機器學習
- 回歸工程
- 一、線性回歸
- 1.定義與問題引入
- 舉個栗子
- 2.損失函式和梯度下降
- 二、邏輯回歸
- 1.定義與問題引入
- 舉個栗子
- 2.損失函式和梯度下降
- 小結
回歸工程
一、線性回歸
1.定義與問題引入
舉個栗子
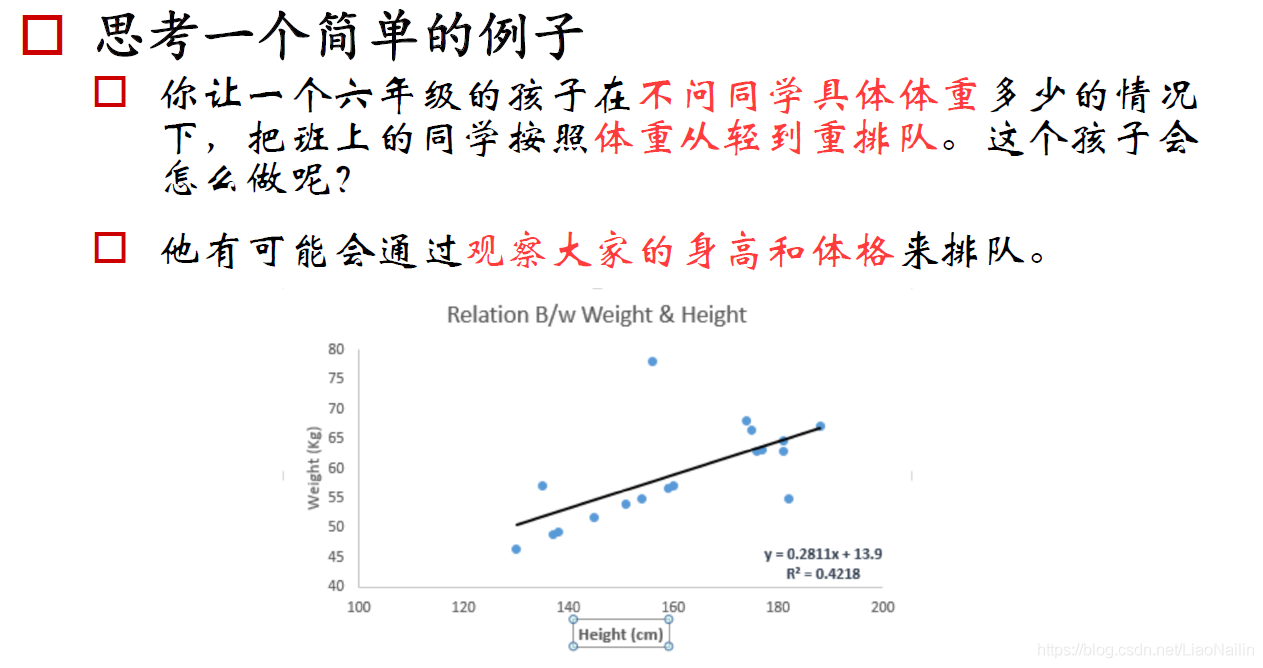
我們通過對大量的身高體重資料進放到一個直角坐標系中得到一個散點圖(例如下圖),干經過觀察,我們發現,身高和體重關系趨近于一條線,用這樣一條線可以大概的估計出一個身高對應的體重,或者一個體重對應的身高,那么問題來了,我們怎么樣得到這樣的一條直線呢?先讓我們來了解一下損失函式
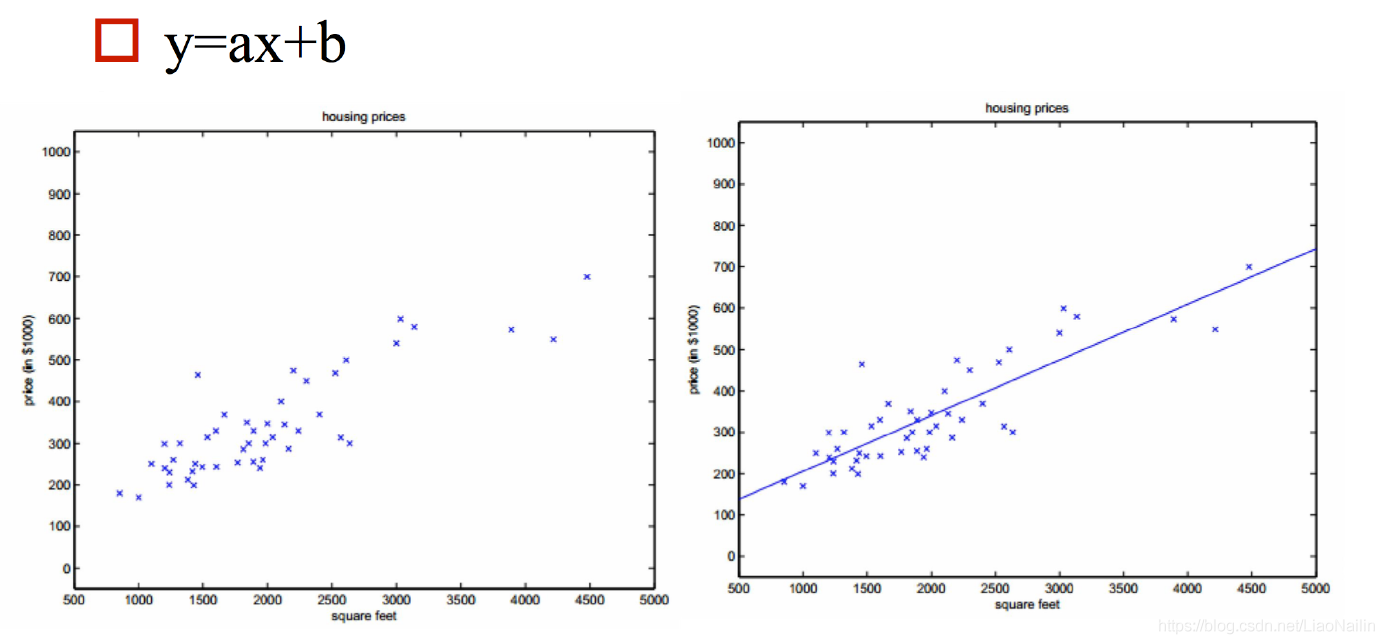
2.損失函式和梯度下降
假定我們用 y = 1 / 2 x y=1/2x y=1/2x來擬合我們得身高體重的線性關系,那么我們發現是有偏差的,此時我們的 a = 1 / 2 ( 斜 率 ) a=1/2(斜率) a=1/2(斜率)此時發現,擬合的程度不夠,明顯我們需要的斜率(模型引數)小了,那么我們怎么確定那個斜率下我們的 y = a x + b y=ax+b y=ax+b能最好的擬合我們的身高體重的散點圖呢?
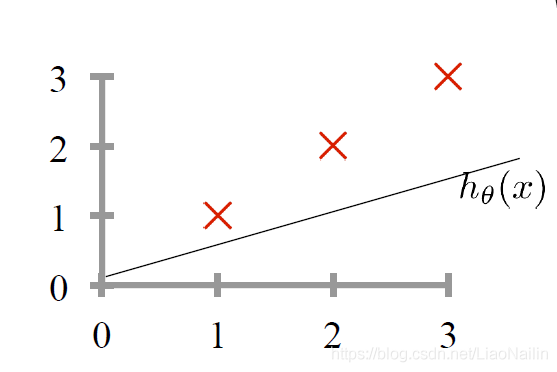
回顧一下初中的數學知識,點到直線的距離
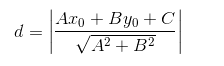
這個距離表示的是預測與實際的誤差,常被稱為損失值,把所有的點的損失值加起來,通過變化
y
=
a
x
+
b
y=ax+b
y=ax+b的引數a,記錄出一個凸函式影像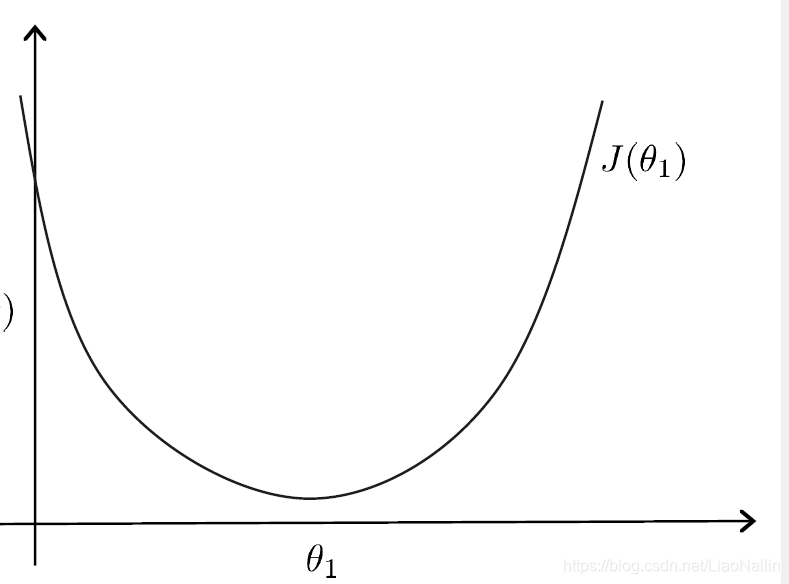
在該圖的函式就被稱為損失函式,顧名思義,損失函式我們為了求到一個區域最優的解,當然是取極小值,得出對應的
a
(
斜
率
)
,
b
(
截
距
)
a(斜率),b(截距)
a(斜率),b(截距),那么問題又來了,我們怎么樣得到這個函式的最小值呢?
在回顧一下初中的數學知識,求導,
導數:在該函式某一點若導數大于零,則單調遞增;若導數小于零,則單調遞減;導數等于零為函式駐點,不一定為極值點,需代入駐點左右兩邊的數值求導數正負判斷單調性,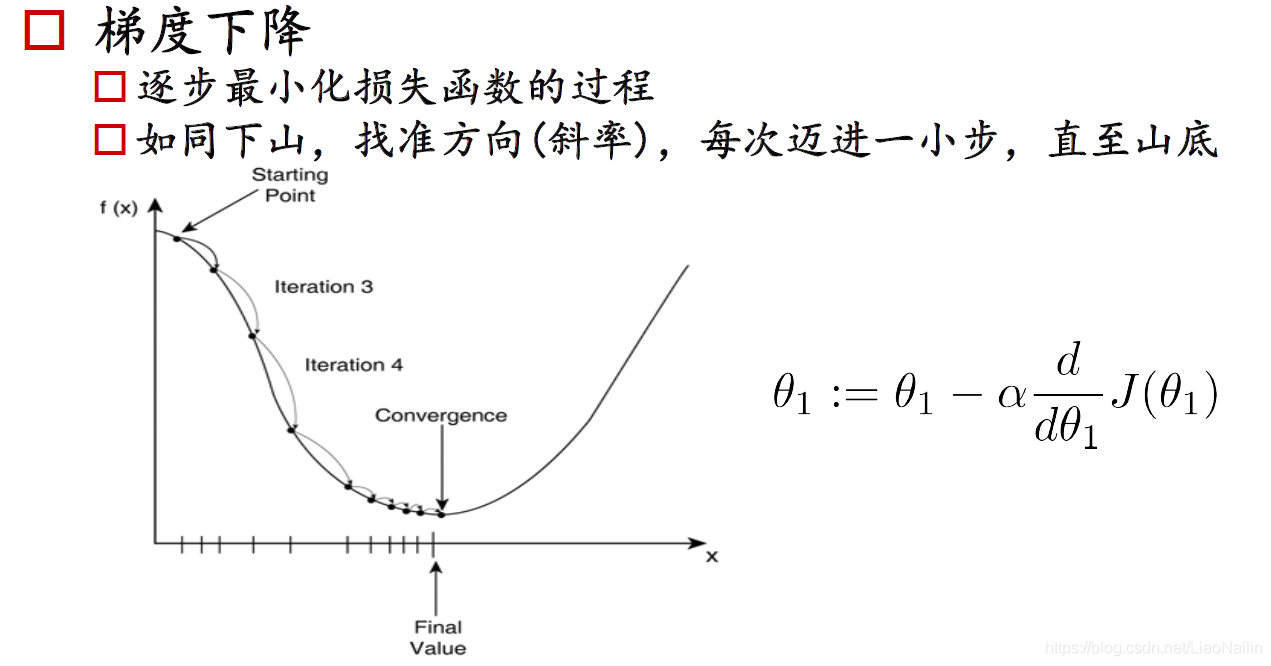
觀察上圖,先不要看公式,我們在y的最高處有一個Starting開始下山,在此進行求導,得到的一個導數值為負數,那我們為了求一個最小值,應該怎么做呢?是不是應該給
x
x
x進行右移呢?然后我們在新的
x
x
x放入函式求導發現還是小于零,那么重復以上操作,直到求導大于零,就可以得到一個趨近于最小值的點了,拿有同學又要問了,我一步向右走多遠呢?要是我直接一腳跨過對面的山頭怎么辦?這時候就有了我們的梯度下降法,
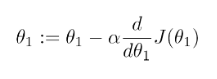
α
α
α我們就是我們的步長(學習率),通過
(
?
α
?
θ
的
導
)
(-α*θ的導)
(?α?θ的導)當我們處于下坡時,該值得到的是一個負數,負負得正,此時我們的方向是向右,當我們超過最低點,到達對面上坡段時,
(
?
α
?
θ
的
導
)
(-α*θ的導)
(?α?θ的導)得到一個正數
θ
?
一
個
正
數
θ-一個正數
θ?一個正數他是不是右開始往坡底走了?
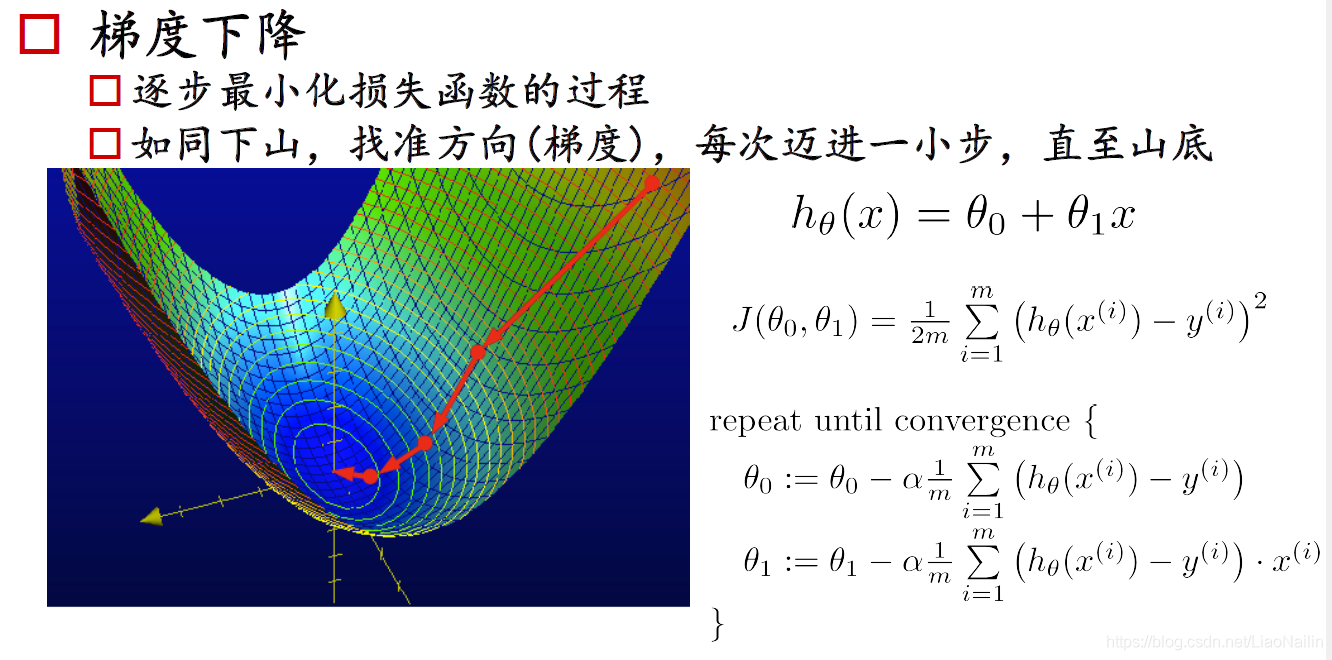
那么又有聰明的小朋友提問了,怎么選擇合適的步長呢? 通過思考我們發現,學習率大的計算次數少,但是不容易得到最優解,有時候太大了,就一直在上面跨來跨去,甚至是越來越高,學習率小的,計算的次數就會很多很多,下山的速度就非常的慢,此時這個值我們把它稱為超引數,最開始我們是擬定這個值,通過觀察和一系列的演算法不斷優化得到一個關于這個損失函式的最合適的學習率,
二、邏輯回歸
1.定義與問題引入
敲黑板(來羅來羅):邏輯回歸跟線性回歸有什么區別呢?邏輯回歸用于處理分類問題,線性回歸用于處理一個連續型的問題,
舉個栗子

假設中考啦,分數是很多很多科,簡單點,就語文數學吧,英語就讓它一邊去吧
我們通過這兩科的成績進行一個預測,預測該學生是否有高中讀,筆者這里有一堆模擬的資料資料包括語文數學成績,以及是否錄取,這三項,
我們通過python的科學庫對資料進行讀取,然后規格化
# %load ../../standard_import.txt
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from sklearn.preprocessing import PolynomialFeatures
pd.set_option('display.notebook_repr_html', False)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', 150)
pd.set_option('display.max_seq_items', None)
#%config InlineBackend.figure_formats = {'pdf',}
%matplotlib inline
import seaborn as sns
sns.set_context('notebook')
sns.set_style('white')
def loaddata(file, delimeter):
data = np.loadtxt(file, delimiter=delimeter)
print('Dimensions: ',data.shape)
print(data[1:6,:])
return(data)
def plotData(data, label_x, label_y, label_pos, label_neg, axes=None):
# 獲得正負樣本的下標(即哪些是正樣本,哪些是負樣本)
neg = data[:,2] == 0
pos = data[:,2] == 1
if axes == None:
axes = plt.gca()
axes.scatter(data[pos][:,0], data[pos][:,1], marker='+', c='k', s=60, linewidth=2, label=label_pos)
axes.scatter(data[neg][:,0], data[neg][:,1], c='y', s=60, label=label_neg)
axes.set_xlabel(label_x)
axes.set_ylabel(label_y)
axes.legend(frameon= True, fancybox = True);
data = loaddata('data1.txt', ',')
X = np.c_[np.ones((data.shape[0],1)), data[:,0:2]]
y = np.c_[data[:,2]]
plotData(data, 'Exam 1 score', 'Exam 2 score', 'Pass', 'Fail')
然后繪制散點圖,分別區分開正樣本(錄去)和負樣本(不錄取)得到這么個玩意
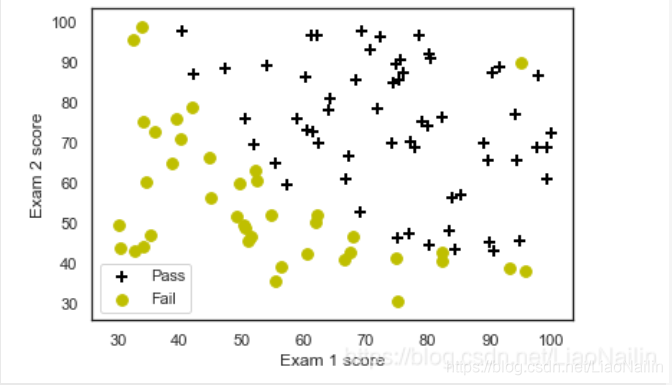
唉?怎么回事?在×中怎么會有一個?呢?

這種情況我們稱為噪聲、噪點也行,有可能是這家活考試作弊,然后分數是那么多但是被開除了不是,這里在后面我們還會涉及到資料清洗這樣的一個操作(降噪),這時候又有熱心的同學問了,那機器怎么知道他的這個成績是否能被錄取呢?常用的演算法有邏輯回歸,k近鄰演算法等,此處我們通過邏輯回歸進行分類
2.損失函式和梯度下降
損失函式又來啦,此時如果通過一個線性回歸的方式來處理,好像有點牽強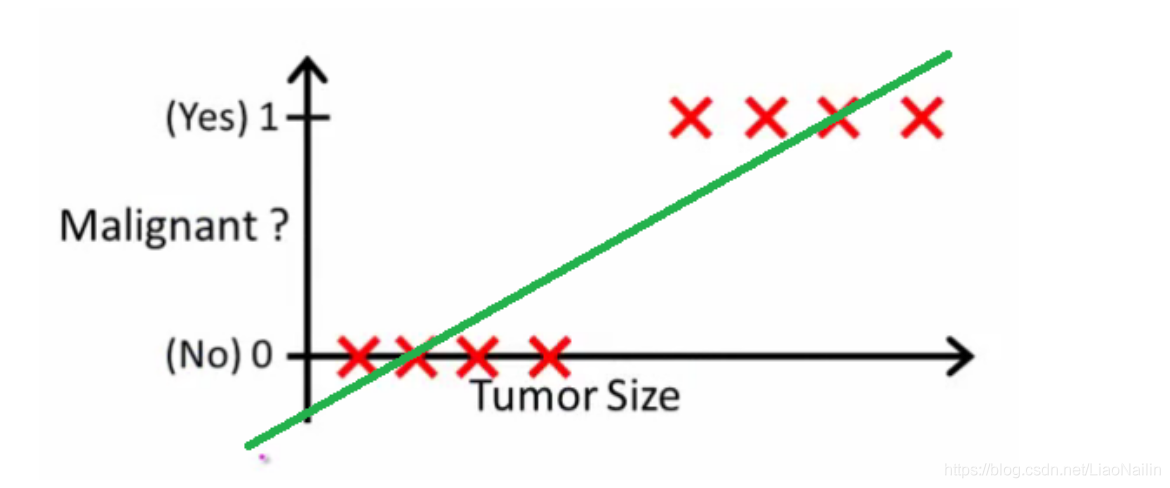
線的下方標識被fall了,上方表示pass,那就發現線性的損失函式不能很好的擬合這些分類問題了,怎么辦呢
s
i
g
m
o
i
d
sigmoid
sigmoid函式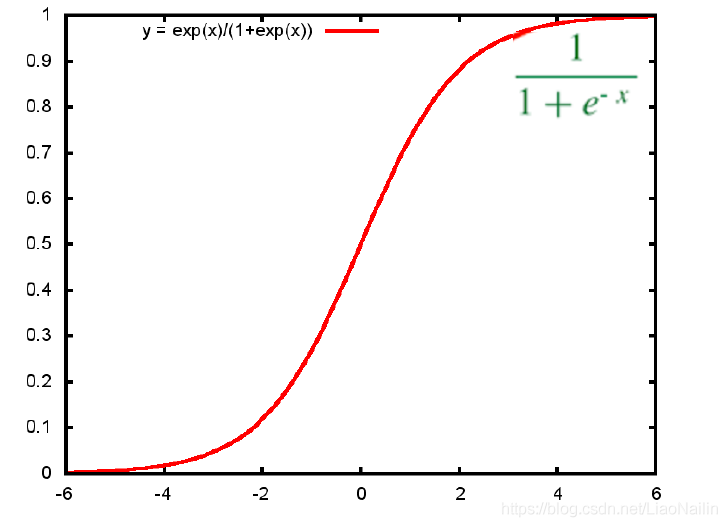
通過這個函式和線性回歸函式的結合,我們可以吧問題變成一個01的問題,例如我們線性回歸上的函式代入兩科成績得到80,80代入sigmoid函式中我們得到一個0-1的值這個值大于0.5則認為事情發生反之則反,然后再通過不斷調整線性回歸的引數得到一個損失函式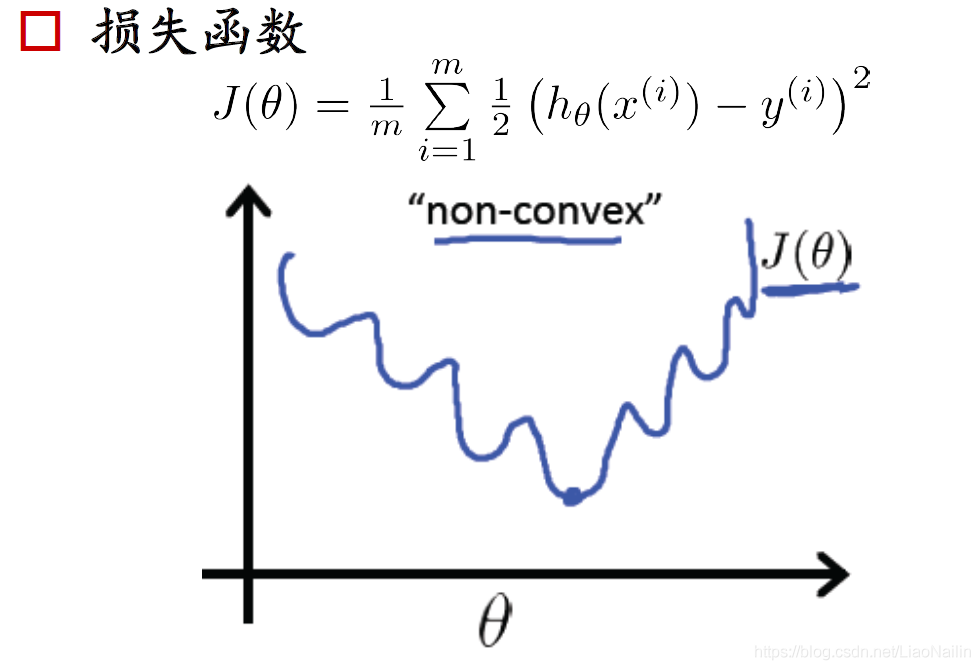
梯度下降又來啦可是在分類問題中,他的損失函式都是這種多個凸的函式,非常不容易求最小值,想象一個球調到這個山谷里很容易卡在半山,而得到一個區域最小值,那么
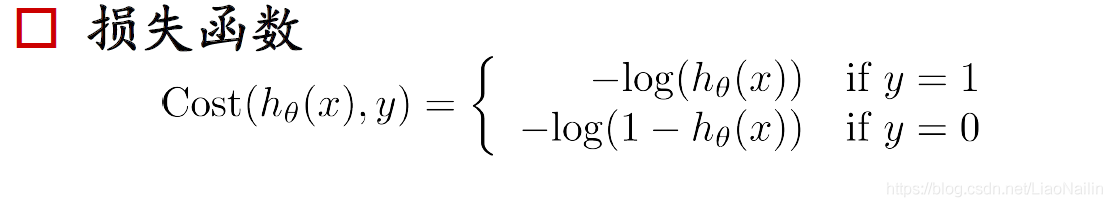
我們進行一個取對數操作
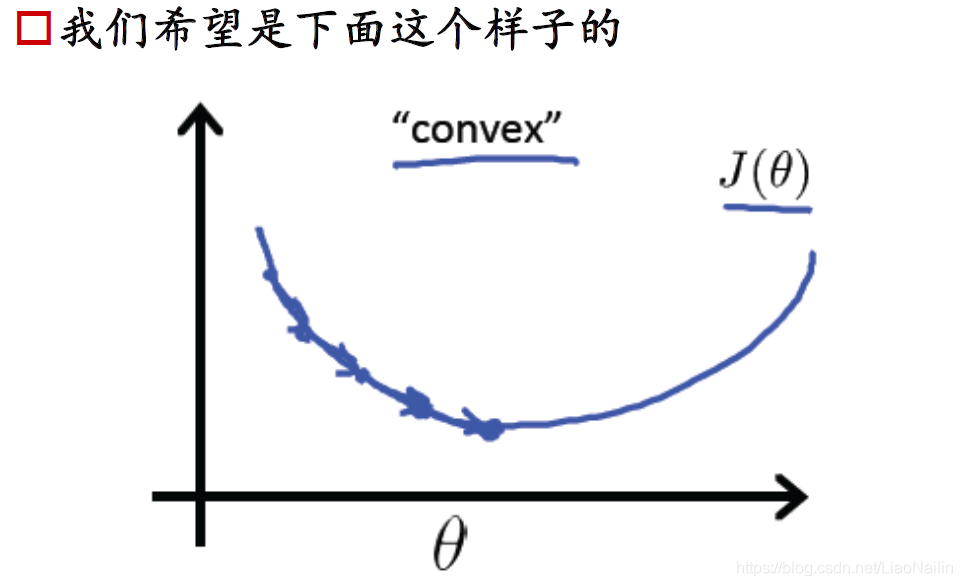
損失函式正則化:𝐽(𝜃)=1𝑚∑𝑖=1𝑚[?𝑦(𝑖)𝑙𝑜𝑔(?𝜃(𝑥(𝑖)))?(1?𝑦(𝑖))𝑙𝑜𝑔(1??𝜃(𝑥(𝑖)))]
#定義sigmoid函式
def sigmoid(z):
return(1 / (1 + np.exp(-z)))
#定義損失函式
def costFunction(theta, X, y):
m = y.size
h = sigmoid(X.dot(theta))
J = -1*(1/m)*(np.log(h).T.dot(y)+np.log(1-h).T.dot(1-y))
if np.isnan(J[0]):
return(np.inf)
return(J[0])
#求解梯度
def gradient(theta, X, y):
m = y.size
h = sigmoid(X.dot(theta.reshape(-1,1)))
grad =(1/m)*X.T.dot(h-y)
return(grad.flatten())
initial_theta = np.zeros(X.shape[1])
cost = costFunction(initial_theta, X, y)
grad = gradient(initial_theta, X, y)
print('Cost: \n', cost)
print('Grad: \n', grad)
# 這里偷懶了,直接呼叫scipy里面的最小化損失函式的minimize函式
res = minimize(costFunction, initial_theta, args=(X,y), method=None, jac=gradient, options={'maxiter':400})
那么我們通過損失函式有了這么一個比較合這個資料的引數模型,我們開始進行預測
#預測功能
def predict(theta, X, threshold=0.5):
p = sigmoid(X.dot(theta.T)) >= threshold
return(p.astype('int'))
# 第一門課45分,第二門課85分的同學
# 咱們對他做個預測,拿到通過考試的概率
sigmoid(np.array([1, 45, 85]).dot(res.x.T))
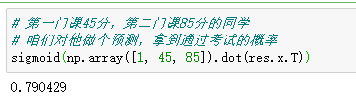
得到這么一個結果,該同學通過考試的概率為0.79.,,,,,,
#繪圖
plt.scatter(45, 85, s=60, c='r', marker='v', label='(45, 85)')
plotData(data, 'Exam 1 score', 'Exam 2 score', 'Pass', 'Failed')
x1_min, x1_max = X[:,1].min(), X[:,1].max(),
x2_min, x2_max = X[:,2].min(), X[:,2].max(),
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
h = sigmoid(np.c_[np.ones((xx1.ravel().shape[0],1)), xx1.ravel(), xx2.ravel()].dot(res.x))
h = h.reshape(xx1.shape)
plt.contour(xx1, xx2, h, [0.5], linewidths=1, colors='b');
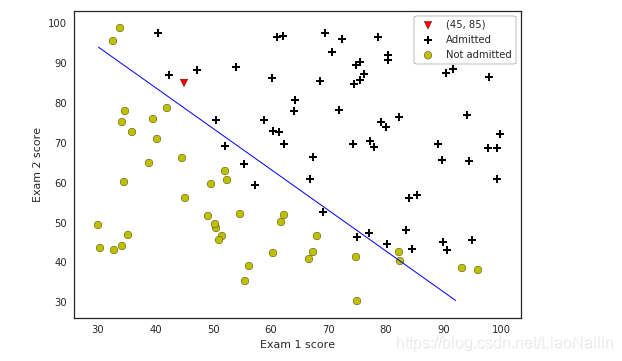
機器預測得出結果至此結束,
有同學又開始杠了,這個問題我兩個成績取平均值然后設定上下限不行啊?
嗯是的,針對這個問題有太多的解決方案,那么資料復雜化,多維度化呢?假如我們在區分貴族學校,在加入一些屬性,例如家庭收入、居住地區房價、該家庭年教育支持 等多個資料來判斷一個學生可以錄取,他會不會來我這里讀書呢?再次簡單的使用平均,明顯不妥吧,因為每一項的權重明顯不同,家里有礦的有錢,但是爸媽不想讀書,也不支持小孩讀書呢?家里經濟一般,但是很重視小孩的教育,每年在教育支出非常多的小孩呢,還有家庭住址離校距離等多個可能有影響的原因,
小結
其實這些功能都有相應的科學庫實作了也就二十行代碼的事,而且模型訓練效果還是比較好的,
那我費這么大勁寫的文章是不是沒用了?不是的,知其所以然才知其所以然,模型是需要不斷地優化的,想要得到一個更切合實際的模型,那就必須不斷的優化,
代碼+資料
密碼:hquq
懇請大家指正批評!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/66687.html
標籤:其他