堆疊
先入后出
也是用queue模塊實作
先入后出的對列(堆疊)
宣告格式:
# 創建一個堆疊
q = queue.LeftQueue()
# 進堆疊
q.put()
# 出堆疊
q.get()
生產者與消費者模式
在并發編程中使用生產者和消費者模式能夠解決絕大多數的并發問題,該模式通過平衡生產執行緒和消費執行緒的作業能力來提高程式的整體處理資料的速度
例:
import threading
import queue
num = 0
# 生產者
def func1(name):
global num
num += 1
print(f"{name}完成{num}號包子")
q.put(f"{num}號包子")
# 消費者
def func2(name):
res = q.get()
print(f"{name}獲取了{res}號包子")
if __name__ == ' main ':
# 創建了一個佇列
q = queue.Queue()
# 創建兩個執行緒
t1 = threading.Thread(target=func1, args=("王大廚",))
t2 = threading.Thread(target=func1, args=("小王",))
t1.start()
t2.start()
消費者就是消耗資料的行程
生產者就是生產資料的行程
什么是生產者與消費者模式
生產者消費者模式是通過一個容器來解決生產者和消費者之間的強耦合問題,生產者和消費者彼此之間不直接通訊,而是通過阻塞佇列來進行通訊,所以生產者生產完資料之后不用等待消費者處理,直接扔給阻塞佇列,消費者不找生產者要資料,而是直接從阻塞佇列里取,阻塞佇列相當于一個緩沖區,平衡了生產者和消費者的處理能力,
為什么使用生產者和消費者模式
在多執行緒中如果生產者生產是資料過快而消費者消耗資料的速度很慢,就會出現供大于求的現象發生,生產者就要等待消費者消耗資料才可以繼續生產,若消費者消耗資料的速度過快,而生產者跟不上消耗的速度就會出現供不應求的現象發生,而這時消費者就需要等待生產者,為了解決這個問題于是引入了生產者和消費者模式,
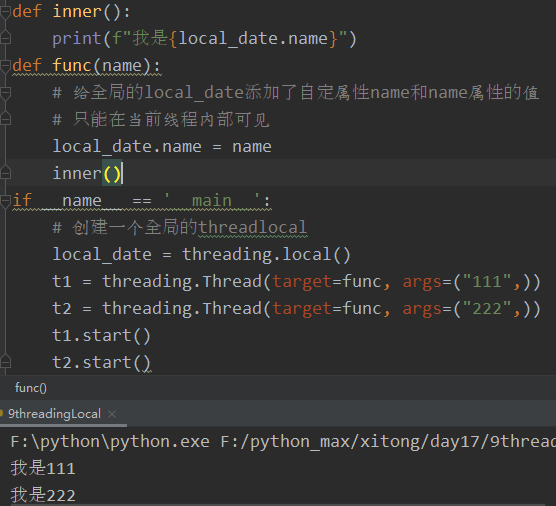
threadingLocal
threadingLocal相當于為每一個執行緒系結了一個資料庫,每個執行緒可以通過訪問自己的資料庫來得到自己想要的資料,解決了引數在一個執行緒中各個函式之間互相傳遞的問題,
例:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/66676.html
標籤:其他
上一篇:pyltp安裝教程——保姆級
下一篇:開啟Scrapy爬蟲之路