CTC 進行解碼;基于 Sequence2Sequence 的方法則是把序列接入回圈神經網路(Recurrent Neural Network, RNN)模塊進行回圈解碼,兩種方式都驗證有效也是主流的兩大做法,
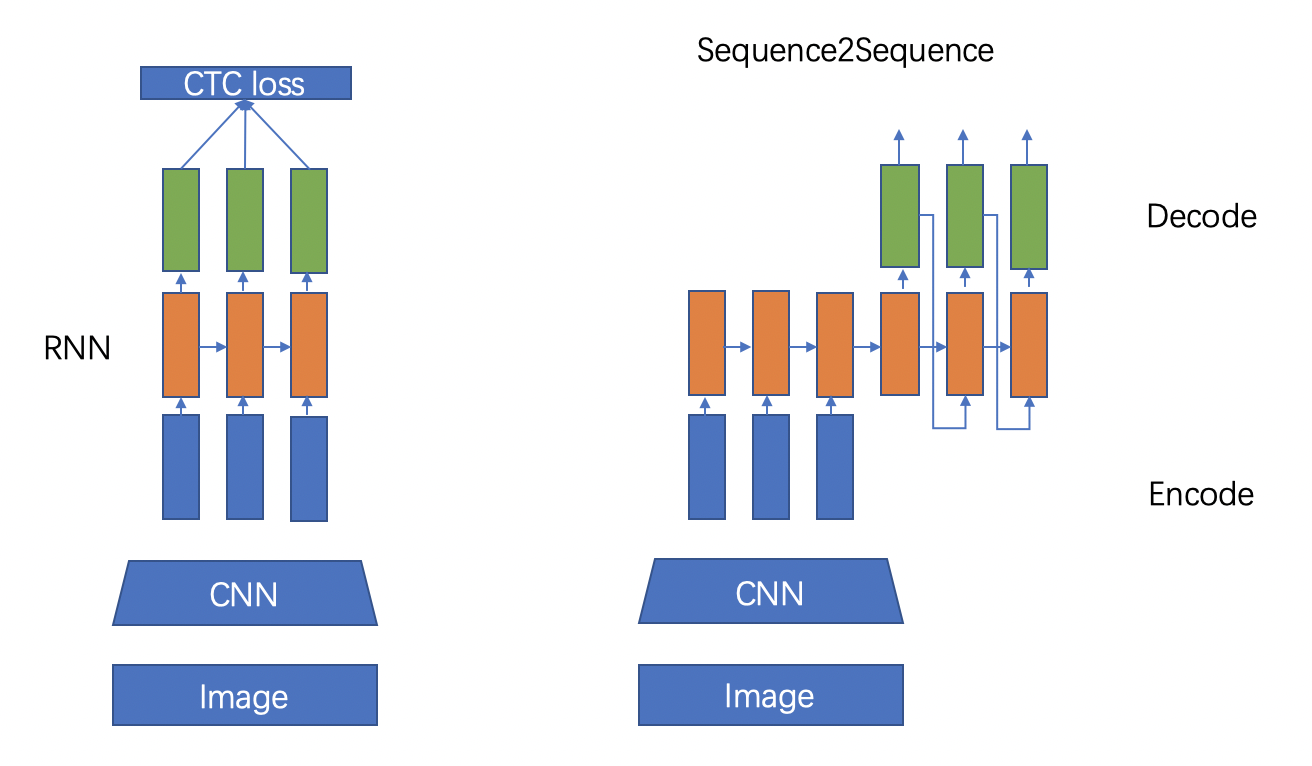
進入CNN,視覺特征提取
進入RNN,序列特征提取
2.1.1 基于CTC的演算法
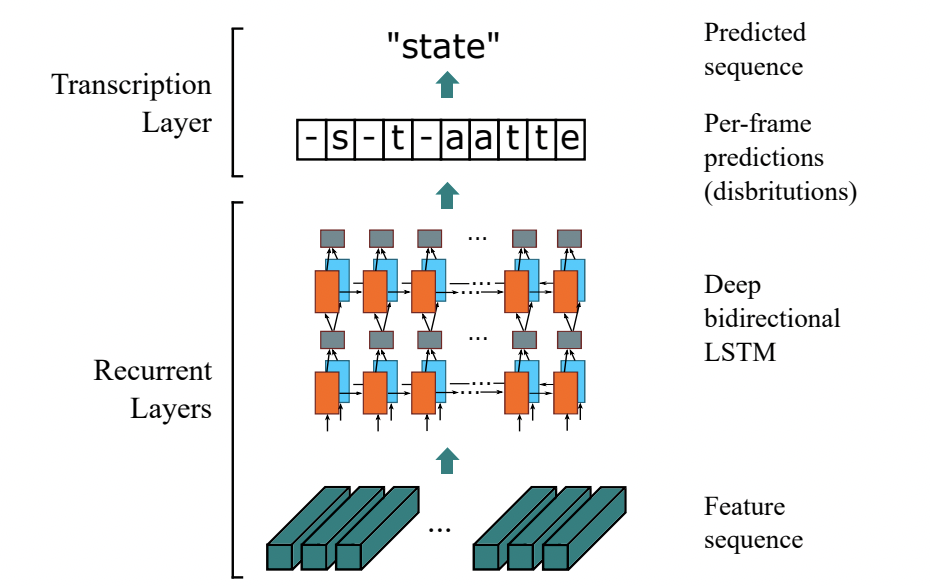
基于 CTC 最典型的演算法是CRNN (Convolutional Recurrent Neural Network)[1],它的特征提取部分使用主流的卷積結構,常用的有ResNet、MobileNet、VGG等,由于文本識別任務的特殊性,輸入資料中存在大量的背景關系資訊,卷積神經網路的卷積核特性使其更關注于區域資訊,缺乏長依賴的建模能力,因此僅使用卷積網路很難挖掘到文本之間的背景關系聯系,為了解決這一問題,CRNN文本識別演算法引入了雙向 LSTM(Long Short-Term Memory) 用來增強背景關系建模,通過實驗證明雙向LSTM模塊可以有效的提取出圖片中的背景關系資訊,最終將輸出的特征序列輸入到CTC模塊,直接解碼序列結果,該結構被驗證有效,并廣泛應用在文本識別任務中,Rosetta[2]是FaceBook提出的識別網路,由全卷積模型和CTC組成,Gao Y[3]等人使用CNN卷積替代LSTM,引數更少,性能提升精度持平,
2.1.2 Sequence2Sequence 演算法
Sequence2Sequence 演算法是由編碼器 Encoder 把所有的輸入序列都編碼成一個統一的語意向量,然后再由解碼器Decoder解碼,在解碼器Decoder解碼的程序中,不斷地將前一個時刻的輸出作為后一個時刻的輸入,回圈解碼,直到輸出停止符為止,一般編碼器是一個RNN,對于每個輸入的詞,編碼器輸出向量和隱藏狀態,并將隱藏狀態用于下一個輸入的單詞,回圈得到語意向量;解碼器是另一個RNN,它接收編碼器輸出向量并輸出一系列字以創建轉換,受到 Sequence2Sequence 在翻譯領域的啟發, Shi[4]提出了一種基于注意的編解碼框架來識別文本,通過這種方式,rnn能夠從訓練資料中學習隱藏在字串中的字符級語言模型,
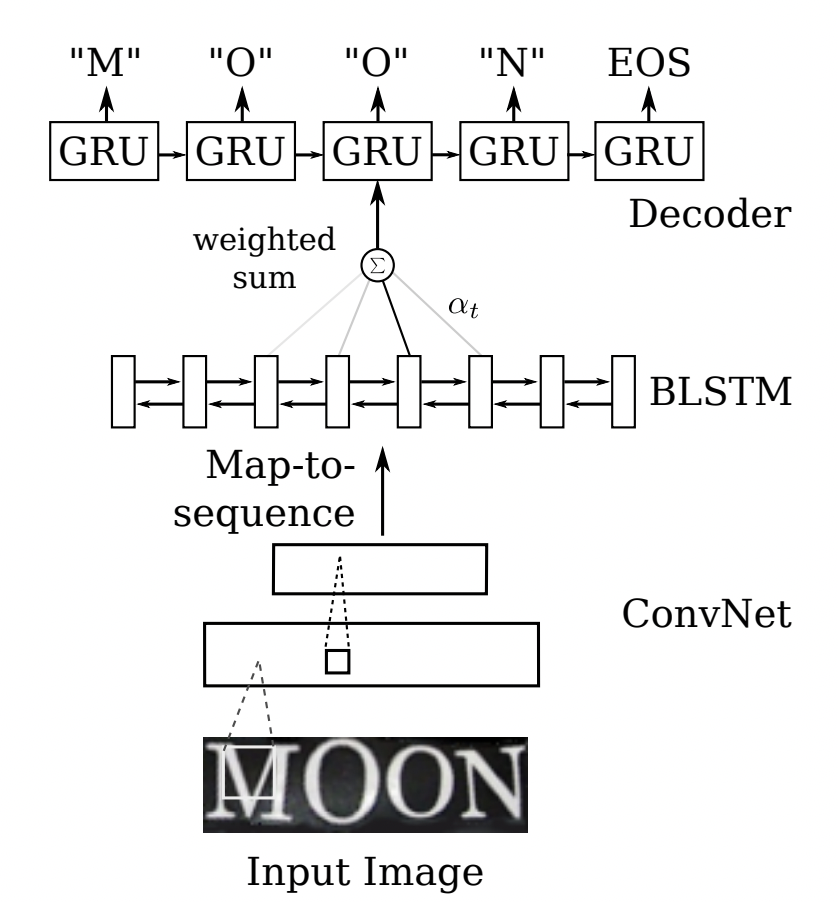
以上兩個演算法在規則文本上都有很不錯的效果,但由于網路設計的局限性,這類方法很難解決彎曲和旋轉的不規則文本識別任務,為了解決這類問題,部分演算法研究人員在以上兩類演算法的基礎上提出了一系列改進演算法,
2.2 不規則文本識別
- 不規則文本識別演算法可以被分為4大類:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法,
2.2.1 基于校正的方法
基于校正的方法利用一些視覺變換模塊,將非規則的文本盡量轉換為規則文本,然后使用常規方法進行識別,
RARE[4]模型首先提出了對不規則文本的校正方案,整個網路分為兩個主要部分:一個空間變換網路STN(Spatial Transformer Network) 和一個基于Sequence2Squence的識別網路,其中STN就是校正模塊,不規則文本影像進入STN,通過TPS(Thin-Plate-Spline)變換成一個水平方向的影像,該變換可以一定程度上校正彎曲、透射變換的文本,校正后送入序列識別網路進行解碼,
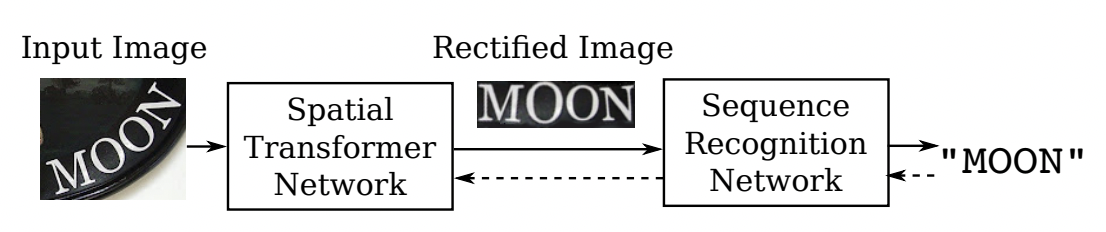
RARE論文指出,該方法在不規則文本資料集上有較大的優勢,特別比較了CUTE80和SVTP這兩個資料集,相較CRNN高出5個百分點以上,證明了校正模塊的有效性,基于此[6]同樣結合了空間變換網路(STN)和基于注意的序列識別網路的文本識別系統,
基于校正的方法有較好的遷移性,除了RARE這類基于Attention的方法外,STAR-Net[5]將校正模塊應用到基于CTC的演算法上,相比傳統CRNN也有很好的提升,
2.2.2 基于Attention的方法
基于 Attention 的方法主要關注的是序列之間各部分的相關性,該方法最早在機器翻譯領域提出,認為在文本翻譯的程序中當前詞的結果主要由某幾個單詞影響的,因此需要給有決定性的單詞更大的權重,在文本識別領域也是如此,將編碼后的序列解碼時,每一步都選擇恰當的context來生成下一個狀態,這樣有利于得到更準確的結果,
R^2AM [7] 首次將 Attention 引入文本識別領域,該模型首先將輸入影像通過遞回卷積層提取編碼后的影像特征,然后利用隱式學習到的字符級語言統計資訊通過遞回神經網路解碼輸出字符,在解碼程序中引入了Attention 機制實作了軟特征選擇,以更好地利用影像特征,這一有選擇性的處理方式更符合人類的直覺,
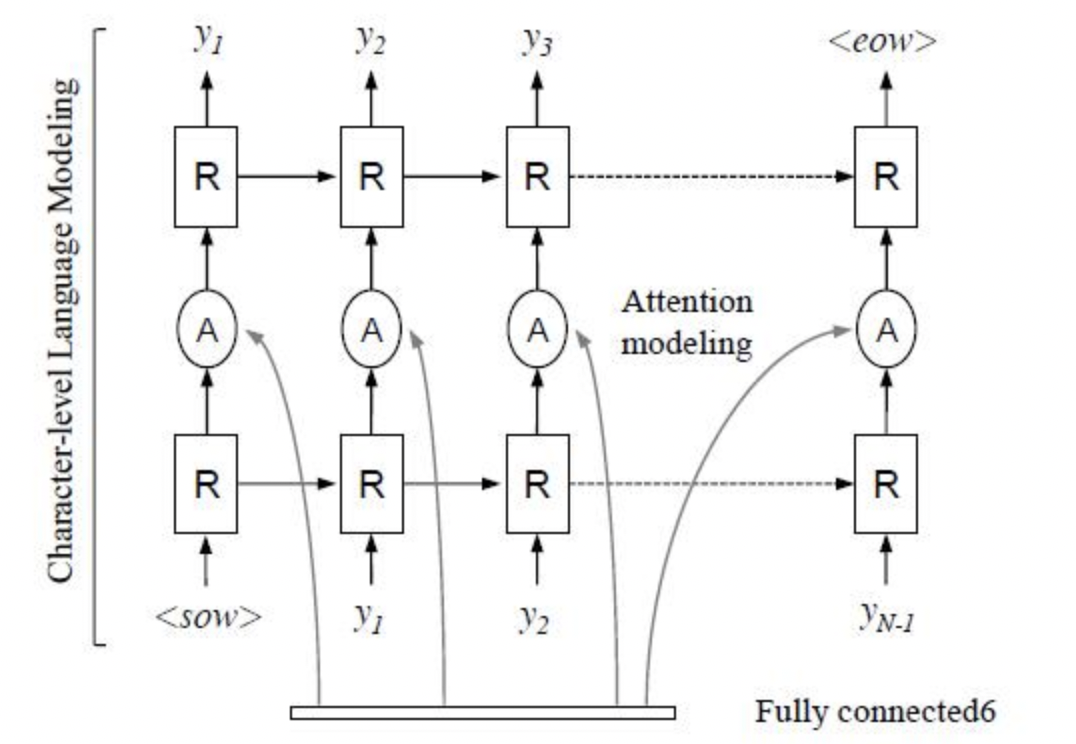
后續有大量演算法在Attention領域進行探索和更新,例如SAR[8]將1D attention拓展到2D attention上,校正模塊提到的RARE也是基于Attention的方法,實驗證明基于Attention的方法相比CTC的方法有很好的精度提升,

2.2.3 基于分割的方法
基于分割的方法是將文本行的各字符作為獨立個體,相比與對整個文本行做矯正后識別,識別分割出的單個字符更加容易,它試圖從輸入的文本影像中定位每個字符的位置,并應用字符分類器來獲得這些識別結果,將復雜的全域問題簡化成了區域問題解決,在不規則文本場景下有比較不錯的效果,然而這種方法需要字符級別的標注,資料獲取上存在一定的難度,Lyu[9]等人提出了一種用于單詞識別的實體分詞模型,該模型在其識別部分使用了基于 FCN(Fully Convolutional Network) 的方法,[10]從二維角度考慮文本識別問題,設計了一個字符注意FCN來解決文本識別問題,當文本彎曲或嚴重扭曲時,該方法對規則文本和非規則文本都具有較優的定位結果,

2.2.4 基于Transformer的方法
隨著 Transformer 的快速發展,分類和檢測領域都驗證了 Transformer 在視覺任務中的有效性,如規則文本識別部分所說,CNN在長依賴建模上存在局限性,Transformer 結構恰好解決了這一問題,它可以在特征提取器中關注全域資訊,并且可以替換額外的背景關系建模模塊(LSTM),
一部分文本識別演算法使用 Transformer 的 Encoder 結構和卷積共同提取序列特征,Encoder 由多個 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆疊而成的block組成,MulitHeadAttention 中的 self-attention 利用矩陣乘法模擬了RNN的時序計算,打破了RNN中時序長時依賴的障礙,也有一部分演算法使用 Transformer 的 Decoder 模塊解碼,相比傳統RNN可獲得更強的語意資訊,同時并行計算具有更高的效率,
SRN[11] 演算法將Transformer的Encoder模塊接在ResNet50后,增強了2D視覺特征,并提出了一個并行注意力模塊,將讀取順序用作查詢,使得計算與時間無關,最終并行輸出所有時間步長的對齊視覺特征,此外SRN還利用Transformer的Eecoder作為語意模塊,將圖片的視覺資訊和語意資訊做融合,在遮擋、模糊等不規則文本上有較大的收益,
NRTR[12] 使用了完整的Transformer結構對輸入圖片進行編碼和解碼,只使用了簡單的幾個卷積層做高層特征提取,在文本識別上驗證了Transformer結構的有效性,
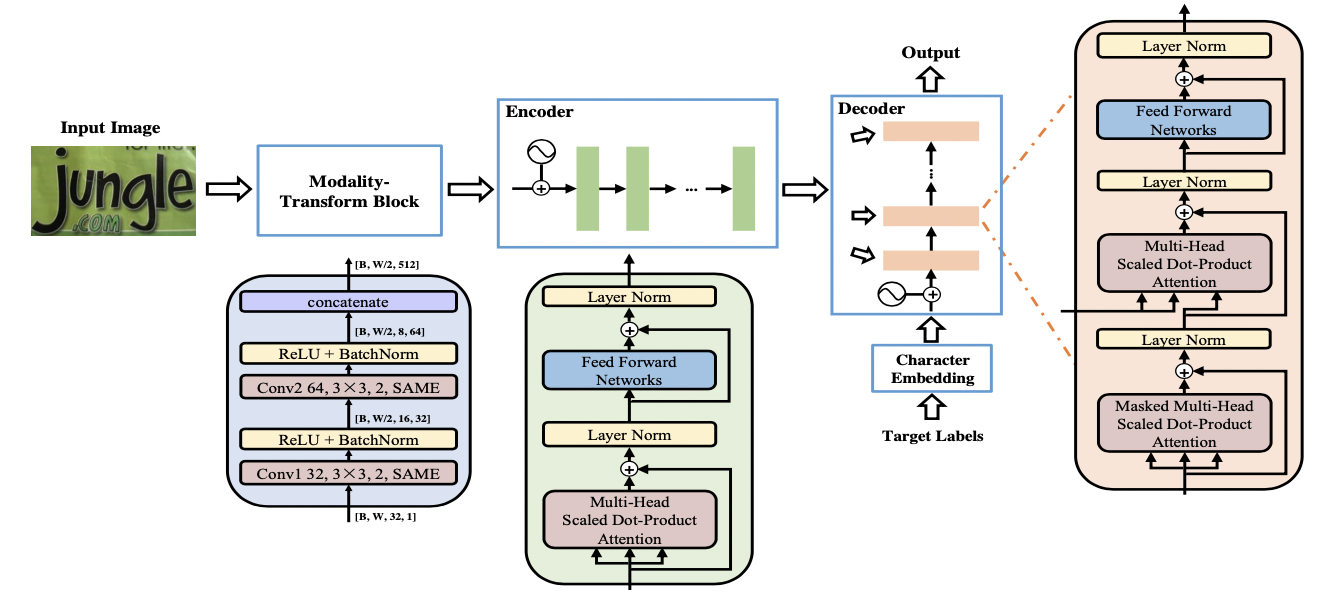
SRACN[13]使用Transformer的解碼器替換LSTM,再一次驗證了并行訓練的高效性和精度優勢,
原文:https://aistudio.baidu.com/aistudio/projectdetail/6276554
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554306.html
標籤:其他
上一篇:移動安全課程
下一篇:返回列表