學習 SUSE Storage 系列文章
(1)SUSE Storage6 實驗環境搭建詳細步驟 - Win10 + VMware WorkStation
(2)SUSE Linux Enterprise 15 SP1 系統安裝
(3)SUSE Ceph 快速部署 - Storage6
(4)SUSE Ceph 增加節點、減少節點、 洗掉OSD磁盤等操作 - Storage6
(5)深入理解 DeepSea 和 Salt 部署工具 - Storage6
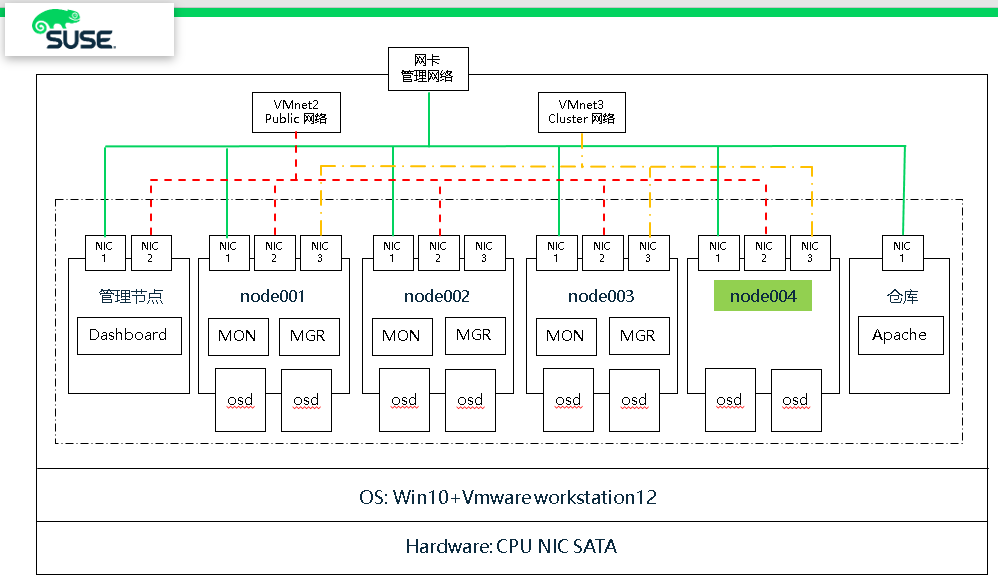
一、測驗環境描述
之前我們已快速部署好一套Ceph集群(3節點),現要測驗在現有集群中在線方式增加節點
- 如下表中可以看到增加節點node004具體配置
主機名 | Public網路 | 管理網路 | 集群網路 | 說明 |
admin | 192.168.2.39 | 172.200.50.39 | --- | 管理節點 |
node001 | 192.168.2.40 | 172.200.50.40 | 192.168.3.40 | MON,OSD |
node002 | 192.168.2.41 | 172.200.50.41 | 192.168.3.41 | MON,OSD |
node003 | 192.168.2.42 | 172.200.50.42 | 192.168.3.42 | MON,OSD |
node004 | 192.168.2.43 | 172.200.50.43 | 192.168.3.43 | OSD |
- 測驗集群架構圖
可以看到架構圖中增加了node004節點,并且node004節點只是作為OSD節點,并無MON或MGR服務
二、增加集群節點 node004
1、收集集群資訊
(1)集群狀態
# ceph -s cluster: id: f7b451b3-4a4c-4681-a4ef-4b5359242a92 health: HEALTH_OK services: mon: 3 daemons, quorum node001,node002,node003 (age 90m) mgr: node001(active, since 89m), standbys: node002, node003 osd: 6 osds: 6 up (since 90m), 6 in (since 23h) data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 12 GiB used, 48 GiB / 60 GiB avail pgs:
(2)集群OSD磁盤資訊
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.05878 root default -5 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000-3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000-7 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000
(3)查看新增節點磁盤
# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 20G 0 disk├─sda1 8:1 0 1G 0 part /boot└─sda2 8:2 0 19G 0 part ├─vgoo-lvswap 254:0 0 2G 0 lvm [SWAP] └─vgoo-lvroot 254:1 0 17G 0 lvm /sdb 8:16 0 10G 0 disksdc 8:32 0 10G 0 disksr0 11:0 1 1024M 0 rom nvme0n1 259:0 0 20G 0 disknvme0n2 259:1 0 20G 0 disknvme0n3 259:2 0 20G 0 disk
2、初始化作業系統
(1)初始化步驟
參考快速部署 storage6 檔案
(2)顯示倉庫
# zypper lrRepository priorities are without effect. All enabled repositories share the same priority.# | Alias | Name | Enabled | GPG Check | Refresh---+----------------------------------------------------+----------------------------------------------------+---------+-----------+-------- 1 | SLE-Module-Basesystem-SLES15-SP1-Pool | SLE-Module-Basesystem-SLES15-SP1-Pool | Yes | (r ) Yes | No 2 | SLE-Module-Basesystem-SLES15-SP1-Upadates | SLE-Module-Basesystem-SLES15-SP1-Upadates | Yes | (r ) Yes | No 3 | SLE-Module-Legacy-SLES15-SP1-Pool | SLE-Module-Legacy-SLES15-SP1-Pool | Yes | (r ) Yes | No 4 | SLE-Module-Legacy-SLES15-SP1-Updates | SLE-Module-Legacy-SLES15-SP1-Updates | Yes | ( p) Yes | No 5 | SLE-Module-Server-Applications-SLES15-SP1-Pool | SLE-Module-Server-Applications-SLES15-SP1-Pool | Yes | (r ) Yes | No 6 | SLE-Module-Server-Applications-SLES15-SP1-Upadates | SLE-Module-Server-Applications-SLES15-SP1-Upadates | Yes | (r ) Yes | No 7 | SLE-Product-SLES15-SP1-Pool | SLE-Product-SLES15-SP1-Pool | Yes | (r ) Yes | No 8 | SLE-Product-SLES15-SP1-Updates | SLE-Product-SLES15-SP1-Updates | Yes | (r ) Yes | No 9 | SUSE-Enterprise-Storage-6-Pool | SUSE-Enterprise-Storage-6-Pool | Yes | (r ) Yes | No 10 | SUSE-Enterprise-Storage-6-Updates | SUSE-Enterprise-Storage-6-Updates | Yes | (r ) Yes | No
(3)hosts檔案
192.168.2.39 admin.example.com admin192.168.2.40 node001.example.com node001192.168.2.41 node002.example.com node002192.168.2.42 node003.example.com node003192.168.2.43 node004.example.com node004192.168.2.44 node005.example.com node005
3、安裝 satlt-minion
- node004節點
zypper -n in salt-minionsed -i '17i\master: 192.168.2.39' /etc/salt/minionsystemctl restart salt-minion.servicesystemctl enable salt-minion.servicesystemctl status salt-minion.service
- admin節點
# salt-keyAccepted Keys:admin.example.comnode001.example.comnode002.example.comnode003.example.comDenied Keys:Unaccepted Keys:node004.example.com <==== 新加節點Rejected Keys:
- 接受key
# salt-key -A
- 測驗node004
# salt "node004*" test.pingnode004.example.com: True
4、預防集群資料平衡
- 以前增加節點的時候,一直使用norebalance方式來預防資料平衡,這種方式比較簡單粗暴,(不建議使用)
# ceph osd set norebalancenorebalance is setadmin:/etc/salt/pki/master # ceph -s cluster: id: f7b451b3-4a4c-4681-a4ef-4b5359242a92 health: HEALTH_WARN norebalance flag(s) set
services:
mon: 3 daemons, quorum node001,node002,node003 (age 2h)
mgr: node001(active, since 2h), standbys: node002, node003
osd: 6 osds: 6 up (since 2h), 6 in (since 24h)
flags norebalance
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 12 GiB used, 48 GiB / 60 GiB avail
pgs:
- 建議使用 “osd_crush_initial_weight”引數,結合salt工具批量執行
(1)新建 global.conf 檔案(admin節點)
# vim /srv/salt/ceph/configuration/files/ceph.conf.d/global.confosd_crush_initial_weight = 0
(2)創建新組態檔(admin節點)
# salt '*' state.apply ceph.configuration.create
注意:執行時有報錯,可忽略
node003.example.com: Name: /var/cache/salt/minion/files/base/ceph/configuration - Function: file.absent - Result: Changed Started: - 15:42:45.362265 Duration: 22.133 ms---------- ID: /srv/salt/ceph/configuration/cache/ceph.conf Function: file.managed Result: False Comment: Unable to manage file: Jinja error: 'select.minions' Traceback (most recent call last): File "/usr/lib/python3.6/site-pack
(3)執行新組態檔,并且只在node001 node002 node003節點上生效 (admin節點)
# salt 'node00[1-3]*' state.apply ceph.configuration
(4)檢查個節點組態檔 (node001,node002,node003)
# cat /etc/ceph/ceph.confosd crush initial weight = 0
5、執行stage0 1 2 (admin節點)
# salt-run state.orch ceph.stage.0# salt-run state.orch ceph.stage.1# salt-run state.orch ceph.stage.2# salt 'node004*' pillar.items # 查看pillar設定是否正確 public_network: 192.168.2.0/24 roles: - storage # 僅僅是 storage 角色 time_server: admin.example.com
6、檢查生成 OSD 報告(admin節點)
# salt-run disks.report node004.example.com: |_ - 0 - Total OSDs: 2 Solid State VG: Targets: block.db Total size: 19.00 GB Total LVs: 2 Size per LV: 1.86 GB Devices: /dev/nvme0n2 Type Path LV Size % of device ------------------------------------------------------------------------- [data] /dev/sdb 9.00 GB 100.0% [block.db] vg: vg/lv 1.86 GB 10% ------------------------------------------------------------------------- [data] /dev/sdc 9.00 GB 100.0% [block.db] vg: vg/lv 1.86 GB 10%
7、運行stage3, 把node004節點添加進來,并自動創建OSD (admin節點)
# salt-run state.orch ceph.stage.38、執行后檢查集群OSD狀態 (admin節點)
可以發現新增節點權重都是0,這是由于之前配置的“osd_crush_initial_weight”引數,預防新增節點或磁盤進來時進行資料平衡,
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.05878 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000-3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000-5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000-9 0 host node004 6 hdd 0 osd.6 up 1.00000 1.00000 <=== 新增節點OSD權重為0 7 hdd 0 osd.7 up 1.00000 1.00000
9、手動增加OSD磁盤權重 (admin節點)
注意:生產環境請在變更時間執行,執行時會資料平衡,影響讀寫,當然也可以通過Ceph引數或QOS來控制讀寫速率,后續檔案中會提到,
# ceph osd crush reweight osd.6 0.00980# ceph osd crush reweight osd.7 0.00980
# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.07837 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 -3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 -9 0.01959 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000 7 hdd 0.00980 osd.7 up 1.00000 1.00000
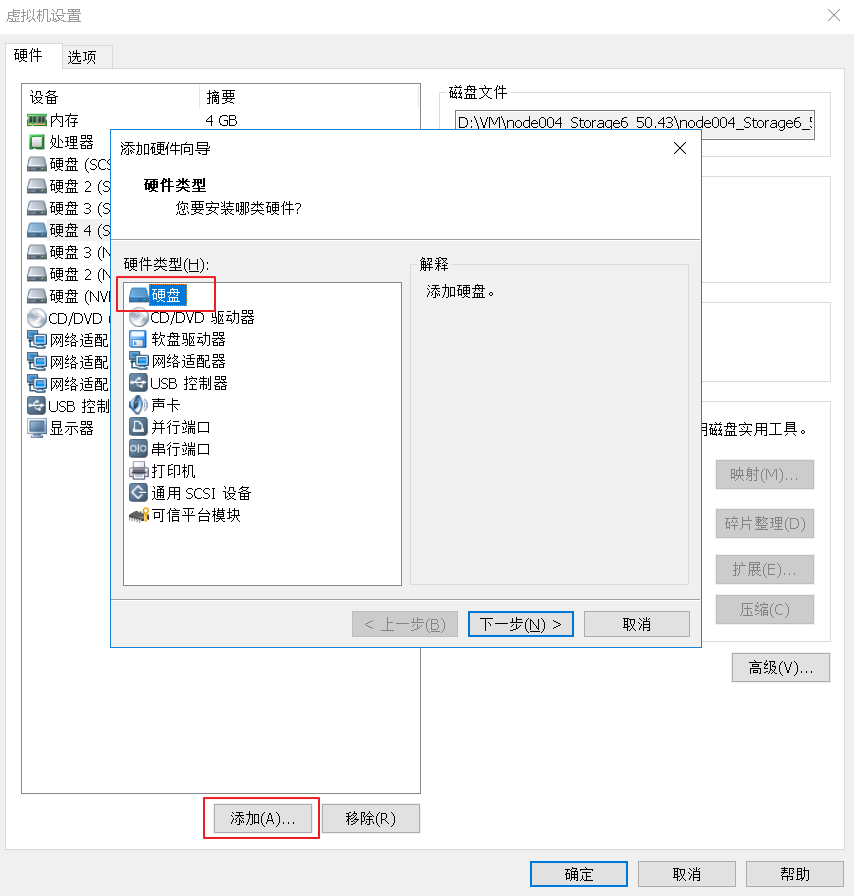
三、增加 OSD 磁盤操作
1、首先我們通過 VMware workstation 的虛擬機 node004 節點上添加一塊10G大小的磁盤
2、開啟虛擬機后,node004主機終端中查看新增磁盤
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot└─sda2 8:2 0 19G 0 part ├─vgoo-lvroot 254:0 0 17G 0 lvm / └─vgoo-lvswap 254:1 0 2G 0 lvm [SWAP]sdb 8:16 0 10G 0 disk └─ceph--block--0515f9d7--3407--46a5-- 254:4 0 9G 0 lvm sdc 8:32 0 10G 0 disk └─ceph--block--9f7394b2--3ad3--4cd8-- 254:5 0 9G 0 lvm sdd 8:48 0 10G 0 disk <== 新增磁盤sr0 11:0 1 1024M 0 rom nvme0n1 259:0 0 20G 0 disk nvme0n2 259:1 0 20G 0 disk ├─ceph--block--dbs--57d07a01--4440--4 254:2 0 1G 0 lvm └─ceph--block--dbs--57d07a01--4440--4 254:3 0 1G 0 lvm nvme0n3 259:2 0 20G 0 disk
3、查看 VG LV 資訊
# lvs LV VG Attr LSize osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-ao---- 9.00g osd-block-79f5920f-b41c-4dd0-94e9-dc85dbb2e7e4 ceph-block-9f7394b2-3ad3-4cd8-8267-7e5993af1271 -wi-ao---- 9.00g osd-block-db-2244293e-ca96-4847-a5cb-9112f59836fa ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g osd-block-db-test ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 2.00g lvroot vgoo -wi-ao---- 17.00g lvswap vgoo -wi-ao---- 2.00g
4、創建 OSD 磁盤的 VG 和 LV
# vgcreate ceph-block-0 /dev/sdd# lvcreate -l 100%FREE -n block-0 ceph-block-0
5、在已在nvme0n2磁盤上創建的 VG 上創建 LV
我們從第3個步驟中可以看到,nvme0n2磁盤已經被 VG ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586所使用,我們要在該VG上創建LV,因為一般一塊PCIE SSD磁盤可以承擔10塊OSD資料磁盤,作為他們WAL和DB加速磁盤使用,
# lvcreate -L 2GB -n db-0 ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586
6、顯示 VG LV 資訊
# lvs LV VG Attr LSize block-0 ceph-block-0 -wi-a----- 10.00g osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-ao---- 9.00g osd-block-79f5920f-b41c-4dd0-94e9-dc85dbb2e7e4 ceph-block-9f7394b2-3ad3-4cd8-8267-7e5993af1271 -wi-ao---- 9.00g db-0 ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 2.00g osd-block-db-2244293e-ca96-4847-a5cb-9112f59836fa ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g lvroot vgoo -wi-ao---- 17.00g lvswap vgoo -wi-ao---- 2.00g
7、使用 ceph-volume 方式創建
- 這次我們通過另一種方式來創建,而不是使用 drive group 方式,因為你需要了解到一旦自動化工具出現問題時如何處理和創建OSD
# ceph-volume lvm create --bluestore --data ceph-block-0/block-0 --block.db ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586/db-0
- 管理節點上,查看OSD輸出資訊
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.07837 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 -3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 -9 0.01959 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000 7 hdd 0.00980 osd.7 up 1.00000 1.00000 8 hdd 0 osd.8 up 1.00000 1.00000 <==== 可以看到 osd.8 被創建出來
8、設定權重
注意:生產環境操作時,會資料平衡會影響到讀寫性能,
# ceph osd crush reweight osd.8 0.00980
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.08817 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 -3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 -9 0.02939 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000 7 hdd 0.00980 osd.7 up 1.00000 1.00000 8 hdd 0.00980 osd.8 up 1.00000 1.00000
四、洗掉OSD磁盤
語法: salt-run osd.remove OSD_ID
1、批量洗掉 node004 節點上 OSD.7 OSD.8
admin:~ # ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.08817 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 -3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 -9 0.02939 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000 7 hdd 0.00980 osd.7 up 1.00000 1.00000 8 hdd 0.00980 osd.8 up 1.00000 1.00000
admin:~ # salt-run osd.remove 7 8Removing osd 7 on host node004.example.comDraining the OSDWaiting for ceph to catch up.osd.7 is safe to destroyPurging from the crushmapZapping the deviceRemoving osd 8 on host node004.example.comDraining the OSDWaiting for ceph to catch up.osd.8 is safe to destroyPurging from the crushmapZapping the device
2、顯示 osd 資訊,node004主機上 osd.7 和 osd.8 已被洗掉
admin:~ # ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.06857 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 -3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 -9 0.00980 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000
3、洗掉 OSD 其他命令
(1)洗掉節點上所有osd
# salt-run osd.remove OSD_HOST_NAME
(2)當 WAL 或 DB 設備損壞時,移除破損的磁盤
# salt-run osd.remove OSD_ID force=True
四、減少集群節點
從集群中移出node004 osd節點,移除前請確保集群有足夠的空間容納node004上的資料
1、手動方式
(1)管理節點查看 OSD 資訊
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.06857 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000-3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000-5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000-9 0.00980 host node004 6 hdd 0.00980 osd.6 up 1.00000 1.00000
(2)node004 節點上停止OSD服務
# systemctl stop ceph-osd@6.service # systemctl stop ceph-osd.target
(3)node004 節點上,卸載掛載目錄
# umount /var/lib/ceph/osd/ceph-6
(4)admin節點上,移除OSD
# ceph osd out 6# ceph osd crush remove osd.6# ceph osd rm osd.6# ceph auth del osd.6
(5)admin節點上,從CRUSH MAP上移除節點資訊
# ceph osd crush rm node004(6)檢查集群是否清理干凈node004
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.05878 root default -7 0.01959 host node001 2 hdd 0.00980 osd.2 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000-3 0.01959 host node002 0 hdd 0.00980 osd.0 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000-5 0.01959 host node003 1 hdd 0.00980 osd.1 up 1.00000 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000
(7)node004節點,洗掉所有相關 VG LV 資訊
- 查看node004節點 VG LV 資訊
node004:~ # vgs VG #PV #LV #SN Attr VSize VFree ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc 1 1 0 wz--n- 9.00g 0 ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 1 1 0 wz--n- 19.00g 18.00g vg00 1 2 0 wz--n- 19.00g 0
node004:~ # lvs LV VG Attr LSize osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-a----- 9.00g osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 1.00g lvroot vg00 -wi-ao---- 17.00g lvswap vg00 -wi-ao---- 2.00g
- 洗掉相關VG LV
# for i in `vgs | grep ceph- | awk '{ print $1 }'`; do vgremove -f $i; done
- 洗掉后查看VG LV 資訊
node004:~ # lvs LV VG Attr LSize lvroot vg00 -wi-ao---- 17.00g lvswap vg00 -wi-ao---- 2.00g
node004:~ # vgs VG #PV #LV #SN Attr VSize VFree vg00 1 2 0 wz--n- 19.00g 0
2、DeepSea 方式
(1)管理節點上修改 policy.cfg 檔案
vim /srv/pillar/ceph/proposals/policy.cfg## Cluster Assignment#cluster-ceph/cluster/*.sls <=== 注釋掉cluster-ceph/cluster/node00[1-3]*.sls <=== 匹配 targetcluster-ceph/cluster/admin*.sls <=== 匹配 target## Roles# ADMIN role-master/cluster/admin*.slsrole-admin/cluster/admin*.sls# Monitoringrole-prometheus/cluster/admin*.slsrole-grafana/cluster/admin*.sls# MONrole-mon/cluster/node00[1-3]*.sls# MGR (mgrs are usually colocated with mons)role-mgr/cluster/node00[1-3]*.sls# COMMONconfig/stack/default/global.ymlconfig/stack/default/ceph/cluster.yml# Storage # 定義為 storage 角色#role-storage/cluster/node00*.sls <=== 注釋掉role-storage/cluster/node00[1-3]*.sls <=== 匹配 target
(2)修改 drive_group.yml 檔案
# vim /srv/salt/ceph/configuration/files/drive_groups.yml# This is the default configuration and# will create an OSD on all available drivesdrive_group_hdd_nvme: target: 'node00[1-3]*' <== 匹配 target data_devices: size: '9GB:12GB' db_devices: rotational: 0 limit: 1 block_db_size: '2G'
(3)執行salt命令,stage2和stage5
# salt-run state.orch ceph.stage.2# salt-run state.orch ceph.stage.5

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/63711.html
標籤:其他
上一篇:感知機算例