這個是我爬取的連接http://hotel.meituan.com/item/161066061/?ci=2017-10-20&co=2017-10-21
爬取的位置
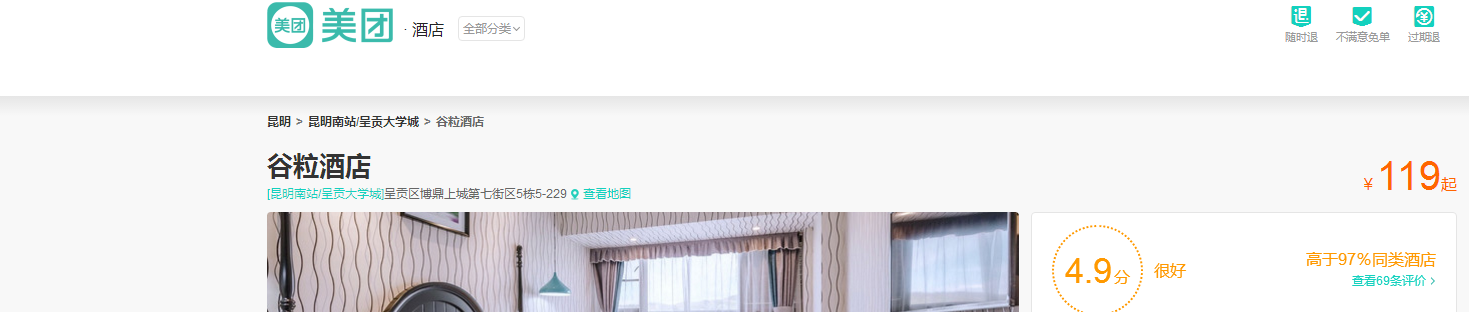
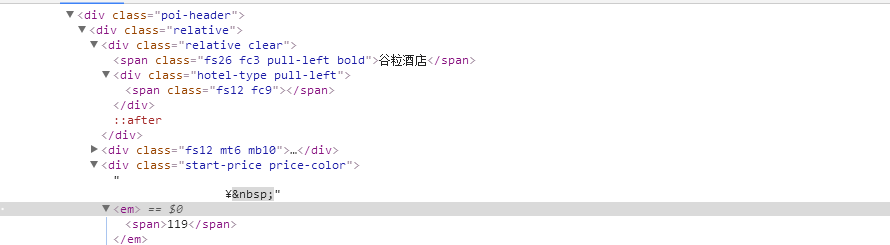
抓取的文本應該是價格,但輸出的是0
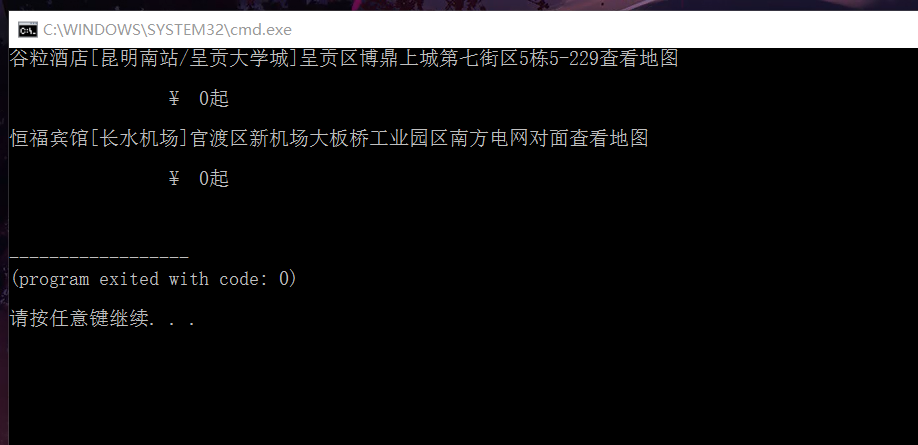
代碼是這個
from urllib.request import urlopen
from bs4 import BeautifulSoup
lii=["http://hotel.meituan.com/item/161066061/?ci=2017-10-20&co=2017-10-21","http://hotel.meituan.com/item/5651700/?ci=2017-10-20&co=2017-10-21"]
for ss in lii:
url=urlopen(ss)
soup=BeautifulSoup(url.read(),"lxml")
ui=soup.find_all("span",{"class":"fs26 fc3 pull-left bold"})
score=soup.select("#poiDetail > div > div > div.base-info > div > div.relative")
for name in score:
print(name.get_text())
是抓取的方法不對嗎?
uj5u.com熱心網友回復:
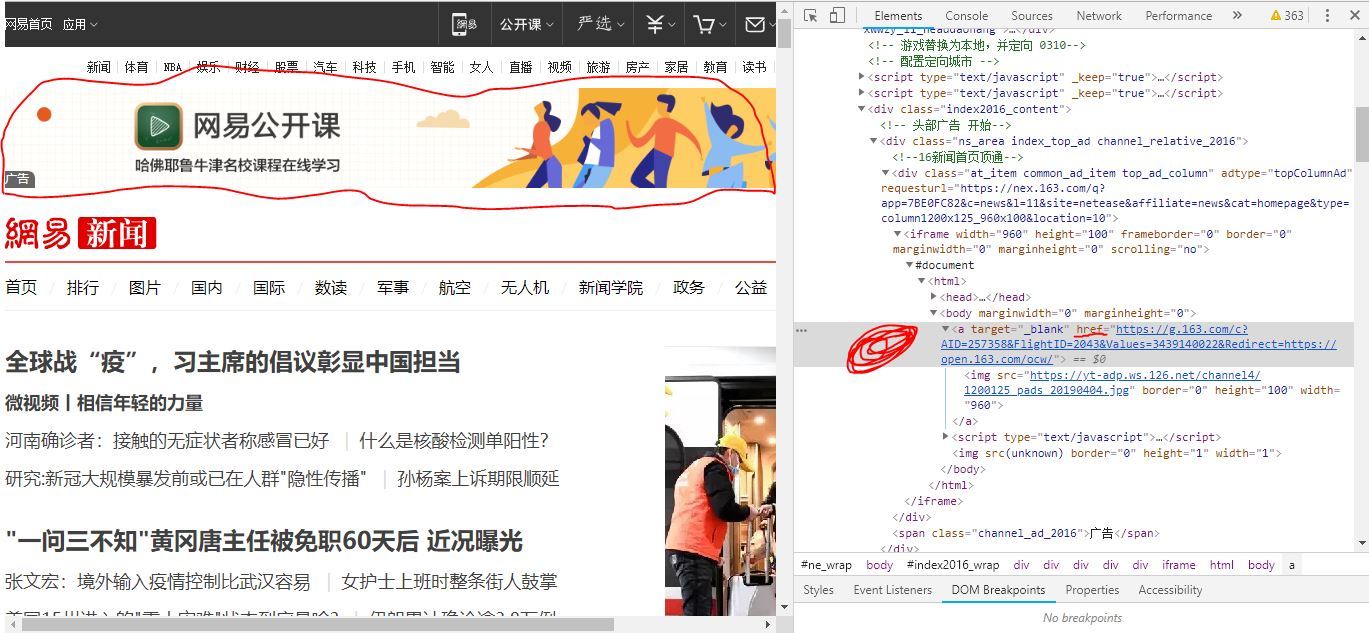
我也遇到了類似的問題,網頁中有的內容復制了selector或xpath之后就能匯出,有的卻是空的。我爬取的是網易新聞的首頁廣告。https://news.163.com/
from requests_html import HTMLSession
session = HTMLSession()
url = 'https://news.163.com/'
r = session.get(url)
sel='//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[1]/div/iframe/html/body/a'
results = r.html.xpath(sel)
print(results.html.text)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/66785.html
標籤:其他開發語言