什么是語言理解?
關于疫情的一段對話:
-
中國:我們這邊快完了
-
歐洲:我們這邊快完了
-
中國:我們好多了
-
歐洲:我們好多了
挑戰:
- 語言的復雜性和多樣性
- 多義/同義/歧義現象
- 靈活多變的表達形式
- 語言背后的環境知識
- 以前沒錢買華為,現在沒錢買華為
語言理解的四個粒度:
- 字的理解 例如:藏
- 詞的理解 例如:蘋果
- 句子的理解 例如:我們這邊快完了
- 篇章的理解 例如:貿易制裁似乎成了美國政府在對華關系中慣用的大棒,然而,這大棒果真如美國政府所希望的那樣靈驗嗎?
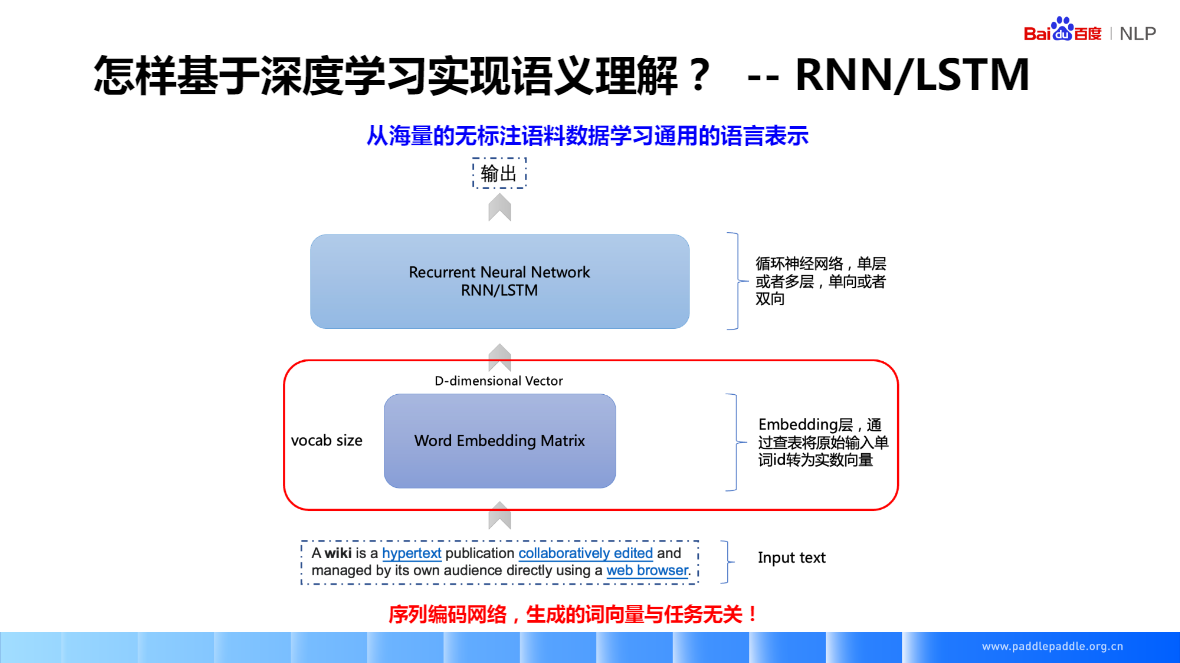
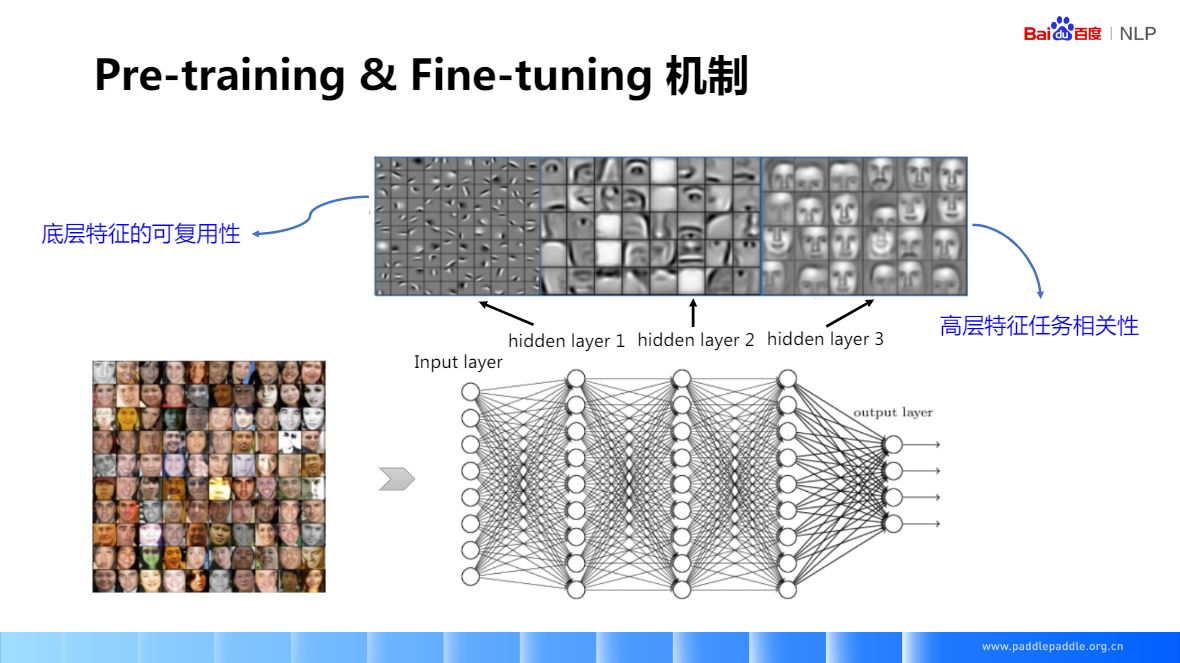
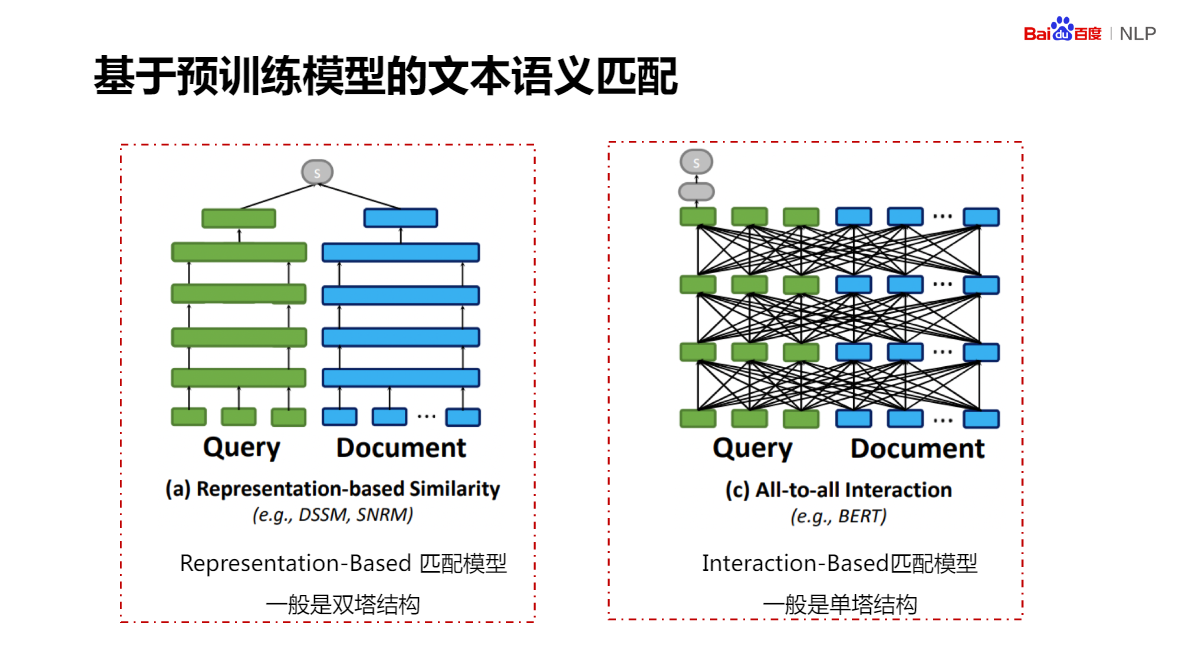
好的表示是實作語言理解的基礎:一個好的表示,是要具備通用涵義,并且與具體任務無關,是時又能根據具體任務,提供有用資訊
理解是針對任務的理解:字詞,關注區域資訊;句子篇章,關注文本的全域資訊

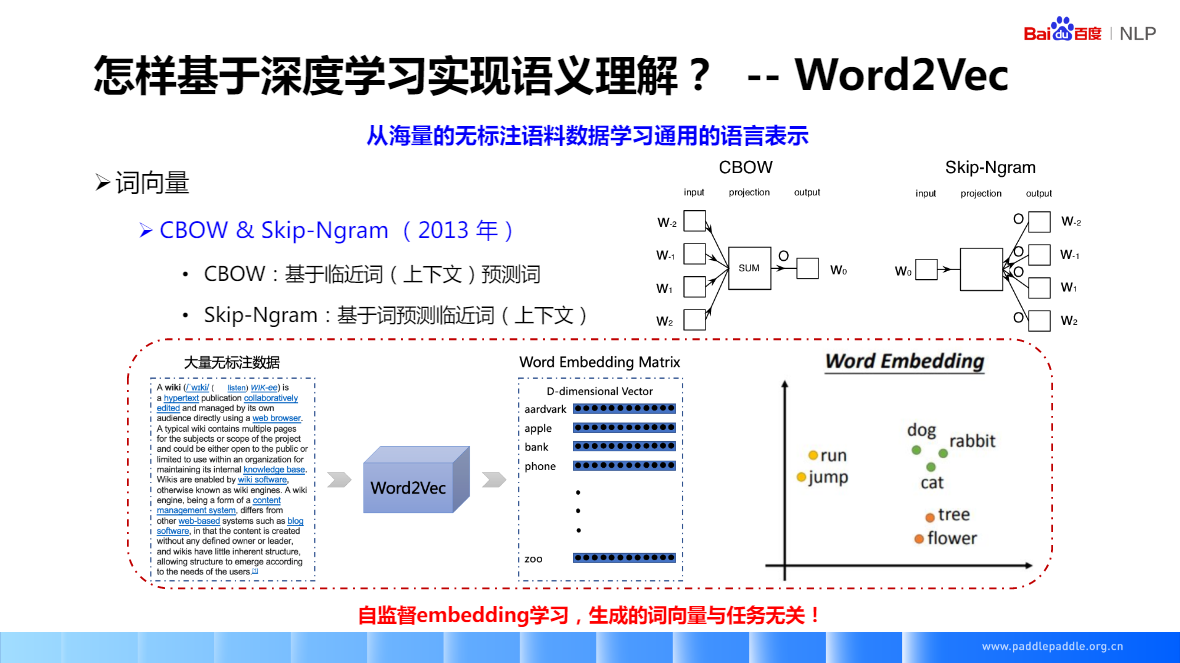
CBOW:基于臨近詞(背景關系)預測詞
Skip-Ngram:基于詞預測臨近詞(背景關系)





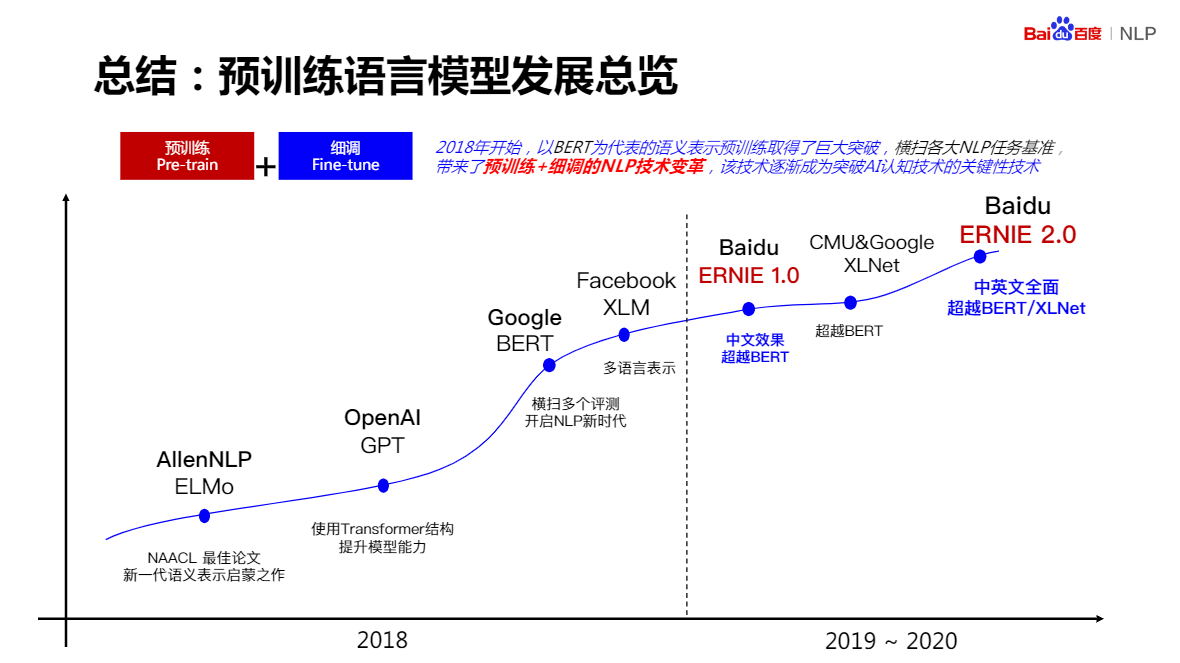
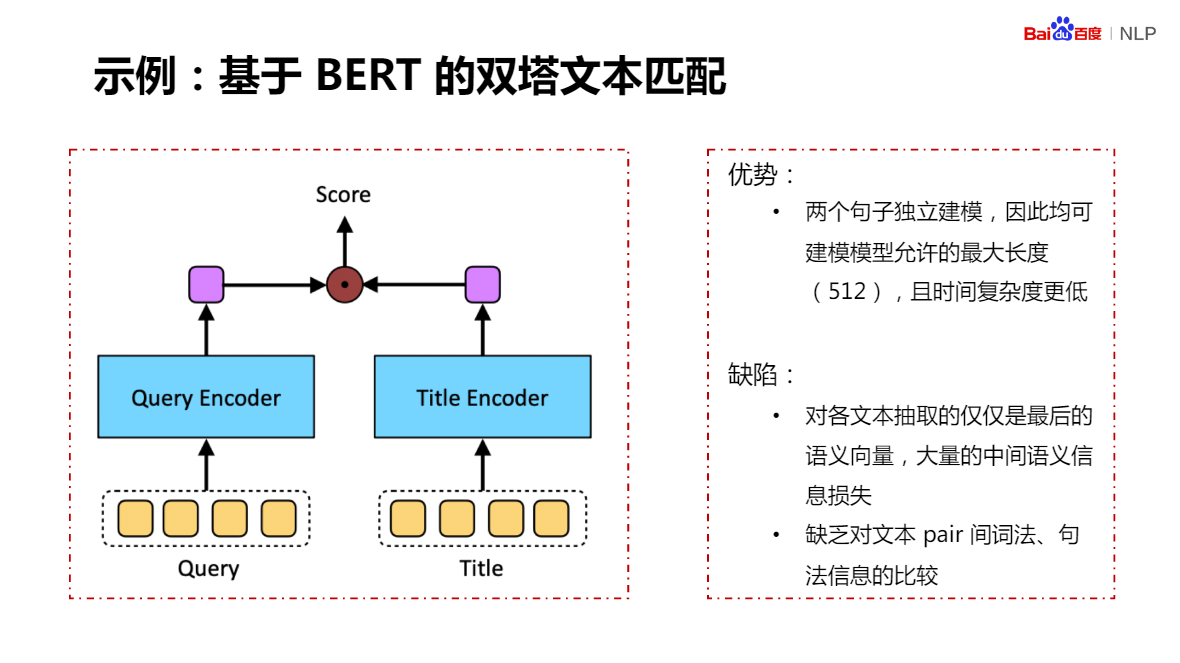
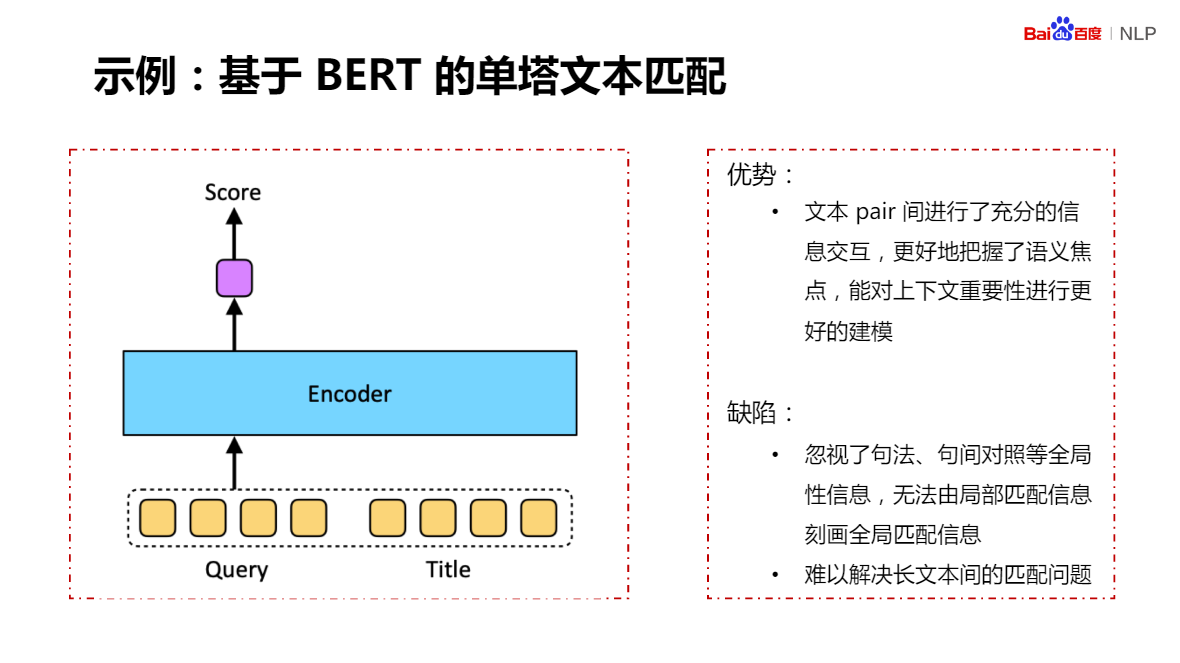
基于預訓練的語意理解技術
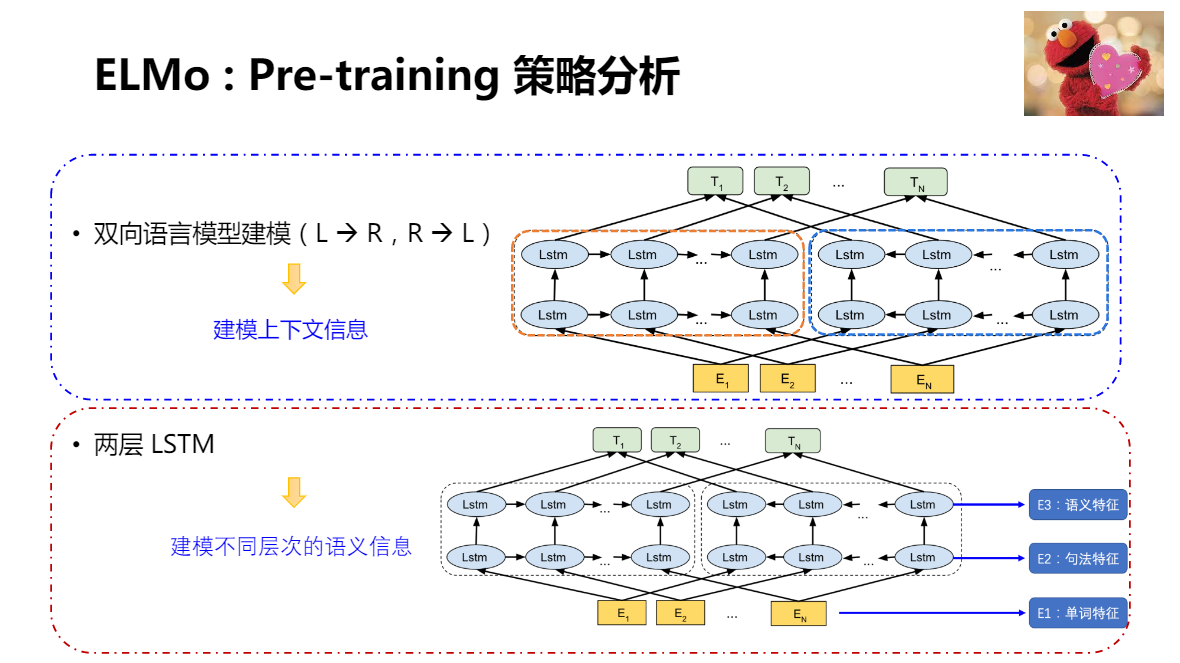
ELMo:第一個現代的語意理解模型
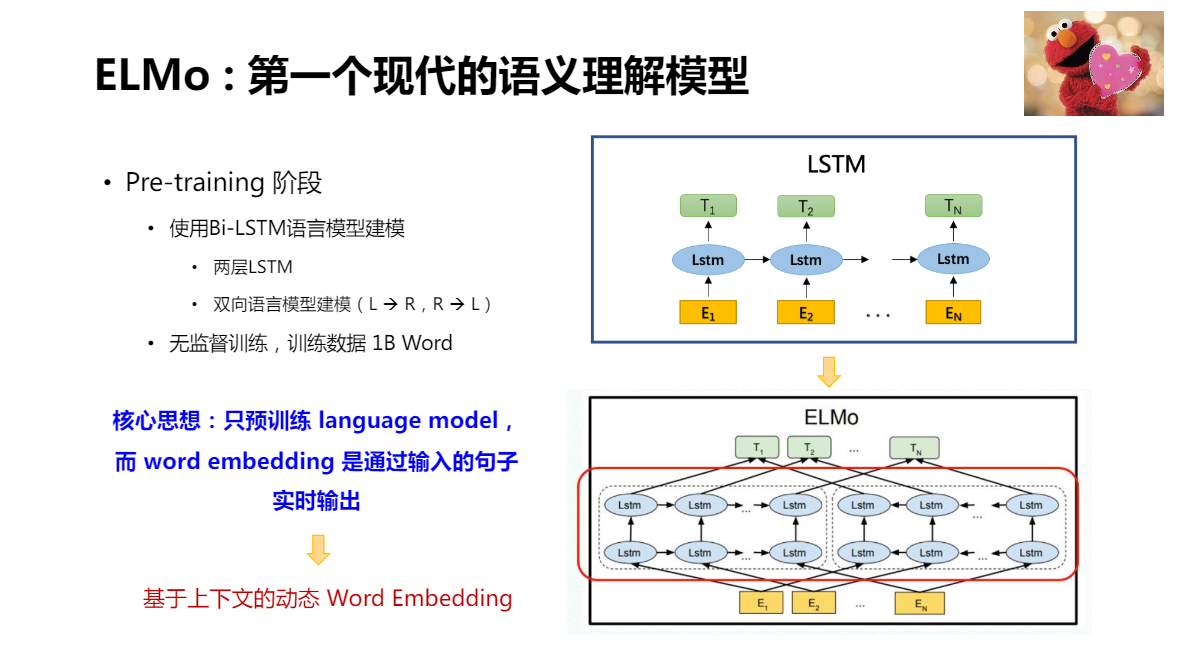
利用兩個LSTM,分別從左到右,從右到左的語言模型建模,實作建模背景關系資訊的目的,
兩層LSTM:從低層到高層,逐個獲取不同層次的語言資訊,從最低層單詞特征,到最高層語文特征
在獲取了預訓練模型特征以后,如何應用到具體的任務中,
ELMo:采用了 Feature-Based 方式進行應用
加權相加引數 \(a_1、a_2、a_3\) 是可學習的,這是實作動態 Word Embedding 關鍵所在
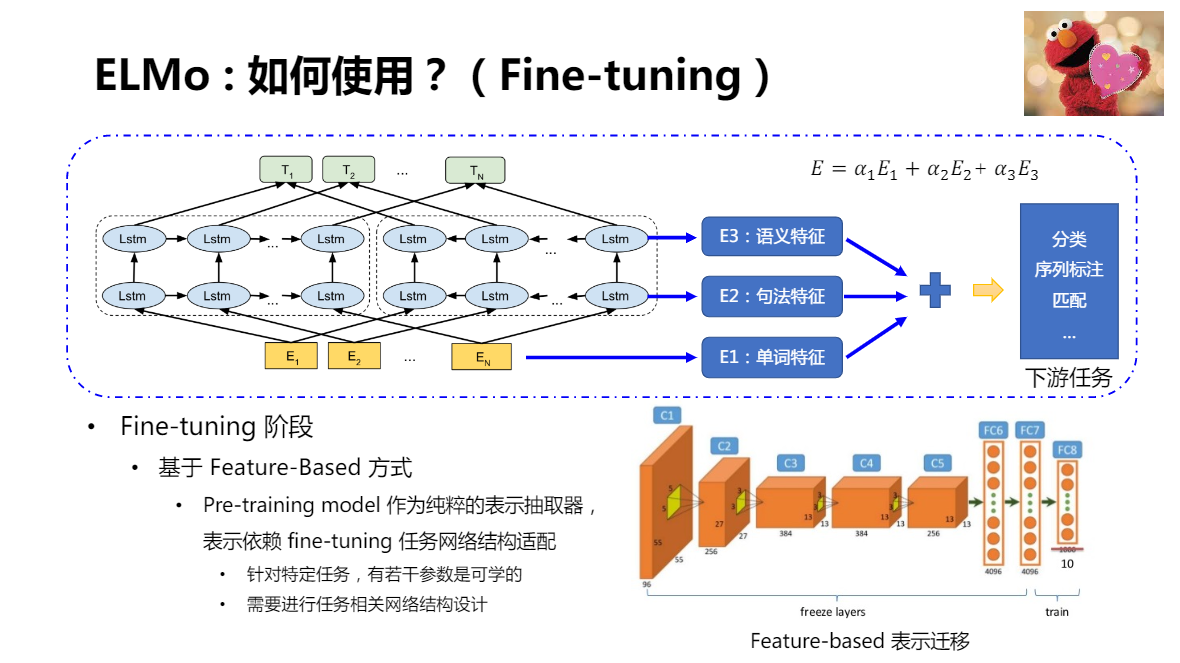
ELMo 不僅解決了多義詞的問題,而且可以將詞性對應起來

ELMo:有什么缺點?
-
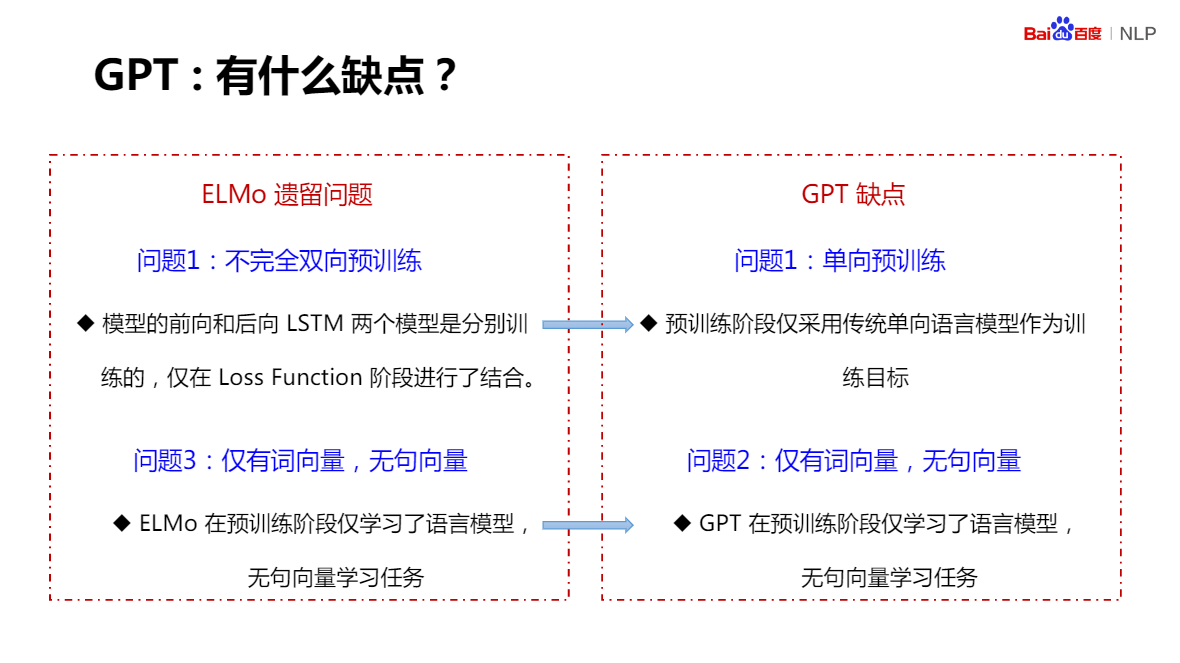
問題1:不完全雙向預訓練
模型的前向和后向LSTM兩個模型是分別訓練的,僅在Loss Function階段進行了結合, -
問題2:需進行任務相關網路結構設計(GPT可解決網格設計問題)
每種型別的下游任務都需要進行特定的網路結構設計和搭建 -
問題3:僅有詞向量,無句向量
ELMo在預訓練階段僅學習了語言模型,無句向量學習任務
GPT:被BERT光芒掩蓋的作業
對BERT的誕生,起到了非常明顯的推動作用
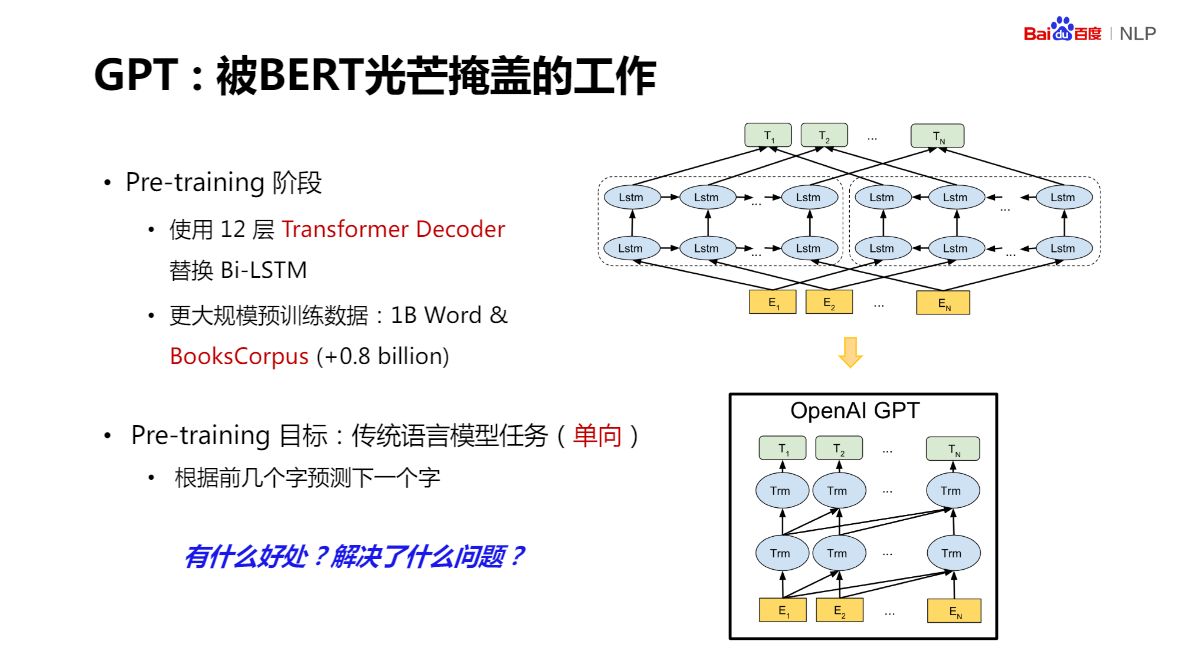
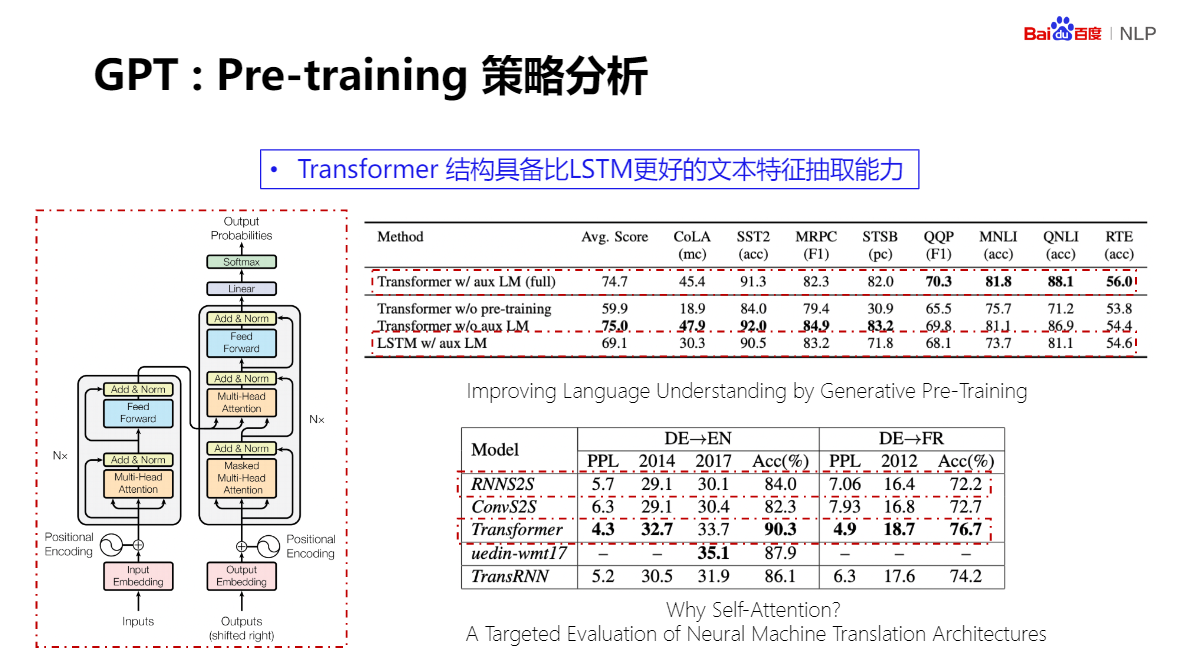
Pre-training 作為 下游任務的一部分參與任務學習,大量減少下游任務網路中新增引數的數量,同時,下游任務的網路,相比較預訓練網路,也只有少量結構上的變動,這樣會節省大量時間
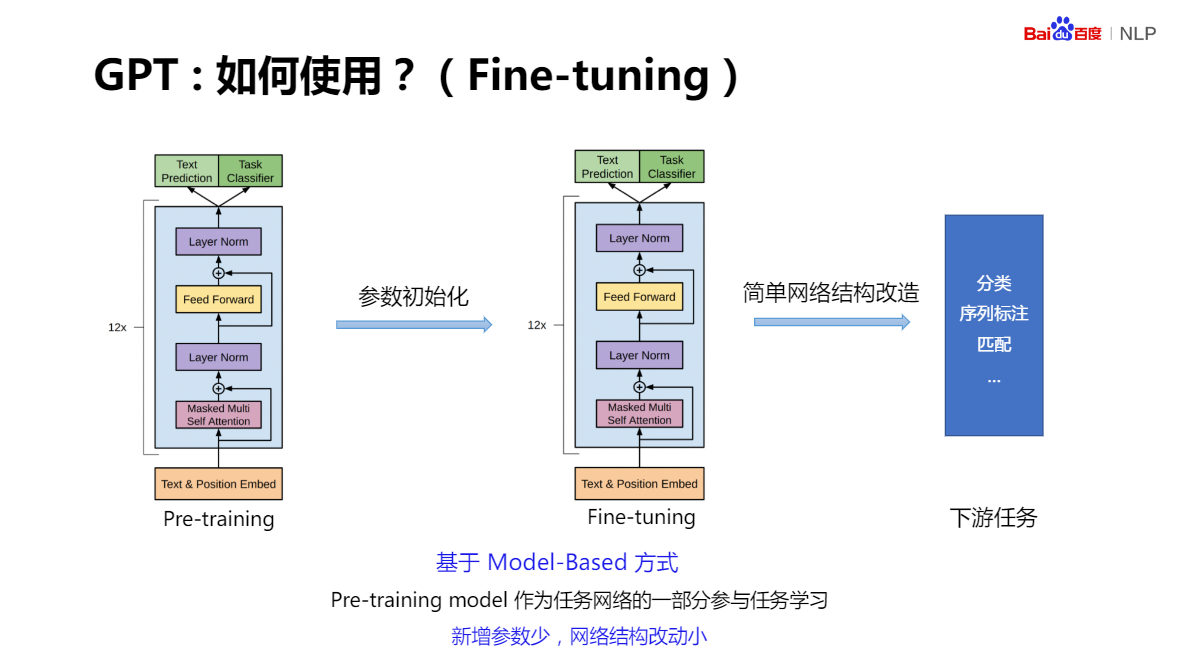
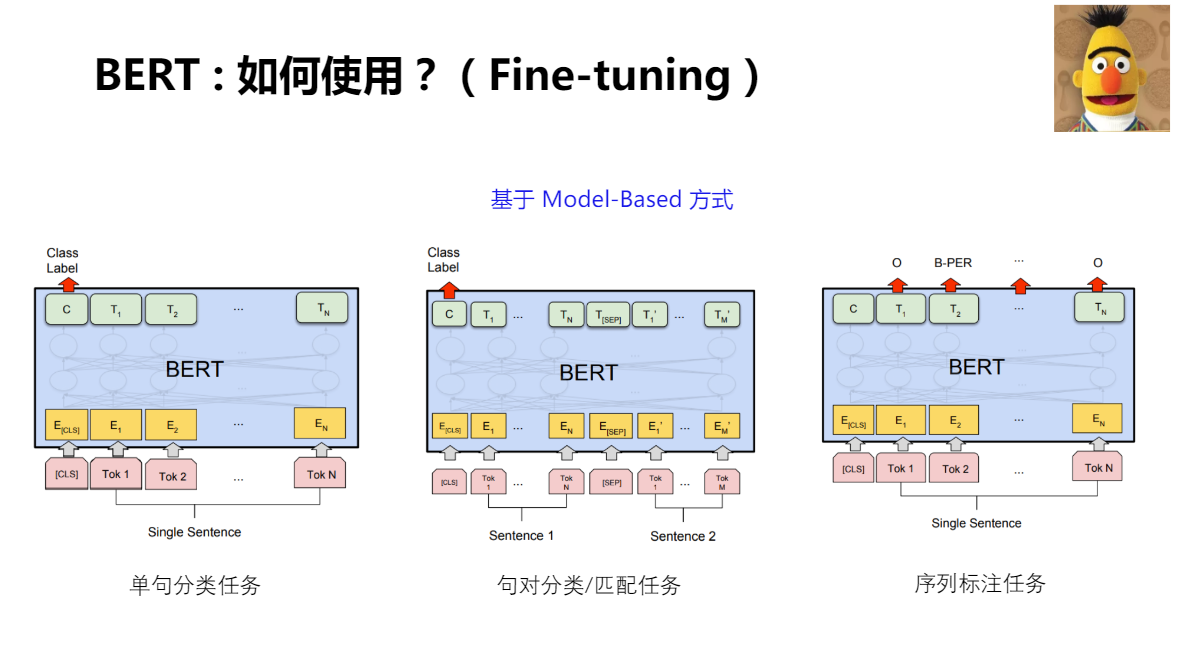
對于分類任務:模型只需要在輸入文本上加上起始(Start)和終結(Extract)的符號,并在網路后端新增一個分類器(FC),
對于句子判斷:如語言識別,兩個句子中增加分隔符就可以了,
對于文本相似度判斷、多項選擇:只需要少量改動,就能實作 Fine-Tuning 程序
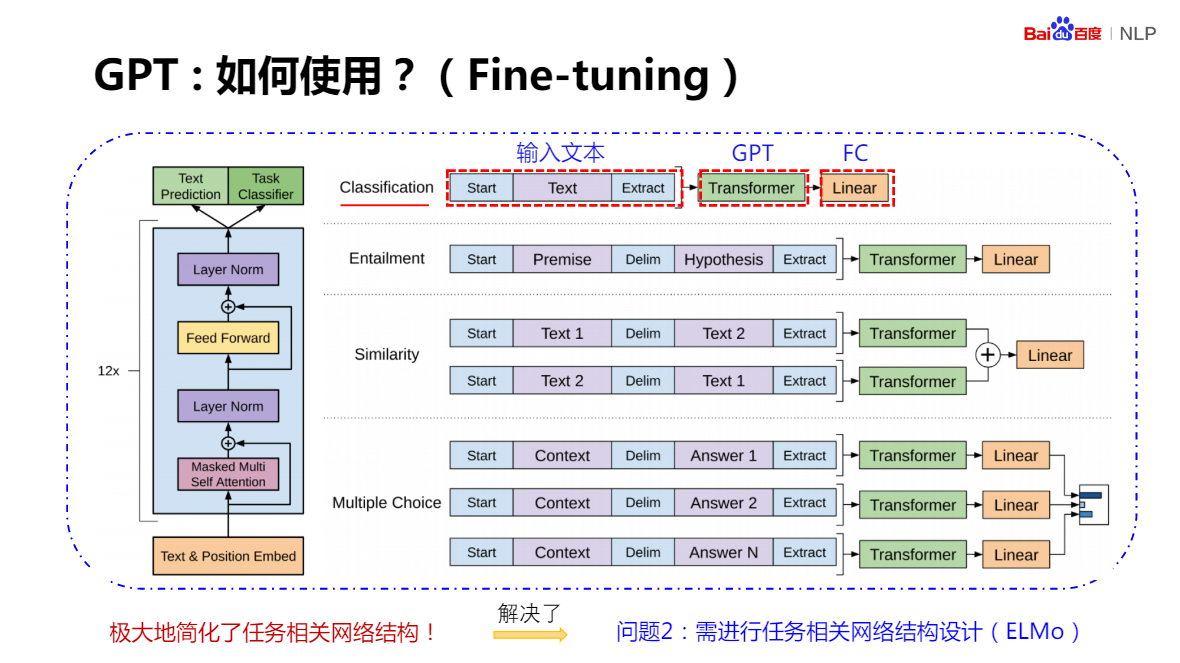
GPT
優點:帶來了明顯的效果提升,也極大的簡化了任務網路相關的結構
缺點:
- 單向預訓練
預訓練階段僅采用傳統單向語言模型作為訓練目標 - 僅有詞向量,無句向量
GPT在預訓練階段僅學習了語言模型,無句向量學習任務
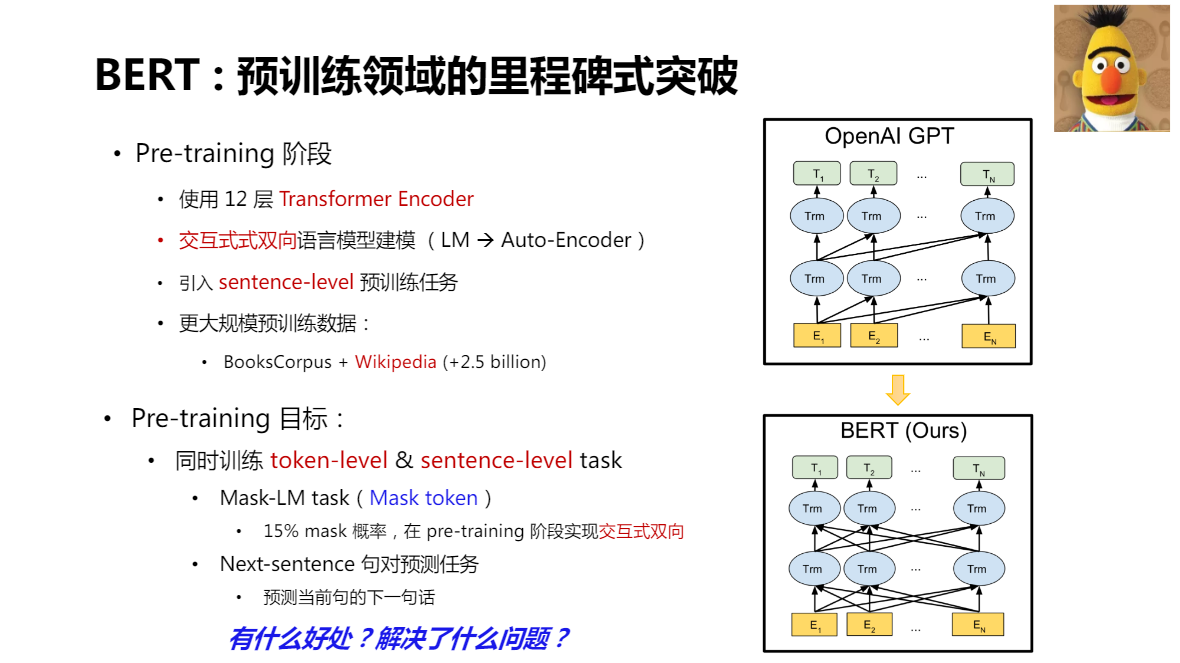
BERT:預訓練領域的里程碑式突破
Pre-training階段
- 延用了GPT 網路結構,使用了12層 Transformer Encoder
- 互動式式雙向語言模型建模(LM -> Auto-Encoder)
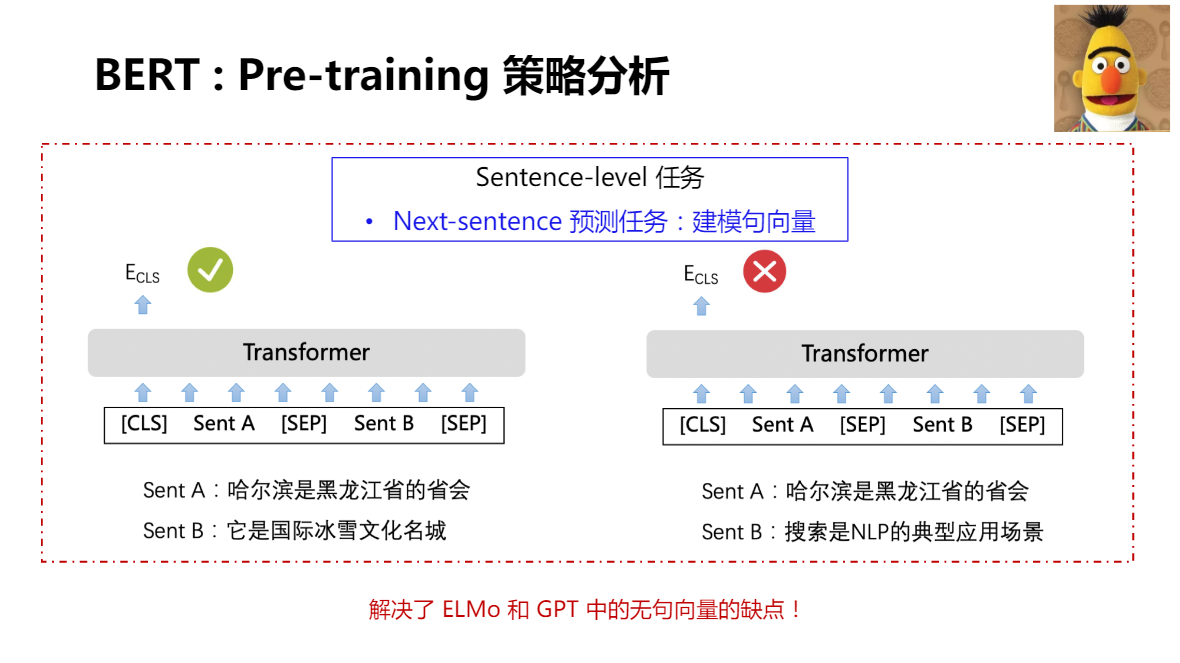
- 引入sentence-level預訓練任務
- 更大規模預訓練資料:BooksCorpus + Wikipedia(+2.5billion)
Pre-training 目標:
同時訓練token-level & sentence-leveltask
- Mask-LM task(Mask token)
15% mask概率,在pre-training階段實作互動式雙向 - Next-sentence句對預測任務
預測當前句的下一句話
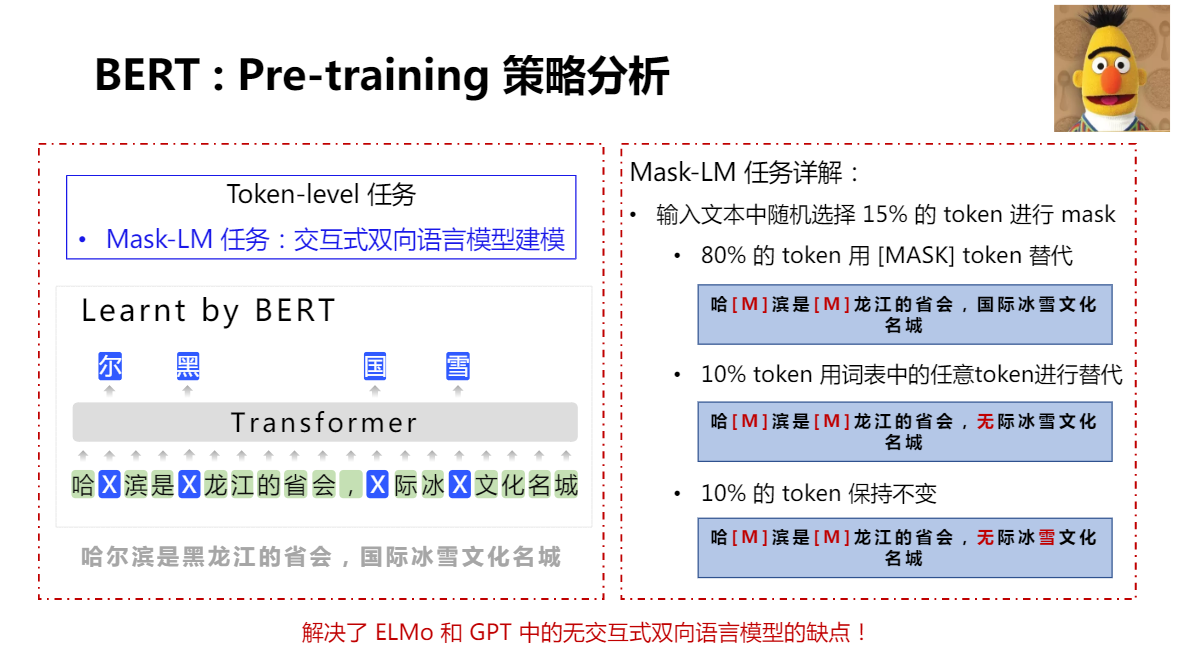
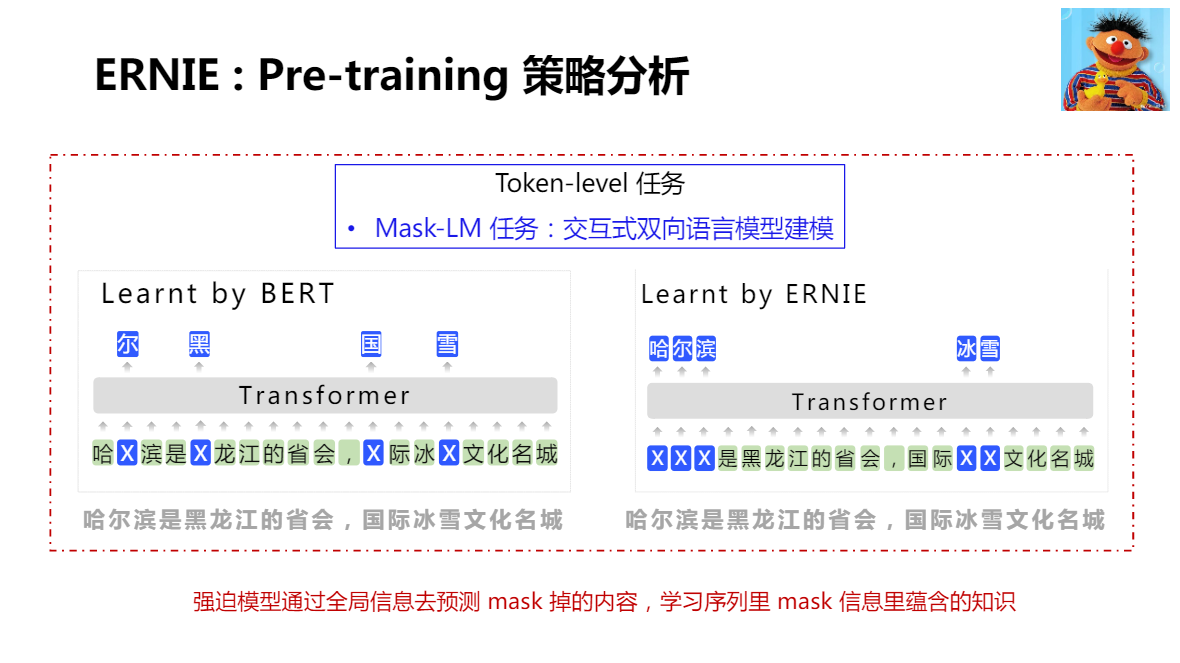
BERT:Pre-training 策略分析
BERT Mast-LM ,Mask 力度是 Token(單個字)
BERT 如何將自己的預訓練模型,應用到下游任務?使用了簡單粗暴的方式:偽結果論

BERT缺點
BERTmask(sub-word)lm任務存在的問題:
- Word哈爾濱;sub-word哈##爾##濱
- Sub-word預測可以通過word的區域資訊完成
- 模型缺乏全域建模資訊的“動力”
難以學到詞、短語、物體的完整語意

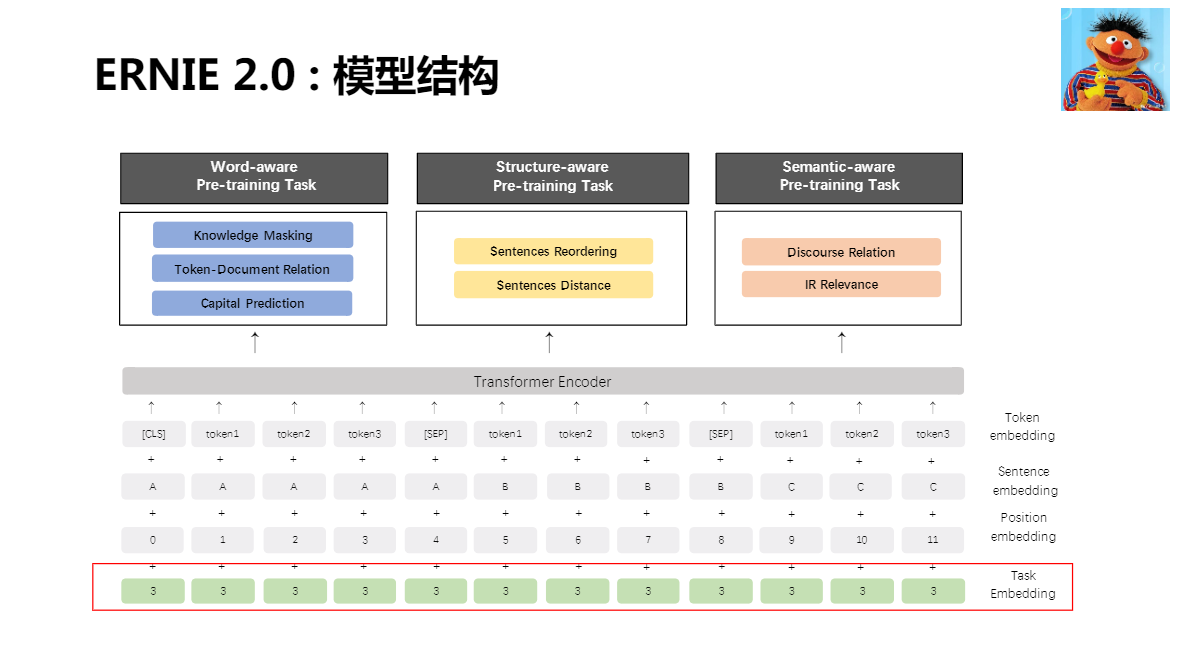
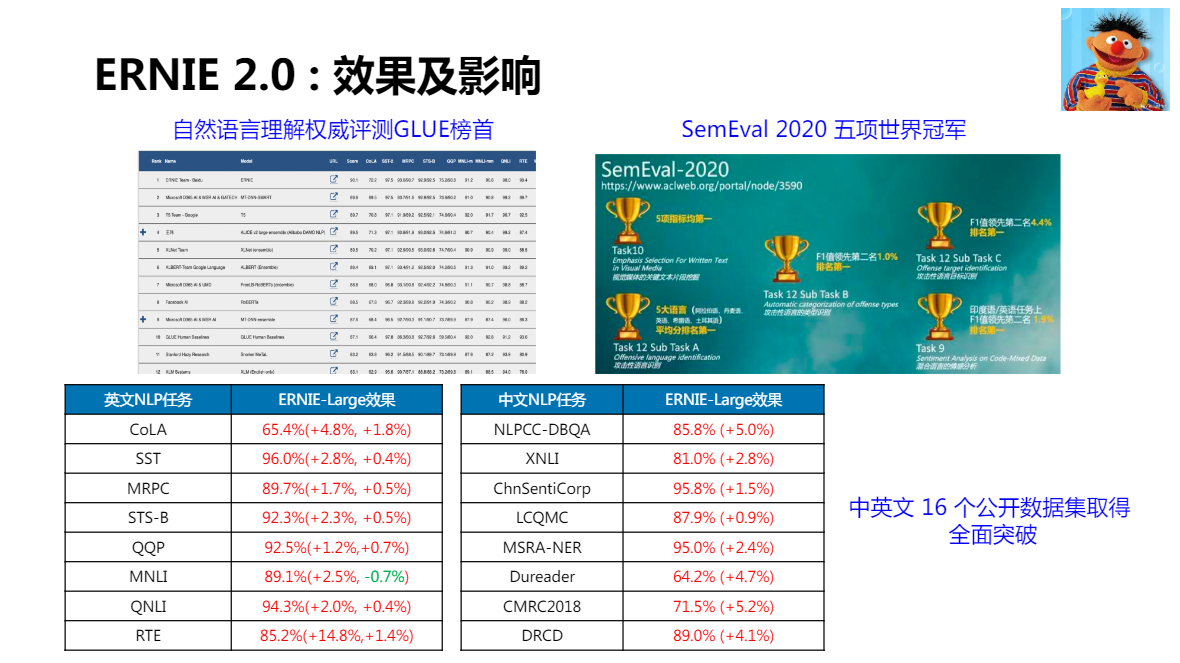
ERNIE:基于知識增強的語意理解模型(百度)
將token 力度擴展到了 word 或 entity,使用了百度自建的語意庫
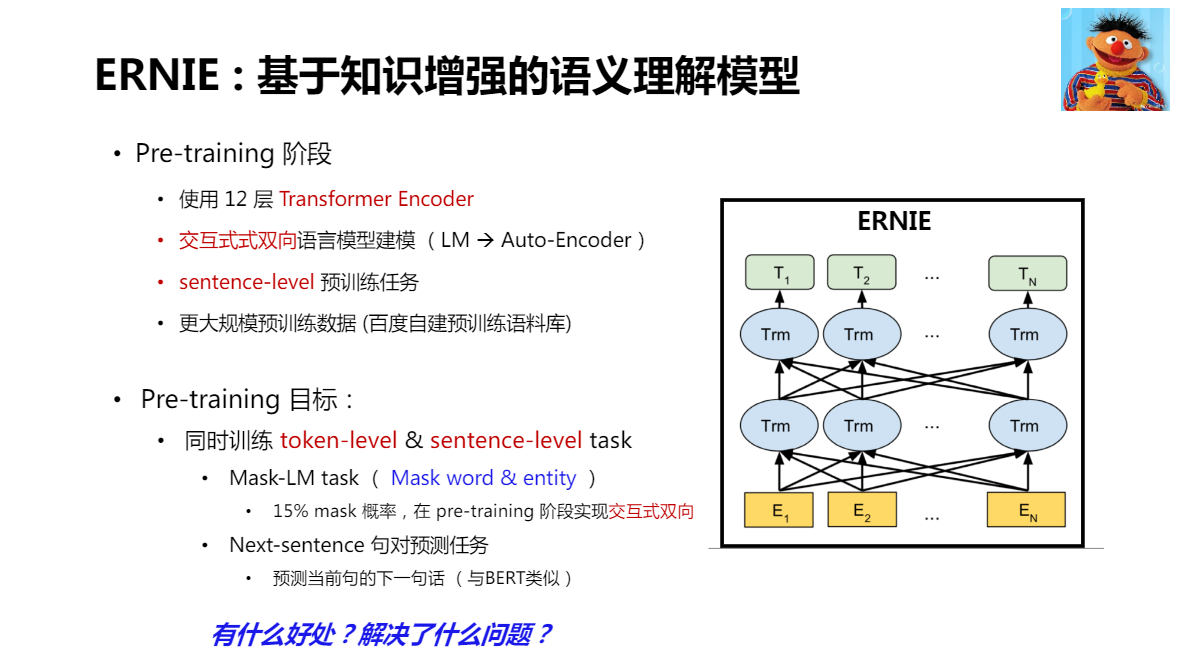
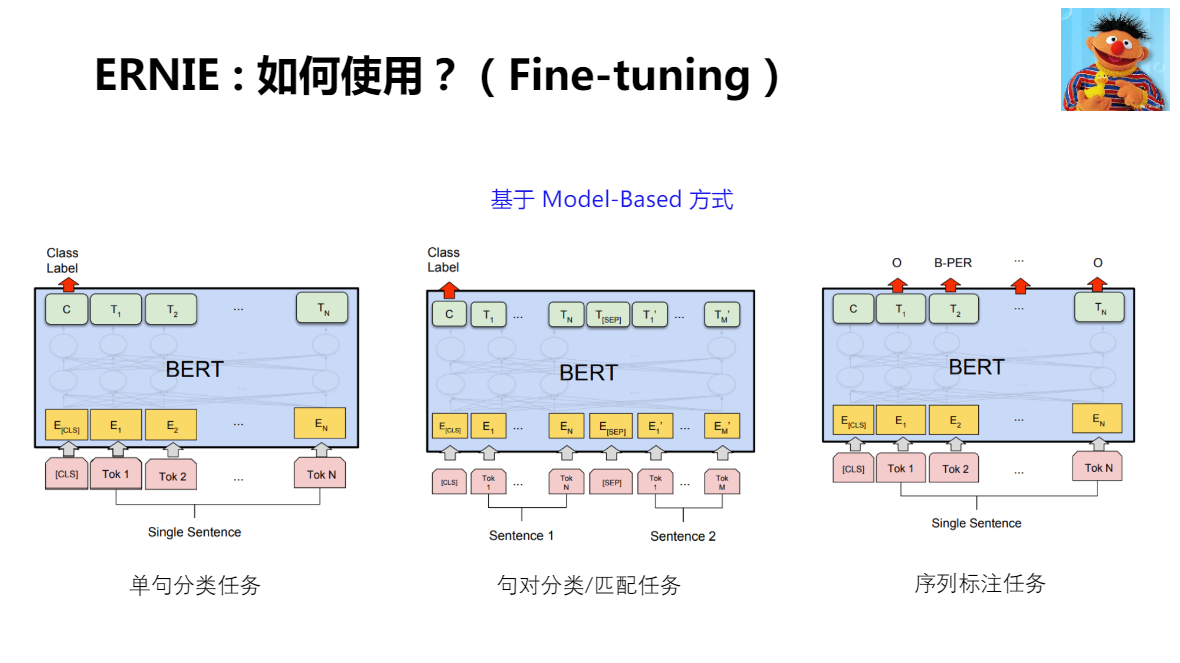
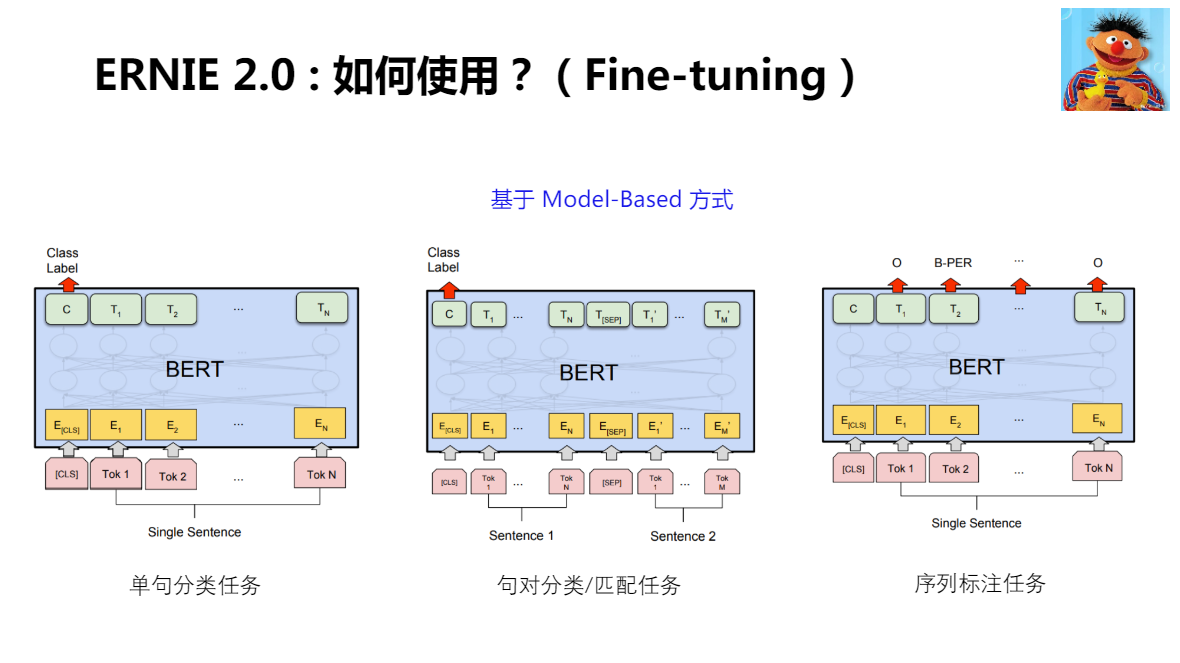
ERNIE 在 Fine-tuning 使用了和 BERT 完全一致的方式


2.0 在預訓練階段,引入了更多的預訓練任務
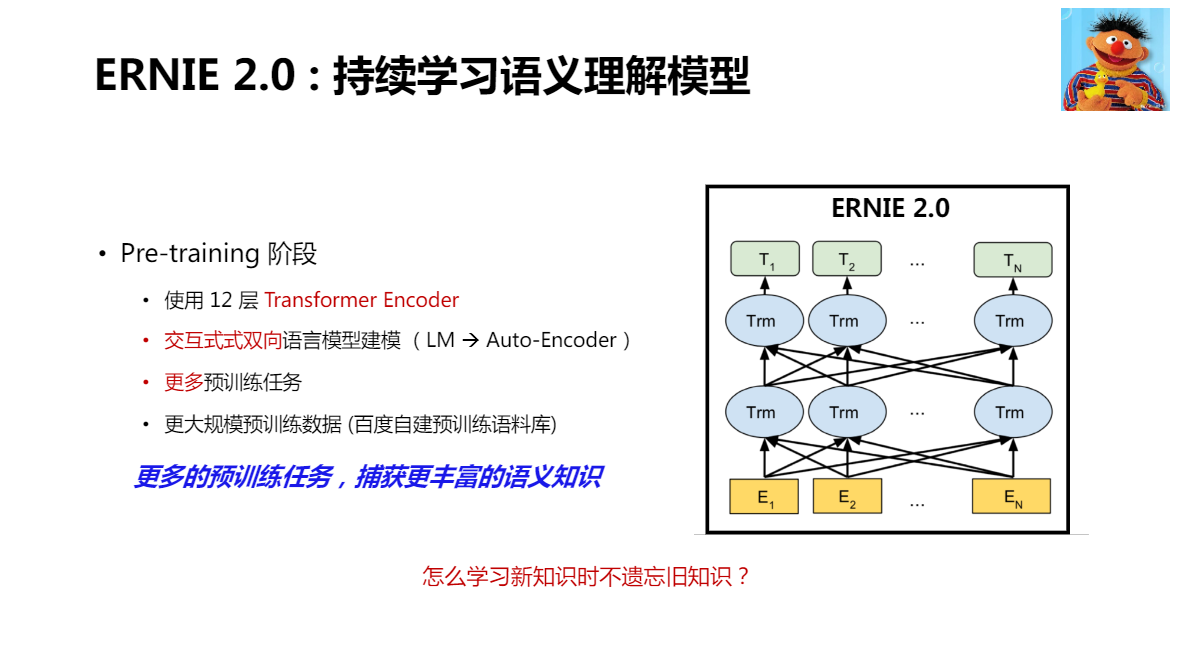
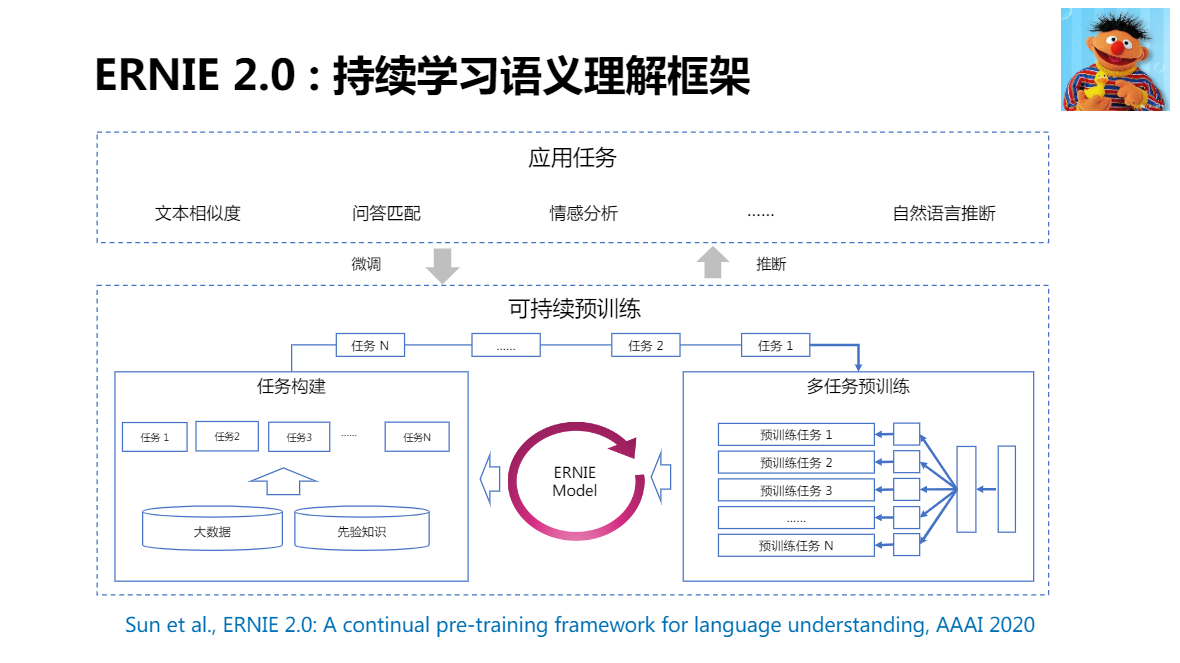
如何在學習新知識的同時,不忘舊知識
在預訓練階段,不斷進行任務的疊加訓練

預訓練模型在NLP經典任務的應用
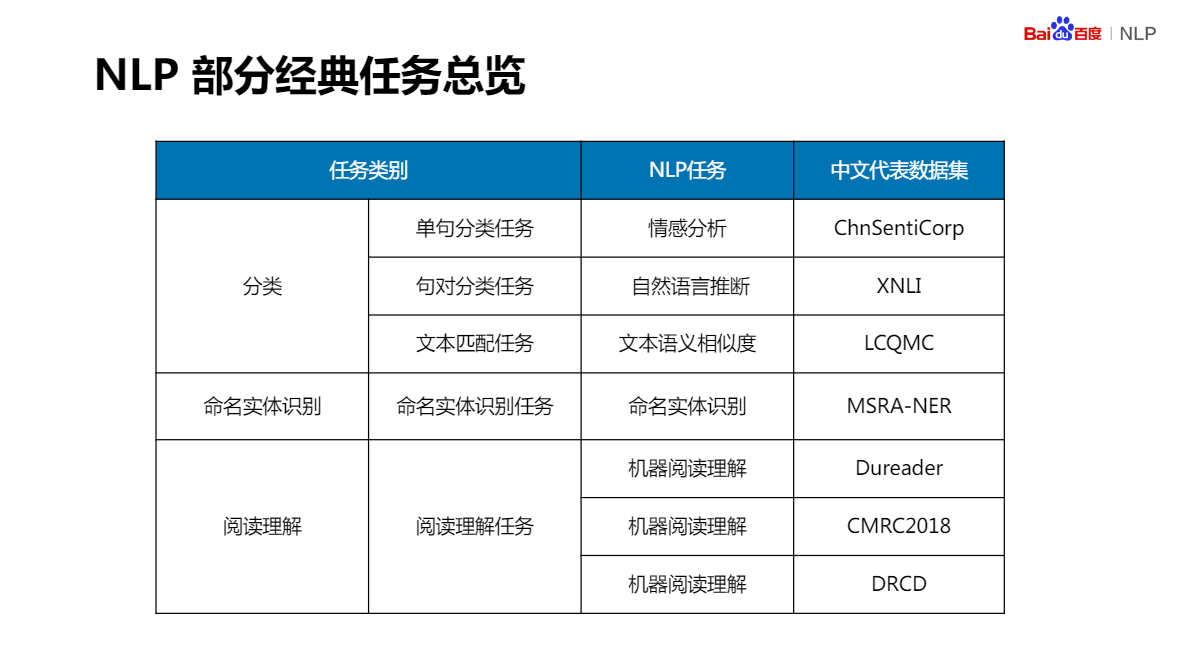
NLP部分經典任務總覽
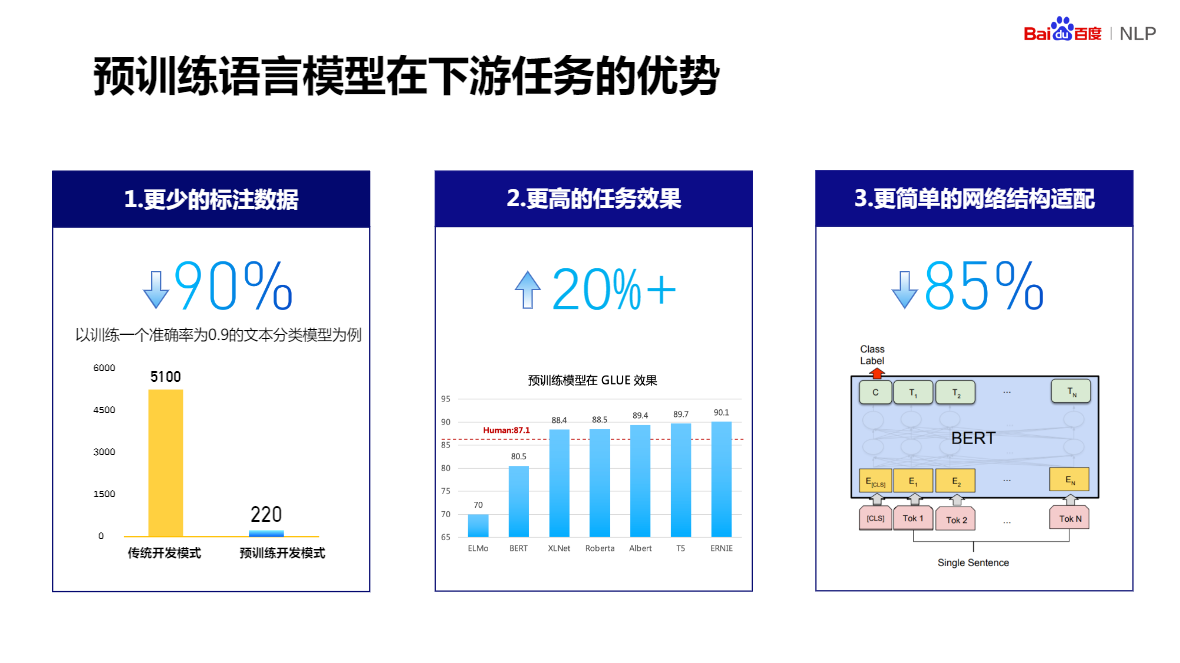
預訓練語言模型在下游任務的優勢
- 更少的標注資料
- 更高的任務效果
- 更簡單的網路結構適配
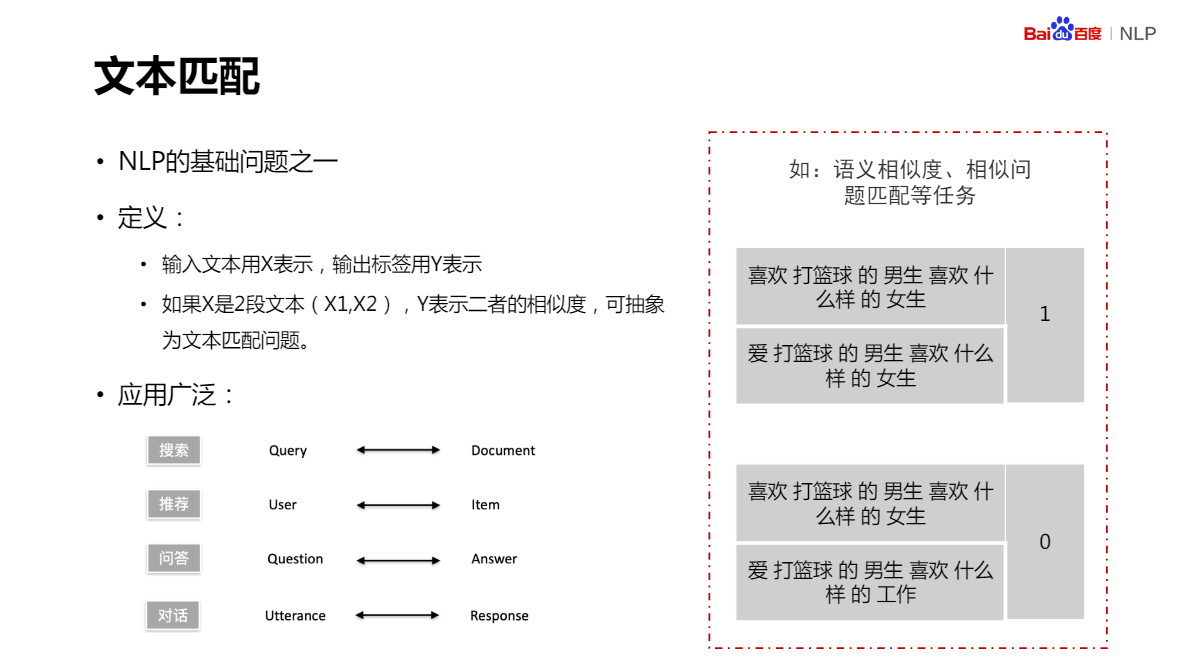
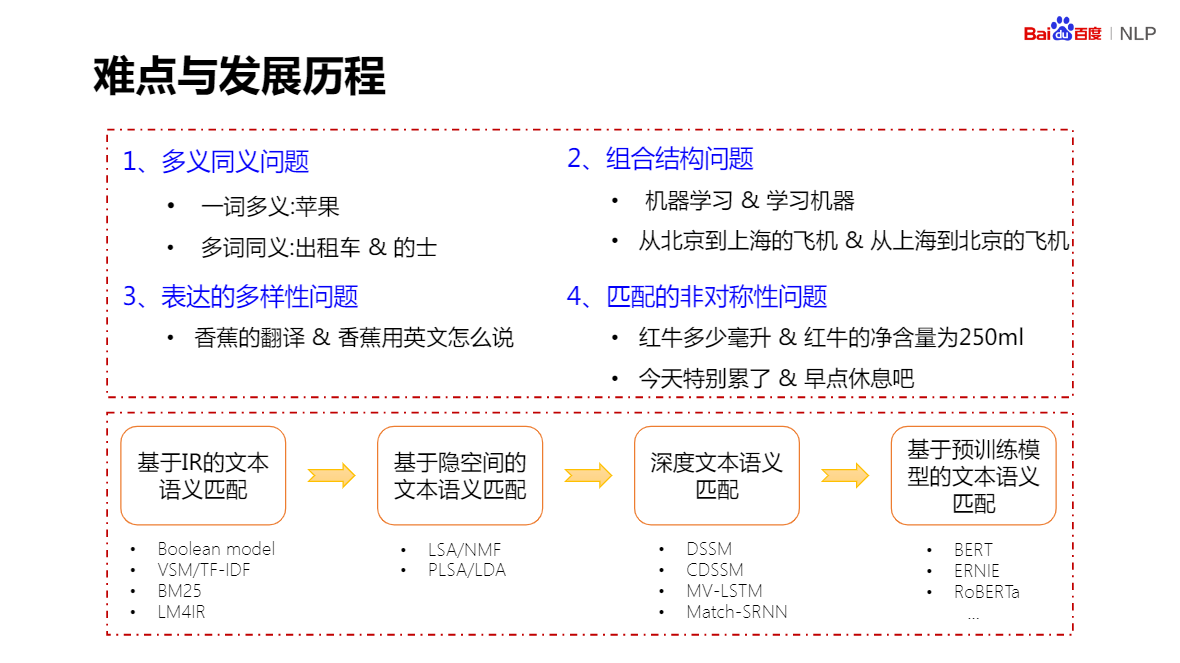
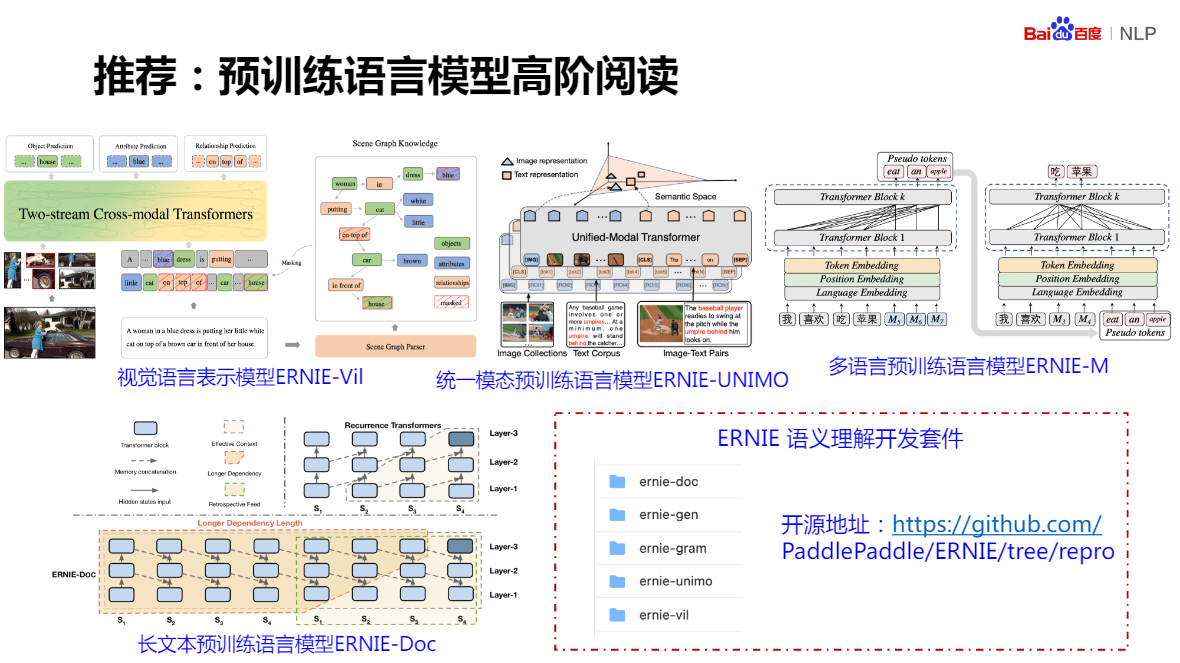
預訓練模型,不是越大越好
預訓練模型,如何達到收斂的狀態?一直是一個難以界定的范圍,越訓越大,很難做到預訓練充分的結果,目前常規采取的方式是,讓它一直訓著,抽取實時對預訓練模型中產生的中間模型,進行一個具體任務驗證,隨時采取一個文本匹配任務進行 Fine-Tuning 驗證,如果預訓練后期,發現了在很長一段時間內,在這樣一個驗證的下游任務上,得到的 Fine-Tuning 結果,基本持平,我們就認為這個模型達到了一個收斂的狀態,或者說區域收斂的狀態,這時候就可以給它停下來了,沒有一個特別規范的指標
原文:https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1455657&sharedType=2&sharedUserId=2631487&ts=1685934903156
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555090.html
標籤:其他
上一篇:刻苦學習aws資料總結
下一篇:返回列表