Trie樹 學習感受
相比于之前學習的kmp匹配演算法,Trie樹的實作還是非常好理解的,(kmp演算法太難了orz)
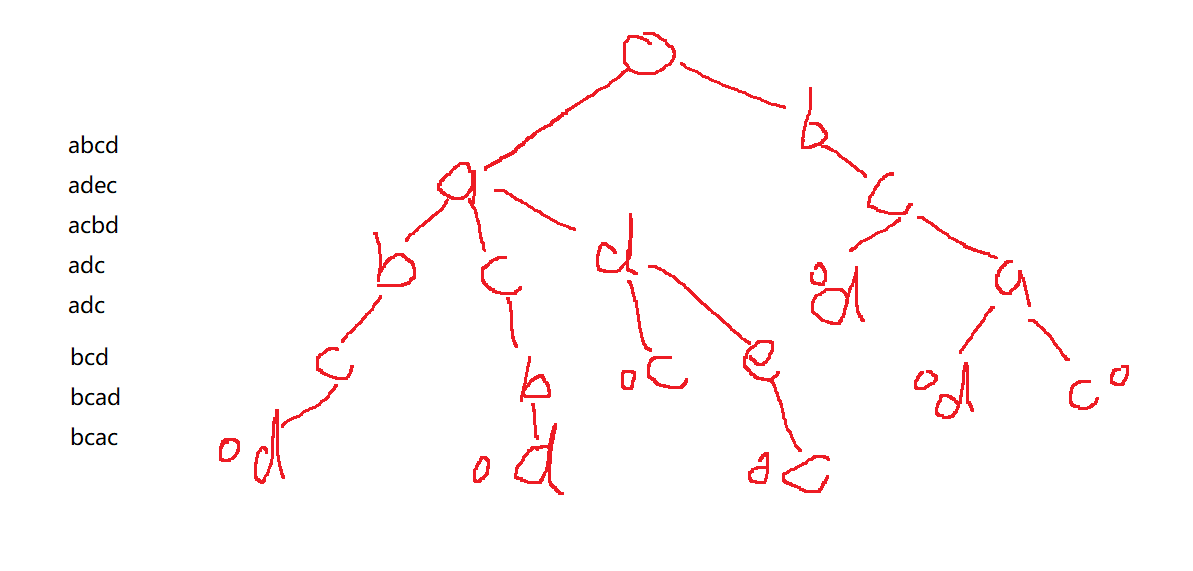
從直觀的模擬程序來看,trie樹就像一顆樹一樣,從上(根節點)到下(葉節點)有序串聯起來組成一個字串,
每一個額外標記結束的位置表示字串的結束,通過計算標記數即可指導一共有多少該字串,
從暴力演算法看Trie演算法
先想想,如果要是暴力演算法來做的話,應該怎么去統計字串出現次數呢?
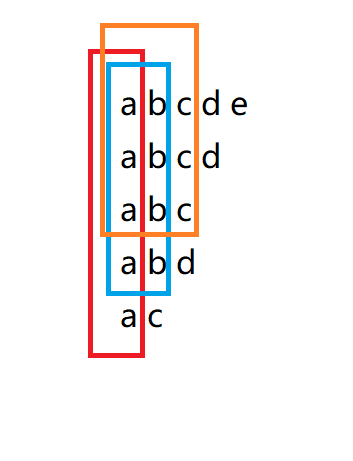
首先要利用陣列去存盤各種不相同的字串,在讀入一個新的字串時,需要先判斷他和已有的字串是否相等,如果不相等,則將該字串存入,如果相等,則跳過該字串,顯然,暴力演算法的時間復雜度會很大,在這里,有沒有更好的判斷方法,讓我不用再去每次判斷都要遍歷所有已經儲存的字串呢?
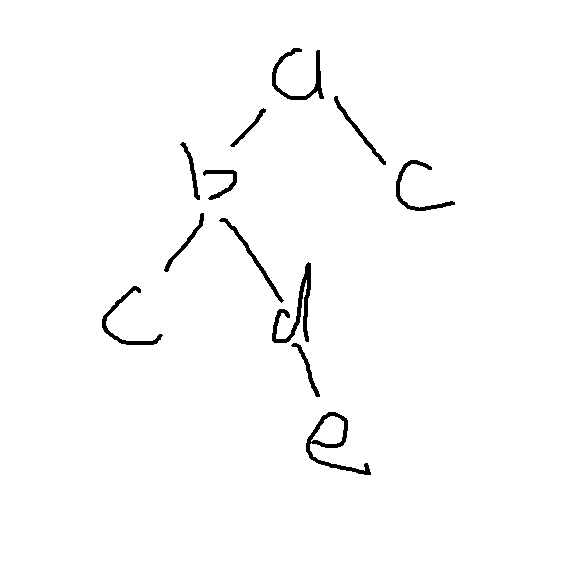
我們來著重討論判斷他和已有字串是否相等,在這里的判斷方法顯然是回圈遍歷兩個字串,判斷字串長度以及每個位置是否相等,那么,在回圈遍歷所有字串的程序中,不難發現,對于部分相等以及完全相等字串,從字串第一個字符起,總會和目標字串有一個公共部分,那么,我們是否可以對于字串每一個位置(對于數的每一層)只存盤一個字串該位置出現的字符,使得所有字串共用一顆樹(如上圖),這樣在大大減少時間復雜度的同時,空間復雜度也得到的減小,
Trie樹的實作
Trie樹的實作程序是用陣列模擬實作多叉樹的程序,首先需要一個二維陣列 trie[n][m] 來實作樹,其中 n 代表所有字符的總長度,m代表多叉樹的最大分支,
再者,需要一個 cnt[n] 陣列存盤每個字串出現的次數,n應該小于所有字符的總數量,
最后,需要一個整型變數 idx , 用于存盤樹中某個節點對應 cnt 陣列的下標,
樹的插入代碼如下:
void insert(string s) { int tmp = 0;//tmp 代表當前節點的位置,0 代表根節點 for(auto c : s) { int u = c - 'a';//將二十六個字母映射到0到25 if(!trie[tmp][u]) trie[tmp][u] = ++ idx;//如果字典樹當前位置當中沒有這個字符,則建立這個字符,且將他與cnt陣列對應 tmp = trie[tmp][u];//類比指標,指向字典樹下一個位置 } cnt[tmp] ++;//把字串結束對應的點的計數陣列增加一 }
樹的查詢代碼如下:
int search(string s) { int tmp = 0;//tmp 代表當前節點的位置,0 代表根節點 for(auto c : s) { int u = c - 'a';//將二十六個字母映射到0到25 if(!trie[tmp][u]) return 0;//如果字典樹當前位置當中沒有這個字符,則查詢結束,證明沒有這個字串 else tmp = trie[tmp][u];//類比指標,指向字典樹下一個位置 } return cnt[tmp];//回傳該字串的個數 }
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554584.html
標籤:其他
下一篇:返回列表