面試官:談一談你對MySQL中的事物和MVCC的理解?
我:吧啦吧啦說了下面一堆,不過看面試官的臉色應該是被驚喜到了,
為什么要有事務
說到事務,不得不提到轉賬的事情,幾乎所有的關于事務的文章都會提到這個老掉牙的案例,我也不例外,
轉賬在資料庫層面可以簡單的抽象成兩個部分:
- 從自己的賬戶中扣除轉賬金額;
- 往對方賬戶中增加轉賬金額,
如果先從自己的賬戶中扣除轉賬金額,再往對方賬戶中增加轉賬金額,扣除執行成功,增加執行失敗,那自己的賬戶白白少了100塊,欲哭無淚,
如果先往對方賬戶中增加轉賬金額,再從自己的賬戶中扣除轉賬金額,增加執行成功,扣除執行失敗,那對方賬戶白白增加了100塊,自己的賬戶也沒有扣錢,喜大普奔,
不管是讓你欲哭無淚,還是喜大普奔,銀行都不會容忍這樣的事情發生,他們會引入事務來解決這類問題,
事務的特性
- 原子性(Atomicity):事務包含的所有操作要么全部成功(提交),要么全部失敗(回滾),
- 一致性(Consistency):事務的執行的前后資料的完整性保持一致,
- 隔離性(Isolation):一個事務執行的程序中,不應該受到其他事務的干擾,
- 持久性(Durability):事務一旦結束,資料就持久到資料庫,即使提交后,資料庫發生崩潰,也不會丟失提交的資料,
四種特性,簡稱ACID,其中最不好理解的就是一致性,有不少人認為原子性、隔離性、持久性就是為了保證一致性,我們也不搞學術研究,一致性到底該怎么解釋,到底怎么定義一致性,就看各位看官的了,
事務的隔離級別
從某個角度來說,我們可以控制的、或者說需要研究的只有隔離性這一個特性,而要控制隔離性,幾乎只有調整隔離級別這一個手段,下面我們就來看看事務的隔離級別,
資料庫是一個客戶端/服務器架構的軟體,每個客戶端與服務器連接后,就會產生一個session(會話),客戶端和服務器的互動就是在session中進行的,理論上來說,如果服務器同時只能處理一個事務,其他的事務都排隊等待,當該事務提交后,服務器才處理下一個事務,這樣才真正具有“隔離性”,什么問題都沒有了,但是如果是這樣,性能就太差了,在性能和隔離性之間,只能做一些平衡,所以資料庫提供了好幾個隔離級別供我們選擇,
在講隔離級別之前,我們先來看看事務并發執行會遇到什么問題,
為了保證下面的敘述可以順利進行,我們要先建一張表:
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年齡',
`grade` int(11) DEFAULT NULL COMMENT '年級',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;臟寫
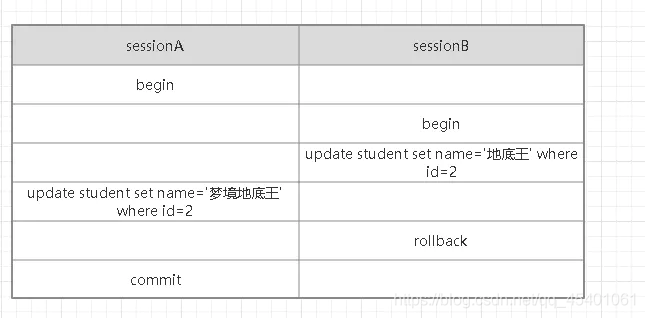
- sessionA和sessionB開啟了一個事務;
- sessionB把id=2的name修改成了“地底王”;
- sessionA把id=2的name修改成了“夢境地底王”;
- sessionB回滾了事務;
- sessionA提交了事務,
如果sessionB在回滾事務的時候把sessionA的修改也給回滾了,導致sessionA的提交丟失了,這種現象就被稱為“臟寫”,sessionA會一臉懵逼,我明明修改了資料,也提交了資料,為什么資料沒有變化呢,
臟讀
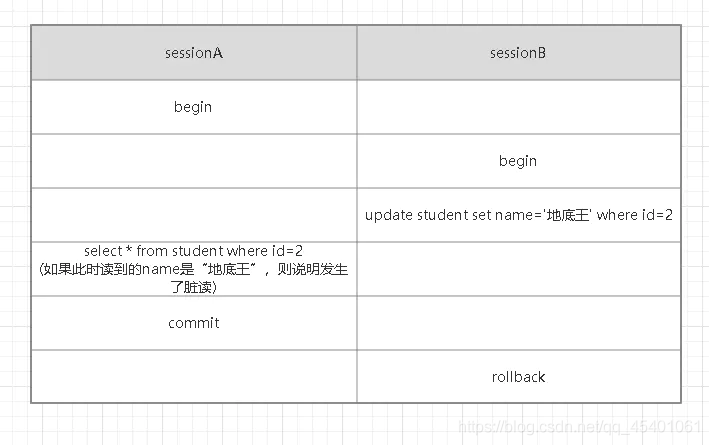
- sessionA和sessionB開啟了一個事務;
- sessionB把id=2的name修改成了“地底王”,此時還未提交;
- sessionA查詢了id=2的資料,如果讀出來的資料的name是“地底王”,也就是讀到了sessionB還沒有提交的資料,就被稱為“臟讀”,
不可重復讀
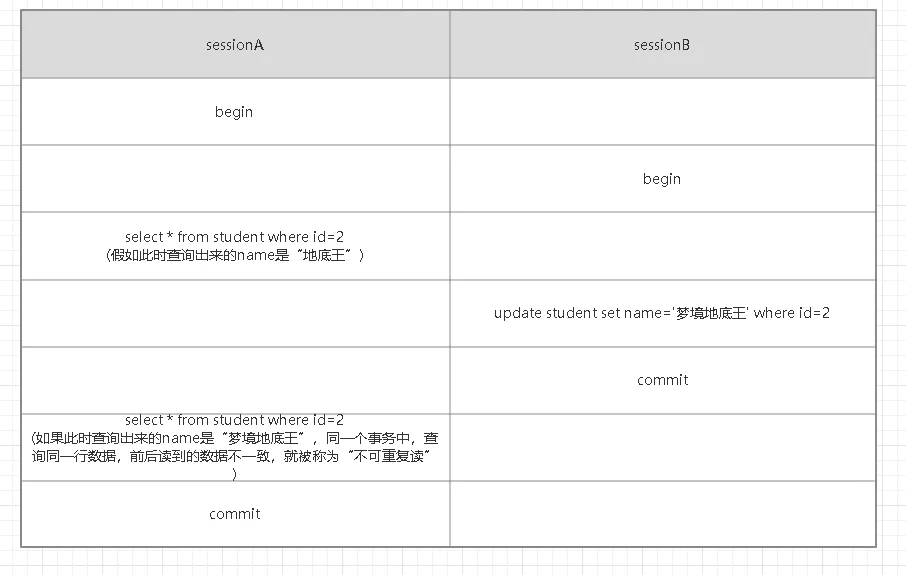
- sessionA和sessionB開啟了一個事務;
- sessionA查詢id=2的資料,假如name是“地底王”,
- sessionB把id=2的name修改成了“夢境地底王”,隨后提交了事務;
- sessionA再一次查詢了id=2的資料,如果name是“夢境地底王”,說明在同一個事務中,sessionA前后讀到的資料不一致,就被稱為“不可重復讀”,
幻讀
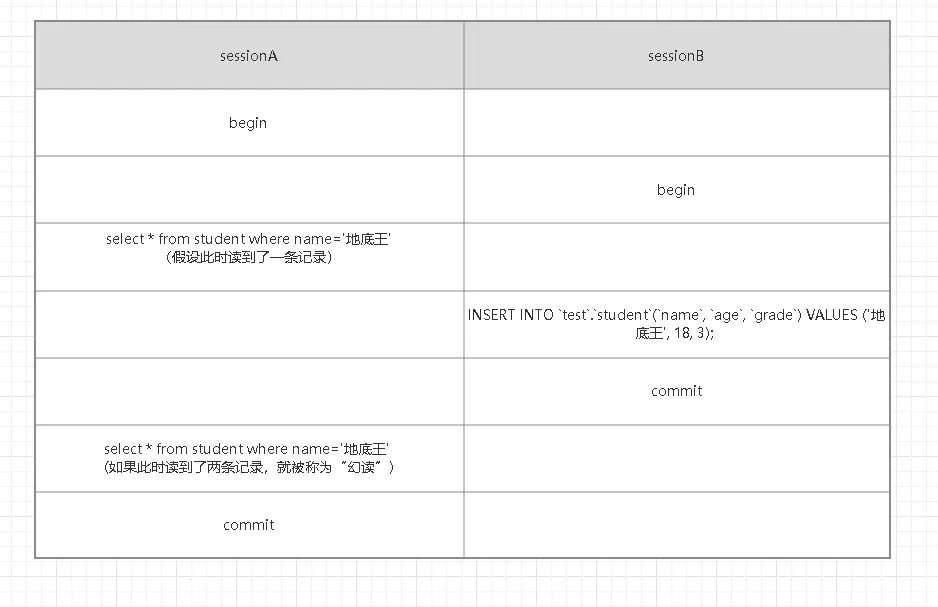
- sessionA和sessionB開啟了一個事務;
- sessionA查詢name=“地底王”的資料,假設此時讀到了一條記錄;
- sessionB又插入一條name=“地底王”的資料,隨后提交;
- seesionA再一次查詢name=“地底王”的資料,如果此時讀到了兩條記錄,第二次查詢讀到了第一次查詢未查詢出來的資料,就被稱為“幻讀”,
四種隔離級別
我們知道了在并發執行事務的時候,會遇到什么問題,有些問題比較嚴重,有些問題比較輕微,一般來說,我們認為按照嚴重性排序是這樣的:
臟寫>臟讀>不可重復讀>幻讀
在SQL標準定義中,設定了四種隔離級別,來解決上述的問題:
- 未提交讀(READ UNCOMMITTED): 最低的隔離級別,會有“臟讀”、“不可重復讀”,“幻讀”三個問題,
- 讀已提交(READ COMMITTED): SQLServer默認隔離級別,可以避免“臟讀”,會有“不可重復讀”,“幻讀”兩個問題,
- 可重復讀(REPEATABLE READ): 可以避免“臟讀”,“不可重復讀”兩個問題,會有“幻讀”問題, MySQL默認隔離級別,但是在MySQL中,此隔離級別解決了“幻讀”問題,
- 串行化(SERIALIZABLE): 所有的問題都不會發生,
因為臟寫的問題實在太嚴重了,在任何隔離級別下,都不會有臟寫的問題,
MVCC
前面說的都是開胃菜,相信大部分小伙伴對于上述內容都是手到擒來,所以我連如何修改事務隔離級別都沒有介紹,各種實驗也都沒有做,就是要把大量的時間、文字投入到這一部分內容中來,
MVCC,全稱是Mutil-Version Concurrency Control,翻譯成中文是多版本并發控制,MySQL就利用了MVCC來判斷在一個事務中,哪個資料可以被讀出來,哪個資料不能被讀出來,
多版本
在看MVCC之前,我們有必要知道另外一個知識點,資料庫存盤一行行資料,是分為兩個部分來存盤的,一個是資料行的額外資訊(本篇博客不涉及),一個是真實的資料記錄,MySQL會為每一行真實資料記錄添加兩三個隱藏的欄位:
- row_id 非必須,如果表中有自定義的主鍵或者有Unique鍵,就不會添加row_id欄位,如果兩者都沒有,MySQL會“自作主張”添加row_id欄位,
- transaction_id 必須,事務Id,代表這一行資料是由哪個事務id創建的,
- roll_pointer 必須,回滾指標,指向這行資料的上一個版本,
如下圖所示:
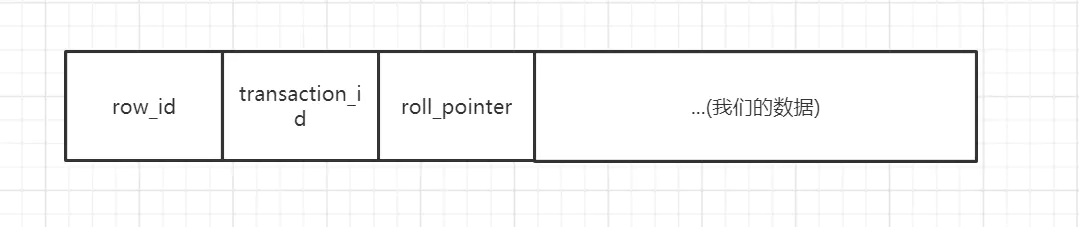
在這里需要著重說明下事務id,當我們開啟一個事務,并不會馬上獲得事務id,哪怕我們在事務中執行select陳述句,也是沒有事務id的(事務id為0),只有執行insert/update/delete陳述句才能獲得事務id,這一點尤為重要,
其中和MVCC緊密相關的是transaction_id和roll_pointer兩個欄位,在開發程序中,我們無需關心,但是要研究MVCC,我們必須關心,
如果有類似這樣的一行資料:
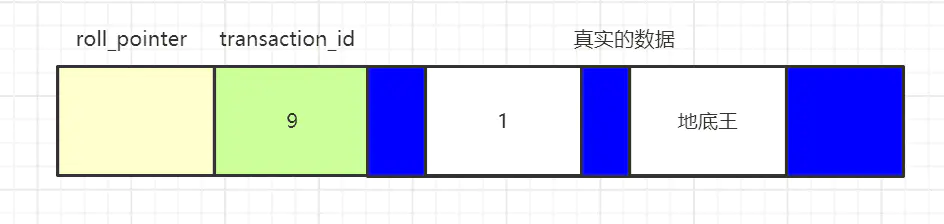
代表這行資料是由transaction_id為9的事務創建出來的,roll_pointer是空的,因為這是一條新紀錄,
實際上,roll_pointer并不是空的,如果真要解釋,需要繞一大圈,理解成空的,問題也不大,
當我們開啟事務,對這條資料進行修改,會變成這樣:
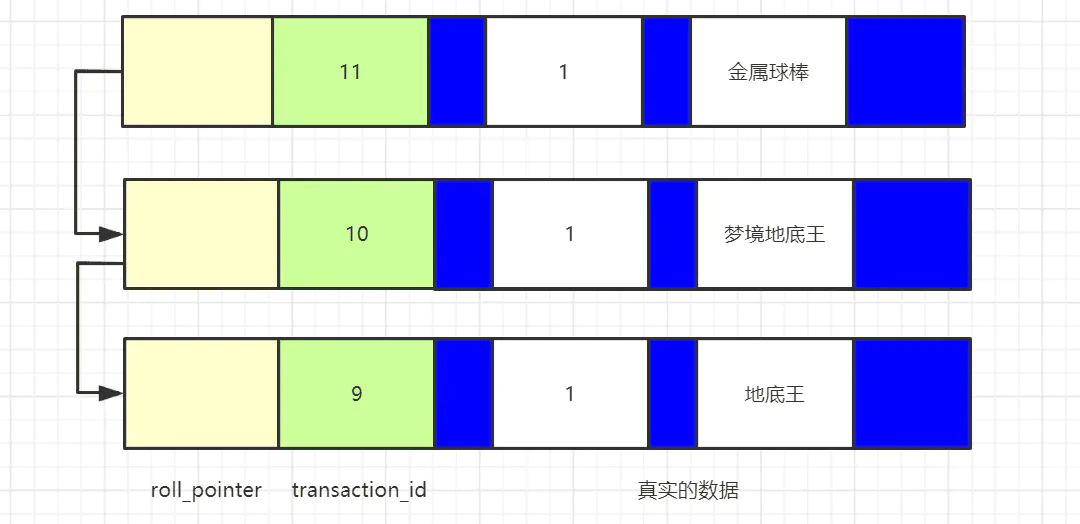
有點感覺了吧,這就像一個單向鏈表,稱之為“版本鏈”,最上面的資料是這個資料的最新版本,roll_pointer指向這個資料的舊版本,給人的感覺就是一行資料有多個版本,是不是符合“多版本并發控制”中的“多版本”這個概念, 那么“并發控制”又是怎么做到的呢,別急,繼續往下看,
ReadView
哎,下面又要引出一個新的概念:ReadView,
對于READ UNCOMMITTED來說,可以讀取到其他事務還沒有提交的資料,所以直接把這個資料的最新版本讀出來就可以了,對于SERIALIZABLE來說,是用加鎖的方式來訪問記錄,
剩下的就是READ COMMITTED和REPEATABLE READ,這兩個事務隔離級別都要保證讀到的資料是其他事務已經提交的,也就是不能無腦把一行資料的最新版本給讀出來了,但是這兩個還是有一定的區別,最核心的問題就在于“我到底可以讀取這個資料的哪個版本”,
為了解決這個問題,ReadView的概念就出現了,ReadView包含四個比較重要的內容:
- m_ids:表示在生成ReadView時,系統中活躍的事務id集合,
- min_trx_id:表示在生成ReadView時,系統中活躍的最小事務id,也就是 m_ids中的最小值,
- max_trx_id:表示在生成ReadView時,系統應該分配給下一個事務的id,
- creator_trx_id:表示生成該ReadView的事務id,
有了這個ReadView,只要按照下面的判斷方式就可以解決“我到底可以讀取這個資料的哪個版本”這個千古難題了:
- 如果被訪問的版本的trx_id和ReadView中的creator_trx_id相同,就意味著當前版本就是由你“造成”的,可以讀出來,
- 如果被訪問的版本的trx_id小于ReadView中的min_trx_id,表示生成該版本的事務在創建ReadView的時候,已經提交了,所以該版本可以讀出來,
- 如果被訪問版本的trx_id大于或等于ReadView中的max_trx_id值,說明生成該版本的事務在當前事務生成ReadView后才開啟,所以該版本不可以被讀出來,
- 如果生成被訪問版本的trx_id在min_trx_id和max_trx_id之間,那就需要判斷下trx_id在不在m_ids中:如果在,說明創建ReadView的時候,生成該版本的事務還是活躍的(沒有被提交),該版本不可以被讀出來;如果不在,說明創建ReadView的時候,生成該版本的事務已經被提交了,該版本可以被讀出來,
如果某個資料的最新版本不可以被讀出來,就順著roll_pointer找到該資料的上一個版本,繼續做如上的判斷,以此類推,如果第一個版本也不可見的話,代表該資料對當前事務完全不可見,查詢結果就不包含這條記錄了,
看完上面的描述,是不是覺得“云里霧里”,“不知所云”,甚至“腦闊疼,整個人都不好了”,
我們換個方法來解釋,看會不會更容易理解點:
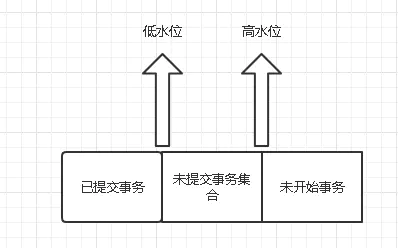
在事務啟動的一瞬間,會創建出ReadView,對于一個資料版本的trx_id來說,有以下三種情況:
- 如果落在低水位,表示生成這個版本的事務已經提交了,或者是當前事務自己生成的,這個版本可見,
- 如果落在高水位,表示生成這個版本的事務是未來才創建的,這個版本不可見,
- 如果落在中間水位,包含兩種情況: a. 如果當前版本的trx_id在活躍事務串列中,代表這個版本是由還沒有提交的事務生成的,這個版本不可見; b. 如果當前版本的trx_id不在活躍事務串列中,代表這個版本是由已經提交的事務生成的,這個版本可見,
上面我比較簡單的解釋了下ReadView,用了兩種方式來說明如何判斷當前資料版本是否可見,不知道各位看官是不是有了一個比較模糊的概念,有了ReadView的基本概念,我們就可以具體看下READ COMMITTED、REPEATABLE READ這兩個事務隔離級別為什么讀到的資料是不同的,以及上述規則是如何應用的,
READ COMMITTED——每次讀取資料都會創建ReadView
假設,現在系統只有一個活躍的事務T,事務id是100,事務中修改了資料,但是還沒有提交,形成的版本鏈是這樣的:
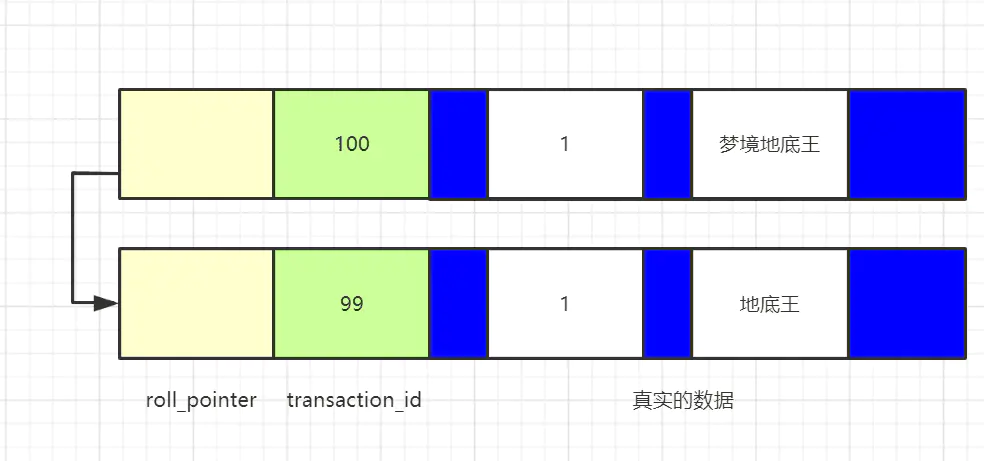
現在A事務啟動,并且執行了select陳述句,此時會創建出一個ReadView,m_ids是【100】,min_trx_id是100, max_trx_id是101,creator_trx_id是0,
為什么m_ids只有一個,為什么creator_trx_id是0?這里再次強調下,只有在事務中執行insert/update/delete陳述句才能獲得事務id,
那么A事務執行的select陳述句會讀到什么資料呢?
- 判斷最新的資料版本,name是“夢境地底王”,對應的trx_id是100,trx_id在m_ids里面,說明當前事務是活躍事務,這個資料版本是由還沒有提交的事務創建的,所以這個版本不可見,
- 順著roll_pointer找到這個資料的上一個版本,name是“地底王”,對應的trx_id是99,而ReadView中的min_trx_id是100,trx_id<min_trx_id,代表當前資料版本是由已經提交的事務創建的,該版本可見,
所以讀到的資料的name是“地底王”,
我們把事務T提交了,事務A再次執行select陳述句,此時,事務A再次創建出ReadView,m_ids是【】,min_trx_id是0, max_trx_id是101,creator_trx_id是0,
因為事務T已經提交了,所以沒有活躍的事務,
那么事務A第二次執行select陳述句又會讀到什么資料呢?
- 判斷最新的資料版本,name是“夢境地底王”,對應的trx_id是100,不在m_ids里面,說明這個資料版本是由已經提交的事務創建的,該版本可見,
所以讀到的資料的name是“夢境地底王”,
REPEATABLE READ ——首次讀取資料會創建ReadView
假設,現在系統只有一個活躍的事務T,事務id是100,事務中修改了資料,但是還沒有提交,形成的版本鏈是這樣的:
現在A事務啟動,并且執行了select陳述句,此時會創建出一個ReadView,m_ids是【100】,min_trx_id是100, max_trx_id是101,creator_trx_id是0,
那么A事務執行的select陳述句會讀到什么資料呢?
- 判斷最新的資料版本,name是“夢境地底王”,對應的trx_id是100,trx_id在m_ids里面,說明當前事務是活躍事務,這個資料版本是由還沒有提交的事務創建的,所以這個版本不可見,
- 順著roll_ponit找到這個資料的上一個版本,name是“地底王”,對應的trx_id是99,而ReadView中的min_trx_id是100,trx_id<min_trx_id,代表當前資料版本是由已經提交的事務創建的,該版本可見,
所以讀到的資料的name是“地底王”,
細心的你,一定發現了,這里我就是復制粘貼,因為在REPEATABLE READ事務隔離級別下,事務A首次執行select陳述句創建出來的ReadView和在READ COMMITTED事務隔離級別下,事務A首次執行select陳述句創建出來的ReadView是一樣的,所以判斷流程也是一樣的,所以我就偷懶了,copy走起,
隨后,事務T提交了事務,由于REPEATABLE READ是首次讀取資料才會創建ReadView,所以事務A再次執行select陳述句,不會再創建ReadView,用的還是上一次的ReadView,所以判斷流程和上面也是一樣的,所以讀到的name還是“地底王”,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/62968.html
標籤:其他