文章目錄
- 前言
- 1. Python環境的搭建
- 1.1 python解釋器的安裝
- 1.2 pycharm的安裝
- 2. Python基礎語法
- 2.1 基本語法
- 2.2 資料型別
- 2.3 識別符號與關鍵字
- 2.4 格式化輸出
- 2.5 轉義字符和print的結束符
- 2.6 輸入與資料型別轉換
- 2.7 復合賦值運算子和邏輯運算子
- 3. Python常用陳述句
- 3.1 判斷陳述句(if陳述句、if-else陳述句、if-elif陳述句)
- 3.2 判斷陳述句(if嵌套)
- 3.3 判斷陳述句(if 綜合案例)
- 3.4 回圈陳述句(while回圈)
- 3.5 回圈陳述句(while回圈嵌套)
- 3.6 回圈陳述句(while...else)
- 3.7 回圈陳述句(for、for...else)
- 4. 字串
- 4.1 字串的使用
- 4.2 下標和切片
- 4.3 字串常用操作方法(查找、修改、判斷)
- 5. 串列、元組和字典
- 5.1 串列的創建和使用
- 5.2 判斷資料是否在串列中存在
- 5.3 串列的常見操作(查找、增加、洗掉、修改、賦值)
- 5.4 串列的回圈遍歷(for、while)
- 5.5 串列的嵌套
- 5.6 元組的訪問
- 5.7 元組常見操作(查找、修改)
前言
人生苦短,我用Python
1. Python環境的搭建
解釋器和開發集成環境pycharm的安裝還是比較簡單的,
1.1 python解釋器的安裝
(1)到官網下載python解釋器
下載地址:https://www.python.org/downloads/release/python-372/
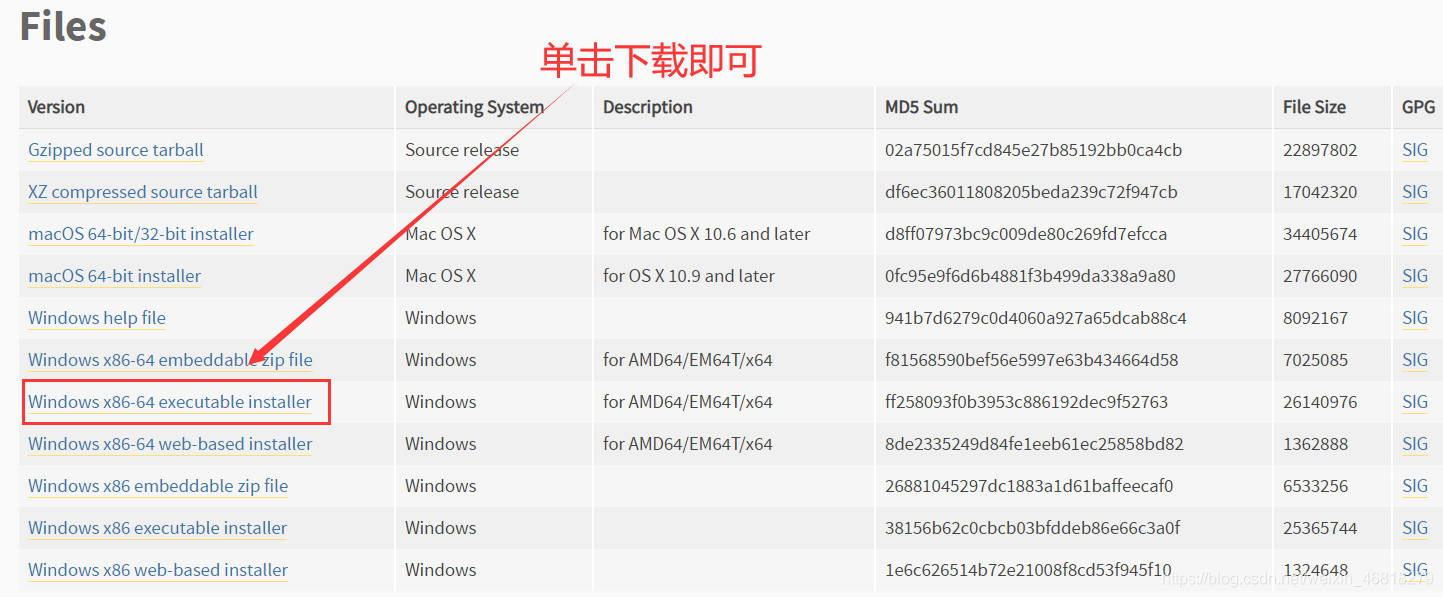
注釋: 這個解釋器是3.7.2版本的
(2)開始安裝python解釋器
安裝解釋器非常簡單,選擇Install Now, 在把下面的環境變數打上對勾就ok了,如下如所示

1.2 pycharm的安裝
工欲善其事,必先利其器,Pycharm是一種Python IDE(集成開發環境),帶有一整套可以幫助用戶在使用Python語言時 提高其效率的工具, 簡單的說提高你寫代碼的速度,撰寫代碼更爽更舒服,
(1)到官網下載Pycharm
下載地址:http://www.jetbrains.com/pycharm/download/#section=windows
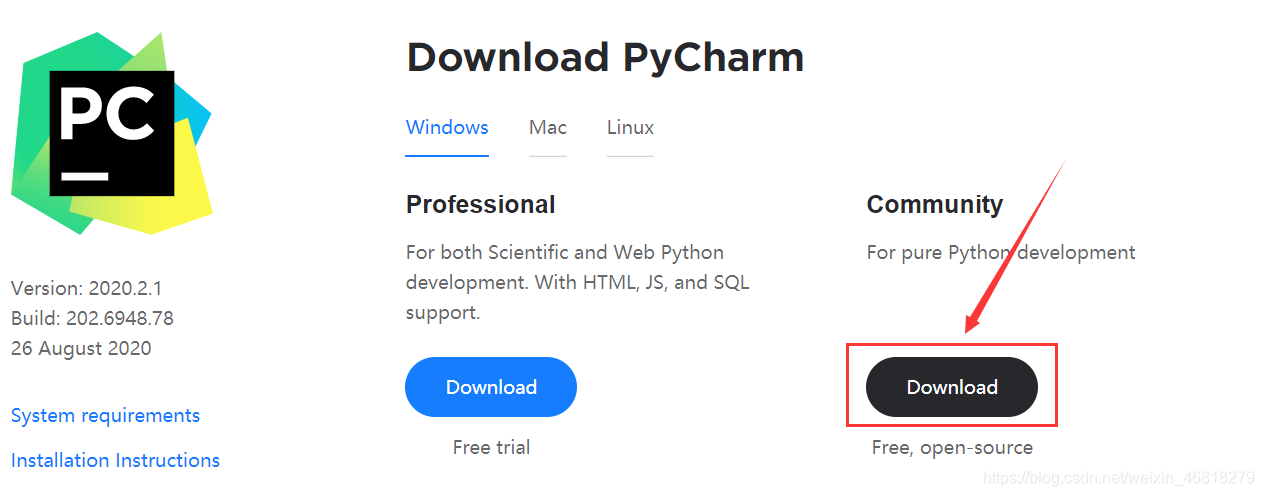
小提示: Pythoncharm分為專業版(professional)和社區版(community),專業版集成了一些框架和庫,收費的,基礎里用不到,社區版就夠用了,
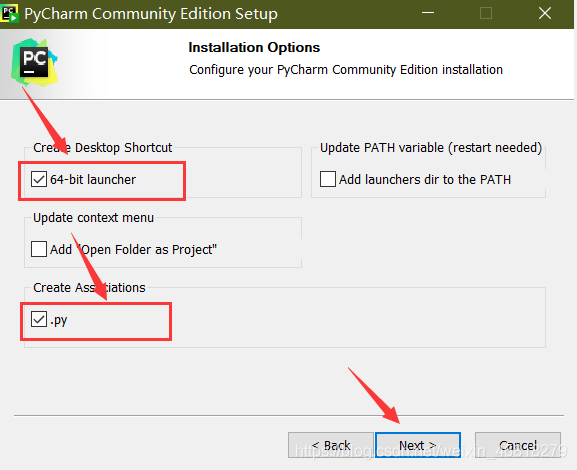
(2)開始安裝pycharm
安裝pycharm也非常簡單,選好安裝路徑,我安裝到D盤了,然后到達了如下圖的界面,選擇一個64位的桌面圖示(shortcut),再選擇一個.py的聯想,如下圖所示,
2. Python基礎語法
2.1 基本語法
直接上代碼,一看就懂了
# 這是一個輸出陳述句
print("Hello,World")
"""
這是一個多行注釋
"""
'''
這也是一個多行注釋
'''
====================================================================================
# 定義變數,儲存資料TOM
my_name = 'TOM'
print(my_name)
# 定義變數,儲存資料,這是一瓶冰紅茶
icdTea = '這是一瓶冰紅茶'
print(icdTea)
2.2 資料型別
來一個思維導圖,簡單明了
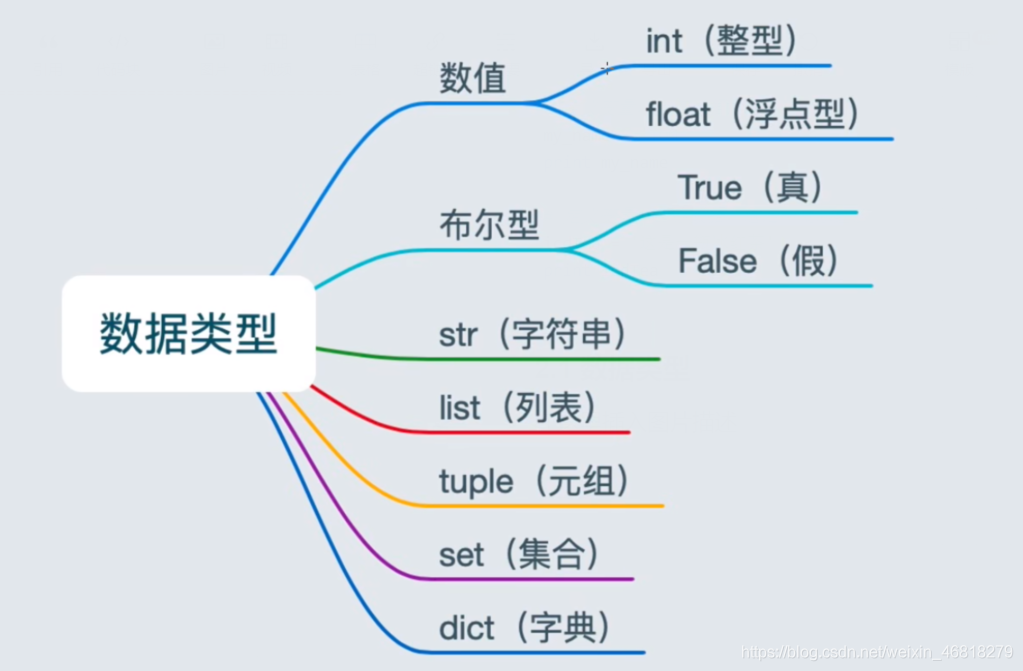
直接上代碼,一看就懂了
# 整型和浮點型
num1 = 1
num2 = 1.2
print(type(num1))
print(type(num2))
# 這是一個字串型別
a = 'hello,world!'
print(type(a))
# 這是一個布爾型別
b = True
print(type(b))
# 這是一個串列型別
c = [10,20,30]
print(type(c))
# 這是一個元組型別
d = (10,20,30)
print(type(d))
# 這是一個集合
e = {10,20,30}
print(type(e))
# 這是一個字典
f = {'name': 'TOM','age': 18}
print(type(f))
小提示:還有個復數型別,就是用于表示數學中的復數,用 real + imagej表示
2.3 識別符號與關鍵字
這里不多說,跟C語言和Java中的知識都差不多一樣,提幾個需要注意的地方,
識別符號:
(1)由數字、字母、下劃線組成
(2)不能數字開頭
(3)不能使用內置關鍵字
(4)嚴格區分大小寫
2.4 格式化輸出
直接上代碼,一看就懂
age = 18
name = 'TOM'
weight = 75.5
stu_id = 1
print('今年我的年齡是%d' % age)
print('我的名字叫%s' % name)
print('我的體重是%.3f' % weight)
print('我的體重是%03d' % stu_id) # 不夠三位,用0補全
print('我的名字叫:%s ,我的年齡是:%d' % (name,age))
print("我的名字叫:%s,我的年齡是:%d" % (name,age+1)) # 年齡加一歲
print("我的名字叫:%s,今年的年齡是:%d,我的體重是:%s,我的學號是:%03d" % (name,age,weight,stu_id))
===========================================================================================
name = "TOM"
age = 18
weight = 75.5
# %s比較強大
print('我的名字叫:%s,我的年齡是:%s,我的體重是:%s' % (name,age,weight))
===========================================================================================
name = 'TOM'
age = 16
# 語法:f'{運算式}'
# 這樣的輸出格式更加高效和簡潔
print(f'我的名字叫{name},我的年齡為{age}')
小提示:
(1)務必掌握這種輸出格式f'{運算式}' ,這種的輸出格式更加高效簡潔,f-格式化字串是Python3.6中新增的格式化方法,這種方法更簡單易讀,
(2)常見的格式符號:%s (字串) %d(有符號的十進制整數) %f(浮點數) %c(字符) 這幾種是常見的格式符號,如果需要其他的再去查就好了,
2.5 轉義字符和print的結束符
直接上代碼,一看就懂
print('hello world')
print('hello\nworld') # hello world直接換行輸出
print('\thello') # 前面輸出空格再輸出hello
=================================================================
# 在python中,print()默認自帶end='\n'這個換行結束符,用戶可以按照需求更改結束符
print('hello', end='\n')
print('world')
print('hello', end='\t')
print('hello')
print('hello', end='...')
print('world')
小提示:要記住print的結束符這個小知識點,
2.6 輸入與資料型別轉換
直接上代碼,一看就懂
passward = input('請輸入您的密碼:')
print(f'您輸入的密碼是:{passward}')
# input接收到的資料型別都是字串
print(type(passward))
====================================================================================
num = input("請輸入一個數字:")
print(num)
print(type(num))
# 強制轉換為int型別
print(type(int(num)))
print(type(int(num)))
===================================================================================
'''
因為得到資料型別并不是程式想要的資料型別,這個時候需要借助資料型別轉換的函式來轉換
'''
num = 1
str1 = '10'
# 1.將資料轉換成浮點型別 float()
print(type(float(num)))
print(float(num))
print(float(str1))
# 2. 將資料轉換成字串型 str()
print(type(str(num)))
# 3. 序列轉換成元組 tuple()
list1 = [10,20]
print(type(list1))
print(type(tuple(list1)))
print(tuple(list1)) # (100, 200)
# 4. 將一個元組轉換成序列 list()
t1 = (100,200)
print(list(t1)) # [100, 200]
# 5. eval() 計算在字串中的有效Python運算式,并回傳一個運算式,把字串中的資料轉換成他原本的型別
str3 = '1'
str4 = '2.1'
str5 = '(10,20)'
str6 = '[10,20]'
print(type(eval(str3))) # <class 'int'>
2.7 復合賦值運算子和邏輯運算子
總結幾個常用算數運算子
(1)** 回傳a的b次冪,比如 2 ** 3,結果位8
(2)% 取余
(3)// 取整除,回傳商的整數部分,
總結幾個常用復合賦值運算子
直接上代碼,一看就懂
a = 10
a += 1
print(a) # 11
b = 10
b *= 3
print(b) # 30
# 注意:先算復合賦值運算子右側的運算式,算復合賦值運算
c = 10
c += 1 + 2
print(c) # 13
# 測驗
d = 10
d *= 1 + 2
print(d) # 30 說明先算復合賦值運算子右側的運算式,再算復合賦值運算
=====================================================================
# 邏輯運算子的運用
a = 0
b = 1
c = 2
# 1.and
print((a < b) and (a < c)) # True
print(a > b and a < c) # False
# 2.or
print(b > c or a < c) # True
# 3.not
print(not a < b) # False
# 程式員的習慣
# 加小括號為了避免歧義,增加優先級
3. Python常用陳述句
3.1 判斷陳述句(if陳述句、if-else陳述句、if-elif陳述句)
直接上代碼,一看就懂
if True:
print('條件成立了')
# 下面的代碼沒有縮進到if陳述句塊,所以和if條件無關
print('這個代碼執行嗎?')
=================================================================
age = 20
if age >= 18:
print('已經成年可以上網')
# 注意:不縮進的陳述句,跟if陳述句沒有關系了,
print('系統關閉')
================================================================
# 注意:input接受用戶輸入的資料是字串型別,這時需要轉換為int型別才能進行判斷
age =int( input('請輸入您的年齡:'))
if age >= 18:
print(f'您輸入的年齡是{age},已經成年可以上網')
================================================================
age =int( input('請輸入您的年齡:'))
if age >= 18:
print(f'您輸入的年齡是{age},已經成年可以上網')
else:
print(f'你輸入的年齡是{age},小朋友,回家寫作業去')
----------------------------------------------------------------
age = int(input('請輸入您的年齡'))
if age < 18:
print(f'您輸入的年齡是{age},童工')
elif (age >= 18) and (age <= 60):
print(f'您輸入的年齡是{age},合法')
elif age > 60:
print(f'您輸入的年齡是{age},退休')
-----------------------------------------------------------------
age = int(input('請輸入您的年齡'))
if age < 18:
print(f'您輸入的年齡是{age},童工')
# 條件的簡化寫法
elif 18 <= age <= 60:
print(f'您輸入的年齡是{age},合法')
elif age > 60:
print(f'您輸入的年齡是{age},退休')
3.2 判斷陳述句(if嵌套)
直接上代碼
# if嵌套坐公交
money = 1
seat = 1
if money == 1:
print('土豪,請上車')
# 判斷是否能坐下
if seat == 1:
print('有空做,請坐下')
else:
print('沒有空做,請等著....')
else:
print('沒錢,不讓上車')
3.3 判斷陳述句(if 綜合案例)
直接上代碼
# 猜拳游戲
import random
player = int(input('請出拳:0--石頭;1--剪刀;2--布'))
# computer = 1
computer = random.randint(0,2)
if ((player == 0) and (computer == 1)) or ((player == 1) and (computer == 2)) or ((player == 2) and (computer == 0)):
print('玩家獲勝,哈哈哈 ')
elif player == computer:
print('平局')
else:
print('電腦獲勝')
================================================================================
# 亂數的使用
'''
步驟:
1.匯入模塊
import random
2.使用這個模塊中的功能
random.randint
'''
import random
num = random.randint(0,2)
print(num)
================================================================================
# 三目運算子
a = 1
b = 2
c = a if a > b else b
print(c)
aa = 10
bb = 6
cc = aa - bb if aa > bb else bb - aa
print(cc)
3.4 回圈陳述句(while回圈)
直接看個栗子就能上手使用while回圈
# 1-100 累加和
i = 1
result = 0
while i <= 100:
result += i
i += 1
print(result)
3.5 回圈陳述句(while回圈嵌套)
# 重復列印5行星星
j = 0
while j < 5:
# 一行星星的列印
i = 0
while i < 5:
# 一行內的星星不能換行,取消print默認結束符\n
print('*', end='')
i += 1
# 利用空的print來進行換行
print()
j += 1
============================================================
# 列印三角形,每行星星的個數和行號數相等
# j表示行號
j = 0
while j < 5:
# 一行星星的列印
i = 0
while i <= j:
# i表示每行里面星星的個數,這個數字要和行號相等所以i要和j聯動
print('*', end='')
i += 1
# 利用空的print來進行換行
print()
j += 1
=============================================================
j = 1
while j <= 9:
# 一行運算式的開始
i = 1
while i <= j:
print(f'{i} * {j} = {i*j} ' , end='\t')
i += 1
# 一行運算式的結束
print() # 自帶換行符
j += 1
3.6 回圈陳述句(while…else)
'''
所謂else指的是回圈正常結束之后要執行的代碼,
即如果是break終止回圈的情況,else下方縮進的代碼將不執行,
'''
i = 1
while i <= 5:
if i == 3:
break
print('媳婦我錯了')
i += 1
else:
print('媳婦原諒我了,真開心吶')
===================================================================
"""
因為continue是退出了當前一次回圈,繼續下一次回圈,所以改回圈在continue控制下
是可以正常結束的,當回圈結束后,則執行了else縮進的代碼,
"""
i = 1
while i <= 5:
if i == 3:
# 切記在執行continue之前,一定要改變計數器,否則就會陷入死回圈
i += 1
continue
print('媳婦我錯了')
i += 1
else:
print('媳婦原諒我了,真開心吶')
3.7 回圈陳述句(for、for…else)
str1 = 'ilovepython'
for i in str1:
# 當某些條件成立,退出回圈 條件:i取到字符e的時候退出回圈
if i == 'e':
# continue
break
print(i)
======================================================================
所謂else指的是回圈正常結束之后要執行的代碼,
str1 = 'ilovepython'
for i in str1:
print(i)
else:
print('回圈正常結束執行的else代碼')
4. 字串
4.1 字串的使用
# 字串的使用區別
a = 'hello' \
' world'
print(a) # 輸出一行 hello world
c = '''hello
world'''
print(type(c))
print(c) # 換行輸出hello world
d = """hello
world"""
print(type(d)) # <class 'str'>
print(d) # 會直接換行輸出
# 列印 I'm Tom,使用單引號,必須使用轉移字符,把他轉義過去
e = 'I\'m Tom'
print(e)
# 要是有單引號出現可以使用雙引號括住
f = "I' love Tom"
print(f)
============================================================================
# 字串的輸出
name = 'Tom'
print('我的名字是%s' % name)
print(f'我的名字是{name}')
==============================================================================
# 字串的輸入
password = input('請輸入您的密碼')
print(f'您輸入的密碼是{password}')
# input接收到的用戶輸入的資料都是字串
print(type(password))
4.2 下標和切片
(1)下標
str1 = 'abcdefg'
print(str1)
# 資料在運行程序中存盤在記憶體
# 使用字串中特定的資料
# 使用編號精確找到某個字符資料,下標索引值
# str[下標]
print(str1[0]) # 輸出a
print(str1[1]) # 輸出b
(2)切片
# 序列名[開始位置的下標:結束位置的下表:步長]
# 取值區間左閉右開的
str1 = '012345678'
# print(str1[2:5:1]) 234
# print(str1[2:5:2]) 24
# print(str1[2:5]) 234 # 如果不寫步長,默認步長是1
# print(str1[:5]) 01234 # 如果不寫開始,默認從0開始選取
# print(str1[2:]) 2345678 # 如果不寫結束,表示選取到最后
# print(str1[:]) 012345678 # 如果不寫開始和結束,表示選取所有
# 負數測驗
# print(str1[::-1]) 876543210 # 如果步長為負數,表示倒敘選取
# print(str1[-4:-1]) 567 下標為-1表示最后一個資料,依次向前類推
# 終極測驗
# print(str1[-4:-1:1]) 567
print(str1[-4:-1:-1]) # 不能選取出資料:從-4開始到-1結束,選取方向從左到右,但是-1步長:從右向左選取
# 如果選取方向(下標開始到結束的方向)和步長方向沖突,則無法選取資料
print(str1[-1:-4:-1]) # 876 方向一致就可以正確輸出
小總結: 下標是精確的找到某一個元素,切片可以利用下標找到某一部分元素(左閉右開)
4.3 字串常用操作方法(查找、修改、判斷)
(1)查找
mystr = 'hello world and itcast and itsmail and Python'
# 1. find()
print(mystr.find('and')) # 輸出的是12,以為下標是從0開始數的
print(mystr.fing('and',15,30))
print(mystr.find('ands')) # -1,ands字串不存在
# 2. index
print(mystr.find('and')) # 12
print(mystr.find('and',15,30)) #23
print(mystr.index('ands')) #如果index查找字串不存在,報錯
# 3. count()
print(mystr.count('and')) 3
print(mystr.count('and',15,30)) 1
print(mystr.count('ands')) 0
# 4. rfind()
print(mystr.rfind('and')) 35
print(mystr.find('ands')) -1 如果沒找到,則回傳-1
# 5. rindex()
print(mystr.rindex('and')) 35 就算是到著找,它的下標還是從左到右從下標0開始的
print(mystr.rindex('ands'))
(2)修改
# 遇到串列、字典,內部的資料可以直接修改,修改的就是原串列或者原字典,叫做可變型別,
# 字串是一個不可變型別的資料
mystr = 'hello world and itcast and itheima and Python'
# replace() 把and換成he replace函式有回傳值,回傳值是修改后的字串
new_str = mystr.replace('and','he')
# new_str = mystr.replace('and','he',1)
# 替換次數如果超出字串出席那的次數,表示替換所有這個字串
# new_str = mystr.replace('and','he',10)
print(mystr)
print(new_str)
# 呼叫了replace函式后,發現原有字串的資料并沒有做到修改,修改后的資料是replace函式的回傳值
# 說明字串是不可變資料型別
# 資料是否可以改變劃分為 可變型別,不可變型別
# 2. split() 分割,回傳一個串列,丟失分割字符
list1 = mystr.split('and')
print(list1)
# 3. join() 合并串列里面的字串資料為一個大字串
mylist = ['aa','bb','cc']
new_str = '...'.join(mylist)
print(new_str)
修改-非重點
# 一、字串對齊
# mystr.ljust(10) 左對齊
# mystr.rjust(10) 右對齊
# mystr.rjust(10,'.') 以點作為填充效果
# mystr.center(10) 中間居中
# mystr.center(10,'.') 以點填充空白的地方
# 二、大小寫轉換
mystr = 'hello world and itcast and itheima and Python'
# 1. capitalize() 字串首字母大寫
# new_str = mystr.capitalize()
# print(new_str)
# 2. title():字串中每個單詞首字母大寫
# new_str = mystr.title()
# print(new_str)
# 3. upper():小寫轉大寫
# new_str = mystr.upper()
# print(new_str)
# 4. lower():大寫轉小寫
# new_str = mystr.lower()
# print(new_str)
# 三、洗掉空白字符
str1 = " hello world and itcast and itheima and Python "
# 1. lstrip():洗掉字串左側空白字符
# print(str1)
# new_str = str1.lstrip()
# print(new_str)
# 2. rstrip():洗掉字串右側空白字符
new_str = str1.rstrip()
print(str1)
print(new_str)
# 3. strip():洗掉字串兩側空白字符
# new_str = str1.strip()
# print(new_str)
(3)判斷
# 判斷開頭或結尾
mystr = 'hello world and itcast and itheima and Python'
# 1. startswith(字串,開始位置下標,結束位置下標):判斷字串是否以某個字串開頭
print(mystr.startswith('hello'))
print(mystr.startswith('hel'))
print(mystr.startswith('hels'))
print(mystr.startswith('hell',0,10)) 開始位置下標和結束位置下標可以省略
# 2. endswich(字串,開始位置下標,結束位置下標),始位置下標和結束位置下標可以省略
print(mystr.endswith('Python'))
print(mystr.endswith('Pythons'))
# 判斷
3. isalpha():字母 純字母才可以,如果中間有空格回傳的false
print(mystr.isalpha())
# 4. isdigit():數字,中間也不能有空格,否則回傳false
print(mystr.isdigit())
mystr1 = "12345"
print(mystr1.isdigit())
# 5. isalnum():數字或字母或組合
print(mystr1.isalnum()) # True
print(mystr.isalnum()) # False 因為中間有空格
mystr2 = 'abc123'
print(mystr2.isalnum())
# 6. isspace():判斷是否是空白,是回傳True
print(mystr.isspace()) # False
mystr3 = ' '
print(mystr3.isspace()) # True
5. 串列、元組和字典
5.1 串列的創建和使用
name_list = ['TOM','Lily','ROSE']
print(name_list) # ['TOM', 'Lily', 'ROSE']
# 根據下標進行輸出
print(name_list[0]) # 輸出 TOM
print(name_list[1]) # 輸出 Lily
print(name_list[2]) # 輸出 ROSE
5.2 判斷資料是否在串列中存在
name_list = ['TOM','Lily','ROSE']
# 1. in 如果在里面就回傳true,否則false
print('TOM' in name_list)
print('TOMS' in name_list)
# 2. not in 這個跟in相反
print('TOM' not in name_list)
print('TOMS' not in name_list)
體驗案例
name_list = ['TOM','List','ROSE']
# 需求:注冊郵箱,用戶輸入一個賬戶名,判斷這個賬號是否存在,如果存在,提示用戶,否則提示可以注冊
name = input("請輸入您的郵箱賬號名:")
if name in name_list:
# 提示用戶名已經存在
print(f'您輸入的名字是{name},此用戶已經存在')
else:
# 提示可以注冊
print(f'您輸入的名字是{name},可以注冊')
5.3 串列的常見操作(查找、增加、洗掉、修改、賦值)
(1)查找(index、count、len)
name_list = ['TOM','Lily','Rose']
# 1.index()
print(name_list.index('TOM')) #回傳 0
# print(name_list.index('TOMs')) 沒有找到,報錯
# 2. count()
print(name_list.count('TOM'))
# print(name_list.count('TOMS')) # 報錯
# 3.len()
print(len(name_list)) # 輸出3
(2)增加(append、extend、insert)
# 1. 串列資料是可變的 -- 串列是可變型別
# 2. append函式追加資料的時候如果是一個序列,追加整個序列到串列的結尾
name_list = ['TOM','Lily','ROSE']
name_list.append('xiaoming')
name_list.append([11,22])
name_list.append(11)
print(name_list) # 輸出結果為:['TOM', 'Lily', 'ROSE', 'xiaoming', [11, 22], 11]
# extent() 追加資料是一個序列,把資料序列里面的資料拆開然后逐一追加到串列的結尾
name_list = ['TOM','Lily','ROSE']
name_list.extend('xiaoming')
# 把序列拆開,逐一的放到串列中
name_list.extend(['xiaoming','xiaojun'])
print(name_list)
# 輸出結果為:['TOM', 'Lily', 'ROSE', 'x', 'i', 'a', 'o', 'm', 'i', 'n', 'g', 'xiaoming', 'xiaojun']
name_list = ['Tom','Lily','ROSE']
# name_list.insert(下標,資料) 在指定位置加入資料
name_list.insert(1,'aa')
print(name_list) # 輸出的結果為:['Tom', 'aa', 'Lily', 'ROSE']
(3)洗掉(del、pop、remove、clear)
name_list = ['Tom','Lily','ROSE']
# 1. del
# del name_list
# print(name_list) 已經把串列已經洗掉,已經沒有串列了
# del 也可以指定下標的資料
# del name_list[0]
# print(name_list) # 輸出的結果 ['Lily', 'ROSE']
# 2. pop() 洗掉指定下標的資料,如果不指定下標,默認洗掉最后一個資料
# 無論是按照下標還是洗掉最后一個,pop函式都會回傳這個被洗掉的資料. 比較厲害的是洗掉一個資料能用一個變數去接收
del_name = name_list.pop()
del_name = name_list.pop(1)
print(del_name)
print(name_list)
# 3. remove(資料) 按照指定的資料進行洗掉的
# name_list.remove('ROSE')
# print(name_list)
# 4. clear() -- 清空
# name_list.clear()
# print(name_list) # 直接清空整個資料
(4)修改(reverse、sort)
name_list = ['TOM','Lily','ROSE']
# 修改指定下標的資料
# name_list[0] = 'aaa'
# print(name_list) # ['aaa', 'Lily', 'ROSE']
# 2. 逆序 reverse()
list1 = [1, 3, 4, 2, 5]
# list1.reverse()
# print(list1)
# 3. sort() 排序:升序(默認)和 降序
# list1.sort() # 升序
list1.sort(reverse=False) # 升序 [1, 2, 3, 4, 5]
list1.sort(reverse=True) # 降序 [5, 4, 3, 2, 1]
print(list1)
(5)賦值
name_list = ['tom','lucy','jack']
list1 = name_list.copy()
print(list1)
print(name_list)
5.4 串列的回圈遍歷(for、while)
for回圈
name_list = ['tom','rose','jack']
i = 0
while i < len(name_list):
print(name_list[i])
i += 1
while回圈
# for回圈的代碼量要少于while的代碼量
# 一般在作業崗位下,涉及到遍歷序列當中的資料的話,一般優選于for回圈
name_list = ['tom','rose','jack']
for i in name_list:
# 遍歷序列中的資料
print(i)
5.5 串列的嵌套
串列嵌套時的資料查詢
name_list = [['TOM', 'Lily','Rose'], ['張三','李四','王二'], [ '小紅', '小綠', '小藍']]
# print(name_list)
# 串列嵌套的時候的資料查詢
print(name_list[0])
print(name_list[0][0])
案例-隨機分配辦公室
# 需求:八位老師,3個辦公室,將8為老師隨機分配到3個辦公室
'''
步驟::
1.準備資料
1.1 8位老師 -- 串列
1.2 3個辦公室 -- 串列嵌套
2. 分配老師到辦公室
隨機分配
就是把老師的名字寫入到辦公室串列 --辦公室串列追加老師資料
3. 驗證是否分配成功
列印辦公室詳細資訊: 每個辦公室的人數和對應的老師名字
'''
import random # 隨機模塊
# 1. 準備資料
teachers = ['A','B','C','D','E','F','G','H'] # 串列存資料
offices = [[], [], []] # 嵌套串列
# 2. 分配老師到辦公室 -- 取到每個老師放到辦公室串列 -- 遍歷老師串列資料
for name in teachers:
# 串列追加資料 -- append(整體添加) --extend(拆開添加) --insert(在指定位置加入資料)
num = random.randint(0,2)
offices[num].append(name) #追加資料
# print(num)
# print(offices)
# 為了更貼合生活,把各個辦公室子串列加一個辦公室編號1 ,2 ,3
i = 1
# 3. 驗證是否成功
for office in offices:
# 列印辦公室人數 -- 子串列資料的個數 len()
print(f'辦公室{i}的人數是{len(office)}')
# 列印老師的名字
# print() -- 每個自立表里面的名字個數不一定 -- 遍歷 -- 子串列
for name in office:
print(name)
i += 1
5.6 元組的訪問
注意: 如果是單個資料的元組,那么后面必須加逗號,否則就不是元組的資料型別,而是整個資料本身的資料型別
# 輸出元組
t1 = (10, 20, 30)
print(t1) # 輸出 (10, 20, 30)
# 如果是單個資料的元組,那么后面必須加逗號,否則就不是元組的資料型別,而是整個資料本身的資料型別
# 1.多個資料元組
t1 = (10, 20, 30)
print(type(t1)) # 輸出 <class 'tuple'>
# 2. 單個資料元組
t2 = (10,)
print(type(t2)) # 輸出 <class 'tuple'>
=====================================================================
# 3. 如果單個資料的元組不加逗號
t3 = (10)
print(type(t3)) # 輸出 <class 'int'>
t4 = ('aaa')
print(type(t4)) # 輸出 <class 'str'>
================================================================================
t5 = ('aaa',)
print(type(t5)) # 輸出 <class 'tuple'>
5.7 元組常見操作(查找、修改)
(1)查找
t1 = ('aa', 'bb', 'cc')
# 1. 下標
print(t1[0]) # aa
# 2. index()
print(t1.index('aa')) # 輸出0 其實有引數二,有引數三對應一個查找的范圍,如果沒有找到就直接報錯,
# 3. count()
print(t1.count('aa')) # 統計aa的次數,輸出結果為1
# 4. len()
print(len(t1)) # 統計整個元組的個數,輸出結果為3
(2)修改
# 元組確實不能修改,但是元組中含有的串列可以修改,
# 作業中盡可能遵循一個規則,但凡是出現在小括號元組里面的資料,盡可以能靠自覺去要求不做修改
# 作業中如果是同事的代碼,有資料出現在元組中,盡可能在查找操作的時候,小心一點,盡可能不要去修改這一部分的操作,
t1 = ('aa', 'bb', 'cc')
# t1[0] = 'aaa' 這個操作是錯的,是不能修改的,
t2 = ('aa', 'bb', ['cc', 'dd'])
print(t2[2])
t2[2][0] = 'TOM'
print(t2)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/66705.html
標籤:其他
上一篇:轉到人工智能上面好轉嗎?
下一篇:單元測驗 mock