目錄
- 1. 網站分析
- 2. 示例代碼
- 3. 注意事項
1. 網站分析
本文實作的爬蟲是抓取京東商城指定蘋果手機的評論資訊,使用 requests 抓取手機評論 API 資訊,然后通過 json 模塊的相應 API 將回傳的 JSON 格式的字串轉換為 JSON 物件,并提取其中感興趣的資訊,讀者可以點擊此處打開 京東商城,如下圖所示:
URL 是 蘋果手機商品 ,商品頁面如下圖所示:
在頁面的下方是導航條,讀者可以單擊導航條上的數字按鈕,切換到不同的頁面,會發現瀏覽器地址欄的 URL 并沒改變,這種情況一般都是通過另外的通道獲取的資料,然后將資料動態顯示在頁面上,那么如何來尋找這個通道的 URL 呢?
在 Chrome 瀏覽器的開發者工具的 Network 選項中單擊 XHR 按鈕,再切換到其他頁,并沒有發現要找的 API URL,可能京東商城獲取資料的方式有些特殊,不是通過 XMLHttpRequest 發送的請求,
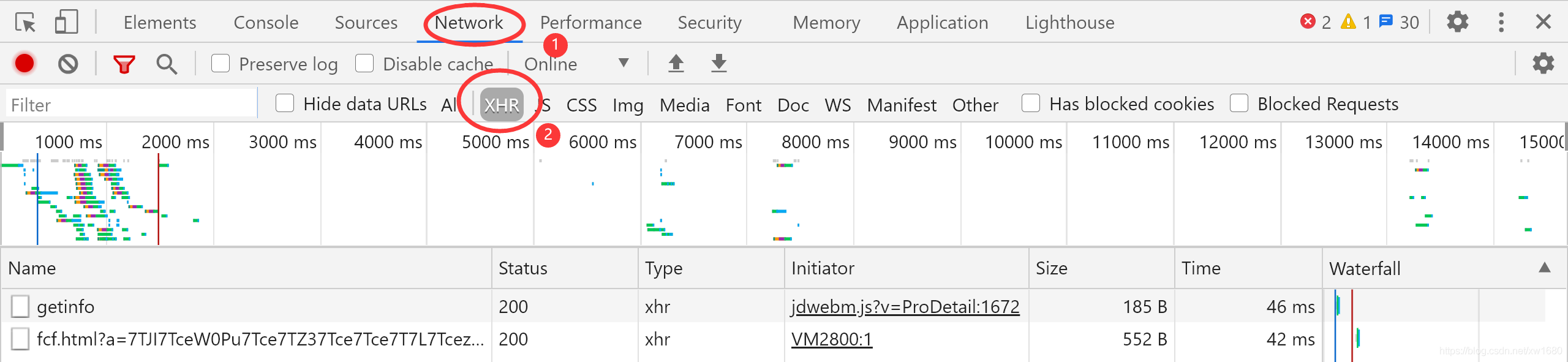
所以重新選中 All 按鈕,顯示所有的 URL,現在用另外一種方式尋找這個 URL,就是 Filter,通過左上角的 Filter 輸入框,可以通過關鍵字搜索 URL,由于本文是抓取評論資料,所以可以嘗試輸入 comments,在左下角的串列中會出現如下圖所示的內容,
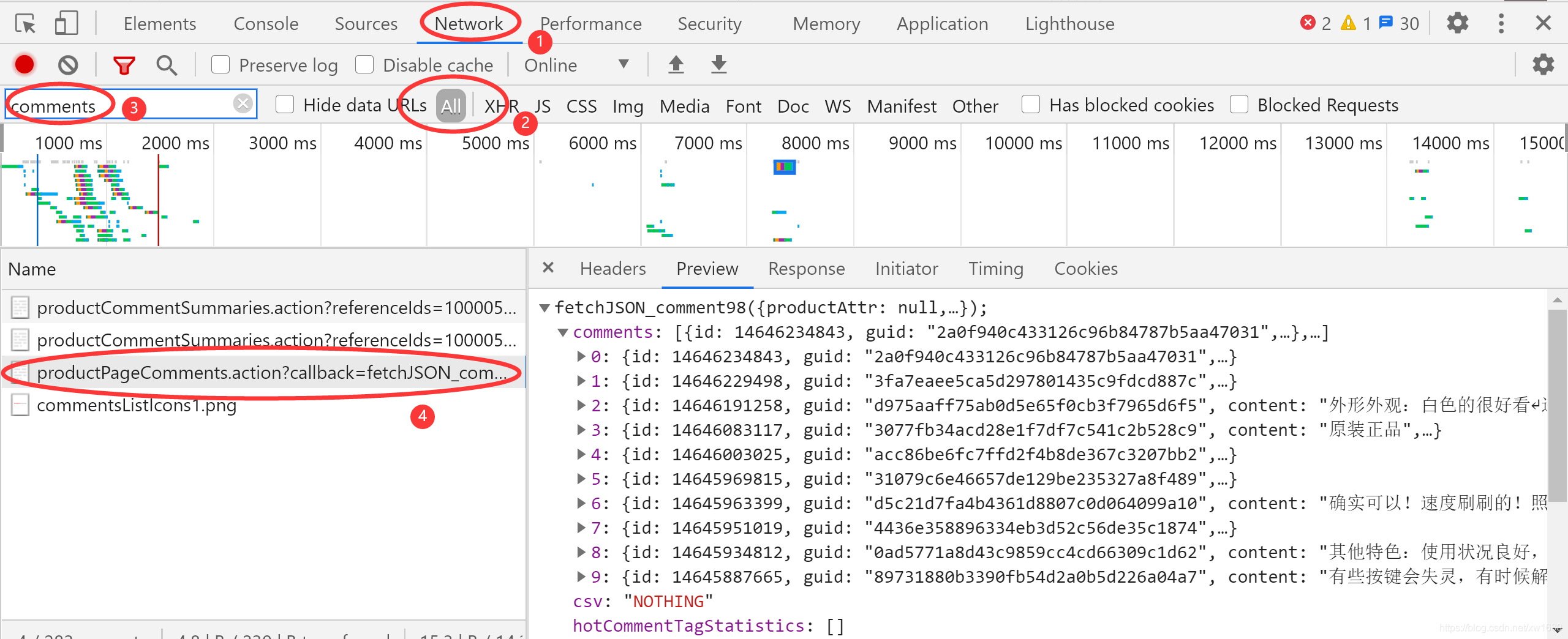
在搜索結果中會看到 1個名為 productPageComments.action 的 URL ,單機這個 URL,在右側切換到 Preview 選項卡,會看到如上圖所示的內容,很明顯,這是 JSON 格式的資料,展開 comments ,會看到有 10 項 ,這是回傳的 10 條評論,在展開某一條評論,如下圖所示:
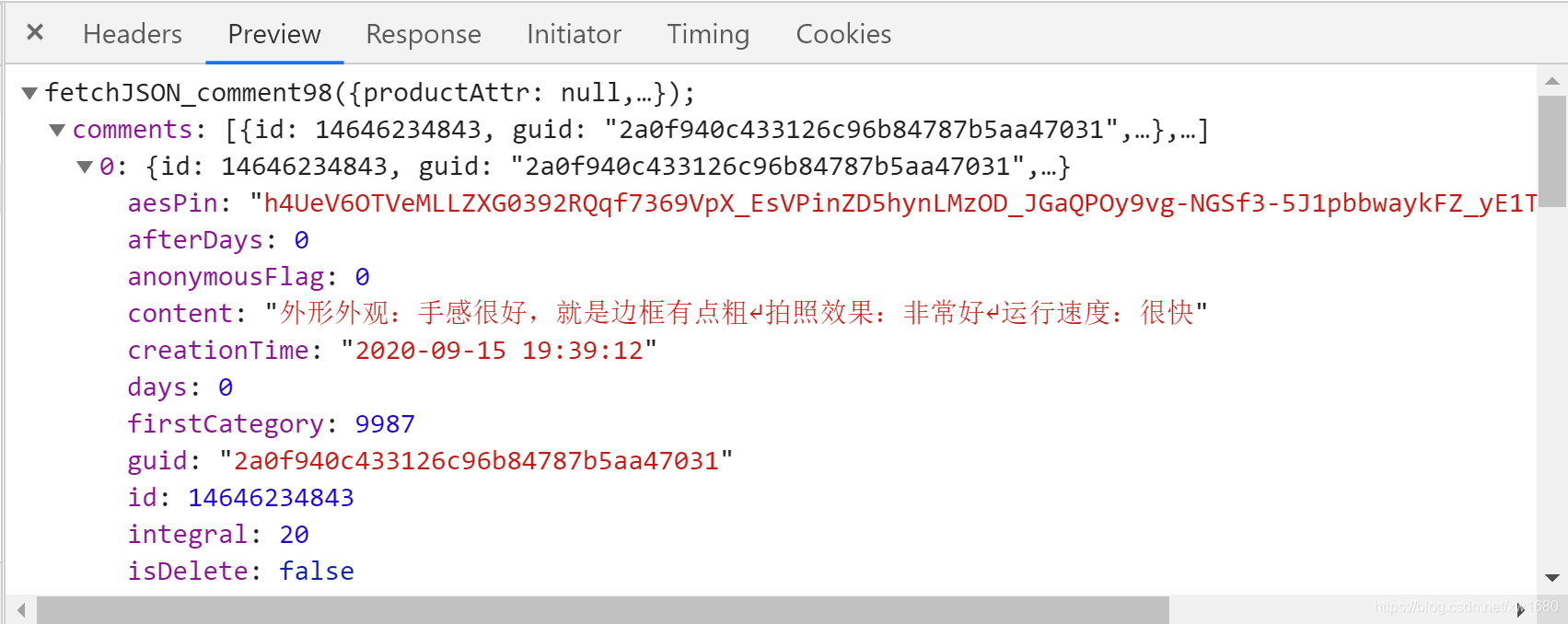
從屬性的內容可以看出,content 屬性是評論內容,creationTime 是評論時間,days 是購買多長時間后才來評論的,通過 Headers 選項卡可以得到如下完整的 URL ,
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100005492549&score=0&sortType=5&page=0&pageSize=10&isShadowSku=100008348530&fold=1
從這個 URL 可以看出,page 引數表示頁數,從 0 開始,pageSize 引數表示每頁獲取的評論數,默認是 10,這個引數可以保留默認值,只改變 page 引數即可,
2. 示例代碼
根據前面的描述實作抓取蘋果手機評論資訊的爬蟲,通過 fetch_comment_count 變數可以控制抓取的評論條數,最后將抓取的結果顯示在控制臺中,示例代碼如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:4.抓取京東蘋果手機評論.py
@time:2020/09/15
"""
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
fetch_comment_count = 1000 # 限定抓取的評論數
index = 0 # 用于記錄爬取到第幾條評論
page_index = 0 # 頁碼
flag = True # 用于控制回圈是否退出
while flag:
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100005492549&score=0&sortType=6&page={}&pageSize=10&isShadowSku=100008348530&rid=0&fold=1'.format(
page_index)
page_index += 1
res = requests.get(url=url, headers=headers)
text = res.text
# 下面的代碼替換回傳資料的部分內容,因為回傳的資料并不是標準的 JSON 格式
json_str = text.replace('fetchJSON_comment98(', '')[:-2]
json_obj = json.loads(json_str) # 將字串轉換為字典物件
comments_list = json_obj['comments']
comments_list_length = len(comments_list)
# 回圈輸出評論資料
for i in range(comments_list_length):
comments = comments_list[i]['content']
print(f'< {index + 1} > {comments}')
creation_time = comments_list[i]['creationTime'] # 獲取評論時間
nickname = comments_list[i]['nickname'] # 獲取昵稱
print(creation_time)
print(nickname)
print("-" * 20)
index += 1
if index == fetch_comment_count:
flag = False
break
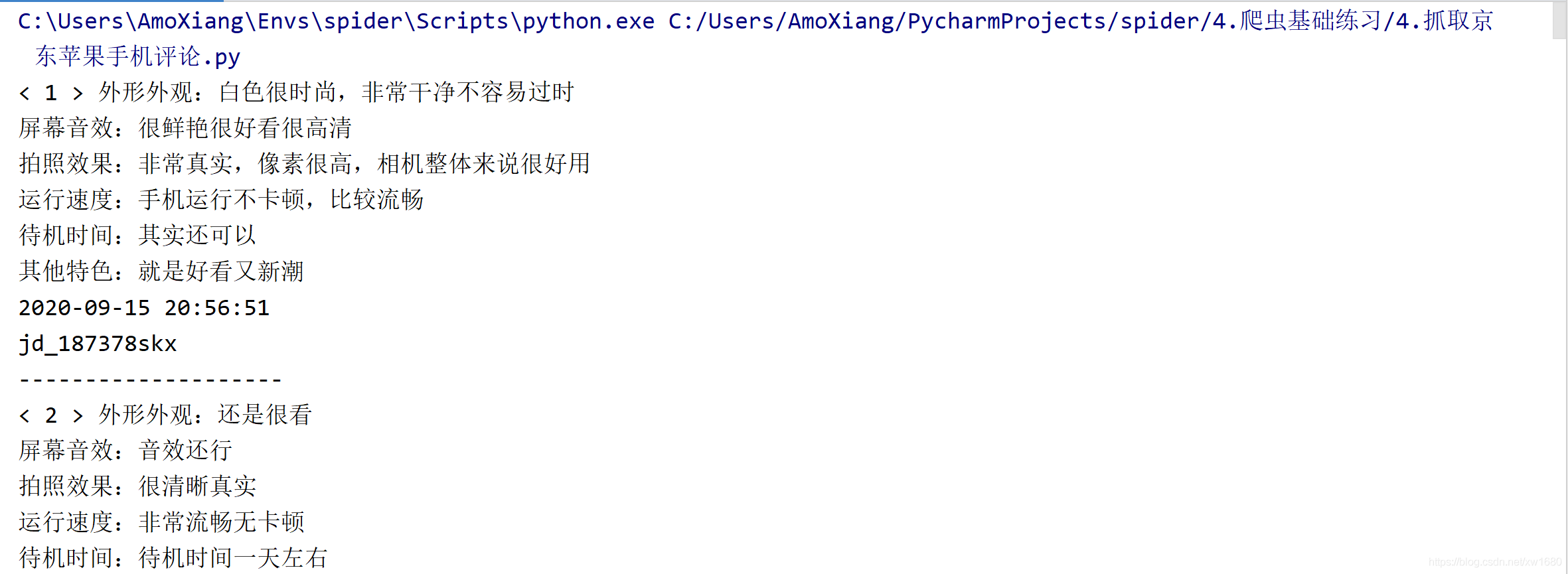
程式運行結果如下圖所示:
3. 注意事項
- 京東商城如果頻繁使用同一個
IP發起大量請求,服務端會臨時性封鎖IP,可以使用一些免費的代理, API URL回傳的資料并不是標準的JSON,里面還有一些雜質,需要在本地將其洗掉, 本例有一個前綴是fetchJSON_comment98,這個前綴是通過URL的callback引數指定的,根據引數名應該是個回呼函式,具體是什么不需要管,總之,需要按照callback引數的值將回傳資料的前綴去掉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/66712.html
標籤:其他
上一篇:在哪里可以討論期權日歷價差策略