標簽: 機器學習
1. 貝葉斯公式是機器學習中常用的計算方法,例如,甲射中靶標的概率是0.4,乙射中靶標的概率是0.8,現在有個人中靶了,問問是甲射中的概率,這非常好計算,P=0.4/(0.8+0.4)=0.33,這是貝葉斯公式的基本應用,具體的貝葉斯公式如下:
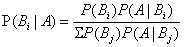
2.《機器學習實戰》中的貝葉斯實作:
略有修改,已經在本地電腦通過測驗,可以運行
import numpy as np
#-_-_-_-_-_-
dataset=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1]
#將出現的所有單詞放在一個串列中,再將串列轉為集合,(呼叫的時候再轉化為串列)
def createVocabList(dataSet0):
vocalist=[]
for i in dataSet0:
for d in i :
vocalist.append(d)
return set(vocalist)
#將資料轉為向量,類似于one_hot編碼
def setOfWords2Vec(vocabList, inputSet):
temp_vector=np.zeros((len(vocabList)))
for i in inputSet:
if i in vocabList:
temp_vector[vocabList.index(i)]=1
return temp_vector
##核心部分,訓練演算法
#輸入 trainMatrix [[0,1 0.....],[0.1,1,1 0......],....]
# 輸入trainCategory,標簽[0,1,0,1,0,1]
# classifyNB函式會用到貝葉斯公式p(c|w)=p(c)p(w|c)/p(w)
# p(c)比較容易求
#
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs) #p(c)
#這里之所以不初始為0,是因為p(w|c),可以看成p(w0,w1,w2...|c)
#如果假設特征之間相互獨立,則寫成
#p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)
#所以為了防止其中一個為0,導致整體概率為0,須將數值初始化為1,分母初始為2
p0Num = np.ones(numWords); p1Num = np.ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#Python在很多小數相乘的時候,會產生下溢,因為精度不夠,所以改成log
p1Vect = np.log(p1Num/p1Denom) #change to log()
p0Vect = np.log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
#核心演算法,利用貝葉斯進行分類
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
# 因為在訓練的時候轉成了log,所以乘法變加法log(a*b)=log(a)+log(b)
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #分母一樣,故把分母省略了
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
if __name__=='__main__':
temp_set=createVocabList(dataset)
word_list=list(temp_set)
trainmatrix=[]
for item in dataset:
temp_vector=setOfWords2Vec(word_list,item)
trainmatrix.append(temp_vector)
p0Vect, p1Vect, pAbusive=trainNB0(trainmatrix,classVec)
#這是我測驗用的,如果輸出為0,就是正確的
#這個test向量對應的是我自己設定的詞串列['cute','love']
test=np.zeros(len(word_list))
test[0]=1
test[1]=1
b=classifyNB(test,p0Vect,p1Vect,pAbusive)
print(b)
#輸出為0,符合預期
3. sklearn中的貝葉斯實作:
查看了一下sklearn源代碼,GaussianNB主要部分如下所示:
def _joint_log_likelihood(self, X):
check_is_fitted(self, "classes_")
X = check_array(X)
joint_log_likelihood = []
for i in range(np.size(self.classes_)):
#####這一部分和上邊的classifyNB函式代碼大同小異--------
jointi = np.log(self.class_prior_[i])
n_ij = - 0.5 * np.sum(np.log(2. * np.pi * self.sigma_[i, :]))
n_ij -= 0.5 * np.sum(((X - self.theta_[i, :]) ** 2) /
(self.sigma_[i, :]), 1)
joint_log_likelihood.append(jointi + n_ij)
#####-------------------------------------------------
joint_log_likelihood = np.array(joint_log_likelihood).T
return joint_log_likelihood
上述的源代碼只不過是令公式中的:
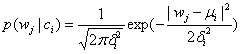
實際應用也非常簡單,這個分類一般應用于連續的,符合正態分布的資料上,除此之外,還有一個MultinomialNB,這個一般應用于離散的資料上.這個貝葉斯分類的對應的公式是:
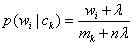
他包含三個引數
alpha:即為上面的常數λ,默認為1,設定的時候稍大于1或者稍小于1
fit_prior:是否考慮先驗概率
class_prior:即貝葉斯公式中的P(C),在fit_prior為true的情況下,如果不填這個引數,他會從樣本中計算.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/65609.html
標籤:其他
上一篇:NLTK自然語言處理庫
下一篇:機器學習筆記(一)