本系列筆記記錄了學習TensorFlow2的程序,主要依據
https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
進行學習


首先需要明確TensorFlow 是一個面向于深度學習演算法的科學計算庫,內部資料保存在張量(Tensor)物件上,所有的運算操作(Operation, OP)也都是基于張量物件進行,
資料型別
Tensorflow中的基本資料型別有三種,包括數值型、字串型和布爾型,
【數值型】又包括:(在 TensorFlow 中間,為了表達方便,一般把標量、向量、矩陣也統稱為張量,不作區分,需要根據張量的維度數和形狀自行判斷, )
1.Scalar(標量)
維度數(Dimension,也叫秩)為 0,shape 為[]
a = tf.constant(1.2) # 創建標量
2.Vector(向量)
維度數為 1,長度不定,shape 為[??]
x = tf.constant([1,2.,3.3])
3.Matrix(矩陣)
維度數為 2,每個維度上的長度不定,shape 為[??,??] (n 行 m 列)
b = tf.constant([[1,2],[3,4]])
4.Tensor(張量)
維度數dim > 2的陣列統稱為張量,
c = tf.constant([[[1,2],[3,4]],[[5,6],[7,8]]]) (三維張量定義)
【字串】型別:
a = tf.constant('Hello, Deep Learning.')
在 tf.strings 模塊中,提供了常見的字串型的工具函式,如拼接 join(),長度 length(),切分 split()等等,如:tf.strings.lower(a)
【布爾】型別:
a = tf.constant(True)
數值精度
常用的精度型別有 tf.int16, tf.int32, tf.int64, tf.float16, tf.float32, tf.float64,其中 tf.float64 即為 tf.double
對于大部分深度學習演算法,一般使用 tf.int32, tf.float32 可滿足運算精度要求,部分對精度要求較高的演算法,如強化學習,可以選擇使用 tf.int64, tf.float64 精度保存張量,
通過訪問張量的 dtype 成員屬性可以判斷張量的保存精度: a = tf.constant(np.pi, dtype=tf.float16) ,print(a.dtype)
轉換精度 :a = tf.cast(a,tf.float32)
布爾型與整形之間相互轉換也是合法的,是比較常見的操作,一般默認 0 表示 False,1 表示 True,在 TensorFlow 中,將非 0 數字都視為 True
待優化張量
為了區分需要計算梯度資訊的張量與不需要計算梯度資訊的張量,TensorFlow 增加了 一種專門的資料型別來支持梯度資訊的記錄:tf.Variable,tf.Variable 型別在普通的張量類 型基礎上添加了 name,trainable 等屬性來支持計算圖的構建,由于梯度運算會消耗大量的 計算資源,而且會自動更新相關引數,對于不需要的優化的張量,如神經網路的輸入 X, 不需要通過 tf.Variable 封裝;相反,對于需要計算梯度并優化的張量,如神經網路層的W 和??,需要通過 tf.Variable 包裹以便 TensorFlow 跟蹤相關梯度資訊, 通過 tf.Variable()函式可以將普通張量轉換為待優化張量,
a = tf.constant([-1, 0, 1, 2])
aa = tf.Variable(a)
aa.name, aa.trainable
'''''''''''''''''''''''''''''''
Out[20]:
('Variable:0', True)
'''''''''''''''''''''''''''''''
創建 Variable 物件是默認啟用優化標志,可以設定 trainable=False 來設定張量不需要優化,
除了通過普通張量方式創建 Variable,也可以直接創建: a = tf.Variable([[1,2],[3,4]])
待優化張量可看做普通張量的特殊型別,普通張量也可以通過 GradientTape.watch()方法臨 時加入跟蹤梯度資訊的串列,
創建張量
1.從 Numpy, List 物件創建
通過 tf.convert_to_tensor 可以創建新 Tensor,并將保存在 Python List 物件或者 Numpy Array 物件中的資料匯入到新 Tensor 中: tf.convert_to_tensor([1,2.]) | tf.convert_to_tensor(np.array([[1,2.],[3,4]]))
需要注意的是,Numpy 中浮點數陣列默認使用 64-Bit 精度保存資料,轉換到 Tensor 型別時 精度為 tf.float64,可以在需要的時候轉換為 tf.float32 型別,
tf.constant()和 tf.convert_to_tensor()都能夠自動的把 Numpy 陣列或者 Python List 資料型別轉化為 Tensor 型別
2. 創建全 0,全 1 張量
考慮線性變換 ?? = ???? +??,將權值矩陣 W 初始化為全 1 矩陣,偏置 b 初始化為全 0 向量,此時線性變 化層輸出?? = ??,是一種比較好的層初始化狀態,通過 tf.zeros()和 tf.ones()即可創建任意形 狀全 0 或全 1 的張量,例如,創建為 0 和為 1 的標量張量:
tf.zeros([2,2]) | tf.ones([3,2])
通過 tf.zeros_like, tf.ones_like 可以方便地新建與某個張量 shape 一致,內容全 0 或全 1 的張量 : tf.zeros_like(a)
tf.*_like 是一個便捷函式,可以通過 tf.zeros(a.shape)等方式實作
3.創建自定義數值張量
tf.fill([2,2], 99)
4.創建已知分布的張量
正態分布(Normal Distribution,或 Gaussian Distribution)和均勻分布(Uniform Distribution)是最常見的分布之一,創建采樣自這 2 種分布的張量非常有用,比如在卷積神經網路中,卷積核張量 W 初始化為正態分布有利于網路的訓練;在對抗生成網路中,隱藏變數 z 一般采樣自均勻分布,
通過 tf.random.normal(shape, mean=0.0, stddev=1.0)可以創建形狀為 shape,均值為 mean,標準差為 stddev 的正態分布??(????????,????????????2),
通過 tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32)可以創建采樣自 [????????????,????????????]區間的均勻分布的張量,
5. 創建序列
tf.range(start, limit, delta=1)可以創建[??????????,??????????),步長為 delta 的序列,不包含 limit 本身:tf.range(1,10,delta=2)
張量的典型應用
1.標量
在 TensorFlow 中,標量最容易理解,它就是一個簡單的數字,維度數為 0,shape 為 [],標量的典型用途之一是誤差值的表示、各種測量指標的表示,比如準確度(Accuracy, acc),精度(Precision)和召回率(Recall)等,
out = tf.random.uniform([4,10]) #隨機模擬網路輸出
y = tf.constant([2,3,2,0]) # 隨機構造樣本真實標簽
y = tf.one_hot(y, depth=10) # one-hot 編碼
loss = tf.keras.losses.mse(y, out) # 計算每個樣本的 MSE
loss = tf.reduce_mean(loss) # 平均 MSE
print(loss)
2.向量
向量是一種非常常見的資料載體,如在全連接層和卷積神經網路層中,偏置張量??就 使用向量來表示,如圖 所示,每個全連接層的輸出節點都添加了一個偏置值,把所有 輸出節點的偏置表示成向量形式:?? = [??1,??2]??,
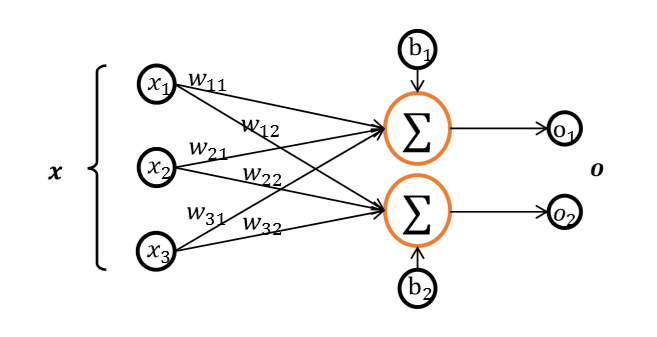
# z=wx,模擬獲得激活函式的輸入 z
z = tf.random.normal([4,2])
b = tf.zeros([2]) # 模擬偏置向量
z = z + b # 累加偏置(到這里 shape 為[4,2]的??和 shape 為[2]的??張量可以直接相加,這是為什么呢?讓我們在 Broadcasting 一節為大家揭秘)
通過高層介面類 Dense()方式創建的網路層,張量 W 和??存盤在類的內部,由類自動創 建并管理,可以通過全連接層的 bias 成員變數查看偏置變數??
fc = tf.keras.layers.Dense(3)# 創建一層 Wx+b,輸出節點為 3 (原書表述為:fc = layers.Dense(3) # 創建一層 Wx+b,輸出節點為 3,此處前提是:)
fc.build(input_shape=(2,4))# 通過 build 函式創建 W,b 張量,輸入節點為 4
fc.bias # 查看偏置
3.矩陣
矩陣也是非常常見的張量型別,比如全連接層的批量輸入?? = [??,??????],其中??表示輸入樣本的個數,即 batch size,??????表示輸入特征的長度,比如特征長度為 4,一共包含 2 個樣本的輸入可以表示為矩陣: x = tf.random.normal([2,4])
可以通過全連接層的 kernel 成員名查看其權值矩陣 W:
fc =tf.keras.layers.Dense(3) # 定義全連接層的輸出節點為 3(原書表述為layers.Dense(3))
fc.build(input_shape=(2,4)) # 定義全連接層的輸入節點為 4
fc.kernel
4.三維張量
三維的張量一個典型應用是表示序列信號,它的格式是 ?? = [??,???????????????? ??????,?????????????? ??????] 其中??表示序列信號的數量,sequence len 表示序列信號在時間維度上的采樣點數,feature len 表示每個點的特征長度,
為了能夠方便字串被神經網路處理,一般將單詞通過嵌入層(Embedding Layer)編碼為固定長度的向量,比如“a”編碼為某個長度 3 的向量,那么 2 個 等長(單詞數為 5)的句子序列可以表示為 shape 為[2,5,3]的 3 維張量,其中 2 表示句子個數,5 表示單詞數量,3 表示單詞向量的長度,
5.四維張量
我們這里只討論 3/4 維張量,大于 4 維的張量一般應用的比較少,如在元學習(meta learning)中會采用 5 維的張量表示方法,理解方法與 3/4 維張量類似,
4 維張量在卷積神經網路中應用的非常廣泛,它用于保存特征圖(Feature maps)資料, 格式一般定義為
[??,?,w,??]
其中??表示輸入的數量,h/w分布表示特征圖的高寬,??表示特征圖的通道數,部分深度學習框架也會使用[??,??,?, ]格式的特征圖張量,例如 PyTorch,圖片資料是特征圖的一種, 對于含有 RGB 3 個通道的彩色圖片,每張圖片包含了 h 行 w 列像素點,每個點需要 3 個數 值表示 RGB 通道的顏色強度,因此一張圖片可以表示為[h,w,3],
維度變換
基本的維度變換包含了改變視圖 reshape,插入新維度 expand_dims,洗掉維度squeeze,交換維度 transpose,復制資料 tile 等
1.Reshape
tf.reshape(x,[2,-1]) #其中的引數-1 表示當前軸上長度需要根據視圖總元素不變的法則自動推導,從而方便用戶書寫,
2.增刪維度
增加維度
一張 28x28 灰度圖片的資料保存為 shape 為[28,28]的張量,在末尾給張量增加一新維度,定義為為通道數維度,此時張量的 shape 變為[28,28,1]:
x = tf.random.uniform([28,28],maxval=10,dtype=tf.int32)
x = tf.expand_dims(x,axis=0)
洗掉維度
x = tf.squeeze(x, axis=0)
如果不指定維度引數 axis,即 tf.squeeze(x),那么他會默認洗掉所有長度為 1 的維度
3.交換維度
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,3,1,2])
'''
shape=(2, 3, 32, 32)
'''
4.資料復制
通過 tf.tile(b, multiples=[2,1])即可在 axis=0 維度復制 1 次,在 axis=1 維度不復制,
Broadcasting
Broadcasting 也叫廣播機制(自動擴展也許更合適),它是一種輕量級張量復制的手段,在邏輯上擴展張量資料的形狀,但是只要在需要時才會執行實際存盤復制操作,對于大部分場景,Broadcasting 機制都能通過優化手段避免實際復制資料而完成邏輯運算,從而相對于 tf.tile 函式,減少了大量計算代價,
A = tf.random.normal([32,1])
tf.broadcast_to(A, [2,32,32,3])
'''out
<tf.Tensor: id=13, shape=(2, 32, 32, 3), .....>
數學運算
1.加減乘除
加減乘除是最基本的數學運算,分別通過 tf.add, tf.subtract, tf.multiply, tf.divide 函式實現,TensorFlow 已經多載了+ −∗ /運算子,一般推薦直接使用運算子來完成加減乘除運算,整除和余除也是常見的運算之一,分別通過//和%運算子實作,
2.乘方
通過 tf.pow(x, a)可以方便地完成?? = ????乘方運算,也可以通過運算子**實作?? ∗∗ ??運算
對于常見的平方和平方根運算,可以使用 tf.square(x)和 tf.sqrt(x)實作,
3.指數、對數
通過 tf.pow(a, x)或者**運算子可以方便實作指數運算????,特別地,對于自然指數????,可以通過 tf.exp(x)實作
自然對數 log?? ??可以通過 tf.math.log(x)實作, 如果希望計算其他底數的對數,可以根據對數的換底公式
4.矩陣相乘
通過@運算子可以方便的實作矩陣相乘,還可以通過 tf.matmul(a, b)實作
TensorFlow 中的矩陣相乘可以使用批量方式,也就是張量 a,b 的維度數可以大于 2,當張量 a,b 維度數大于 2時,TensorFlow 會選擇 a,b 的最后兩個維度進行矩陣相乘,前面所有的維度都視作 Batch維度,
矩陣相乘函式支持自動 Broadcasting 機制
a = tf.random.normal([4,28,32])
b = tf.random.normal([32,16])
tf.matmul(a,b)
Out:
<tf.Tensor: id=264, shape=(4, 28, 16)........>
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/62242.html
標籤:其他
上一篇:C++模型部署影像預處理問題