摘要:Raft演算法是一種分布式共識演算法,用于解決分布式系統中的一致性問題,
本文分享自華為云社區《共識演算法之Raft演算法模擬數》,作者: TiAmoZhang ,
01、Leader選舉
存在A、B、C三個成員組成的Raft集群,剛啟動時,每個成員都處于Follower狀態,其中,成員A心跳超時為110ms,成員B心跳超時為150ms,成員C心跳超時為130ms,其他相關資訊如圖1所示,

■ 圖1 Raft模擬初始狀態
由于集群中不存在Leader,A、B、C三個成員都不會收到來自Leader的心跳資訊,其中,成員A的超時最短,最先進入選舉狀態,修改自己的狀態為Candidate,并增加自己的任期編號為1,發起請求投票訊息,如圖2所示,
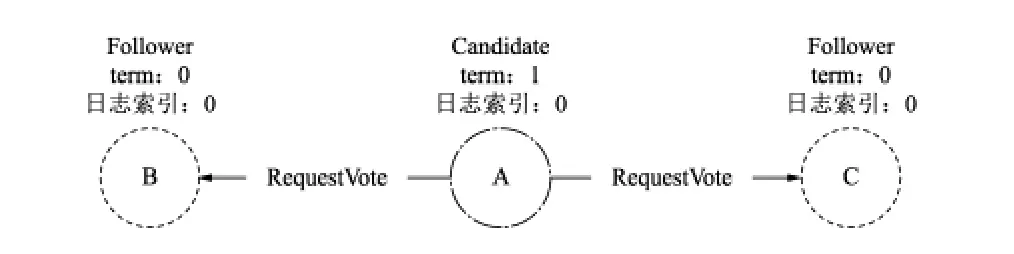
■ 圖2 請求投票
成員A通過RequestVote廣播自己的選票給成員B、C,選票描述了成員A所擁有的資料,其包含成員A所處的term及最新的日志索引,成員B、C根據投票規則處理RequestVote訊息,
term大的成員拒絕投票給term小的成員,
日志索引大的成員拒絕投票給日志索引小的成員,
一個term內只投出一張選票,采用先來先獲得投票的原則,
很明顯,成員B、C的term小于成員A的term,也不存在比成員A日志索引更大的日志索引,并且term為1的選票還沒有投給其他成員,因此成員B、C將term為1的選票投給成員A并更新自己的term為1,
成員A獲得包括自己在內的3張選票,贏得大多數選票,成員A晉升為Leader,并向其他成員發送心跳資訊,維護自己的領導地位,如圖3所示,
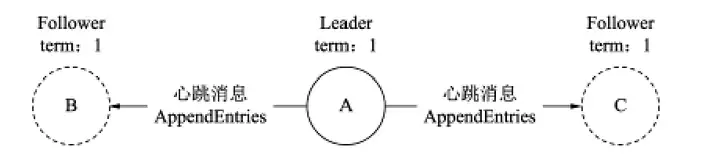
■ 圖3 Leader晉升示意
如果成員A在等待投票超過約定的時間內沒有收到多數派的選票,則會重置自己的超時,并結束本次選舉行程,接著會有其他成員在等待心跳超時后發起Leader選舉,在當前案例中,發起Leader選舉的順序為A→C→B,
可能因為網路問題,使集群中的所有成員又發起了一輪選舉,但是都沒有獲得多數派的選票,因此會隨機產生新的超時,開始下一個回圈的選舉,
02、日志復制
日志復制是一個一階段協商的程序,其中,日志項的提交操作由下一輪協商或者心跳訊息來代替完成,因此處理事務請求,Raft只需要發送一輪AppendEntries訊息即可,
AppendEntries訊息除了會包含需要復制日志項的相關資訊外,通常會攜帶Leader的committedIndex引數,標示著最后一個已提交的日志索引,每個Follower的本地都維護了committedIndex,Follower可以對比Leader的committedIndex來推進自己的提交操作,
接著如圖3所示的示例,一個三個成員組成的集群,成員A為Leader,成員B和C為Follower,并且在集群中未提交任何日志項,Leader收到客戶端發送的Add請求后,Leader和Follower依次執行以下步驟,如圖4所示,
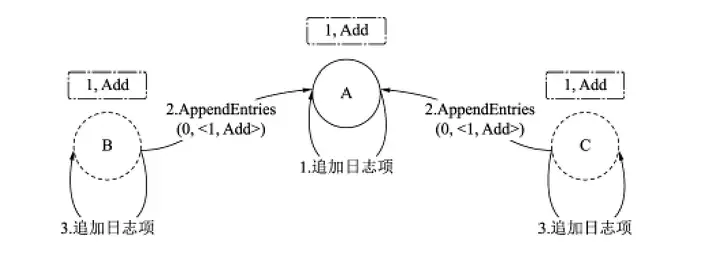
■ 圖4 日志復制-復制
(1)Leader將其封裝成日志項追加到本地的日志中,日志索引為1,
(2)Leader通過AppendEntries(0, <1, Add>)訊息時將日志項廣播給所有的Follower,其中:
- 第一個引數為committedIndex,即Leader最后提交的日志索引,
- 第二個引數為Leader所處的日志索引,即Add日志項的索引,
- 第三個引數為事務操作指令,即客戶端的指令,
(3)Follower收到訊息,將日志項追加到本地的日志中,
此時,成員A、B、C都擁有日志項Add且都已在索引為1上完成了持久化,Follower在處理完AppendEntries訊息后需要回復ACK訊息給Leader,代表接受該日志項,Leader收到多數派的ACK訊息后,可以在本地提交該日志項并執行狀態轉移,之后將執行結果回傳給客戶端,如圖5所示,
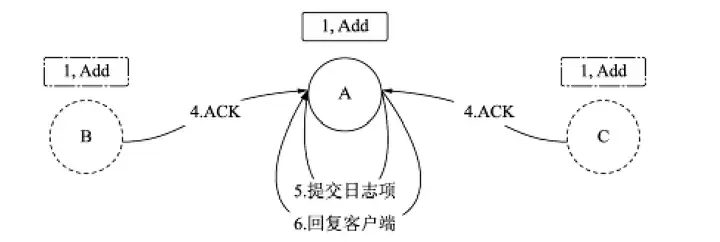
■ 圖5 日志復制-回復
在當前場景中,成員A提交了索引為1的日志項,成員B、C僅僅擁有索引為1的日志項的所有資訊但并未提交,成員B、C需要等待下一次AppendEntries訊息,根據其committedIndex推進索引為1的日志項的提交操作,以心跳的AppendEntries訊息為例,該AppendEntries訊息僅攜帶了committedIndex,此時Leader已經提交了索引為1的日志項,因此committedIndex為1,Follower則可以提交索引為1及其之前的所有日志項,如圖6所示,

■ 圖6 日志復制-心跳
03、日志對齊
我們使用<term, logIndex>表示一個日志項,如表1所示為Follower E的日志索引3和Follower D的日志索引4,與當前Leader處理不一致的情況,出現這種情況可能是Follower E和Follower D曾經當選過Leader,并且在自己的term上提出了日志索引為3和4的日志項后立即宕機造成的,
■ 表1 日志對齊
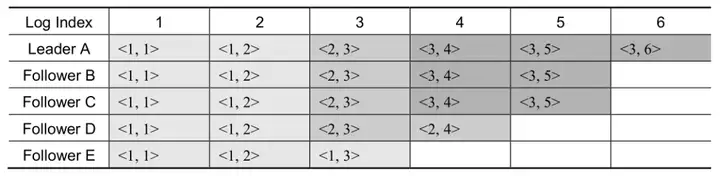
要使Follower E和Follower D與Leader資料保持一致,大致步驟分為兩步:尋找nextIndex,復制nextIndex及其之后的日志項,在Raft中,這個步驟均可由AppendEntries訊息來完成,這里以Follower E成員為例,互動細節如下:
(1)Leader為Follower E初始化nextIndex,nextIndex=lastLogIndex+1,即nextIndex=6+1=7,
(2)Leader通過AppendEntries發送探測訊息,攜帶preLogIndex(nextIndex-1)及preLogTerm,其中,preLogIndex=6,preLogTerm=3,
(3)Follower收到探測訊息,對比索引為6的日志項,回傳失敗的回應給Leader并攜帶lastLogIndex=3,
(4)Leader收到失敗的回應,更新nextIndex=lastLogIndexmsg+1,即nextIndex=4,
(5)Leader發送下一輪的探測訊息,其中,preLogIndex=3,preLogTerm=2,
(6)Follower收到探測訊息,對比索引為3的日志項,回傳失敗的回應給Leader并攜帶lastLogIndex=3,
(7)Leader收到失敗的回應,此時lastLogIndexmsg+1 ≤ nextIndex,則nextIndex單調遞減為3,
(8)Leader發送下一輪的探測訊息,其中,preLogIndex=2,preLogTerm=1,
(9)Follower收到探測訊息,對比索引為2的日志項,回傳探測成功的回應給Leader,
(10)Leader在成功探測到nextIndex之后,通過AppendEntries訊息從nextIndex開始發送索引為3的日志項給Follower,
(11)Follower將以Leader的資料為準,覆寫本地的日志項并回傳處理成功的回應給Leader,
(12)Leader收到成功回應后,單調遞增nextIndex,繼續發送下一個日志項,直到nextIndex等于Leader的lastLogIndex,意味著該Follower擁有Leader所有的資料,本次日志對齊即完成,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556593.html
標籤:其他
上一篇:【筆試實戰】LeetCode題單刷題-編程基礎 0 到 1【二】
下一篇:返回列表