這篇學習筆記強調幾何直覺,同時也注重感知機演算法內部的動機,限于篇幅,這里僅僅討論了感知機的一般情形、損失函式的引入、作業原理,關于感知機的對偶形式和核感知機,會專門寫另外一篇文章 感知機實戰篇請看這里,關于感知機的實作代碼,亦不會在這里出現,會有一篇專門的文章介紹如何撰寫代碼實作感知機,那里會有幾個使用感知機做分類的小案例,
感知機演算法是經典的神經網路模型,雖然只有一層神經網路,但前向傳播的思想已經具備,究其本質,感知機指這樣一個映射函式:\(sign(w_ix_i + b)\),將資料帶進去計算可以得到輸出值,通過比較輸出值和資料原本對應的標簽值是否正負號相同從而推斷出模型訓練的結果,
1. 何為感知機?
接上面的敘述,感知機的數學模型為\(sign(w_ix_i + b)\),其中\(w = (w_1,w_2,...,w_n)\)是權重向量,\(x_i = (x_i^{1},x_i^{2},...,x_i^{n})\)是一個樣本點,從符號很容易理解,它們都是定義在\(R^n\)空間的(如果難以理解,可以簡單的理解為樣本點有\(n\)個維度,相應的權重向量也須有\(n\)個維度和它相匹配).
下面是一副經典的感知機模型圖:
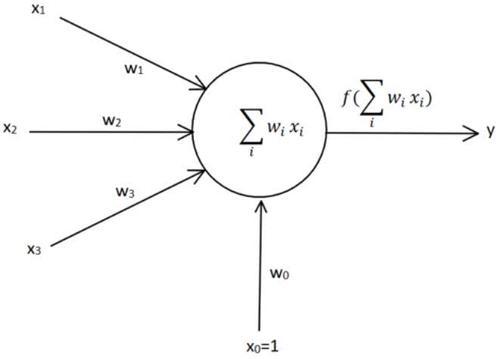
最左邊的表示輸入一個樣本點的特征向量,通過各自的權重前向傳播到神經元,在神經元有一個加法器,最后通過一個激活函式來決定是否激活,最下面的\(x_0\)是bias項,一般文獻中記為\(b\),
2. 感知機可以解決什么問題?
這里我們可以看一個經典的例子,利用感知機模型來解決經典的\(OR問題\),
【例1】設有4個樣本點,\((0,0),(0,1),(1,0),(1,1)\),根據\(OR\)的邏輯,必須至少有一個不為\(0\)才能判定為真,翻譯成機器學習的表達即標簽為\((-1,1,1,1)\),這里負數表示負樣本,正數表示正樣本,

我們希望的是能找到一條直線(分類器),將正負樣本點準確分開,根據\(\S1\)中的敘述,樣本點是定義在\(R^2\)空間的,顯然權重向量為\(w = (w_1,w_2)\),考慮偏置項\(b\),一般添補一個\(x_i^{0}\)為\(-1\)以便把式子\(\sum\limits_{1}^{n} w_ix_i + b\)直接寫成\(\sum\limits_{0}^{n}w_ix_i\),先給出權重更新公式$ w_{ij} ← w_{ij} ? η(y_{j} ? t_{j} ) · x_i $, 稍后會給出解釋,
設定權重初值為\(w = (0,0)\),并且約定當且僅當\(sign(x=0)=0\),算作誤分類,依次代入樣本點:
-
代入\((0,0)\)點,\(sign(wx + b) = sign(0 * 0 + 0 * 0 + 0*(-1)) = 0\),無法判定是否為負類,錯誤,
-
更新權重
\(b = 0 - 1 * (1-0) * (-1)=1\)
\(w_1 = 0 - 1 * (1-0) * 0=0\)
\(w_2 = 0 - 1 * (1-0) * 0=0\)
-
-
代入\((0,1)\)點,\(sign(wx + b) = sign(0 * 0 + 0 * 1 +1 *(-1)) = -1\),判定為負類,錯誤,
-
更新權重
\(b = 1 - 1 * (1 - (-1)) * (-1) = -1\)
\(w_1 = 0 - 1 * (1 - (-1))*0 = 0\)
\(w_2 = 0 - 1*(1-(-1))*1 = 2\)
-
-
代入\((1,0)\)點,\(sign(wx+b)=sign(0 * 1 + 2 * 0 + (-1) * (-1))= 1\),判定為正類,正確,
-
代入\((1,1)\)點,\(sign(wx + b)=sign(0 * 1 + 2 * 1 + (-1)* -1)=3\),判定為正類,正確,
-
第二輪遍歷,代入\((0,0)\),\(sign(0*0 + 2*0 + (-1)*-1)=1\),無法判定是否為負類,錯誤,
-
更新權重
\(b = -1 - 1*(1-(-1))*(-1)=1\)
\(w_1 = 0 - 1*(1-(-1))*0=0\)
\(w_2 = 2 - 1*(1-(-1))*0 = 2\)
-
-
代入\((0,1)\),\(sign(0 * 0 + 2 * 1 + 1 * (-1))=1\),判定為正類,正確,
后面的步驟就省略不寫了,讀者可以自行驗算,根據代碼計算的結果,如果初始權重設為[0,0,0]這樣比較極端的值,學習速率為1時,且按照順序選擇樣本點時,需要完整的走完兩輪迭代才能得到穩定的權重,最后解得分類函式為: \(sign(2x^{(1)} + 2x^{(2)} - 1)\),讀者可以帶資料進去驗算,
3. 感知機不能解決什么問題?
這里有一段經典的公案,《感知機》是這本書的出現,直接讓神經網路這一流派的研究停止了二十年,因為書中在詳盡介紹感知機原理的同時,還指出了感知機的致命缺陷:無法解決\(XOR\)問題,
\(XOR\)又稱為異或,它的邏輯如下:
| 變數1 | 變數2 | 邏輯運算結果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
這是個比較奇怪的邏輯,變數之間當且僅當不相等時為真,
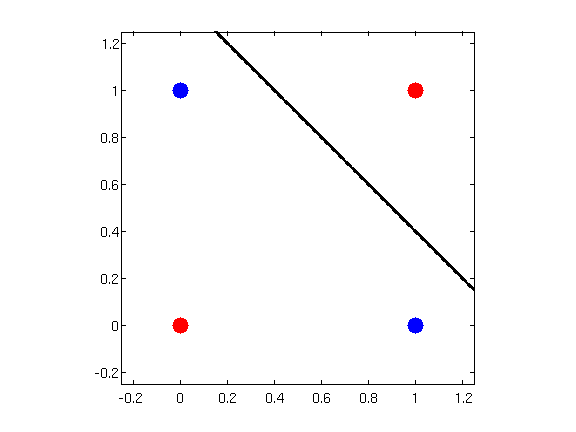
憑著幾何直覺,我們很快就能發現,不可能有這樣的超平面,能準確的分開紅色和藍色兩類樣本,
這里小結一下:
感知機可以解決完全線性可分的問題,
這似乎是一句廢話,但是感知機背后強大的思想確衍生出了支持向量機這個傳統機器學習的巔峰,而對于線性不可分的樣本,可以使用多層神經網路(\(Multi \space Layer \space Network\))或者使用核感知機,事實上兩層的感知機就可以解決\(XOR\)問題
4. 感知機是如何作業的?
在上面這個略顯啰嗦的例子,我們看到了感知機的作業方法,它的演算法流程可以概括如下:
- 選取初始值\(w_0, b_0\)
- 在訓練集中選取一個資料點\((x_i,y_i)\)
- 檢查在這個樣本點上,模型是否會錯誤分類,如果錯誤分類,則更新\(w_i,b_i\)
- 回到第2步,直到整個訓練集中沒有誤分類點
從上面的演算法,我們至少能讀出這么幾層意思:
- 初始值是隨機給的,賦值為0是一個簡便的做法,但通常設定為一個很小的隨機值,后面會詳細討論
- 每次訓練其實只用到一個樣本點,即使訓練集中有很多資料點亦是如此,這和 \(w_ix_i\)這個運算式的計算方式有關,詳見上面的數值例子,
- 演算法的重點在誤分類這里,那么如何定義誤分類就非常要緊了,
- 演算法是一個迭代的程序,且要滿足所有樣本點都分類正確才停機,反過來理解,就是感知機演算法只能運用于完全線性可分的資料集,如果資料集是不能完全線性可分的,感知機永遠不會停機,除非訓練之前先設定好停機條件,常見的比如設定訓練次數或者誤差上界(一旦誤差小于$ \varepsilon $ 即可停機),
顯然,如何定義錯誤是感知機演算法里的頭等大事,
5. 該如何定義錯誤?
通俗定義:映射函式\(sign(wx + b)\)求解得到的值和原始標簽值異號,即表示分類錯誤,
根據這個表述,我們可以很容易地將資料集分類:正確分類和錯誤分類,顯然我們要做的事就是想辦法讓模型把分錯的樣本點分對,同時對于原本已經分對的點不能又分錯了,
如果采用幾何作圖的方法,可以不斷調整超平面(即上面提到的直線,術語上通稱為超平面)來達到目標,只要給定的資料集是完全線性可分的,但是,如果是高維空間的資料集,幾何直覺就不靈了,這時需要引入代數工具,而引入損失函式就是這樣的工具,它和我們依靠幾何直覺做的事情是相同的:把所有點分對 \(\iff\) 將損失函式降到最小,
損失函式的定義可以憑直覺而為:計算誤分類樣本的個數,例如樣本空間共有\(M\)個樣本,其中錯誤分類的樣本屬于區域\(E\),顯然損失函式就是 \(\sum\limits_{i\in E}x_i\) ,但問題隨之而來,我們沒有工具來優化這個函式,使之向最小值運動,于是自然地想到,計算所有誤分類點到超平面的距離,對距離之和做優化,具體的思路是這樣的:
- 找到描述樣本點到超平面距離的計算式
- 正確分類的樣本點的距離和丟棄不看
- 定義誤分類的距離和,對它求最小值
在\(R^n\)空間中,任何一個樣本點\(x_0\)到超平面的距離公式 \(\frac{1}{||w||}|w\cdot x + b|\),對于誤分類來說,\(y_i(w \cdot x + b) < 0\),于是如果有一個誤分類點\(x_0\),那么它到超平面的距離可以寫作 \(-y_i\frac{1}{||w||}|w\cdot x + b|\),對于所有的誤分類來說,自然可以寫出下面的損失函式:$$L(w,b) = -\sum\limits_{i\in E} y_i \frac{1}{||w||}|w\cdot x + b|$$,這里添加負號的目的是使得損失函式的值恒為正數,這樣對它求最小值可以使用凸優化工具,顯然地,誤分類樣本點越少,\(L(w,b)\)越小;誤分類點離超平面的距離越小,\(L(w,b)\)越小,
這里舍棄掉\(\frac{1}{||W||}\)是因為它是一個正的系數,并且對于\(L(w,b)\)具有伸縮性,因此不影響最小化\(L(w,b)\),
6. 知錯后如何改錯?
回顧微分學知識,我們知道一個全域的凸函式取得最小值是在導數為0處,但是,放在多元函式的觀點來看,一元函式的導數本質上也是梯度,當一個函式沿著負梯度的方向運動是,函式值的減少是最快的;沿著正梯度方向運動時,函式值增加啊是最快的,下面我們就來求其梯度,
\[\frac{\partial L}{\partial w} = - \sum\limits_{x_i \in E} y_i x_i \]
\[\frac{\partial L}{\partial b} = - \sum\limits_{x_i \in E} y_i \]
我們來看關于\(w\)的梯度運算式,本質上就是找到所有的誤分類點,然后把標簽值\(y_i\)作為一個權重(\(+1/-1\)),如果\(x_1\)是一個被錯誤分類的點,假設這個點對應的原始標簽是正類,現在被分成負類,所以在前面加一個符號,表示往反方向彌補,所以\(\sum\limits_{x_i \in E}y_ix_i\)
可以理解為通過所有錯誤分類的樣本點擬合出一個運動方向,往那個方向運動可以彌補模型中\(w\)引數的錯誤,
而例1中,我們每次只選取一個樣本點,假設這個樣本點是\((x_i,y_i)\),那么更新公式就是 \(w = w + \eta y_i x_i\),其中的\(\eta\)是每次更新的步長,術語為學習率,同理,偏置項的更新公式為 \(b = b + \eta y_i\),
7. \(Novikoff\) 定理
先敘述一下這個定理,定理來自李航老師的《統計學習方法》第二版Page42,
設訓練資料集\(T = {(x_1,y_1),(X_2,y_2),...,(x_N,y_N)}\)是線性可分的,其中\(x_i \in X = R^n, y_i \in Y = \{-1,+1\}, i = 1,2,...,N\),則
(1) 存在滿足條件\(||\hat{w}_{opt}|| = 1\)的超平面\(\hat{w}_{opt} \cdot \hat{x} = w_{opt} \cdot x + b_{opt}\)將訓練資料集完全正確分開;且存在\(\gamma > 0\),對所有的\(i = 1,2,...,N\)有$$y_i (\hat{w}{opt} \cdot \hat{x}i) = y_i (w{opt} \cdot x_i + b{opt}) \ge \gamma$$
(2)令\(R = \max\limits_{1 \le i \le N} ||\hat{x}_i||\),則感知機演算法在訓練資料集上的誤分類次數\(k\)滿足不等式 $$k \le (\frac{R}{\gamma})^2$$
先從直覺上理解下這個定理表述的意思,大意是對于可以找出線性超平面做分類的資料集,存在一個下界$ \gamma $,所有樣本點到超平面的距離都至少大于這個 $ \gamma $,同時錯誤分類的次數有一個上界,第 \(k+1\) 次之后,分類都是正確的,演算法最終是收斂的,
證明
(1) 由于資料是線性可分的,因此一定存在一個分割超平面\(S\),不妨就取\(S\)的引數為\(\hat{w}_{opt}\),顯然對于超平面上的所有點\(x\),都有\(\hat{w}_{opt} \cdot x = w_{opt} \cdot x + b_{opt} = 0\),并滿足\(||\hat{w}_{opt}||=1\),而對于訓練資料集中的樣本點,由于現在都被正確分類了,所以有\(\hat{w}_{opt} \cdot x_i > 0\),于是取 \(\gamma = \min\limits_{i} \{y_i(w_{opt} \cdot x_i + b_{opt} \}\),這就得到了下界,
(2) 由 \(k \le (\frac{R}{\gamma})^2\)推出\(k \gamma \le \sqrt{k} R\) ,
假設\((x_i,y_i)\)是一個在第\(k\)次被誤分類的點,那么這件事的觸發條件是 \(y_i (\hat{w}_{k-1} \cdot x_i) \le 0\).
由更新公式,\(\hat{w}_k = \hat{w}_{k-1} + \eta y_i \hat{x}_{i}\) .
-
\(\hat{w}_{k} \cdot \hat{w}_{opt} = \hat{w}_{k-1} \cdot \hat{w}_{opt} + \eta y_i \hat{w}_{opt} \cdot \hat{x}_i \ge \hat{w}_{k-1} \cdot \hat{w}_{opt} + \eta \gamma\) .
迭代\(k-1\)次立即得到 \(\hat{w}_{k} \cdot \hat{w}_{opt} \ge k\eta\gamma\).
-
對\(\hat{w}_k\)兩邊平方,
\(||\hat{w}_k||^2 = ||\hat{w}_{k-1}||^2 + 2\eta y_i \hat{w}_{k-1} \cdot \hat{x}_{i} + \eta^2 ||\hat{x}_{i}||^2\). 注意到中間這項是負數(因為這是誤分類點)
立即得到 \(||\hat{w}_k||^2 \le ||\hat{w}_{k-1}||^2 + \eta^2 ||\hat{x}_{i}||^2 \le ||\hat{w}_{k-1}||^2 + \eta^2 R^2\).
迭代\(k-1\)次后立即得到 \(||\hat{w}_k||^2 \le k \eta^2 R^2\) .
即可建立不等式
\(k\eta\gamma \le \hat{w}_{k} \cdot \hat{w}_{opt} \le ||\hat{w}_{k}|| \cdot ||\hat{w}_{opt}|| \le \sqrt{k}\eta R\). 再稍加變形就得到欲證的式子,
這里\(R\)其實只是一個記號而已,它代表的意思是從所有誤分類中找到模長最大的,而這個記號其實是從證明程序中產生的,
作為介紹感知機原理的文章,已經寫得非常長啦,可以就此打住~
如果有任何紕漏差錯,歡迎評論互動,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/63784.html
標籤:其他