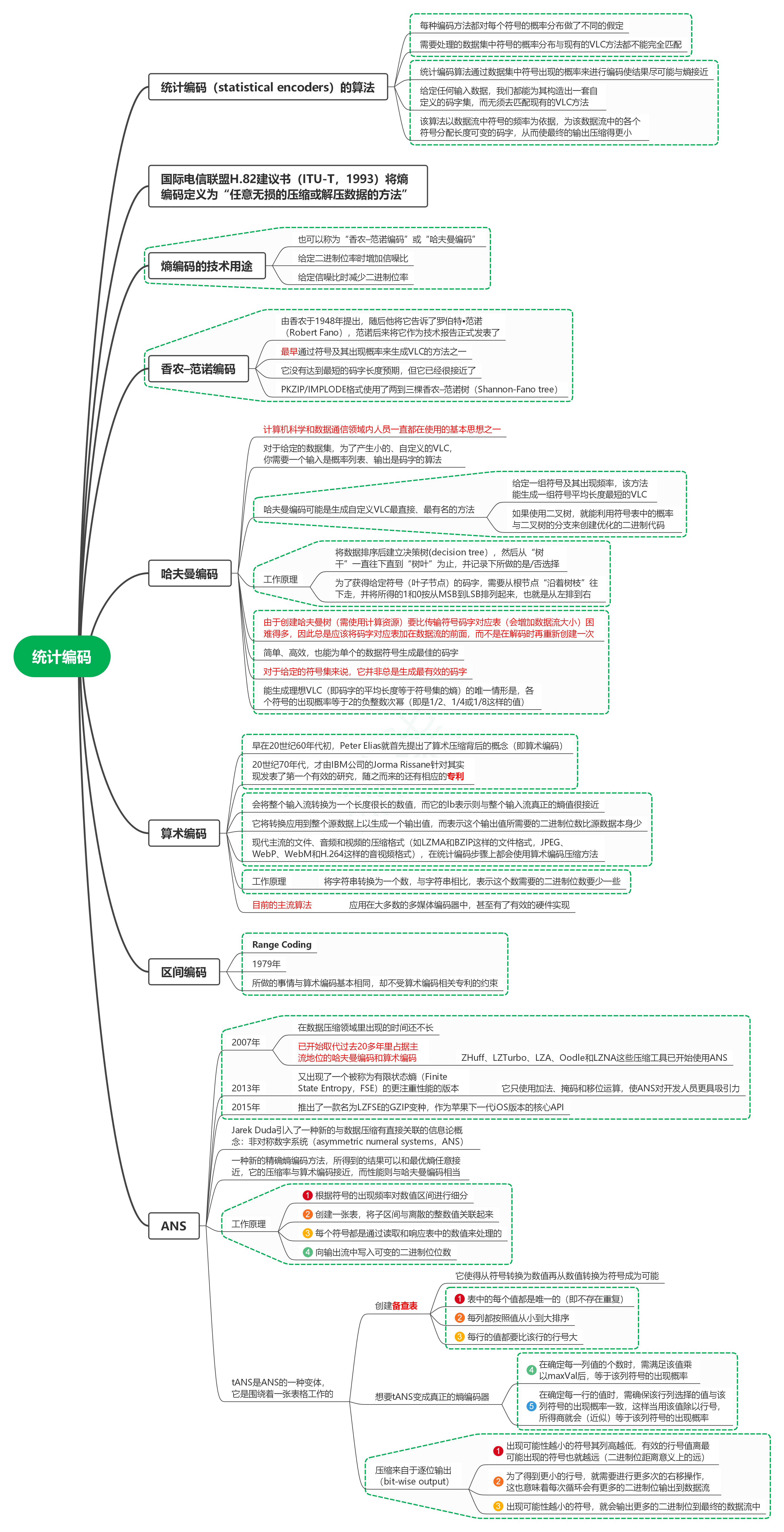
1. 統計編碼(statistical encoders)的演算法
1.1. 每種編碼方法都對每個符號的概率分布做了不同的假定
1.2. 需要處理的資料集中符號的概率分布與現有的VLC方法都不能完全匹配
1.3. 統計編碼演算法通過資料集中符號出現的概率來進行編碼使結果盡可能與熵接近
1.4. 給定任何輸入資料,我們都能為其構造出一套自定義的碼字集,而無須去匹配現有的VLC方法
1.5. 該演算法以資料流中符號的頻率為依據,為該資料流中的各個符號分配長度可變的碼字,從而使最終的輸出壓縮得更小
2. 國際電信聯盟H.82建議書(ITU-T,1993)將熵編碼定義為“任意無損的壓碩訓解壓資料的方法”
3. 熵編碼的技術用途
3.1. 也可以稱為“香農–范諾編碼”或“哈夫曼編碼”
3.2. 給定二進制位率時增加信噪比
3.3. 給定信噪比時減少二進制位率
4. 香農–范諾編碼
4.1. 由香農于1948年提出,隨后他將它告訴了羅伯特?范諾(Robert Fano),范諾后來將它作為技術報告正式發表了
4.2. 最早通過符號及其出現概率來生成VLC的方法之一
4.3. 它沒有達到最短的碼字長度預期,但它已經很接近了
4.4. PKZIP/IMPLODE格式使用了兩到三棵香農–范諾樹(Shannon-Fano tree)
5. 哈夫曼編碼
5.1. 計算機科學和資料通信領域內人員一直都在使用的基本思想之一
5.2. 對于給定的資料集,為了產生小的、自定義的VLC,你需要一個輸入是概率串列、輸出是碼字的演算法
5.3. 哈夫曼編碼可能是生成自定義VLC最直接、最有名的方法
5.3.1. 給定一組符號及其出現頻率,該方法能生成一組符號平均長度最短的VLC
5.3.2. 如果使用二叉樹,就能利用符號表中的概率與二叉樹的分支來創建優化的二進制代碼
5.4. 作業原理
5.4.1. 將資料排序后建立決策樹(decision tree),然后從“樹干”一直往下直到“樹葉”為止,并記錄下所做的是/否選擇
5.4.2. 為了獲得給定符號(葉子節點)的碼字,需要從根節點“沿著樹枝”往下走,并將所得的1和0按從MSB到LSB排列起來,也就是從左排到右
5.5. 由于創建哈夫曼樹(需使用計算資源)要比傳輸符號碼字對應表(會增加資料流大小)困難得多,因此總是應該將碼字對應表加在資料流的前面,而不是在解碼時再重新創建一次
5.6. 簡單、高效,也能為單個的資料符號生成最佳的碼字
5.7. 對于給定的符號集來說,它并非總是生成最有效的碼字
5.8. 能生成理想VLC(即碼字的平均長度等于符號集的熵)的唯一情形是,各個符號的出現概率等于2的負整數次冪(即是1/2、1/4或1/8這樣的值)
6. 算術編碼
6.1. 早在20世紀60年代初,Peter Elias就首先提出了算術壓縮背后的概念(即算術編碼)
6.2. 20世紀70年代,才由IBM公司的Jorma Rissane針對其實作發表了第一個有效的研究,隨之而來的還有相應的專利
6.3. 會將整個輸入流轉換為一個長度很長的數值,而它的lb表示則與整個輸入流真正的熵值很接近
6.4. 它將轉換應用到整個源資料上以生成一個輸出值,而表示這個輸出值所需要的二進制位數比源資料本身少
6.5. 現代主流的檔案、音頻和視頻的壓縮格式(如LZMA和BZIP這樣的檔案格式,JPEG、WebP、WebM和H.264這樣的音視頻格式),在統計編碼步驟上都會使用算術編碼壓縮方法
6.6. 作業原理
6.6.1. 將字串轉換為一個數,與字串相比,表示這個數需要的二進制位數要少一些
6.7. 目前的主流演算法
6.7.1. 應用在大多數的多媒體編碼器中,甚至有了有效的硬體實作
7. 區間編碼
7.1. Range Coding
7.2. 1979年
7.3. 所做的事情與算術編碼基本相同,卻不受算術編碼相關專利的約束
8. ANS
8.1. 2007年
8.1.1. 在資料壓縮領域里出現的時間還不長
8.1.2. 已開始取代過去20多年里占據主流地位的哈夫曼編碼和算術編碼
8.1.2.1. ZHuff、LZTurbo、LZA、Oodle和LZNA這些壓縮工具已開始使用ANS
8.2. 2013年
8.2.1. 又出現了一個被稱為有限狀態熵(Finite State Entropy,FSE)的更注重性能的版本
8.2.1.1. 它只使用加法、掩碼和移位運算,使ANS對開發人員更具吸引力
8.3. 2015年
8.3.1. 推出了一款名為LZFSE的GZIP變種,作為蘋果下一代iOS版本的核心API
8.4. Jarek Duda引入了一種新的與資料壓縮有直接關聯的資訊論概念:非對稱數字系統(asymmetric numeral systems,ANS)
8.5. 一種新的精確熵編碼方法,所得到的結果可以和最優熵任意接近,它的壓縮率與算術編碼接近,而性能則與哈夫曼編碼相當
8.6. 作業原理
8.6.1. 根據符號的出現頻率對數值區間進行細分
8.6.2. 創建一張表,將子區間與離散的整數值關聯起來
8.6.3. 每個符號都是通過讀取和回應表中的數值來處理的
8.6.4. 向輸出流中寫入可變的二進制位位數
8.7. tANS是ANS的一種變體,它是圍繞著一張表格作業的
8.7.1. 創建備查表
8.7.1.1. 它使得從符號轉換為數值再從數值轉換為符號成為可能
8.7.1.2. 表中的每個值都是唯一的(即不存在重復)
8.7.1.3. 每列都按照值從小到大排序
8.7.1.4. 每行的值都要比該行的行號大
8.7.2. 想要tANS變成真正的熵編碼器
8.7.2.1. 在確定每一列值的個數時,需滿足該值乘以maxVal后,等于該列符號的出現概率
8.7.2.2. 在確定每一行的值時,需確保該行列選擇的值與該列符號的出現概率一致,這樣當用該值除以行號,所得商就會(近似)等于該列符號的出現概率
8.7.3. 壓縮來自于逐位輸出(bit-wise output)
8.7.3.1. 出現可能性越小的符號其列高越低,有效的行號值離最可能出現的符號也就越遠(二進制位距離意義上的遠)
8.7.3.2. 為了得到更小的行號,就需要進行更多次的右移操作,這也意味著每次回圈會有更多的二進制位輸出到資料流
8.7.3.3. 出現可能性越小的符號,就會輸出更多的二進制位到最終的資料流中
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554493.html
標籤:其他
上一篇:ChatGPT玩法(二):AI玩轉Excel表格處理
下一篇:返回列表