一、背景
地圖App的功能可以簡單概括為定位,搜索,導航三部分,分別解決在哪里,去哪里,和怎么去的問題,高德地圖的搜索場景下,輸入的是,地理相關的檢索query,用戶位置,App圖面等資訊,輸出的是,用戶想要的POI,如何能夠更加精準地找到用戶想要的POI,提高滿意度,是評價搜索效果的最關鍵指標,
一個搜索引擎通常可以拆分成query分析、召回、排序三個部分,query分析主要是嘗試理解query表達的含義,為召回和排序給予指導,
地圖搜索的query分析不僅包括通用搜索下的分詞,成分分析,同義詞,糾錯等通用NLP技術,還包括城市分析,wherewhat分析,路徑規劃分析等特定的意圖理解方式,
常見的一些地圖場景下的query意圖表達如下:
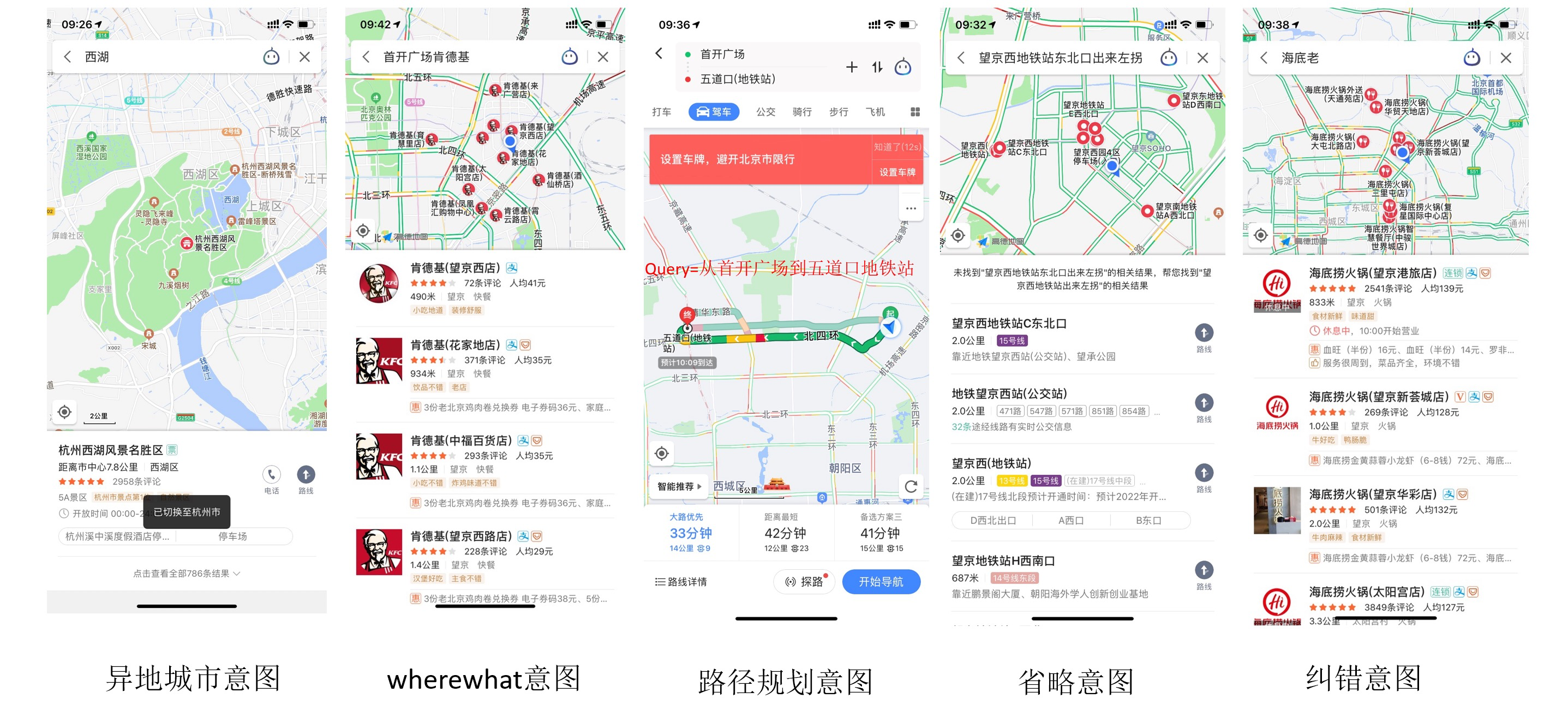
query分析是搜索引擎中策略密集的場景,通常會應用NLP領域的各種技術,地圖場景下的query分析,只需要處理地理相關的文本,多樣性不如網頁搜索,看起來會簡單一些,但是,地理文本通常比較短,并且用戶大部分的需求是唯一少量結果,要求精準度非常高,如何能夠做好地圖場景下的文本分析,并提升搜索結果的質量,是充滿挑戰的,
二、整體技術架構
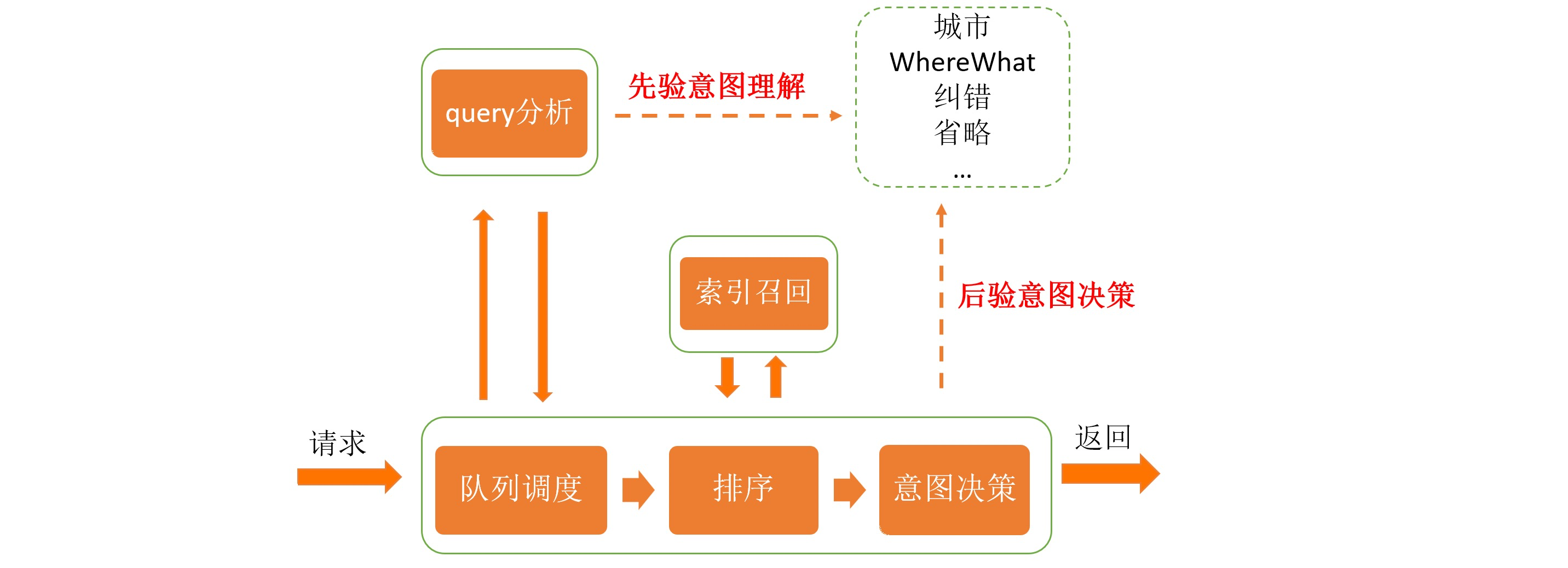
搜索架構
類似于通用檢索的架構,地圖的檢索架構包括query分析,召回,排序三個主要部分,先驗的,用戶的輸入資訊可以理解為多種意圖的表達,同時下發請求嘗試獲取檢索結果,后驗的,拿到每種意圖的檢索結果時,進行綜合判斷,選擇效果最好的那個,
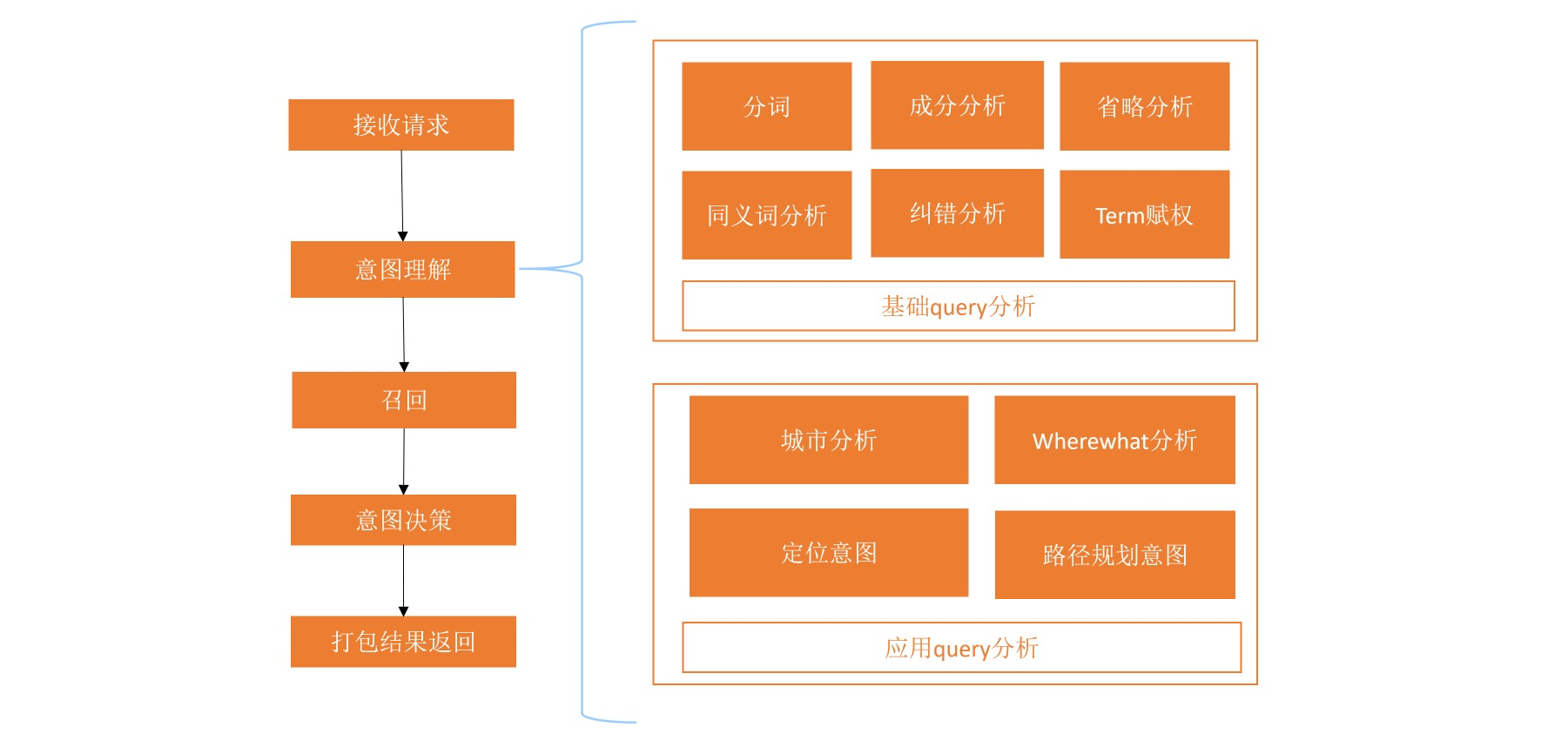
query分析流程
具體的意圖理解可分為基礎query分析和應用query分析兩部分,基礎query分析主要是使用一些通用的NLP技術對query進行理解,包括分析,成分分析,省略,同義詞,糾錯等,應用query分析主要是針對地圖場景里的特定問題,包括分析用戶目標城市,是否是where+what表達,是否是從A到B的路徑規劃需求表達等,

整體技術演進
在地里文本處理上整體的技術演進經歷了規則為主,到逐步引入機器學習,到機器學習全面應用的程序,由于搜索模塊是一個高并發的線上服務,對于深度模型的引入有比較苛刻的條件,但隨著性能問題逐漸被解決,我們從各個子方向逐步引入深度學習的技術,進行新一輪的效果提升,
NLP領域技術在最近幾年取得了日新月異的發展,bert,XLNet等模型相繼霸榜,我們逐步統一化各個query分析子任務,使用統一的向量表示對進行用戶需求進行表達,同時進行seq2seq的多任務學習,在效果進一步提升的基礎上,也能夠保證系統不會過于臃腫,
本文就高德地圖搜索的地理文本處理,介紹相關的技術在過去幾年的演進,我們將選取一些點分上下兩篇進行介紹,上篇主要介紹搜索引擎中一些通用的query分析技術,包括糾錯,改寫和省略,下篇著重介紹地圖場景中特有query分析技術,包括城市分析,wherewhat分析,路徑規劃,
三、通用query分析技術演進
3.1 糾錯
在搜索引擎中,用戶輸入的檢索詞(query)經常會出現拼寫錯誤,如果直接對錯誤的query進行檢索,往往不會得到用戶想要的結果,因此不管是通用搜索引擎還是垂直搜索引擎,都會對用戶的query進行糾錯,最大概率獲得用戶想搜的query,
在目前的地圖搜索中,約有6%-10%的用戶請求會輸入錯誤,所以query糾錯在地圖搜索中是一個很重要的模塊,能夠極大的提升用戶搜索體驗,
在搜索引擎中,低頻和中長尾問題往往比較難解決,也是糾錯模塊面臨的主要問題,另外,地圖搜索和通用搜索,存在一個明顯的差異,地圖搜索query結構化比較突出,query中的片段往往包含一定的位置資訊,如何利用好query中的結構化資訊,更好地識別用戶意圖,是地圖糾錯獨有的挑戰,
常見錯誤分類
(1) 拼音相同或者相近,例如: 盤橋物流園-潘橋物流園
(2) 字形相近,例如: 河北冒黎-河北昌黎
(3) 多字或者漏字,例如: 泉州州頂街-泉州頂街
糾錯現狀
原始糾錯模塊包括多種召回方式,如:
拼音糾錯:主要解決短query的拼音糾錯問題,拼音完全相同或者模糊音作為糾錯候選,
拼寫糾錯:也叫形近字糾錯,通過遍歷替換形近字,用query熱度過濾,加入候選,
組合糾錯:通過翻譯模型進行糾錯替換,資源主要是通過query對齊挖掘的各種替換資源,
組合糾錯翻譯模型計算公式:
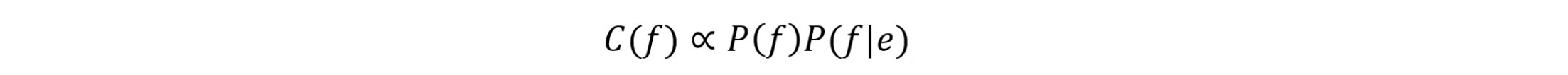
其中p(f)是語言模型,p(f|e)是替換模型,
問題1:召回方式存在缺陷,目前query糾錯模塊主要召回策略包括拼音召回、形近字召回,以及替換資源召回,對于低頻case,解決能力有限,
問題2:排序方式不合理,糾錯按照召回方式分為幾個獨立的模塊,分別完成相應的召回和排序,不合理,
技術改造
改造1:基于空間關系的物體糾錯
原始的糾錯主要是基于用戶session挖掘片段替換資源,所以對于低頻問題解決能力有限,但是長尾問題往往集中在低頻,所以低頻問題是當前的痛點,
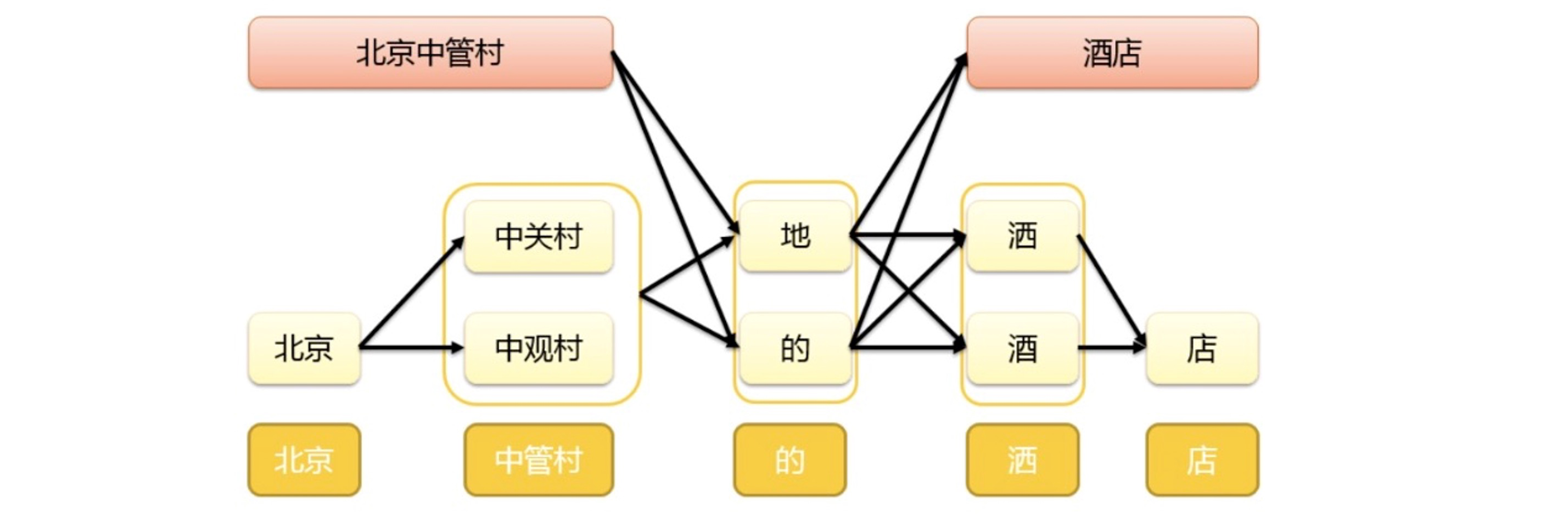
地圖搜索與通用搜索引擎有個很大的區別在于,地圖搜索query比較結構化,例如北京市朝陽區阜榮街10號首開廣場,我們可以對query進行結構化切分(也就是地圖中成分分析的作業),得到這樣一種帶有類別的結構化描述,北京市【城市】朝陽區【區縣】阜榮街【道路】10號【門址后綴】首開廣場【通用物體】,
同時,我們擁有權威的地理知識資料,利用權威化的地理物體庫進行前綴樹+后綴樹的索引建庫,提取疑似糾錯的部分在索引庫中進行拉鏈召回,同時利用物體庫中的邏輯隸屬關系對糾錯結果進行過濾,實踐表明,這種方式對低頻的區劃或者物體的錯誤有著明顯的作用,
基于字根的字形相似度計算
上文提到的排序策略里面通過字形的編輯距離作為排序的重要特征,這里我們開發了一個基于字根的字形相似度計算策略,對于編輯距離的計算更為細化和準確,漢字資訊有漢字的字根拆分詞表和漢字的筆畫數,

將一個漢字拆分成多個字根,尋找兩個字的公共字根,根據公共字根筆畫數來計算連個字的相似度,
改造2:排序策略重構
原始的策略召回和排序策略耦合,導致不同的召回鏈路,存在顧此失彼的情況,為了能夠充分發揮各種召回方式的優勢,急需要對召回和排序進行解耦并進行全域排序優化,為此我們增加了排序模塊,將流程分為召回和排序兩階段,
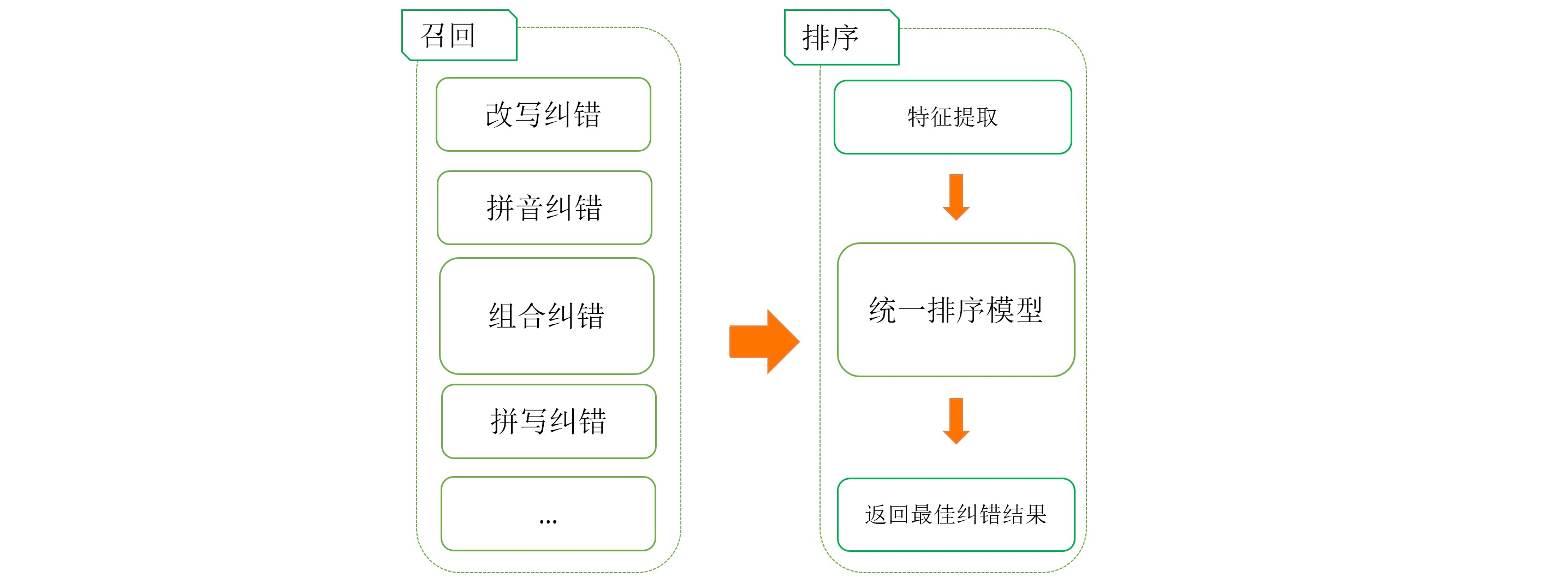
模型選擇
對于這個排序問題,這里我們參考業界的實踐,使用了基于pair-wise的gbrank進行模型訓練,
樣本建設
通過線上輸出結合人工review的方式構造樣本,
特征建設
(1) 語意特征,如統計語言模型,
(2) 熱度特征,pv,點擊等,
(3) 基礎特征,編輯距離,切詞和成分特征,累積分布特征等,
這里解決了糾錯模塊兩個痛點問題,一個是在地圖場景下的大部分低頻糾錯問題,另一個是重構了模塊流程,將召回和排序解耦,充分發揮各個召回鏈路的作用,召回方式更新后只需要重訓排序模型即可,使得模塊更加合理,為后面的深度模型升級打下良好的基礎,后面在這個框架下,我們通過深度模型進行seq2seq的糾錯召回,取得了進一步的收益,
3.2 改寫
糾錯作為query變換的一種方式的召回策略存在諸多限制,對于一些非典型的query變換表達,存在策略的空白,比如query=永城市新農合辦,目標POI是永城市新農合服務大廳,用戶的低頻query,往往得不到較好搜索效果,但其實用戶描述的語意與主poi的高頻query是相似的,
這里我們提出一種query改寫的思路,可以將低頻query改寫成語意相似的高頻query,以更好地滿足用戶需求多樣性的表達,
這是一個從無到有的實作,用戶表達的query是多樣的,使用規則表達顯然是難以窮盡的,直觀的思路是通過向量的方式召回,但是向量召回的方式很可能出現泛化過多,不適應地圖場景的檢索的問題,這些都是要在實踐程序中需要考慮的問題,
方案
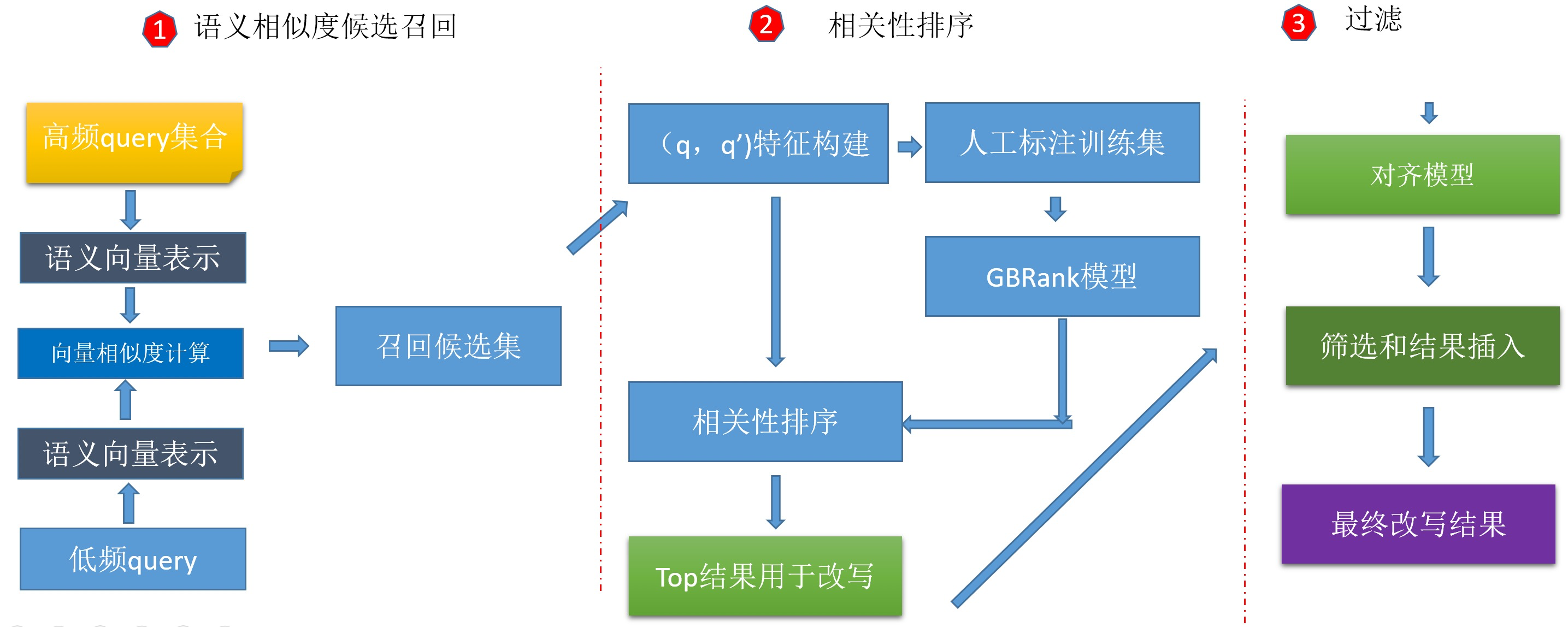
整體看,方案包括召回,排序,過濾,三個階段,
召回階段
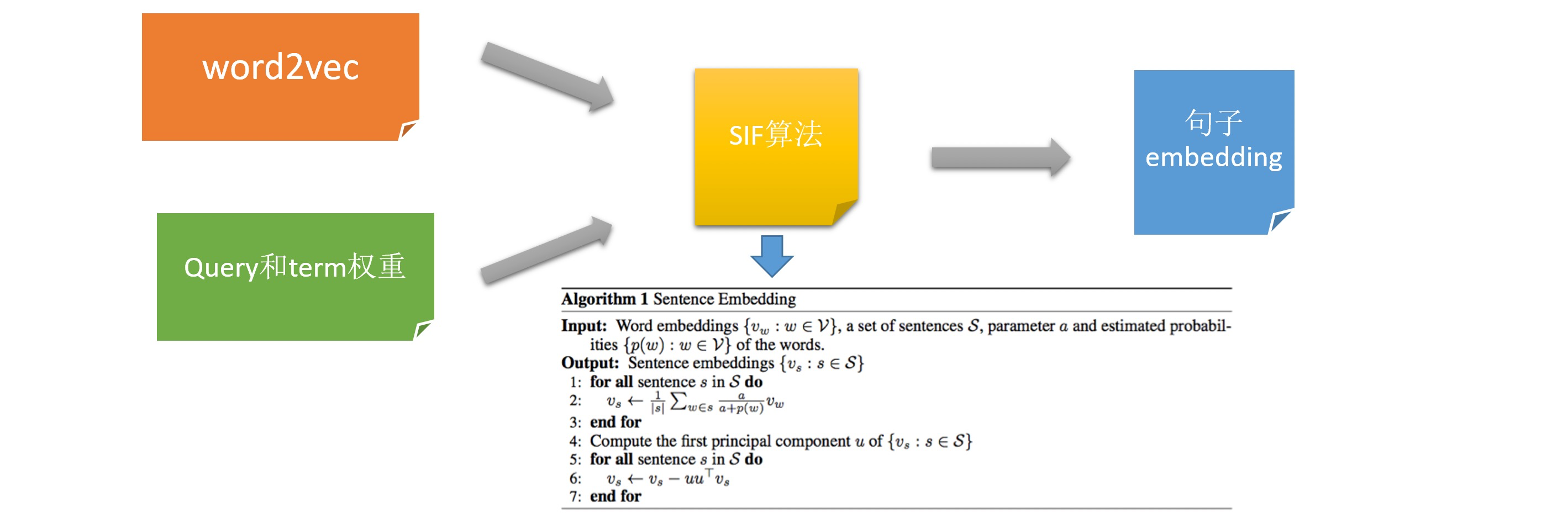
我們調研了句子向量表示的幾種方法,選擇了演算法簡單,效果和性能可以和CNN,RNN媲美的SIF(Smooth Inverse Frequency),向量召回可以使用開源的Faiss向量搜索引擎,這里我們使用了阿里內部的性能更好的的向量檢索引擎,
排序階段
樣本構建
原query與高頻query候選集合,計算語意相似度,選取語意相似度的TOPK,人工標注的訓練樣本,
特征建設
1.基礎文本特征
2.編輯距離
3.組合特征
模型選擇
使用xgboost進行分數回歸
過濾階段
通過向量召回的query過度泛化非常嚴重,為了能夠在地圖場景下進行應用,增加了對齊模型,使用了兩種統計對齊模型giza和fastalign,實驗證明二者效果幾乎一致,但fastalign在性能上好于giza,所以選擇fastalign,

通過對齊概率和非對齊概率,對召回的結果進行進一步過濾,得到精度比較高的結果,
query改寫填補了原始query分析模塊中一些低頻表達無法滿足的空白,區別于同義詞或者糾錯的顯式query變換表達,句子的向量表示是相似query的一種隱式的表達,有其相應的優勢,
向量表示和召回也是深度學習模型逐步開始應用的嘗試,同義詞,改寫,糾錯,作為地圖中query變換主要的三種方式,以往在地圖模塊里比較分散,各司其職,也會有互相重疊的部分,在后續的迭代升級中,我們引入了統一的query變換模型進行改造,在取得收益的同時,也擺脫掉了過去很多規則以及模型耦合造成的歷史包袱,
3.2 省略
在地圖搜索場景里,有很多query包含無效詞,如果用全部query嘗試去召回很可能不能召回有效結果,如廈門市搜"湖里區縣后高新技術園新捷創運營中心11樓1101室 縣后brt站",這就需要一種檢索意圖,在不明顯轉義下,使用核心term進行召回目標poi候選集合,當搜索結果無果或者召回較差時起到補充召回的作用,
在省略判斷的程序中存在先驗后驗平衡的問題,省略意圖是一個先驗的判斷,但是期望的結果是能夠進行POI有效召回,和POI的召回欄位的現狀密切相關,如何能夠在策略設計的程序中保持先驗的一致性,同時能夠在后驗POI中拿到相對好的效果,是做好省略模塊比較困難的地方,
原始的省略模塊主要是基于規則進行的,規則依賴的主要特征是上游的成分分析特征,由于基于規則擬合,模型效果存在比較大的優化空間,另外,由于強依賴成分分析,模型的魯棒性并不好,
技術改造
省略模塊的改造主要完成了規則到crf模型的升級,其中也離線應用了深度學習模型輔助樣本生成,
模型選擇
識別出來query哪些部分是核心哪些部分是可以省略的,是一個序列標注問題,在淺層模型的選型中,顯而易見地,我們使用了crf模型,
特征建設
term特征,使用了賦權特征,詞性,先驗詞典特征等,
成分特征,仍然使用成分分析的特征,
統計特征,統計片段的左右邊界熵,城市分布熵等,通過分箱進行離散化,
樣本建設
專案一期我們使用了使用線上策略粗標,外包細標的方式,構造了萬級的樣本供crf模型訓練,
但是省略query的多樣性很高,使用萬級的樣本是不夠的,在線上模型無法快速應用深度模型的情況下,我們使用了boostraping的方式,借助深度模型的泛化能力,離線構造了大量樣本,
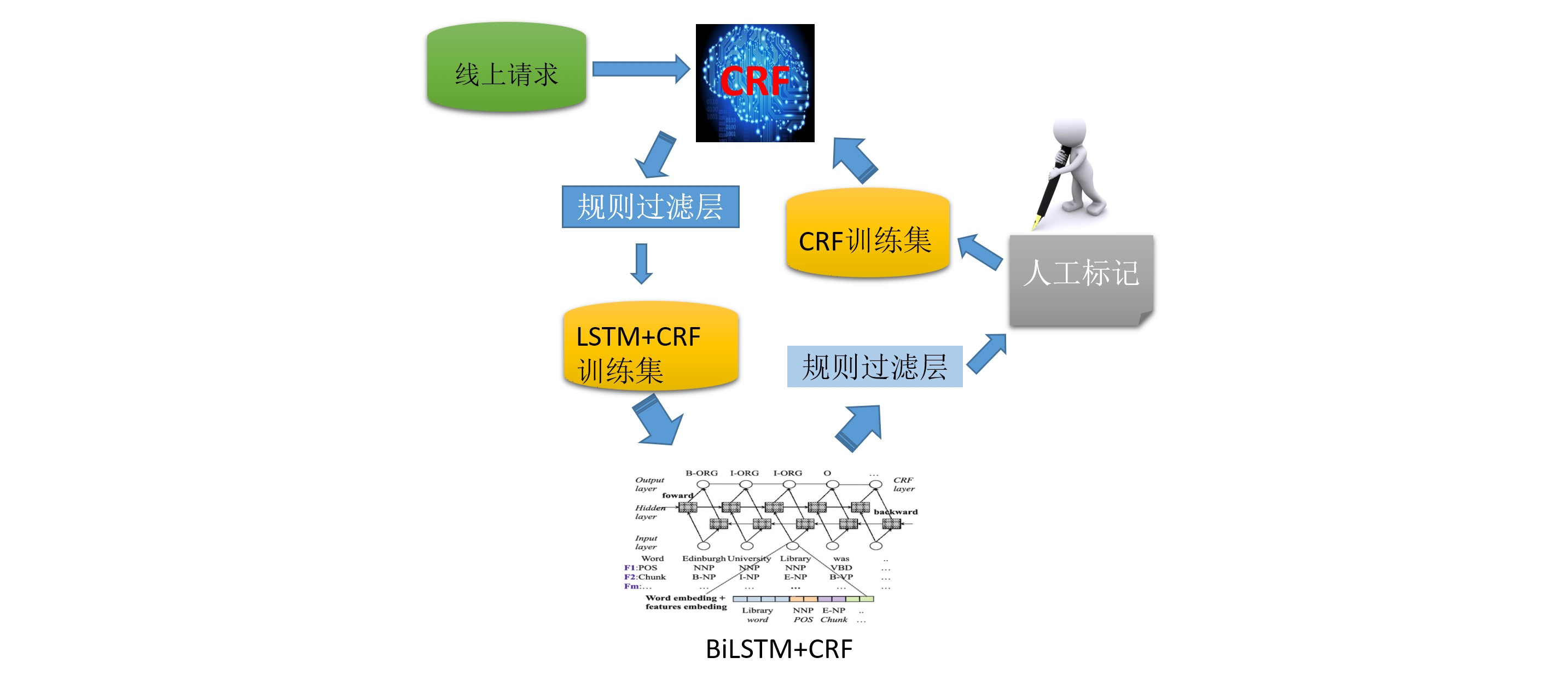
使用了這種方式,樣本從萬級很容易擴充到百萬級,我們仍然使用crf模型進行訓練和線上應用,
在省略模塊,我們完成了規則到機器學習的升級,引入了成分以外的其他特征,提升了模型的魯棒性,同時并且利用離線深度學習的方式進行樣本構造的回圈,提升了樣本的多樣性,使得模型能夠更加接近crf的天花板,
在后續深度模型的建模中,我們逐步擺脫了對成分分析特征的依賴,對query到命中poi核心直接進行建模,構建大量樣本,取得了進一步的收益,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/60205.html
標籤:其他
上一篇:AI-影像基礎知識-02