HashMap的實作原理
HashMap的資料結構
在看Hashmap的資料結構之前先來看看陣列和鏈表的特點
陣列:尋址容易插入和洗掉的時候比較困難(陣列有下表尋址,但是插入洗掉的時候下表要移動,擴容的時候也很麻煩)
鏈表:尋址困難,插入和洗掉容易,元素的指標指向下一個元素,在插入洗掉的時候只需要對指標進行操作就好
然而HashMap就是二者的結合,我們可以發現哈希表是由陣列+鏈表組成的如下圖
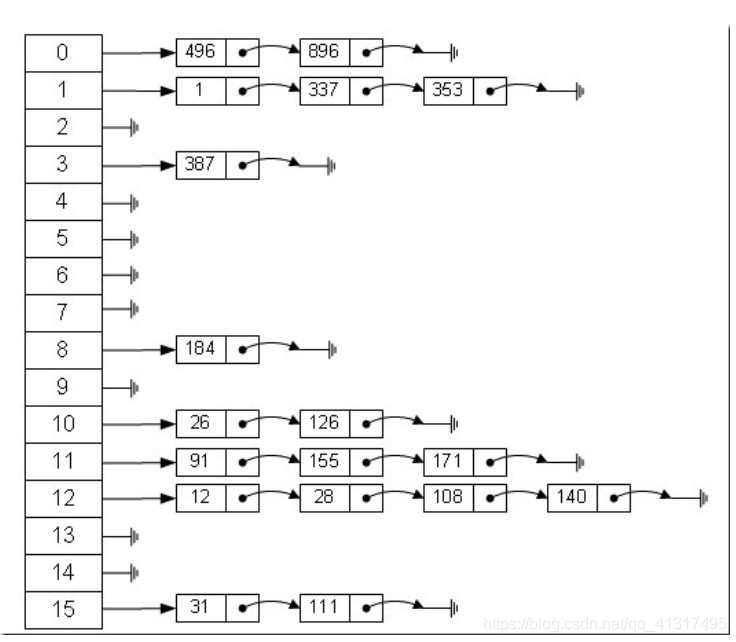
? JDK1.8之前,哈希表底層采用陣列+鏈表實作,即使用鏈表處理沖突,同一hash值的鏈表都存盤在一個鏈表里,但是當位于一個桶中的元素較多,即hash值相等的元素較多時,通過key值依次查找的效率較低,
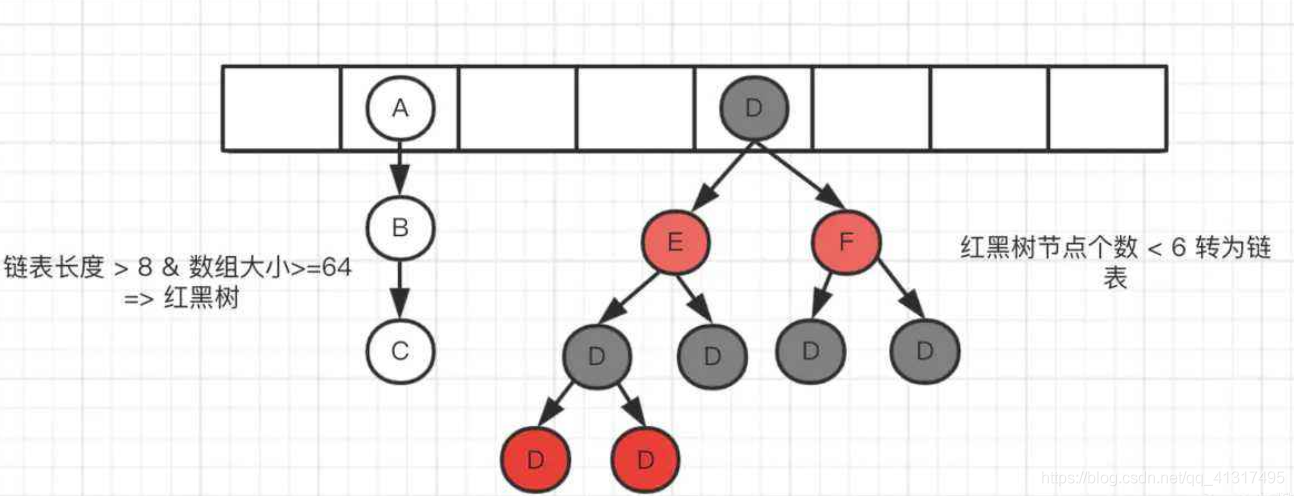
? JDK1.8中,哈希表存盤采用陣列+鏈表+紅黑樹實作,當鏈表長度超過閾值(8)時,將鏈表轉換為紅黑樹,這樣大大減少了查找時間,如下圖(畫的不好看,只是表達一個意思,):
? 1,進行鍵值對存盤時,先通過hashCode()計算出鍵key的哈希值,然后再陣列中查詢,如果沒有則保存,
? 2,但是如果找到相同的哈希值,那么接著呼叫equals方法判斷它們的值是否相同,僅當滿足以上兩種條件才能認定為相同的資料,因此對于Java中的包裝類里面都重寫了hashCode()和equals()方法,
? JDK1.8引入紅黑樹大程度優化了HashMap的性能,根據物件的hashCode和equals方法來決定的,如果我們往集合中存放自定義的物件,那么保證其唯一,就必須復寫hashCode和equals方法建立屬于當前物件的比較方式,(可以自定義排序方法)
HashMap<K,V>:存盤資料采用的哈希表結構,元素的存取順序不能保證一致,由于要保證鍵的唯一、不重復,需要重寫鍵的hashCode()方法、equals()方法,另外Map介面中的集合都有兩個泛型變數<K,V>,在使用時,要為兩個泛型變數賦予資料型別,兩個泛型變數<K,V>的資料型別可以相同,也可以不同
主要方法
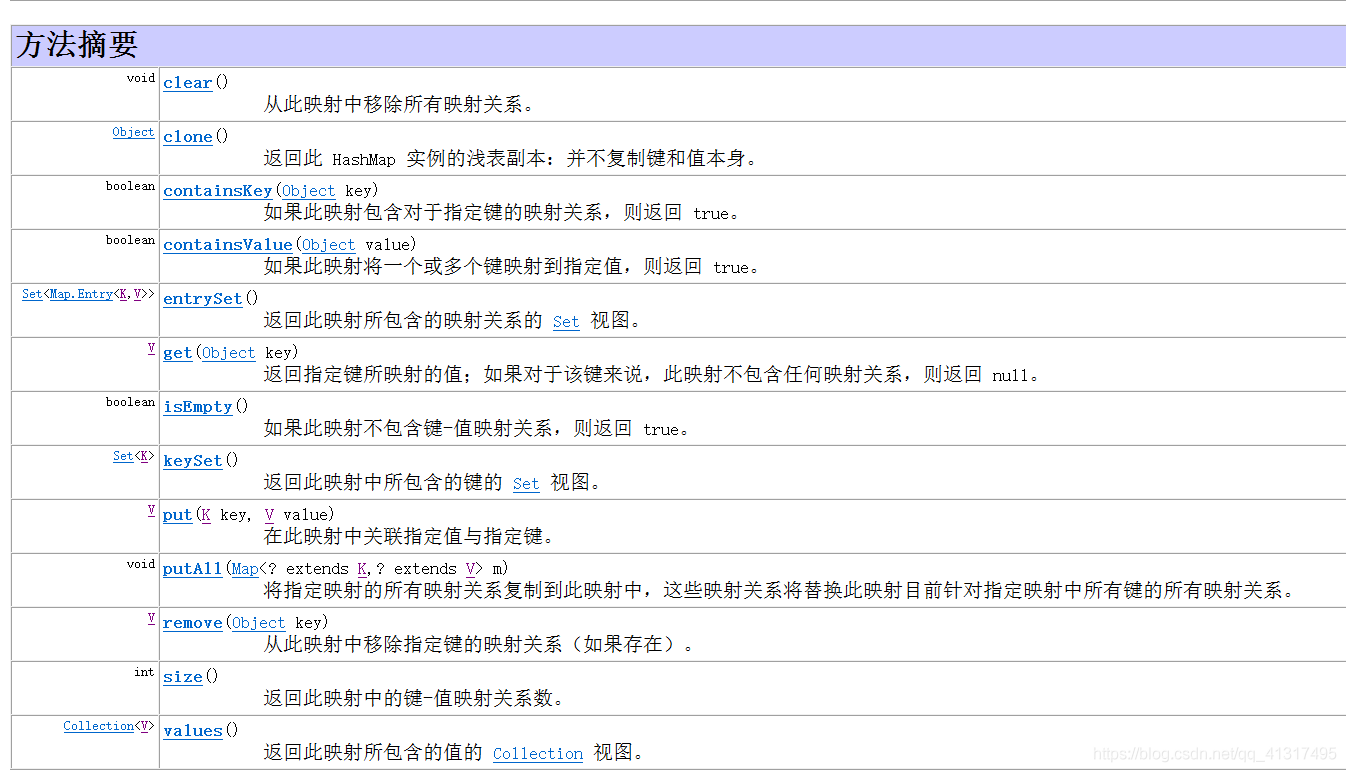
HashMap原始碼查看
進入put方法

人后在進入putVal方法
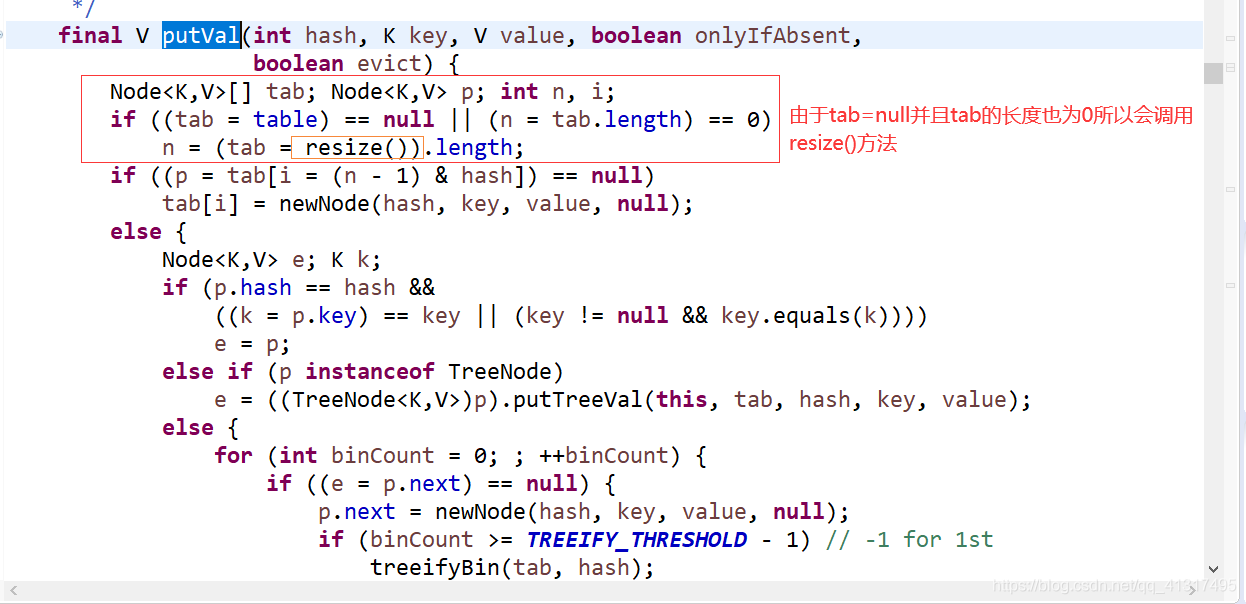
然后進入resize()方法
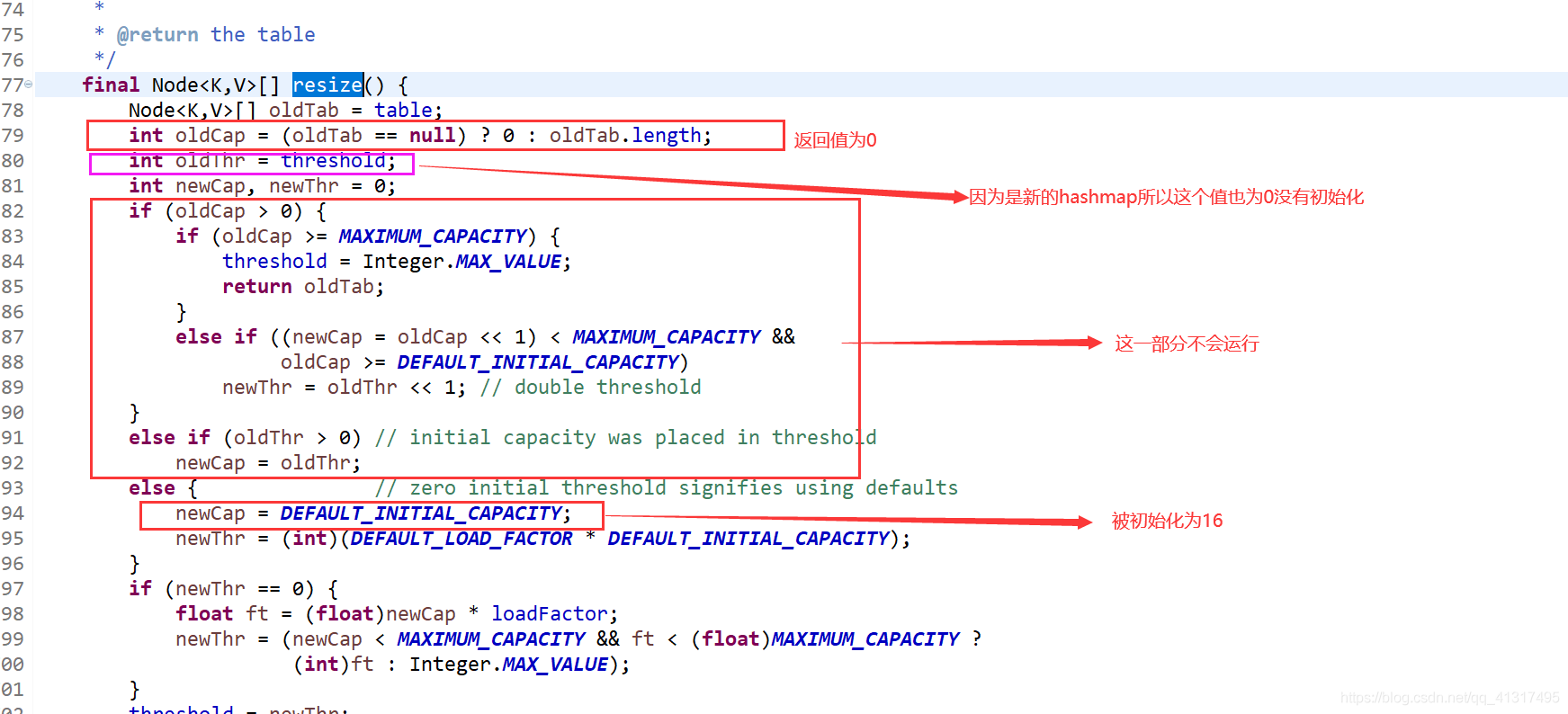

這個值是16
所以當存入一組鍵值對的時候,先對key進行hash,然后映射到一個初始化長度為16的陣列上,
進入HashMap<>();
會發現創建一個初始化陣列長度為16,負載因子0.75

負載因子0.75

負載因子:在HashMap的底層存在著一個名字為table的Entry陣列,在實體化HashMap的時候,會輸入兩個引數,一個是 int initCapacity(初始化陣列大小,默認值是16),一個是float loadFactor(負載因子,默認值是0.75),首先會根據initCapacity計算出一個大于或者等于initCapacity且為2的冪的值capacity,例如initCapacity為15,那么capacity就會為16,還會算出一個臨界值threshold,也就是capacity * loadFactor,貼出源代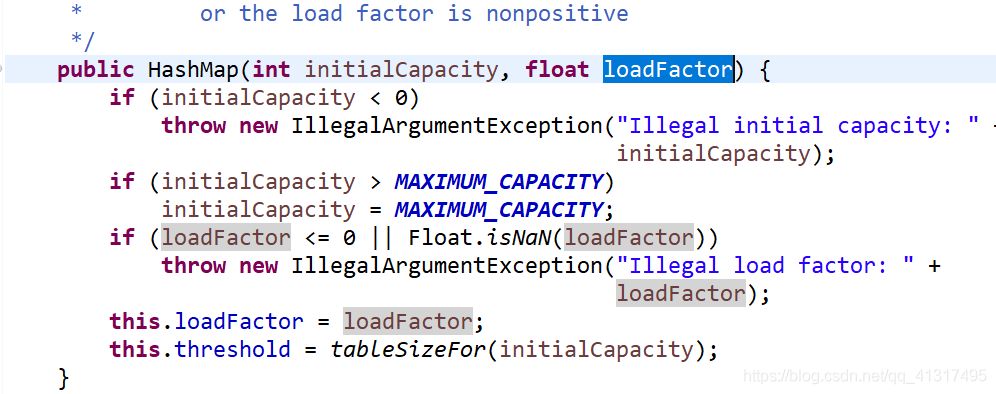
第一次讀原始碼,有錯誤請指出!感覺應該不是很對!哈哈哈哈
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/57539.html
標籤:其他
上一篇:入門級最強SSM整合(簡便易懂注解和組態檔)idea
下一篇:Redis實作分布式鎖