本文是用機器學習打造聊天機器人系列的第三篇,通過閱讀本文你將對聊天機器人的實作有一個大致的思路,
我們的聊天機器人將具備什么樣的特性?
- 用戶可以使用人類自然語言的方式來表達自己的意圖,
- 可以依據用戶的反饋進行在線增量學習,使用的越久,能回答得問題越多,
- 采用非侵入式設計,通過幾個簡單的API就可以接入,
- 語料資料使用簡單的txt格式,只要更換txt,就可以服務于不同的知識領域,
- 提供做為Demo的UI系統,
開源聊天機器人框架ChatterBot簡介
本專案基于chatterbot0.8.7來開發,但不僅于此,讓我們先對chatterbot做一個簡單的了解,
什么是ChatterBot?
ChatterBot是一個基于機器學習的口語式對話引擎,基于python撰寫,可以基于已有的會話集合回傳匹配問題的回應,ChatterBot的非侵入式語言設計,使得我們可以在其上訓練任何語言的對話模型,
怎么使用chatterbot?
首先,安裝chatterbot0.8.7版本:
pip install ChatterBot==0.8.7
創建一個chat bot實體:
from chatterbot import ChatBot
chatbot = ChatBot(
'Charlie',
trainer='chatterbot.trainers.ListTrainer'
)
訓練你的機器人:
from chatterbot.trainers import ListTrainer
# 對話語料對,一問一答
conversation = [
"Hello",
"Hi there!",
"How are you doing?",
"I'm doing great.",
"That is good to hear",
"Thank you.",
"You're welcome."]
chatbot.train(conversation)
獲取回應,"Thanks!"在上面的語料對中是沒有的,但是其默認使用的Levenshtein distance演算法能讓引擎從問答對中選出一個相近的回答:
response = chatbot.get_response("Thanks!")
print(response) # 將輸出You're welcome.
ok,如果你也已經得到了上面的正確輸出,你可能想說,就這么簡單?其實如果從簡單體驗一下的角度來說,就是這么簡單,但是如果你想做一個像那么回事的聊天機器人出來,那么還有一段路要走,比如Levenshtein distance演算法其實過于簡單了,會導致一些答非所問的情況,除此之外,還有一些其他我們需要完善的地方,具體會在下一個話題中討論,
如此簡單就實作了一個聊天機器人,其中有沒有什么不妥?
的確,這里面是有一些問題的:
- chatterbot的默認實作,可以正常處理1000左右的問答對,但是隨著資料量的繼續增加,就會十幾秒甚至幾十秒才能獲取到回答,以及更長的時間才能訓練完成(這里有一點需要注意,就是chatterbot中提到的訓練,其實就是將問答語料寫入資料庫中),這顯然是不能接受的,
- 默認采用的Levenshtein distance演算法在句子的相似度比較上過于簡單了,它只關心一句話變成另一句話需要的最小的修改步驟有多少,認為步驟越少,兩句話越相近,所以它并不會考慮句子中每個詞的具體含義,比如不知道西紅柿和番茄雖然每個字都不同,長度也不同,但是其實指的是同一個東西,
沒錯,我們要解決的主要問題就是上面列出的2個問題,概括來說就是2個方面,一個是性能,另一個是智能,雖然問題只有2個,但是解決起來確是要花費一番功夫的,
首先,讓我們來分析一下性能的問題:
1、chatterbot默認采用sqlite資料庫,sqlite是一個關系型資料庫,非常輕量,無需配置和部署,但是當資料量比較大的時候,寫性能相對mongodb等nosql資料庫還是有差距的,對于我們的場景,由于不存在強事務要求,所以建議切換到mongodb資料庫,你會發現訓練速度會有較大的提升;
策略:chatterbot除了支持sqlite,還支持mongodb,所以可以通過修改配置的方式切換到mongodb資料庫,示例如下:
chat = ChatBot(
bot_name,
database=bot_name,
database_uri=current_app.config['DATABASE_URI'],
storage_adapter="chatterbot.storage.MongoDatabaseAdapter")
2、chatterbot將所有問答對存盤在一起,比如在mongodb中,是存盤在一個集合里的,這樣匹配問題的時候,就要和所有的問答對資料比較一遍,如果資料量很大的話,效率肯定是很慢的;
策略:將問答對分類存盤,比如在mongodb中,不同型別的問答對存盤在不同的集合里,這一步稱為意圖分類,所以我們需要通過另外的演算法來確定輸入句子的意圖類別,然后在指定類別下去判斷句子和哪些問題更為近似,然后回傳對應的回答,這樣做的好處是方便維護,大體量的問答對被拆分到各個對應的類別下,分別匹配,體量自然會減少很多,并且某一型別的問答對的資料量增加,對其他型別問答對的回應速度沒有直接的影響,
3、chatterbot區分問題和答案是根據句子是否出現在in_response_to屬性下的text屬性中來判斷的,這導致需要先查詢出in_response_to下的所有text,然后根據text再查出所有屬于問題的句子,這樣的查詢效率是很低的;
策略:在準備問答對語料的時候,分別對問題和答案進行標識,比如用Q和A做前綴,這樣存盤到資料庫中后,查詢的時候就可以用Q來直接匹配出問題,而不需要多次查詢資料庫,
4、chatterbot默認采用Levenshtein distance演算法將當前輸入的問題和資料庫里每一個問答記錄進行比較,具體做法是先查出所有的問答句子,然后for回圈進行一一比較,選擇出最相似的句子做為回應回傳,效率自然不會高,
策略:改為使用詞向量進行比較,具體在下面的智能度策略中有介紹,
ok,我們再來聊聊如何提升chatterbot的智能度:
1、采用余弦相似度演算法代替Levenshtein distance演算法
Levenshtein distance演算法只是單純的計算一個句子變成另一個句子需要經過的最小的編輯步驟,并沒有考慮句子中詞匯本身的含義,所以它并能識別出"蘋果"比起"香水"來說和"香蕉"在語意上靠的更近,而余弦相似度是指比較兩個向量之間的余弦相似度,向量當然分別是輸入句子的句向量和資料庫中所有問題句子的句向量,而句子轉為向量的方式是采用的word2vec,該方法在后續講原理的部分會具體介紹,這里我們只需要知道詞向量模型可以將詞轉為對應的向量,這些向量在空間中呈現一種語意上的關系,比如用詞向量表示我們的詞的時候,會發現 King的向量-Man的向量+Woman的向量=Queen的向量,
那么句子又是怎么轉成向量的呢?這里我們采用了平均向量的方法,就是先對句子分詞,然后將詞向量相加再除以向量的個數,至于為什么余弦值可以表示兩個向量的相似度,我們同樣也會在原理的部分進行介紹,
2、采用向量化并行計算策略代替for回圈比對
有了句子的向量表示后,我們就可以采用一些并行計算的方式來代替for回圈,具體的操作是將所有資料放到一個矩陣中一起計算,CPU雖然遠比不上GPU的并行計算速度,但是比起for回圈的方式仍然可以帶來幾十到幾百倍計算速度的提升,在此也體現了chatterbot的優秀設計,使得我們可以在不更改源代碼的情況下就替換掉原有的匹配演算法,具體見代碼篇的介紹,
一個問題從輸入到給出回復將經歷什么?
到此,我們解釋了為什么需要基于chatterbot再做一些事情,以及如何做,現在我們來看看一個問題從輸入到給出回復具體經歷了哪些步驟:
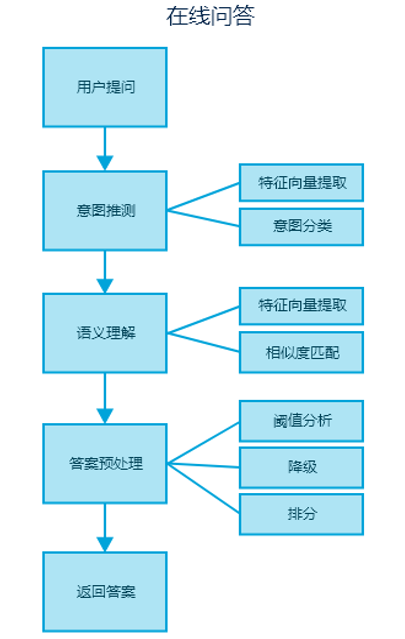
用戶提問后,由意圖推測組件接收問題,組件內部進行特征提 取后,傳給意圖分類器去預測問題所屬的類別(比如:這是一個關于 “電影演員”的問題,或關于“電影上映時間”的問題),接著問題會傳遞到語意 理解模塊,并自動觸發合適的語意理解實體去嘗試匹配問題對應的 答案,這里說的語意理解就是在指定的意圖分類下,去匹配具體的問題,比如“你覺得功夫類電影誰演的好?”,或者“愛情片什么時間段上映比較合適?”等,整個程序主要是采用詞向量模型構造問題句子的特征向量,通過貝葉斯演算法進行意圖分類,以及 采用余弦相似度演算法計算問題和答案的匹配分數,此時引擎會根據 匹配分數結合閾值進行分析,從而決定是直接回傳答案,還是降級處理,所以有些場景下可能會回傳多個候選答案,候選答案會根據分數降序排列,
如何讓機器人說我想聽的話?
前面說的都是如何根據輸入的問題給與合適的回復,本篇主要討論如何調教機器人說你想聽的回復,具體流程如下:
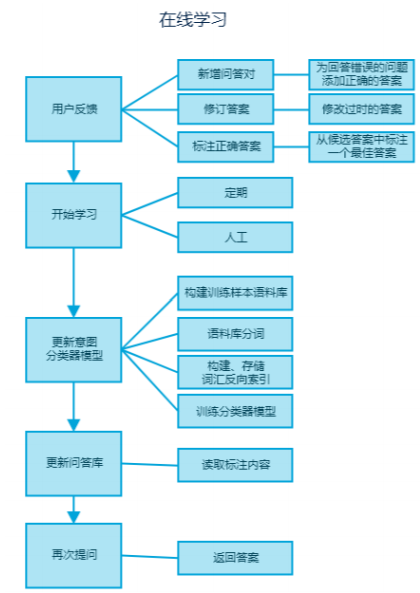
用戶提問后,如果系統沒能給出滿意的答案,用戶可以通過新增問答對、修訂答案 2 種方式來進行反饋,當系統給出多個候選答 案,但是正確答案沒有排在首位時,用戶可以通過標注最佳答案來 進行反饋,可以定期讓問答引擎自主學習用戶的反饋,重新訓練意 圖分類器并更新問答語料庫,當用戶自己或其他用戶再次問到相同 含義的問題時即可得到相應的答案,
由于我們可以自己調教機器人,所以你可以將其調教成僅屬于你自己的獨一無二的性格??,
下一篇《用機器學習打造聊天機器人(四) 代碼篇》將展示打造聊天機器人的相關代碼實作及說明,
ok,本篇就這么多內容啦~,感謝閱讀O(∩_∩)O,
本博客內容來自公眾號“程式員一一滌生”,歡迎掃碼關注 o(∩_∩)o
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/57278.html
標籤:其他