CAP是Consistency、Availability、Partition Tolerance的首字母,不同的資料對這三個詞的解釋稍有差異,例如IBM Cloud Docs/維基百科/百度百科等等,對于CAP理論的定義也發生著變化,在第一版的解釋中說的是對于一個分布式計算系統而言,不可能同時滿足一致性、可用性和磁區容錯三個設計規約;而到了第二版的解釋變成在一個分布式系統(指互相連接并共享資料的節點的集合)中,當涉及讀寫操作時,只能保證一致性、可用性和磁區容錯三者中的兩個,另一個必須被犧牲
然而從解釋中不難看出,CAP理論探討的分布式系統強調互相連接和資料共享,也就是說例如Memcache集群并不是CAP理論探討的物件,因為不具備相互連接和資料共享的特性,而MySQL集群式CAP理論探討的物件;CAP理論還提及了當讀寫操作時,也就是說它關注的是讀寫操作而不是分布式系統的全部功能
Consistency 一致性
第一版的解釋是所有節點在同一時刻都能看到相同的資料,到了第二版解釋是對某個指定的客戶端而言,讀操作保證能夠回傳最新的寫操作結果,區別非常明顯:
- 第一版從節點的角度考慮問題,第二版從客戶端的角度考慮問題
- 第一版從節點擁有資料考慮而第二版從客戶端讀寫角度考慮
- 第一版強調節點同時擁有相同的資料,而第二版并未強調如此說法,實際上對于系統事務來說,在事務執行程序中,系統其實處于不一致的狀態,不同的節點的資料并不完全一致,因此第二版強調客戶端讀操作能夠獲取最新的寫結果,因為在事務執行程序中,客戶端是無法讀取到未提交的資料的,只有等事務提交后,客戶端才能讀取到事務寫入的資料,而如果事務執行失敗則會回滾,客戶端也不會讀取到事務中間寫入的資料
Availability 可用性
第一版強調每個請求都能得到成功或失敗的回應,到了第二版則強調非故障的節點在合理的時間內回傳合理的回應(不是錯誤和超時的回應),區別也很明顯:
- 第一版強調了every request,第二版強調了A non-failing node,顯然更加嚴謹,因為故障節點并不一定能得到回應,只有非故障節點這個前提存在才可能滿足可用性要求
- 第一版強調了response分為success和failure,第二版則強調reasonable response和reasonable time,并且強調了no error or timeout
Partition Tolerance 磁區容錯性
第一版強調盡管出現訊息丟失或磁區錯誤,但系統能夠繼續運行,到了第二版則強調出現網路磁區后,系統能夠繼續“履行職責”,區別非常明顯:
- 第一版強調系統運行,但第二版強調的是在系統運行的前提下,系統仍能夠履行職責
- 第一版強調的是message loss or partial failure,第二版則直接用network partitions,第一版中說的message loss(丟包)只是網路障礙的一種,第二版直接說現象,即發生了磁區現象,不管是什么原因,可能是丟包,可能是網路中斷,還可能使網路擁堵,只要導致了網路磁區就算在內
CAP的選擇
如果說CAP只能選擇兩個必須放棄一個,放到分布式環境下考量,則P是必選要素,因為網路本身無法做到100%可靠,理論上分布式系統不可能選擇CA架構,只能選擇CP和AP架構
CP-Consistency/Partition Tolerance
為了保證一致性,當出現網路磁區現象后,N1節點上的資料已經更新到了Y,但由于N1和N2之間網路中斷,資料Y無法同步到N2,N2節點上的資料還是X,這時候客戶端訪問N2時,需要回傳error,提示客戶端系統發生了故障,這種處理方式違背了可用性Availability原則
AP-Availability/Partition Tolerance
為了保證可用性,當發生磁區現象后,N1節點上的資料已經更新到Y,但由于N1和N2之間的復制中斷,資料Y無法同步到N2,N2上的資料還是X,此時客戶端訪問N2時,N2將當前自己擁有的資料X回傳給客戶端,而實際上當前最新資料已經是Y了,無法滿足一致性Consistency
CAP細節
理論的優點在于清晰簡潔,易于理解,但缺點就是高度抽象化,省略了很多細節,導致在將理論應用到實踐時,由于各種復雜情況,可能出現誤解和偏差,CAP 理論也不例外,如果我們需要在實踐中應用 CAP 理論,如果沒有意識到這些關鍵的細節點,就可能發現方案很難落地
CAP 關注的粒度是資料 , 而不是整個系統
CAP理論的定義和解釋中,用的都是system 、node這類系統級的概念,這就給很多人造成了很大的誤導,認為我們在進行架構設計時,整個系統要么選擇CP,要么選擇 AP ,但在實際設計程序中,每個系統不可能只處理一種資料,而是包含多種型別的資料,有的資料必須選擇CP ,有的資料必須選擇AP,而如果我們做設計時,從整個系統的角度去選擇CP還是AP,就會發現顧此失彼,無論怎么做都是有問題的
- 以一個最簡單的用戶管理系統為例 ,用戶管理系統包含用戶賬號資料(用戶ID、密碼)、用戶資訊資料(昵稱、興趣、愛好、性別、自我介紹等),通常情況下,用戶賬號資料會選擇CP,而用戶資訊資料會選擇AP,如果限定整個系統為CP,則不符合用戶資訊資料的應用場景;如果限定整個系統為AP,則又不符合用戶賬號資料的應用場景
- 所以在CAP理論落地實踐時,我們需要將系統內的資料按照不同的應用場景和要求進行分類,每類資料選擇不同的策略(CP還是AP),而不是直接限定整個系統所有資料都是同一策略
CAP 是忽略網路延遲的
這是一個非常隱含的假設,布魯爾在定義一致性時,并沒有將延遲考慮進去,也就是說,當事務提交時,資料能夠瞬間復制到所有節點,但實際情況下,從節點A復制資料到節點B, 總是需要花費一定時間的,如果是相同機房,耗費時間可能是幾毫秒;如果是跨不同地點的機房,耗費的時間就可能是幾十毫秒,這就意味著, CAP 理論中的C在實踐中是不可能完美實作的,在資料復制的程序中,節點A和節點B的資料并 不一致
不要小看了這幾毫秒或幾十毫秒的不一致,技術上是無法做到分布式場景下完美的一致性的,而業務 上必須要求一致性,因此例如單個用戶的余額、單個商品的庫存,理論上要求選擇CP而實際上CP都做不到,只能選擇CA,也就是說,只能單點寫入,其他節點做備份,無法做到分布式情況下多點寫入需要注意的是,這并不意味著這類系統無法應用分布式架構,只是說“單個用戶余額、單個商品庫存”無法做分布式,但系統整體還是可以應用分布式架構的
例如,常見的將用戶磁區的分布式架構如下圖所示 :
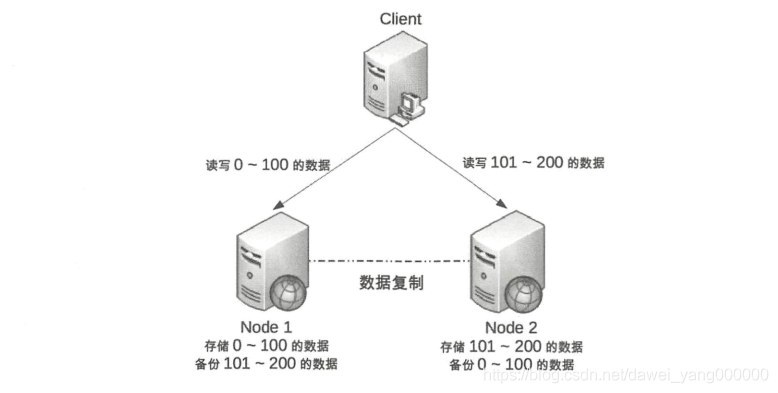
我們可以將用戶id為0~100的資料存盤在Node1,將用戶id為101~200 的資料存盤在Node2, Client根據用戶id來決定訪問哪個Node,對于單個用戶來說,讀寫操作都只能在某個節點上進行;對所有用戶來說,有一部分用戶的讀寫操作在 Node1上,有一部分用戶的讀寫操作在Node2上
這樣的設計有一個很明顯的問題就是某個節點故障時,這個節點上的用戶就無法進行讀寫操作了,但站在整體上來看,這種設計可以降低節點故障時受影響的用戶的數量和范圍,畢竟只影響20%的用戶肯定要比影響所有用戶要好,這也是為什么挖掘機挖斷光纜后,支付寶只有 一部分用戶會出現業務例外,而不是所有用戶業務例外的原因
正常運行情況下 ,不存在CP和AP的選擇 ,可以同時滿足CA
CAP 理論告訴我們分布式系統只能選擇CP或AP,但其實這里的前提是系統發生了“磁區”現象,如果系統沒有發生磁區現象,也就是說P不存在的時候(節點間的網路連接一切正常), 沒有必要放棄C或A,應該C和A都可以保證,這就要求架構設計的時候既要考慮磁區發生時選擇CP還是AP ,也要考慮磁區沒有發生時如何保證CA
同樣以用戶管理系統為例,即使是實作CA ,不同的資料實作方式也可能不一樣 : 用戶賬號資料可以采用“訊息佇列”的方式來實作CA ,因為訊息佇列可以比較好地控制實時性,但實作起來就復雜一些;而用戶資訊資料可以采用“資料庫 同步”的方式來實作 CA,因為資料庫的方式雖然在某些場景下可能延遲較高,但使用起來簡單
放棄并不等于什么都不做,需要為磁區恢復后做準備
CAP 理論告訴我們三者只能取兩個,需要“犧牲( sacrificed )”另外一個,實際上,CAP 理論的“犧牲” 只是說在磁區程序中我們無法保證C或A,但并不意味著什么都不做,因為在系統整個運行周期中,大部分時間都是正常的,發生磁區現象的時間并不長
例如, 99.99%可用性(俗稱4個9 )的系統, 一年運行下來, 不可用的時間只有50分鐘,99.999% (俗稱5個9)可用性的系統 一年運行下來,不可用的時間只有5分鐘 ,磁區期間放棄C或A,并不意味著永遠放棄C和A,我們可以在磁區期間進行一些操作,從而讓磁區故障解決后,系統能夠重新達到 CA 的狀態
最典型的就是在磁區期間記錄一些日志,當磁區故障解決后,系統根據日志進行資料恢復,使得重新達到CA狀態,同樣以用戶管理系統為例,對于用戶賬號資料,假設選擇了CP,則磁區發生后,節點1可以繼續注冊新用戶,節點2無法注冊新用戶(這里就是不符合A的原 因,因為節點2收到注冊請求后會回傳error),此時節點1可以將新注冊但未同步到節點 2的用戶記錄到日志中,當磁區恢復后,節點1讀取日志中的記錄,同步給節點2,當同步完成后,節點1和節點2就達到了同時滿足CA的狀態
而對于用戶資訊資料,假設我們選擇了AP ,則磁區發生后,節點1和節點2都可以修改用戶資訊,但兩邊可能修改不一樣,例如,節點1和節點2都記錄了未同步的愛好資料,當磁區恢復后,系統按照某個規則來合并資料,也可以完全將資料沖突報告出來,由人工來選擇具體應該采用哪一條
ACID/BASE
ACID
ACID 是資料庫管理系統為了保證事務的正確性而提出來的一個理論, ACID 包含四個約束, 基本解釋如下
- Atomicity (原子性):一個事務中的所有操作,要么全部完成,要么全部不完成,不會結束在中間某個環節 ,事務在執行程序中發生錯誤,會被回滾到事務開始前的狀態,就像這個事務從來沒有執行過一樣
- Consistency (一致性): 在事務開始之前和事務結束以后,資料庫的完整性沒有被破壞
- Isolation C 隔離性):資料庫允許多個并發事務同時對資料進行讀寫和修改的能力,隔離性可以防止多個事務并發執行 時由于交叉執行而 導致資料的不一致,事務隔離分為不同級別,包括讀未提交(Read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(Serializable)
- Durability (持久性) :事務處理結束后,對資料的修改就是永久的,即便系統故障也不會丟失,
不難看出,ACID中的A(Atomicity)和CAP中的A(Availability)意義完全不同,而 ACID中的C和CAP中的C名稱雖然都是一致性,但含義也完全不一樣,ACID中的C是指資料庫的資料完整性,CAP中的C是指分布式節點中的資料一致性,再結合ACID的應用場景是資料庫事務,CAP 關注的是分布式系統資料讀寫這個差異點來看,其實CAP和ACID的對比就類似
BASE
BASE是Basically Available(基本可用)、Soft State(軟狀態)和 Eventually Consistency(最終一致性)三個短語的縮寫 , 其核心思想是即使無法做到強一致性(CAP的一致性就是強一致性),但應用可以采用適合的方式達到最終一致性(Eventual Consistency)
BASE是指基本可用(Basically Available)、軟狀態(Soft State)、最終一致性(Eventual Consistency)
基本可用(Basically Available)
分布式系統在出現故障時,允許損失部分可用性,即保證核心可用,這里的關鍵詞是“部分”和“核心”,具體選擇哪些作為可以損失的業務,哪些是必須保證的業務,是一項有挑戰的作業
軟狀態(Soft State)
允許系統存在中間狀態,而該中間狀態不會影響系統整體可用性,這里的中間狀態就是CAP理論中的資料不一致,
最終一致性(Eventual Consistency)
系統中的所有資料副本經過一定時間后,最終能夠達到一致的狀態,這里的關鍵詞是“ 一定時間”和“最終”,“ 一定時間”和資料的特性是強關聯的,不同的資料能夠容忍的不一致時間是不同的; “最終”的含義就是不管多長時間,最侄訓是要達到一致性的狀態
BASE理論本質上是對CAP的延伸和補充,更具體地說,是對CAP中AP方案的一個補充,前面在剖析 CAP 理論時,提到了其實和BASE相關的兩點:
- CAP 理論是忽略延時的,而實際應用中延時是無法避免的,這一點就意味著完美的CP場景是不存在的,即使是幾毫秒的資料復制延遲,在這幾毫秒時間間隔內,系統是不符合CP要求的,因此CAP中的CP方案,實際上也是實作了最終一致性,只是“一定時間”是指幾毫秒而己
- AP 方案中犧牲一致性只是指磁區期間,而不是永遠放棄一致性,這一點其實就是 BASE 理論延伸的地方,磁區期間犧牲一致性,但磁區故障恢復后,系統應該達到最終一致性 ,
綜合上面的分析,ACID是資料庫事務完整性的理論, CAP是分布式系統設計理論, BASE是CAP理論中AP方案的延伸
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55791.html
標籤:其他
上一篇:“Thanos“ VS “VictoriaMetrics“,誰才是打造大型 Prometheus 監控系統的王者?
下一篇:開箱即用的Dubbo模版