編譯程式是一種翻譯程式,編譯程式是將一種語言形式翻譯成另一種語言形式,它將高級語言所寫的源程式翻譯成等價的機器語言或匯編語言的目標程式,
整個編譯程序一般可以劃分為 5 個階段:詞法分析、語法分析、語意分析及中間代碼生成、中間代碼優化和目標代碼生成,我們以一個簡單的程式段為例,分別介紹這 5 個階段所完成的任務,例如,計算圓柱體表面積的程式段如下:
float r,h,s;
s = 2 * 3.1416 * r * (h + r);
詞法分析
詞法分析階段的任務是對構成源程式的字串進行從左到右的掃描和分解,根據語言的詞法規則,識別出一個一個具有獨立意義的單詞(也稱單詞符號,簡稱符號),
語言的詞法規則是單詞符號的形成規則,它規定了哪些字串構成一個單詞符號,上述源程式通過詞法分析,根據語言的詞法規則識別出如下單詞符號:
- 基本字(關鍵字) float
- 識別符號 r,h,s
- 常數 3.1416,2
- 運算子 *,+
- 界符 () ; ,
單詞符號的型別有:關鍵字、識別符號、常數、運算子、界符,
語法分析
語法分析的任務是在詞法分析的基礎上,根據語言的語法規則,從單詞符號串中識別出各種語法單位(如運算式、說明、 陳述句等)并進行語法檢查,即檢查各種語法單位在語法結構上的正確性,
語言的語法規則是語法單位的形成規則,它規定了如何從單詞符號形成語法單位,上述源程式通過語法分析,根據語言的語法規則識別單詞符號串 s = 2 * 3.1416 * r * (h + r),其中 s 是 <變數>,單詞符號串 2 * 3.1416 * r * (h + r) 組合成 <運算式 > 這樣的語法單位, 則由 <變數> = <運算式> 構成 <賦值陳述句> 這樣的語法單位,在識別各類語法單位的同時進行語法檢查,可以看到上述源程式是一個語法上正確的程式,
語意分析及中間代碼生成
定義一種語言除了要求定義語法外,還要求定義其語意,即對語言的各種語法單位賦予具體的意義,
語意分析的任務是首先對每種語法單位進行靜態的語意審查,然后分析其含義,并用另一種語言形式(比源語言更接近于目標語言的一種中間代碼或直接用目標語言)來描述這種語意,例如,上述源程式中,賦值陳述句的語意為:計算賦值號右邊運算式的值,并把它送到賦值號左邊的變數所確定的記憶體單元中,語意分析時,先檢查賦值號右邊運算式和左邊變數的型別是否一致,然后再根據賦值陳述句的語意,對它進行翻譯可得到如下形式的四元式中間代碼:
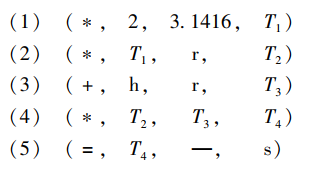
其中,T1、T2、T3、T4 是編譯程式引進的臨時變數,存放每條指令的運算結果,上述每一個四元式所表示的語意為:

這樣,我們將源語言形式的賦值陳述句翻譯為四元式表示的另一種語言形式,這兩種語言在結構形式上是不同的,但在語意上是等價的,
中間代碼優化
中間代碼優化的任務是對前階段產生的中間代碼進行等價變換或改造,以期獲得更為高效的,節省時間和空間的目標代碼,優化主要包括區域優化和回圈優化等,例如上述四元式經區域優化后得:
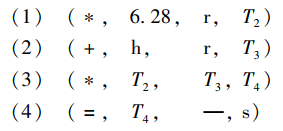
其中,2 和 3.1416 兩個運算物件都是編譯時的已知量,在編譯時就可計算出它的值 6.28,而不必等到程式運行時再計算,即不必生成(*,2,3.1416,T1)的運算指令,
目標代碼生成
目標代碼生成的任務是將中間代碼變換成特定機器上的絕對指令代碼或可重定位的指令代碼或匯編指令代碼,
表格管理 & 錯誤處理
在編譯程式的各個階段中,都要涉及表格管理和錯誤處理,
編譯程式的重要功能之一,是記錄源程式中所使用的變數的名字,并且收集與名字屬性相關的各種資訊,名字屬性包括一個名字的存盤分配、型別、作用域等資訊,如果名字是一個函式名,還會包括其引數數量、型別、引數的傳遞方式以及回傳型別等資訊,符號表資料結構可以為變數名字創建記錄條目,來登記源程式中所提供的或在編譯程序中所產生的這些資訊,編譯程式在作業程序的各個階段需要構造、查找、修改或存取有關表格中的資訊,因此在編譯程式中必須有一組管理各種表格的程式,
如果編譯程式只處理正確的程式,那么它的設計和實作將會大大簡化,但是程式設計人員還期望編譯程式能夠幫助定位和跟蹤錯誤,無論程式員如何努力,程式中難免總會有錯誤出現,雖然錯誤很常見,但很少有語言在設計的時候就考慮到錯誤處理問題,大部分程式設計語言的規范沒有規定編譯程式應該如何處理錯誤;錯誤處理方法由編譯程式的設計者決定, 因此,從一開始就計劃好如何進行錯誤處理,不僅可以簡化編譯程式的結構,還可以改進錯誤處理方法,一個好的編譯程式在編譯程序中, 應具有廣泛的程式查錯能力,并能準確地報告錯誤的種類及出錯位置,以便用戶查找和糾正,因此在編譯程式中還必須有一個出錯處理程式,
編譯程式
編譯程序的這 5 個階段的任務分別由 5 個程式完成,這 5 個程式分別稱為詞法分析程式、語法分析程式、語意分析及中間
代碼生成程式、中間代碼優化程式和目標代碼生成程式,另外再加上表格管理程式和出錯處理程式,這些程式便是編譯程
序的主要組成部分,一個典型編譯程式的結構框圖如圖所示,
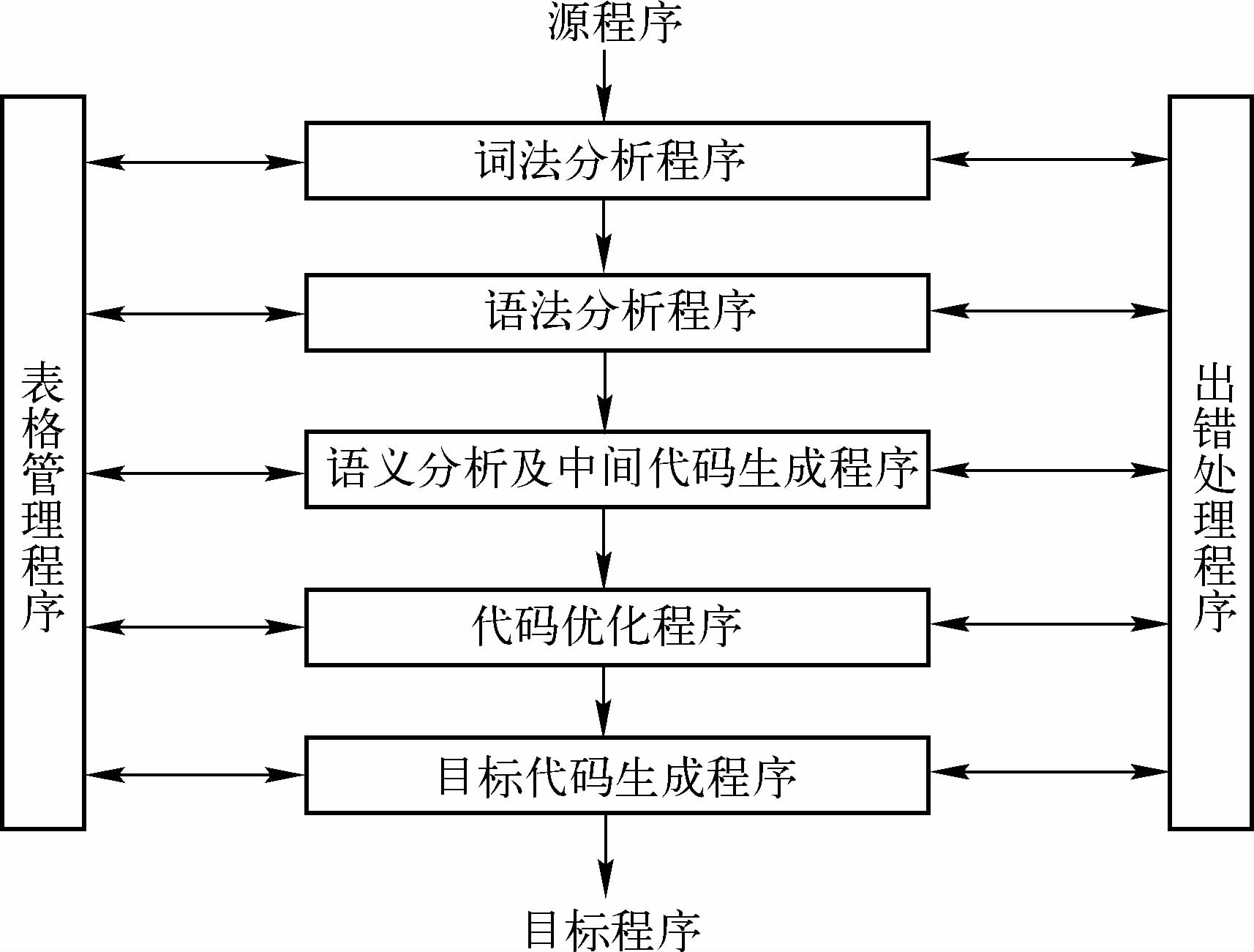
需要注意的是,圖中所給出的各個階段之間的關系是指它們之間的邏輯關系,不一定是執行時間上的先后關系,實際
上,可按不同的執行流程來組織上述各階段的作業,這在很大程度上依賴于編譯程序中對源程式掃描的遍數以及如何劃分各遍掃描所進行的作業,
此處所說的 “遍”,是指對源程式或其等價的中間語言程式從頭到尾掃描一遍,并完成規定加工處理作業的程序,例如,可以將前述 5 個階段的作業結合在一起,對源程式從頭到尾掃描一遍來完成編譯的各項作業,這種編譯程式稱為一遍掃描的編譯程式,對于某些程式設計語言,用一遍掃描的編譯程式去實作比較困難,可采用多遍掃描的編譯程式結構,每遍可完成上述某個階段的一部分、全部或多個階段的作業,且每一遍的作業是從前一遍獲得的作業結果開始的,最后一遍的作業結果是目標語言程式,第一遍的輸入則是用戶書寫的源程式,
多遍掃描的編譯程式較一遍掃描的編譯程式少占存盤空間,遍數多一些,可使各遍所要完成的功能獨立而單純,其編譯程式邏輯結構清晰,但遍數多勢必增加輸入輸出開銷,這將降低編譯效率,一個編譯程式究竟應分成幾遍和它所面臨的源語言的特征、機器規模、設計的目標等因素有關,很難統一劃定,一般在主存可能的前提下,還是遍數少一點為好,
參考資料
《編譯原理(第4版)》1.2 編譯程序和編譯程式的基本結構
本文來自博客園,作者:真正的飛魚,轉載請注明原文鏈接:https://www.cnblogs.com/feiyu2/p/17492776.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555648.html
標籤:其他
上一篇:Gamma:強大的AI制作PPT神器,用完再也回不去了!
下一篇:返回列表