摘要:我們提供了一鍵運行的notebook AI作畫 Dreambooth 生成自定義主體,可以在ModelArts平臺上除錯開發自己的文生圖模型,
本文分享自華為云社區《DreamBooth+LoRA微調生成主體》,作者: 杜甫蓋房子 ,
DreamBooth+LoRA微調生成主體
文生圖風靡一時,但預訓練的文生圖模型無法控制生成特定的主體,DreamBooth提供了一種方法,只需要特定主體的幾張圖就可以微調文生圖模型,生成包含特定主體的圖片,例如,提供如下主體圖片,給定主體名稱為biu model:

微調文生圖模型后,使用"biu model in the garden"作為prompt推理,將生成包含該主體的圖片:

我們提供了一鍵運行的notebook AI作畫 Dreambooth 生成自定義主體,可以在ModelArts平臺上除錯開發自己的文生圖模型,此外,我們還提供了零代碼運行的Workflow DreamBooth自定義生成主體,可以通過簡單的可視化配置完成模型訓練、AI應用打包、在線推理服務部署等全流程,無需任何開發即可玩轉個性化文生圖模型微調,
DreamBooth
DreamBooth 是一種生成個性化文生圖模型的方法,用戶可以給定3~5張某個主體的影像及該主體的名稱,微調文生圖模型(本案例使用的是Stable Diffusion v1-4),微調后的模型可以使用主體名稱作為prompt,生成對應主體的影像,如圖:
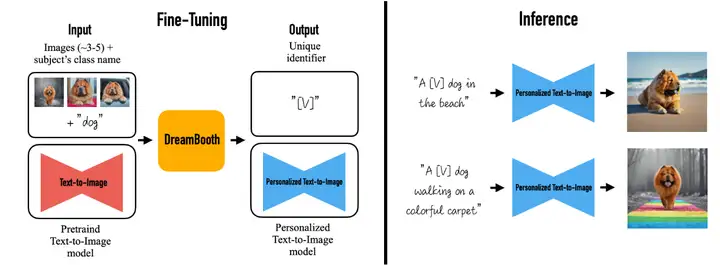
圖源:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth想要將定義的主體名稱與特定主體系結,同時保留主體對應類別的細節特征,因此,在構建主體名稱時可以加入大類別名,如主體是一只可愛的小貓,則主體名稱可以定義為"a [V] cat",其中大類名"cat"可以保留大類特征,[V]作為稀有識別符號,可以避免主體受通用詞組先驗知識的影響,
為了減少微調導致的語意漂移,以及保持擴散模型生成內容的多樣性,DreamBooth引入了prior preservation loss,利用大類的先驗知識生成與訓練主體相同大類的不同實體對模型進行監督:
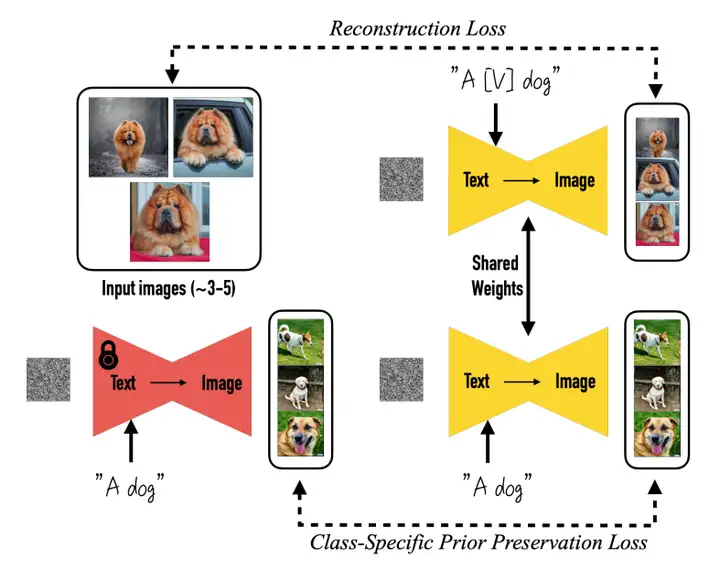
圖源:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
LoRA
Low-Rank Adaptation of Large Language Models (LoRA) 是一種訓練方法,可以在消耗較少記憶體的同時加速大模型的訓練,大模型通常具有很多引數,直接微調大模型將是一個緩慢而昂貴的程序,在Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning中提出一個洞見:預訓練語言模型微調后,權重矩陣中表征特征的部分其實是很低秩的,作者受此啟發,認為模型微調時,更新的權重表征特征的部分應該也是低秩的,即在模型微調時,權重可以表示為:W=W0+ΔWW=W0?+ΔW,其中,W0W0?為不更新的預訓練權重矩陣,ΔWΔW為實際更新的、可以進行低秩分解的權重矩陣,如圖,藍色部分為不更新的預訓練權重,橙色部分為分解為兩個低秩矩陣的微調權重:
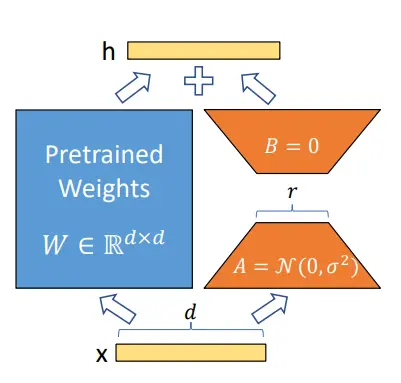
圖源:LoRA: Low-Rank Adaptation of Large Language Models
LoRA有幾個顯而易見的優勢:
- 預訓練權重保持不變,因此模型不容易發生災難性的遺忘;
- 秩分解矩陣的引數明顯少于原始模型,微調部分的權重更小,易于移植;
- 預訓練模型可以共享,不同的任務只需要提供很小的LoRA模塊,可以高效的切換任務,顯著降低存盤需求;
- 微調成本大幅降;
- 在推理時可以將橙色部分與藍色部分合并,不會引入額外的推理時延,
案例
我們提供了兩種形式的案例:一鍵運行的notebook AI作畫 Dreambooth 生成自定義主體 和零代碼運行的Workflow DreamBooth自定義生成主體,
notebook使用上靈活程度更高,適合有一定代碼能力的朋友玩一下,Workflow封裝程度更高,提供了詳細的使用檔案,同時包含了AI應用等節點,不需要寫任何代碼也可以生成自己的模型并在線測驗,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554378.html
標籤:其他
上一篇:從0到1:如何建立一個大規模多語言代碼生成預訓練模型
下一篇:返回列表