
uj5u.com熱心網友回復:
如果Spark沒有對資料做處理, 為什么不直接MySQL主從同步,在從庫上做統計分析?uj5u.com熱心網友回復:
1.資料量未來肯定會越來越大2.有資料處理的,按業務場景劃分,實時的指標開發還是會用到spark,直接用mysql做指標開發不符合未來的業務發展
uj5u.com熱心網友回復:
這樣的話,主流作法是kafka分兩個消費,一個是實時計算指標更新MySQL;一個是直接落盤,走離線數倉ETL。
因為實時計算著重于性能,一般使用HyperLogLog等會丟失精度但是快的方法進行統計。
精確統計資料,需要離線數倉,定時跑批,去修正實時計算的結果。
前期實時流hold得住的時候,離線結果可以先做對實時結果進行驗算,而不修正。如果誤差越來越大,就需要離線介入修正結果。
uj5u.com熱心網友回復:
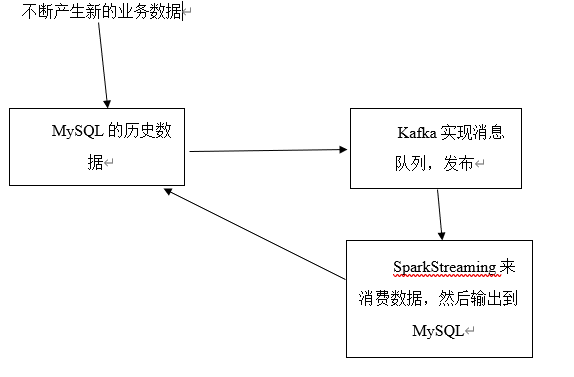
1:mysql-maxwell-binlog-kafka-hbaseapi-hbase-oozie-hive-sqoop-mysql-view2:mysql-maxwell-binlog-kafka-logstash-es-sparkstreaming-mysql-view
3:mysql-maxwell-binlog-kafka-sparkstreaming-mysql-view
4:mysql備庫-sparkstreaming-mysql-view
總有你喜歡的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55622.html
標籤:分布式計算/Hadoop
上一篇:求問我這個希爾排序哪里寫的不對
下一篇:關于影像識別的AP問題