隨著線上泛娛樂的興起,語聊房、在線 KTV 以及直播等場景在人們的日常生活中占據越來越重要的地位,用戶對于音質的要求也越來越高,因此超越傳統語音降噪演算法的 AI 降噪演算法應運而生,所以目前各大 RTC 廠商普遍使用 AI 技術進行降噪處理,使用 AI 降噪技術消除除人聲外的一切聲音,
但對于一些特殊場景,如在線 KTV、線上直播等聲卡場景,或者彈唱、伴奏、樂器等使用場景中,我們可以明顯的感受到,一般降噪處理或 AI 降噪處理的程序中會將音樂/伴奏誤識別為噪音,并進行降噪處理,給用戶帶來很不好的線上體驗,因此,在此類使用場景中用戶越來越不滿足于背景降噪,而是提出更高要求,那就是深度降噪的同時保留音樂的音質,為了滿足用戶消噪與音樂音質高保真的需求,ZEGO 即構科技自研了一套自適應降噪方案,能在音樂與非音樂場景中智能切換,既保證了無音樂場景下的語音的質量,又保留了音樂的高保真音質,
音樂場景降噪方案簡介
首先簡單了解一下即構音樂場景降噪的方案流程:
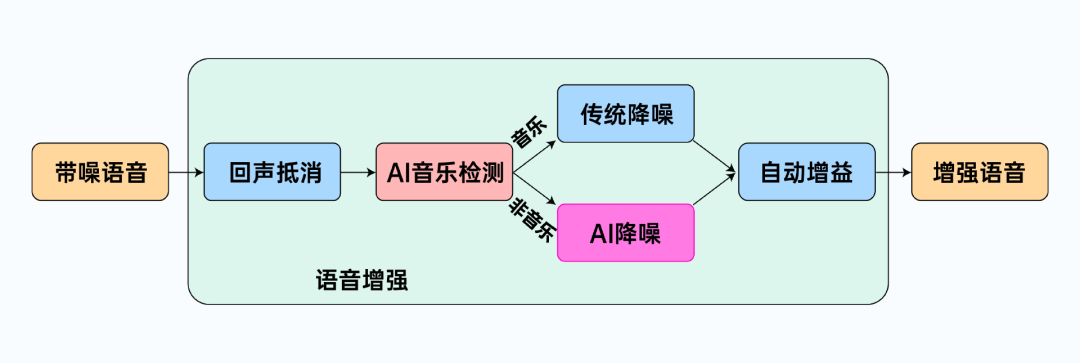
從圖中可以看到,經過前處理后的音頻資料會被送入 AI 音樂檢測模塊,接著根據檢測結果將場景分為音樂和非音樂場景,若檢測出音樂場景則會使用傳統降噪對音頻資料進行處理,以減少對音樂的損傷,非音樂場景則繼續使用 AI 降噪進行更深度的噪聲消除,最后資料會經過自動增益模塊完成最終的語音增強,
關于 AI 音樂檢測演算法
由上文描述中可以看到,完成音樂場景降噪功能最重要的一環就是 AI 音樂檢測演算法,為了滿足音樂場景的實時切換與極高檢測率的需求,我們自研了基于AI的音樂檢測演算法 ZegoAIMusicDetecion, 演算法流程如下:
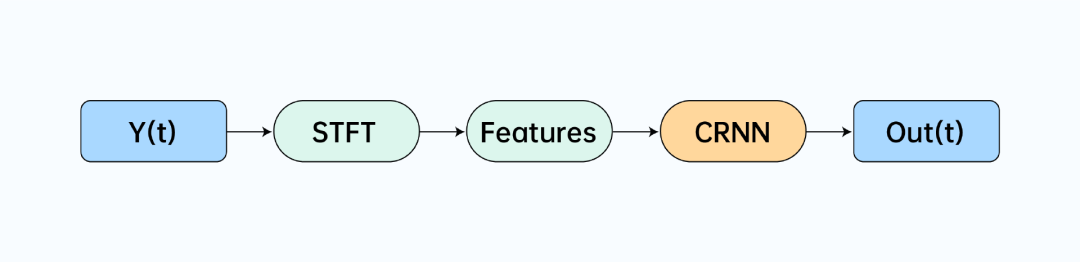
我們對資料進行幀長為 20ms,幀移為 10ms 的 STFT 處理后,使用 Bark 頻帶尺度將資料分為8 個子帶,再分別求取一階差分,二階差分和譜平坦度最終得到 25 維特征,將計算得到的特征送入到我們設計的輕量型網路模型 CRNN,模型結構如下:
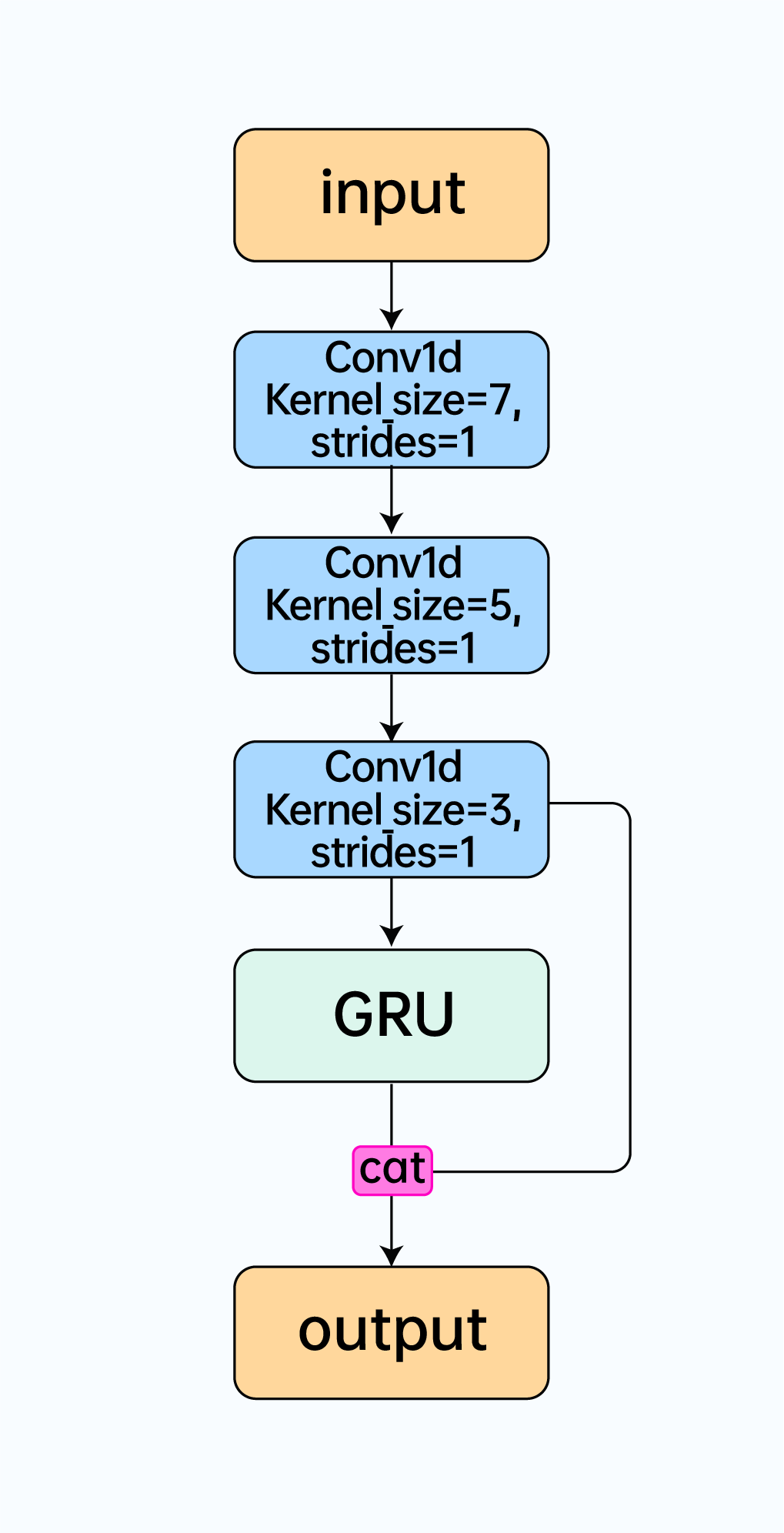
這里使用多層 Conv1d 卷積層能進一步的對特征進行提取,訓練時,我們搜集了大量的開源音樂、語音與噪聲資料進行訓練,同時使用不同信噪比進行資料混合增強,確保模型有足夠的泛化性,在訓練優化器上,我們選擇了 AdamW 以更好地對模型進行正則化處理,學習率為 0.001,批大小是 64,損失函式我們使用了交叉熵函式,公式如下:
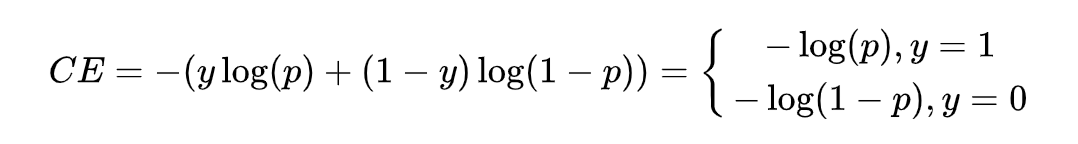
演算法效果與性能開銷
有了 AI 音樂檢測演算法的幫助,我們最終可以實作針對音樂場景的降噪方案,方案最終的效果如下:

從上面的頻譜圖以及實際的聽感來看,都可以直觀的感受到即構音樂場景降噪方案對音樂音質的保護,在提供良好效果的同時,ZegoAIMusicDetecion 秉承著極輕量級模型的設計理念,整體計算量大約為 1.2M FLOPS,RTF 指標在各個平臺和終端上均控制在 0.2% 以內,在此基礎上,我們采用多幀平滑的后處理技術使音樂檢測誤檢率低于 1%,音樂檢測率達到 95% 以上,
技術展望
音樂場景在泛娛樂社交和互動中十分常見,需要注重用戶和聽眾的使用感覺,做好音樂場景降噪處理,綜上所述,ZEGO 即構科技為了同時兼顧降噪與音樂音質體驗,自研了基于 AI 的音樂檢測演算法(點這里),設計出一套音樂場景降噪方案,充分體現即構對于用戶良好體驗的高度重視,
未來,我們會結合具體行業和場景,引入更多的可行性方案,提升產品的場景適應能力,給用戶提供更好的音頻體驗!了解更多ZEGO即構IM即時通訊服務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555764.html
標籤:其他
上一篇:即視角|出海正當時:歐美、東南亞、中東、拉美市場觀察
下一篇:返回列表