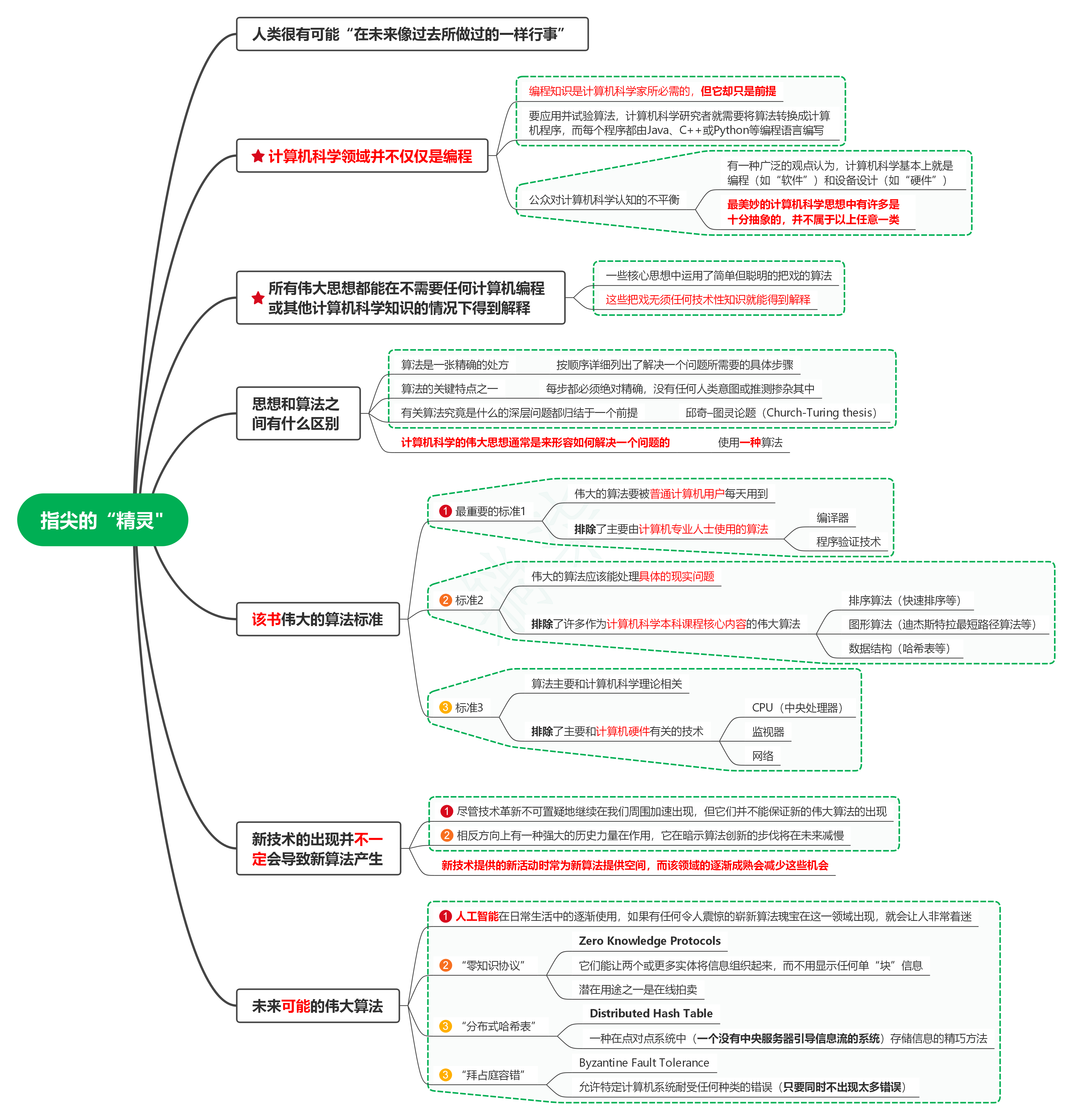
1. 人類很有可能“在未來像過去所做過的一樣行事”
2. 計算機科學領域并不僅僅是編程
2.1. 編程知識是計算機科學家所必需的,但它卻只是前提
2.2. 要應用并試驗演算法,計算機科學研究者就需要將演算法轉換成計算機程式,而每個程式都由Java、C++或Python等編程語言撰寫
2.3. 公眾對計算機科學認知的不平衡
2.3.1. 有一種廣泛的觀點認為,計算機科學基本上就是編程(如“軟體”)和設備設計(如“硬體”)
2.3.2. 最美妙的計算機科學思想中有許多是十分抽象的,并不屬于以上任意一類
3. 所有偉大思想都能在不需要任何計算機編程或其他計算機科學知識的情況下得到解釋
3.1. 一些核心思想中運用了簡單但聰明的把戲的演算法
3.2. 這些把戲無須任何技術性知識就能得到解釋
4. 思想和演算法之間有什么區別
4.1. 演算法是一張精確的處方
4.1.1. 按順序詳細列出了解決一個問題所需要的具體步驟
4.2. 演算法的關鍵特點之一
4.2.1. 每步都必須絕對精確,沒有任何人類意圖或推測摻雜其中
4.3. 有關演算法究竟是什么的深層問題都歸結于一個前提
4.3.1. 邱奇–圖靈論題(Church-Turing thesis)
4.4. 計算機科學的偉大思想通常是來形容如何解決一個問題的
4.4.1. 使用一種演算法
5. 該書偉大的演算法標準
5.1. 最重要的標準1
5.1.1. 偉大的演算法要被普通計算機用戶每天用到
5.1.2. 排除了主要由計算機專業人士使用的演算法
5.1.2.1. 編譯器
5.1.2.2. 程式驗證技術
5.2. 標準2
5.2.1. 偉大的演算法應該能處理具體的現實問題
5.2.2. 排除了許多作為計算機科學本科課程核心內容的偉大演算法
5.2.2.1. 排序演算法(快速排序等)
5.2.2.2. 圖形演算法(迪杰斯特拉最短路徑演算法等)
5.2.2.3. 資料結構(哈希表等)
5.3. 標準3
5.3.1. 演算法主要和計算機科學理論相關
5.3.2. 排除了主要和計算機硬體有關的技術
5.3.2.1. CPU(中央處理器)
5.3.2.2. 監視器
5.3.2.3. 網路
6. 新技術的出現并不一定會導致新演算法產生
6.1. 盡管技術革新不可置疑地繼續在我們周圍加速出現,但它們并不能保證新的偉大演算法的出現
6.2. 相反方向上有一種強大的歷史力量在作用,它在暗示演算法創新的步伐將在未來減慢
6.3. 新技術提供的新活動時常為新演算法提供空間,而該領域的逐漸成熟會減少這些機會
7. 未來可能的偉大演算法
7.1. 人工智能在日常生活中的逐漸使用,如果有任何令人震驚的嶄新演算法瑰寶在這一領域出現,就會讓人非常著迷
7.2. “零知識協議”
7.2.1. Zero Knowledge Protocols
7.2.2. 它們能讓兩個或更多物體將資訊組織起來,而不用顯示任何單“塊”資訊
7.2.3. 潛在用途之一是在線拍賣
7.3. “分布式哈希表”
7.3.1. Distributed Hash Table
7.3.2. 一種在點對點系統中(一個沒有中央服務器引導資訊流的系統)存盤資訊的精巧方法
7.4. “拜占庭容錯”
7.4.1. Byzantine Fault Tolerance
7.4.2. 允許特定計算機系統耐受任何種類的錯誤(只要同時不出現太多錯誤)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554849.html
標籤:其他
上一篇:AtCoder Beginner Contest 305
下一篇:返回列表