在本地跑了個程式,中間第二個階段本應該是秒出 結果兩分鐘多才出結果,不知道哪里出現錯誤。有大神可以幫忙指正么?
uj5u.com熱心網友回復:
你要點進Stage,看看Task的資訊才知道uj5u.com熱心網友回復:
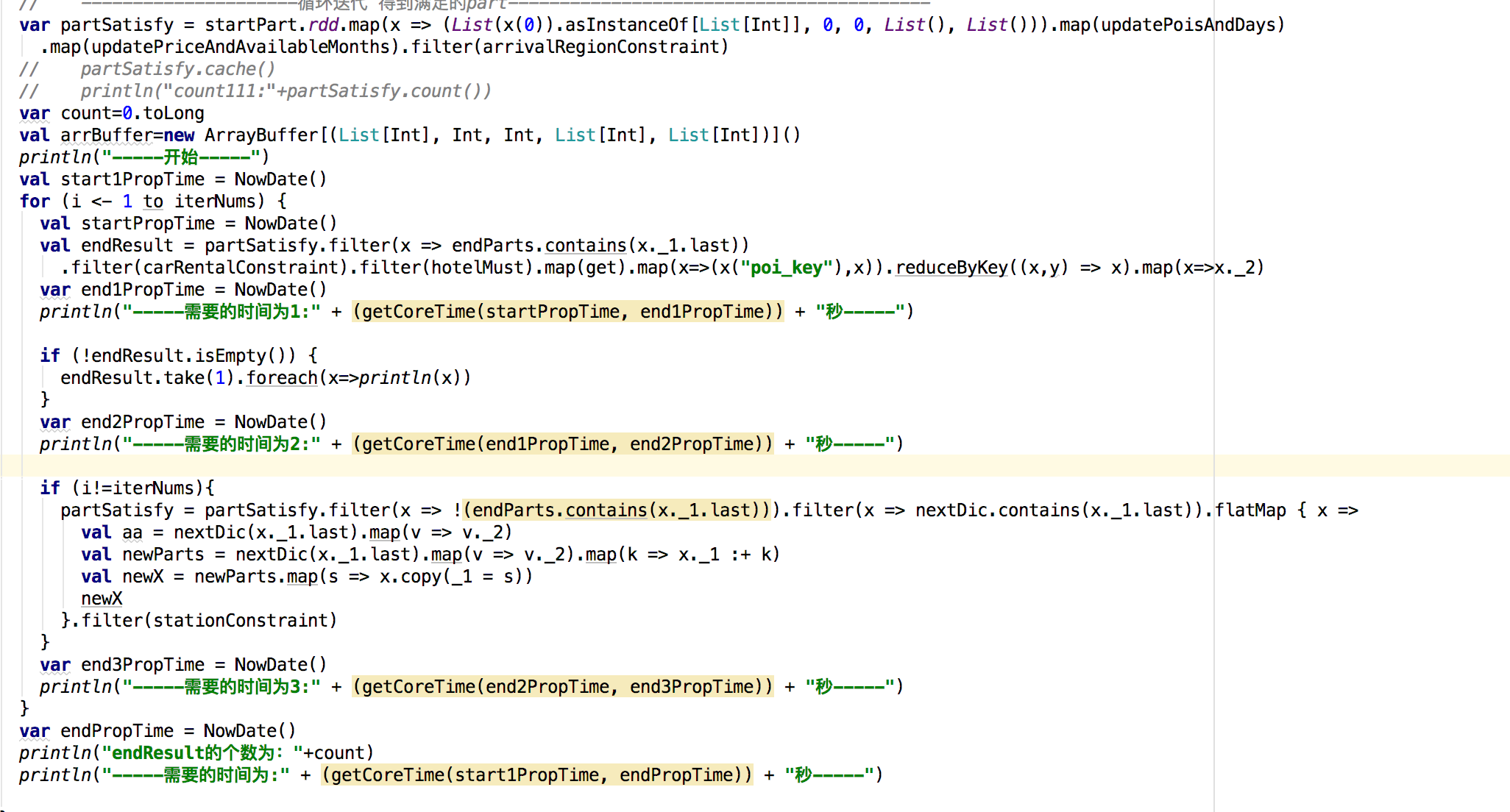
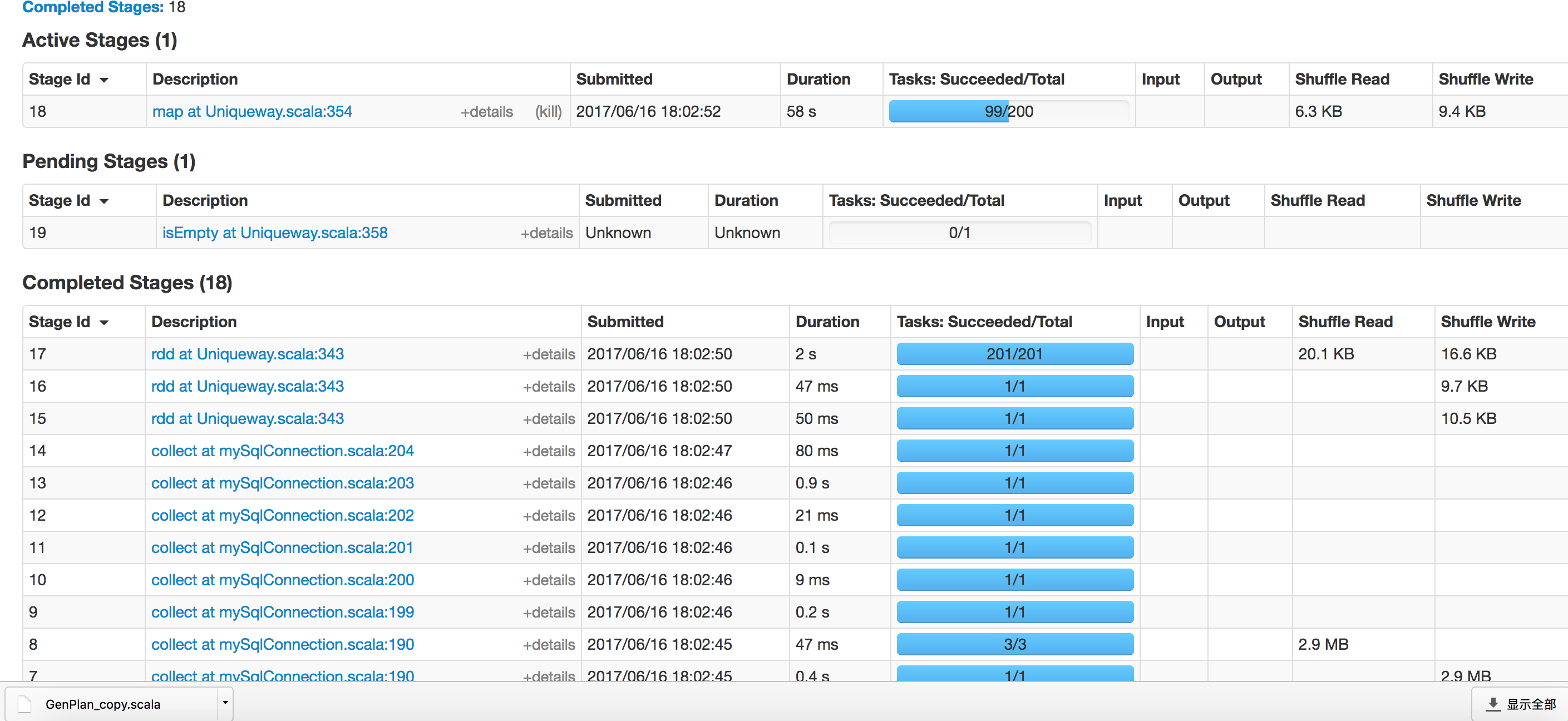
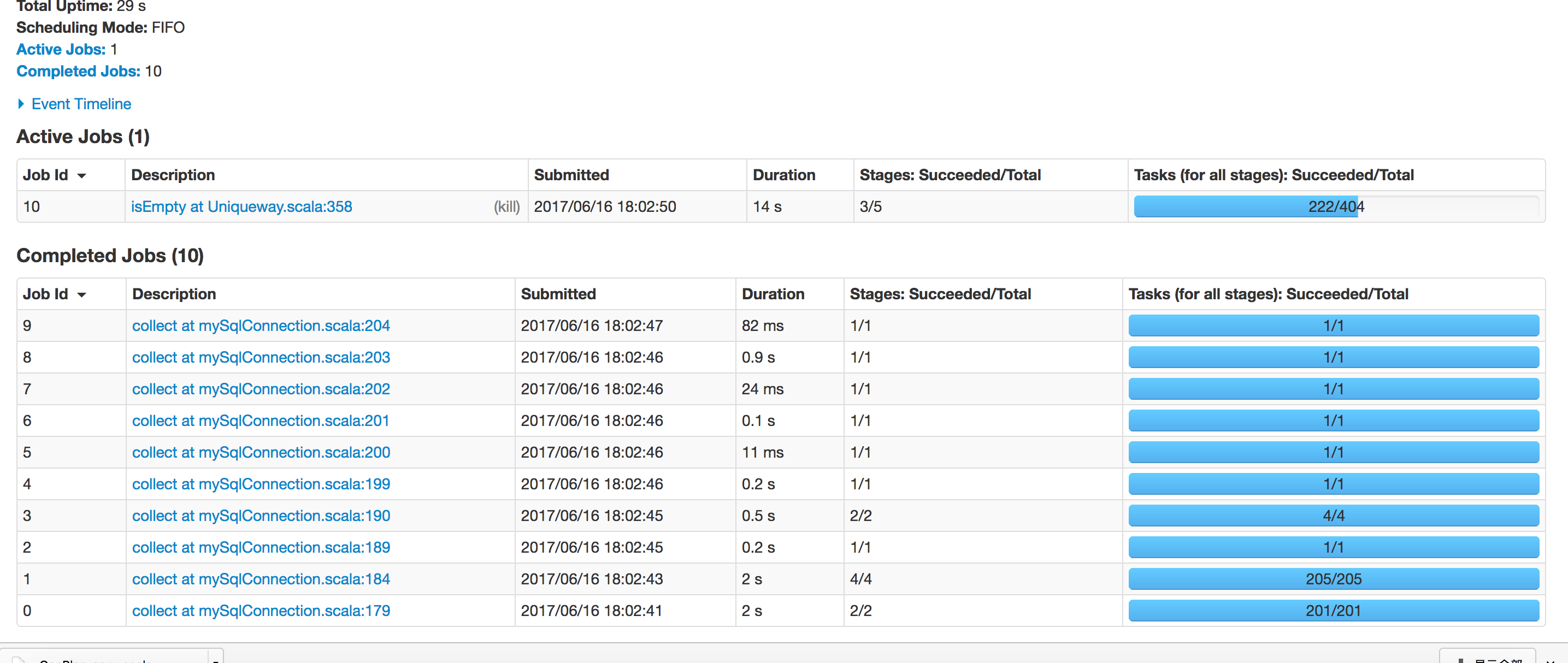
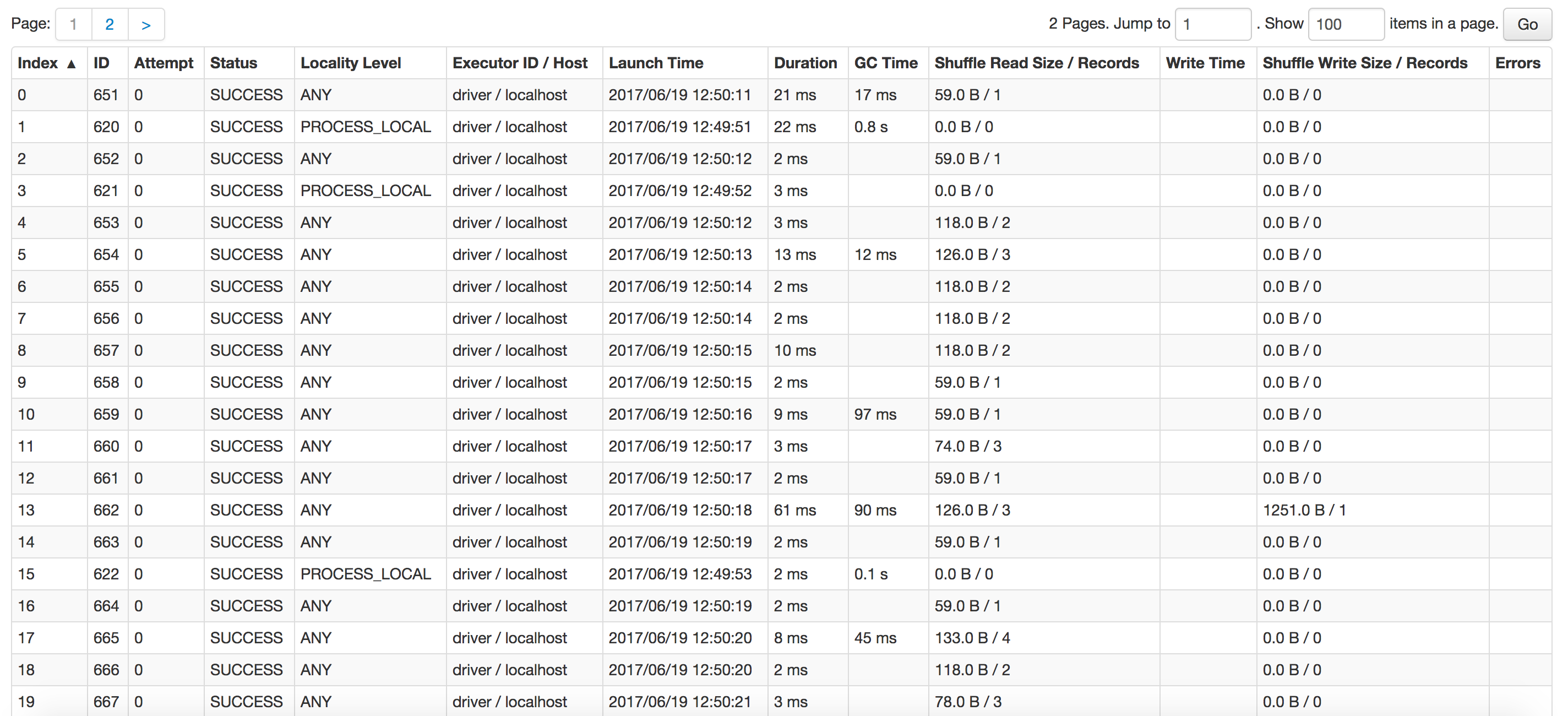
要具體看哪些資料呢 。。。。這是點進去的Task資訊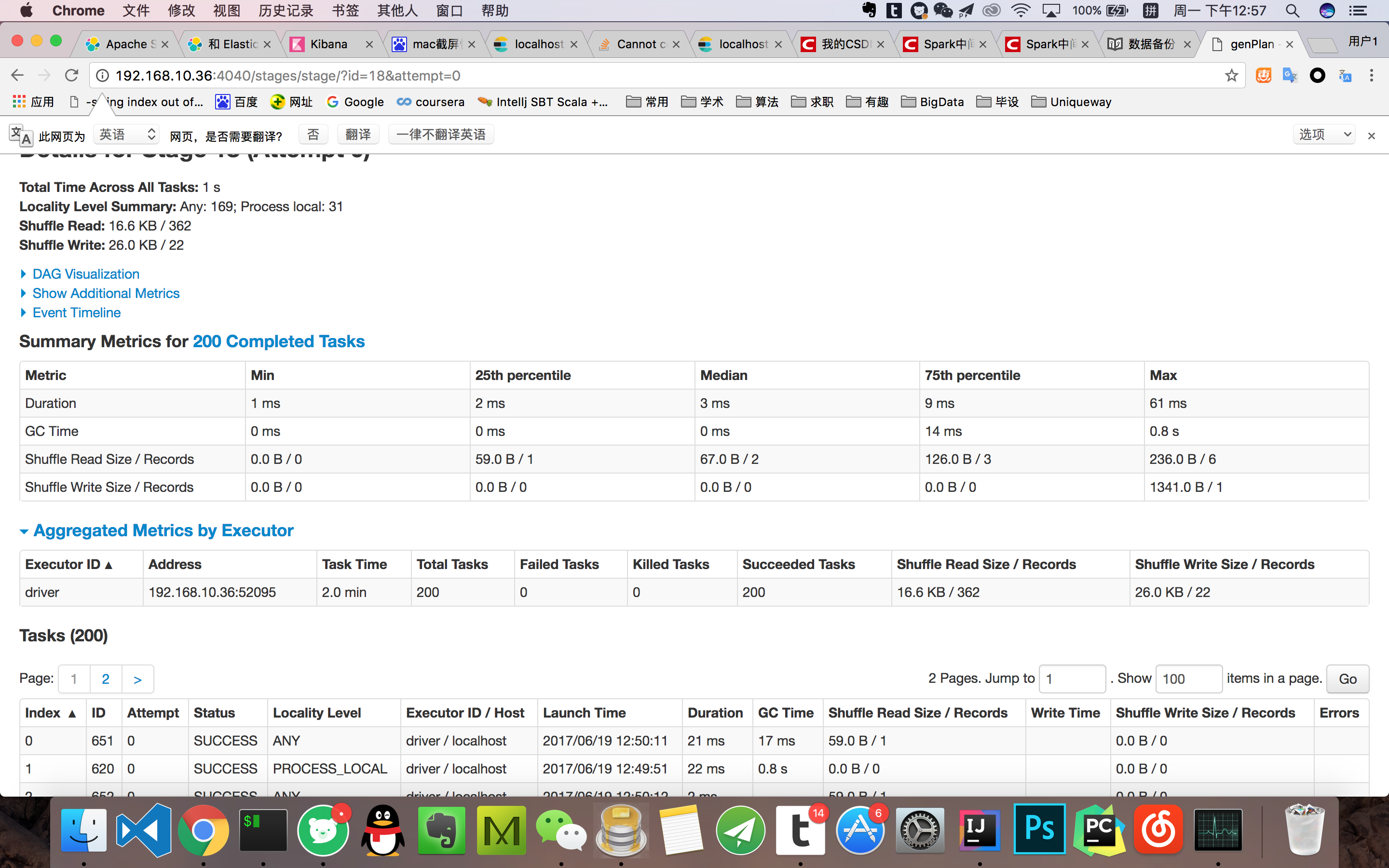
uj5u.com熱心網友回復:
我擦汗。。。你應該是沒理解Spark的執行邏輯。。。filter map flatMap等操作屬于transform,rdd經過若干的transform,直到action(如take count isEmpty foreach foreachPartition)才會真正執行。你計算的時間1沒有任何意義uj5u.com熱心網友回復:
嗯 關于這點其實我也知道 當初只是這么設定了而已。其實最開始的時候 迭代三次運行的時間也就是30秒,可現在不知道為什么 在每一輪的第二階段的時間就可以達到兩分鐘。迭代三次下來 那時間得有十分鐘了。中間我是曾經在reduceByKey前面加了repatition(3),后來又改了repartion(5),后來又改成了repartion(200),這個repartion應該是防止資料傾斜的吧 我用的又是單機 就一個節點。當時沒理解,就這么加上去了。達到200之后發現用時太長,然后就洗掉了。但是從此task就變成了200 ,第二階段時間也一直就成兩分鐘了 從新設定成repartition(3)也不好使。就不知道怎么回事
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/62920.html
標籤:Spark
下一篇:桌面云虛擬化和服務器虛擬化區別