目錄
- 一.發送的幾種方式
- 二.主要原始碼
- 三.自定義負載均衡
- 四.訊息傳遞保障
- 五.一些引數配置
- 六.Producer發送資料列印日志重復
一.發送的幾種方式
在producer端,存在2個執行緒,一個是producer主執行緒,用戶端呼叫send訊息時,是在主執行緒執行的,資料被快取到RecordAccumulator中,send方法即刻回傳,也就是說此時并不能確定訊息是否真正的發送到broker,另外一個是sender IO執行緒,其不斷輪詢RecordAccumulator,滿足一定條件后,就進行真正的網路IO發送,使用的是異步非阻塞的NIO,主執行緒的send方法提供了一個用于回呼的引數,當sender執行緒發送完后,回呼函式將被呼叫,可以用來處理成功,失敗或例外的邏輯,
主要就是主執行緒不會參與io,實際的io需要新的執行緒去做,則主執行緒和新執行緒是異步的關系,
參考文章:https://www.cnblogs.com/benfly/p/10000034.html
1.異步發送
for(int i=0 ; i<10 ; i++){
ProducerRecord<String,String> record =
new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i);
producer.send(record);
}
2.阻塞異步發送,主執行緒會被get()函式阻塞
for(int i=0;i<10;i++){
String key = "key-"+i;
ProducerRecord<String,String> record =
new ProducerRecord<>(TOPIC_NAME,key,"value-"+i);
Future<RecordMetadata> send = producer.send(record);
RecordMetadata recordMetadata = send.get();
System.out.println(key + "partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset());
}
3.異步回呼發送
for(int i=0;i<10;i++){
ProducerRecord<String,String> record =
new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(
"partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset());
}
});
}
二.主要原始碼
KafkaProducer:
1.metricConfig
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
2.加載負載均衡器
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
3.初始化Serializer
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
4.初始化accumulator,類似于計數器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
5.啟動newSender,守護執行緒
this.sender = newSender(logContext, kafkaClient, this.metadata);
可以得到結論:1.producer執行緒安全 2.批量發送,不會一條一條發送,
producer.send(record):
1.計算磁區
int partition = partition(record, serializedKey, serializedValue, cluster);
2.計算批次 accumulator.append
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
大致流程圖:
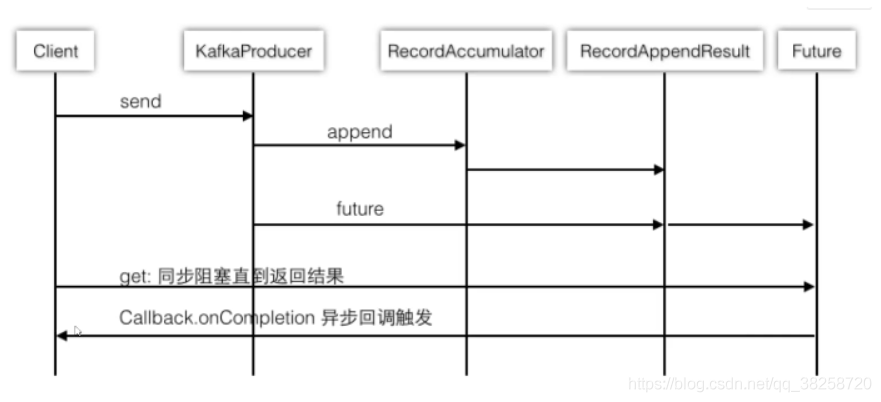
三.自定義負載均衡
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,“com.chengyanban.kafka_study.producer.SamplePartition”);
public class SamplePartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
/*
key-1
key-2
key-3
*/
String keyStr = key + "";
String keyInt = keyStr.substring(4);
System.out.println("keyStr : " + keyStr + "keyInt : " + keyInt);
int i = Integer.parseInt(keyInt);
return i%2; //兩個磁區
}
四.訊息傳遞保障
properties.put(ProducerConfig.ACKS_CONFIG,“all”);
(1)acks=0: 設定為 0 表示 producer 不需要等待任何確認收到的資訊,副本將立即加到socket buffer 并認為已經發送,沒有任何保障可以保證此種情況下 server 已經成功接收資料,同時重試配置不會發生作用(因為客戶端不知道是否失敗)回饋的 offset 會總是設定為-1;
(2)acks=1: 這意味著至少要等待 leader已經成功將資料寫入本地 log,但是并沒有等待所有 follower 是否成功寫入,這種情況下,如果 follower 沒有成功備份資料,而此時 leader又掛掉,則訊息會丟失,
(3)acks=all: 這意味著 leader 需要等待所有備份都成功寫入日志,這種策略會保證只要有一個備份存活就不會丟失資料,這是最強的保證,
(4)其他的設定,例如 acks=2 也是可以的,這將需要給定的 acks 數量,但是這種策略一般很少用,
五.一些引數配置
Properties properties = new Properties();
//批次最大位元組數 16KB
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384");
//一旦我們獲得某個 partition 的batch.size,他將會立即發送而不顧這項設定,然而如果我們獲得訊息位元組數比這項設定要小的多,我們需要“linger”特定的時間以獲取更多的訊息,
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
//快取資料的記憶體大小,先在客戶端快取,然后再一批一批發送 32MB
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432");
六.Producer發送資料列印日志重復
參考文章:https://www.cnblogs.com/yangxusun9/p/12561986.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55742.html
標籤:其他