大資料實驗環境準備與配置(1/4)
第一部分:Hadoop環境搭建前的Linux環境安裝與配置
(1) 搜索 “Ubuntu”,選擇官方下載,或者打開網站:https://ubuntu.com/download/desktop
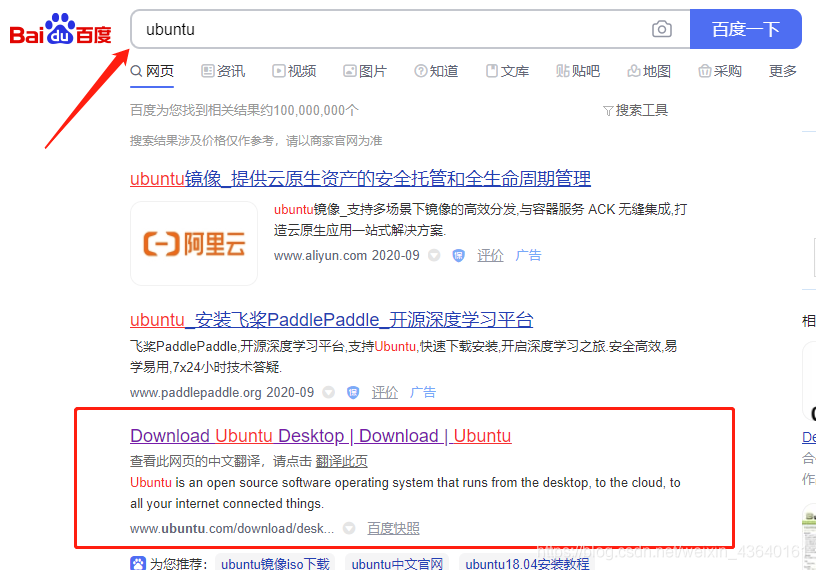
(2) 點擊綠色的 Download按鈕,
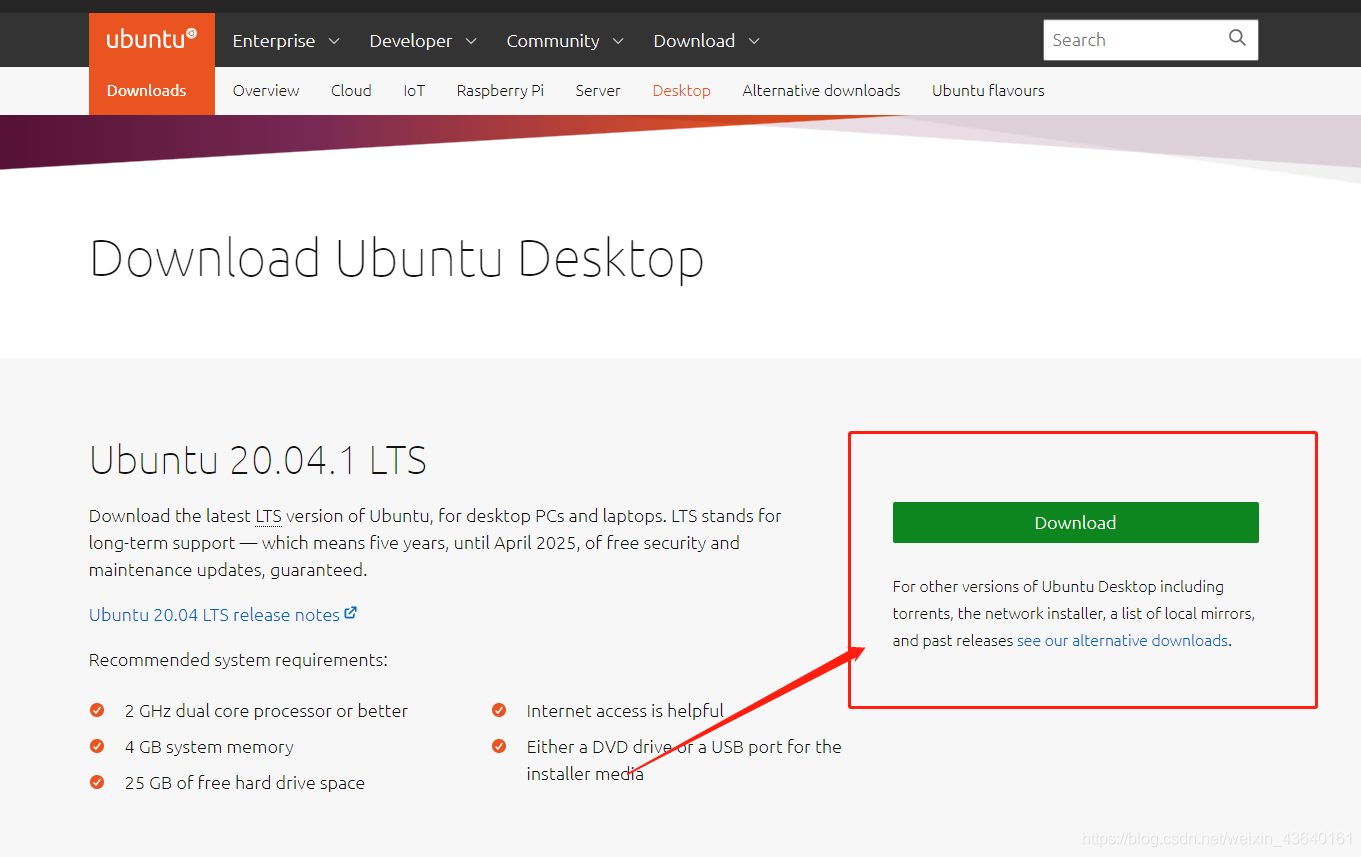
(3) 這個官方網站是全速下載,這里391KB/s是因為我網路全速就這樣/(ㄒoㄒ)/~~
(4) iso檔案下載完成后,在已經準備好的虛擬機軟體VMware里面進行Ubuntu系統的安裝
選擇 “創建新的虛擬機”

(5) 選擇 “典型(推薦)”

(6) 點擊“瀏覽”找到前面下載的iso檔案,再點擊下一步,
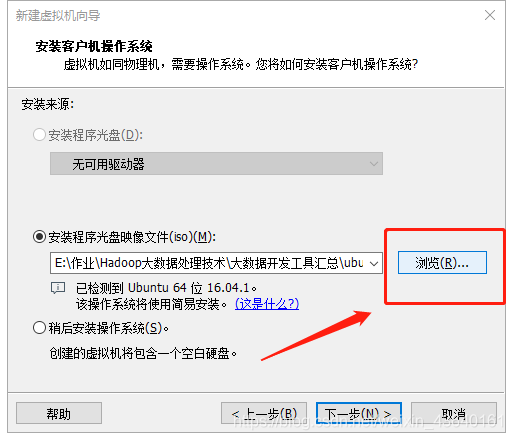
(7)填寫簡易的安裝資訊,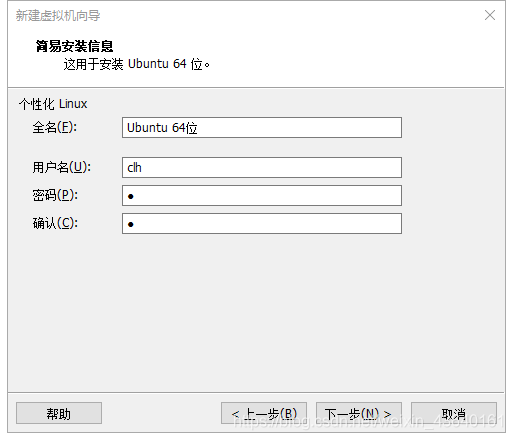
(8) 選擇好安裝的位置,
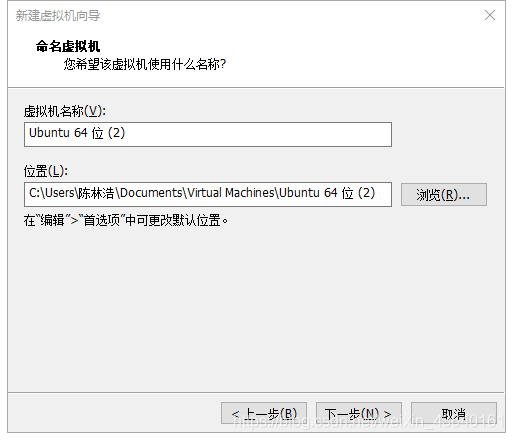
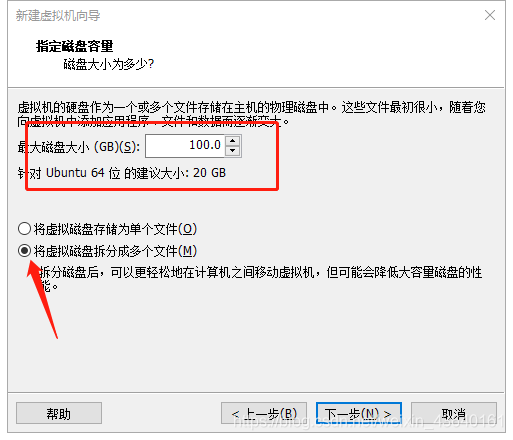
(9) 磁盤大小選擇100G,如果感覺自己磁盤不夠的同學,可以適當減少,但是不要低于25G
(10) 點擊“自定義硬體”
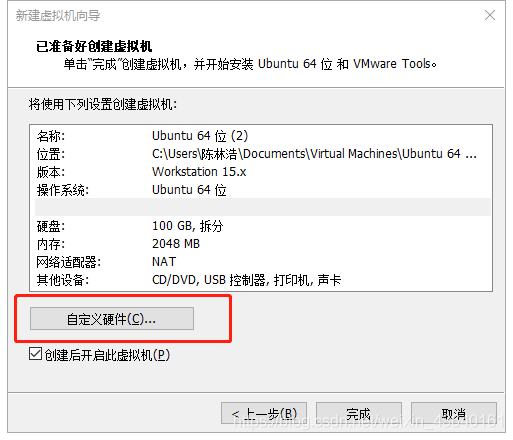
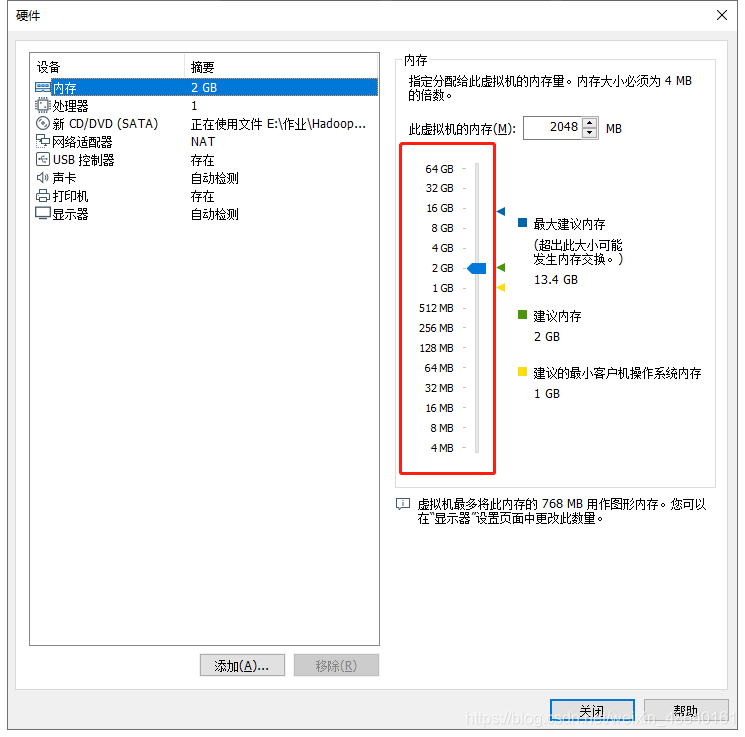
(11) 記憶體分配建議在2G以上,這里我個人給到的是8G(我是雙通道16G的記憶體,如果你電腦只有8G建議給到4G,加開系統安裝速度)
(12) 安裝完成后,會有以下畫面,選擇Ubuntu 64位,輸入前面設定的用戶名密碼,

這樣,桌面版的Ubuntu作業系統就完成安裝了
溫馨提示:安裝Ubuntu虛擬機前必須到BIOS中開啟虛擬化技術支持,
(13) 滑鼠右鍵點擊桌面,選擇“Open Terminal”打開終端
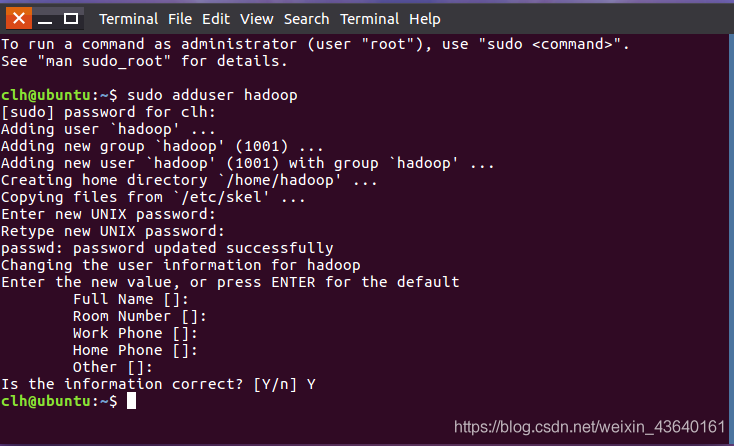
(14) 創建hadoop用戶并安裝vim編輯器
終端命令:sudo adduser hadoop
終端命令:sudo apt-get install vim

(如果提示沒有vim安裝包,首先執行第(16)步,再執行apt-get update更新軟體包,然后再進行vim安裝,)
(15) 用剛創建的hadoop用戶進入Ubuntu系統,,測驗hadoop用戶是否創建成功,
終端命令:su hadoop

(16) 進入root用戶/etc目錄,編輯sudoers
終端命令:
su root
cd /etc
vi sudoers
編輯sudoers時候,用的是vim,與傳統的文本編輯器不一樣,沒用滑鼠操作,需要特殊的命令
vim操作教程:https://www.runoob.com/linux/linux-vim.html
給hadoop用戶增加權限
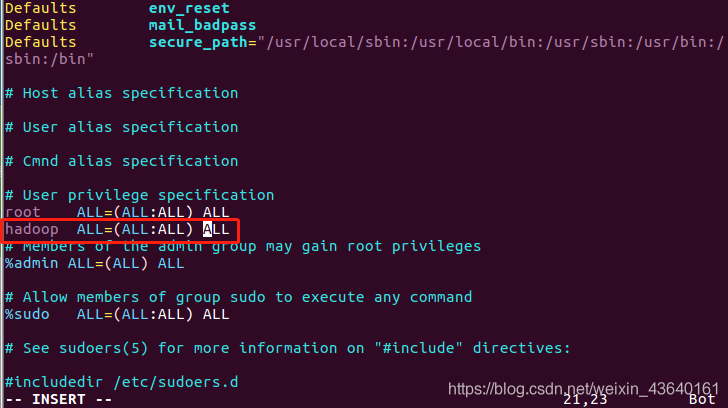
(17) 安裝SSH
集群、單節點模式都需要用到 SSH 登陸(類似于遠程登陸,你可以登錄某臺 Linux 主機,并且在上面運行命令),Ubuntu 默認已安裝了 SSH client,此外還需要安裝 SSH server:
終端命令:sudo apt-get install openssh-server

安裝后,可以使用如下命令登陸本機:
ssh localhost
此時會有如下提示(SSH首次登陸提示),輸入 yes ,然后按提示輸入密碼 hadoop,這樣就登陸到本機了,

(18) 配置SSH無密碼登陸
但這樣登陸是需要每次輸入密碼的,我們需要配置成SSH無密碼登陸比較方便,
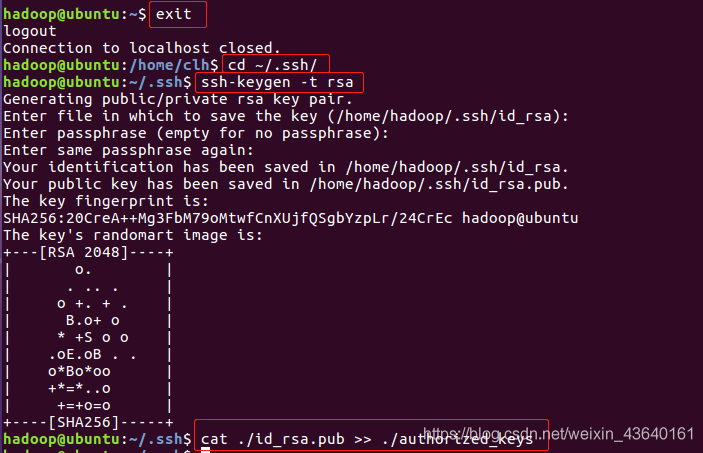
首先退出剛才的 ssh,就回到了我們原先的終端視窗,然后利用 ssh-keygen 生成密鑰,并將密鑰加入到授權中:
exit # 退出剛才的 ssh localhost
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 會有提示,都按回車就可以
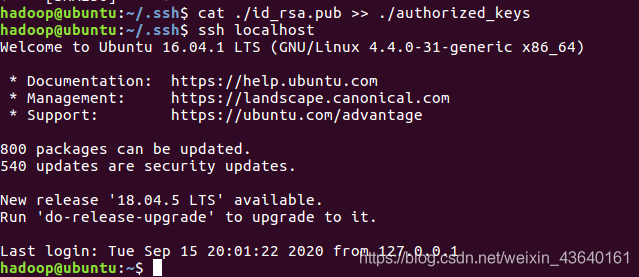
cat ./id_rsa.pub >> ./authorized_keys # 加入授權
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示,
關于這個實驗的第一步到此就完成了,因為內容比較多,所以我分成了四個部分,后續會繼續更新,堅持做到這里的小伙伴都很棒!希望各位小伙伴保持對技術的追求,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/65975.html
標籤:其他